昇腾NPU赋能海外主流大模型 | Llama-2-7b深度测评与部署方案【玩转华为云】

一. 昇腾NPU引领国产AI算力新时代
当生成式人工智能迈入规模化应用的深水区,大模型已从技术探索走向产业落地的关键节点,而算力作为支撑这一进程的核心基础设施,正面临着前所未有的双重挑战:一方面,以Llama、GPT系列为代表的大模型参数规模持续扩大,对算力的峰值性能、内存带宽、能效比提出了指数级增长的需求;另一方面,全球算力供给格局的不确定性,使得核心算力设施的国产化替代成为保障AI产业自主可控发展的战略刚需。
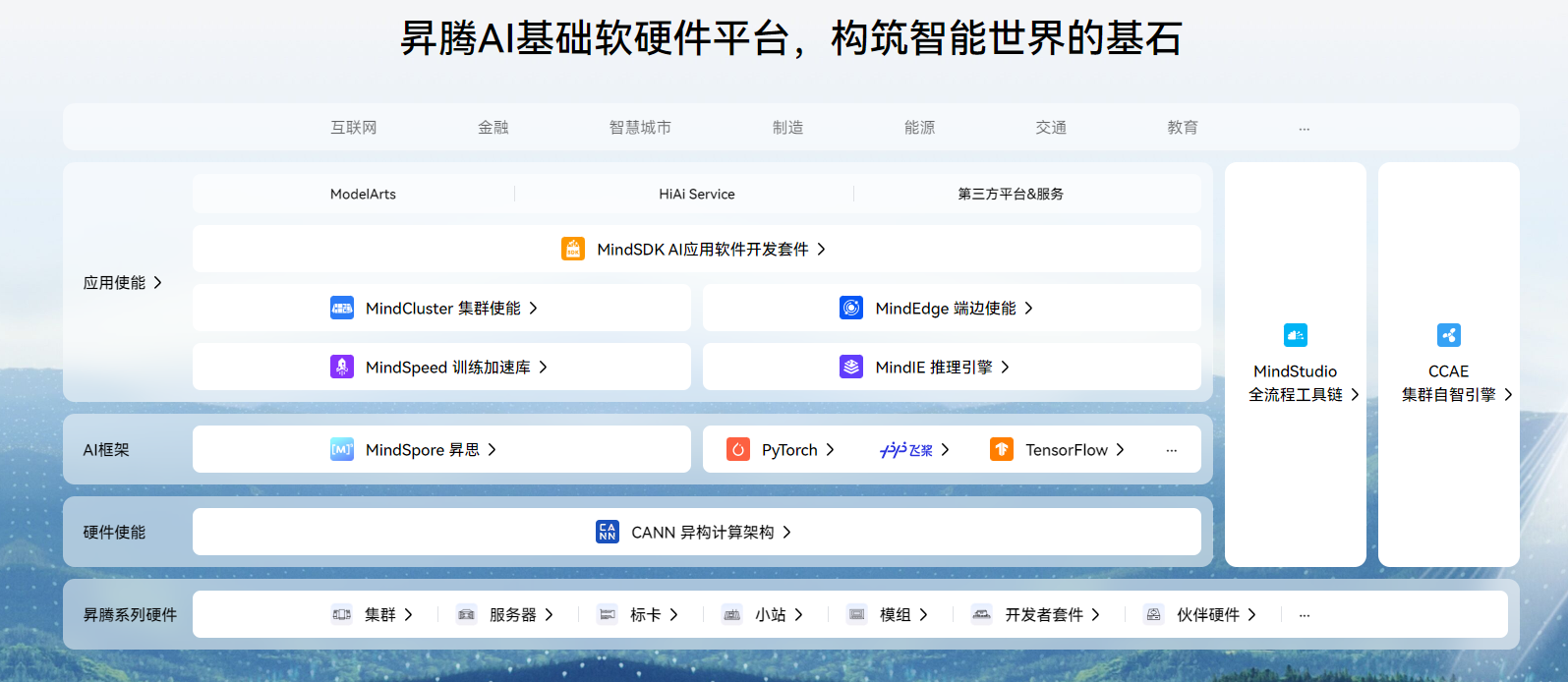
在此背景下,昇腾NPU(神经网络处理器)作为国产高端AI芯片的核心代表,其技术成熟度、生态适配性与性能表现,直接关系到我国在全球AI算力竞争中的核心话语权。
昇腾NPU自诞生以来,便承载着构建国产AI算力底座的战略使命,通过“芯片-框架-模型-应用”全栈式技术布局,打破了海外算力芯片在高端AI领域的垄断局面。从架构设计来看,昇腾NPU采用面向AI计算的专用架构,集成了大量AI计算单元与高效内存管理模块,能够针对性解决大模型训练与推理过程中的数据吞吐瓶颈。
本次测评的核心硬件平台基于昇腾910B NPU构建,其为大模型的高速推理提供了坚实的硬件基础;
1.什么是昇腾NPU
昇腾 NPU(Ascend Neural Processing Unit)是由华为自主研发的新一代 专用人工智能处理器(AI Processor),核心目标是为深度学习训练与推理任务提供高性能、低功耗的计算支持。与传统 CPU 或 GPU 不同,NPU 采用了 “算子级优化 + 并行加速架构” 的设计理念,其底层指令集与内存控制逻辑完全围绕神经网络计算特点进行优化,能够实现更高的计算密度与能效比。

昇腾 NPU 的核心技术优势体现在以下三个方面:
- 架构层面:采用自研的 Da Vinci 架构,将向量计算单元、标量计算单元与 AI 专用矩阵计算单元融合在统一芯片中,实现数据流驱动的高并行计算;
- 算力表现:以昇腾 910B 为例,其单芯片算力可达 320 TFLOPS(FP16),并支持多芯片互联(HCCS 高速通信协议),可扩展至上千 PFLOPS 级 AI 集群;
- 生态体系:依托 CANN(Compute Architecture for Neural Networks) 计算架构、MindSpore 深度学习框架及 AscendCL 底层驱动接口,昇腾已构建起从芯片、框架、算子到应用的全栈生态体系,形成了国产 AI 算力的完整闭环。
在大模型时代,昇腾 NPU 不仅承担着推理加速的硬件角色,更是 国产AI自主创新的算力底座。它让中国开发者能够在本土硬件环境中完成大模型训练、微调与推理部署,为实现“AI核心技术自主可控”提供了坚实的算力基础。
2.Llama-2-7b
Llama-2-7b 是由 Meta(原 Facebook)推出的第二代开源大语言模型(LLaMA 系列)的中型版本,拥有约 70 亿个参数(7B Parameters),在性能与资源占用之间实现了理想平衡。作为 LLaMA 系列的重要成员,Llama-2 相比前代在训练语料、模型结构及对话能力方面都有显著提升,尤其在 多语言理解、逻辑推理与代码生成 等任务中展现出强大的通用能力。

Llama-2-7b 的主要技术特征包括:
- 模型结构:基于标准的 Transformer Decoder-only 架构,采用多头自注意力机制与高效位置编码设计;
- 训练数据:使用了超过 2 万亿 tokens 的多领域语料,包括英文、中文、编程语言、百科与学术数据,覆盖面广泛;
- 训练优化:在预训练阶段引入了动态学习率与分层权重衰减策略,并在指令微调阶段使用 RLHF(人类反馈强化学习)进一步增强对话质量;
- 推理特性:支持 FP16 与 INT8 混合精度推理,可在有限显存(≥40GB)环境下运行;
- 适配生态:在 HuggingFace Transformers、PyTorch、MindSpore 等多个框架中均可直接加载使用,兼容性良好。
在实际应用中,Llama-2-7b 既能提供接近 GPT-3.5 级别的推理能力,又具备可控开放的部署特性,非常适合在 国产昇腾 NPU 平台 上进行本地化部署与性能测评。
其模型规模适中、权重可开放下载,成为国产算力生态验证与 AI 工程落地的理想实验对象。
二. GitCode算力平台快速构建
GitCode 是一款由 CSDN 开发者社区与华为云 CodeArts 联合打造的新一代开源代码托管平台,它集代码托管、协同研发、项目管理与开源运营支持于一体,同时也为 AI 和机器学习项目提供算力支持。
1.环境准备与检验
首先在GitCode页面主页打开我的Notebook。
如果没有使用/创建过,需要激活Notebook。
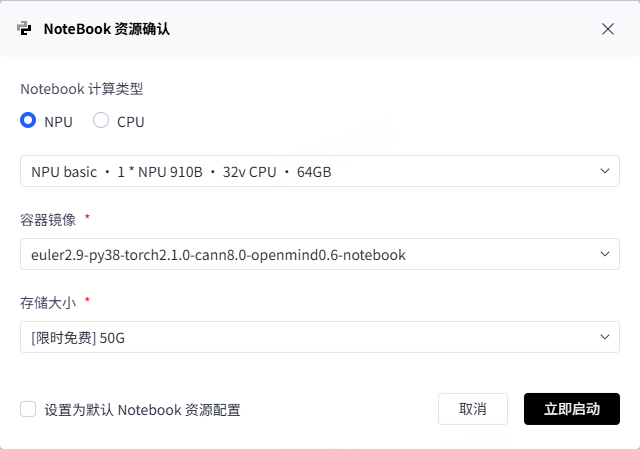
选择资源类型如下:
计算类型:选择的是 NPU 类型,具体规格为
NPUbasic·1*NPU910B·32VCPU·64GB。使用 1 颗 NPU 910B 芯片,搭配 32 核虚拟 CPU(VCPU)和 64GB 内存进行计算任务。
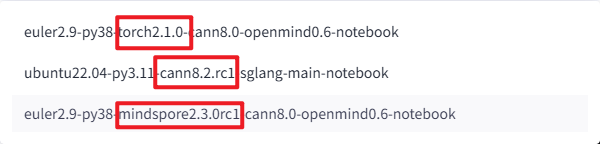
容器镜像:使用的镜像是
euler2.9-py38-torch2.1.0-cann8.0-openmind0.6-notebook
存储配置:分配了 50GB 存储,限时免费。
或者使用mindspore都是可以的。
启动后,耐心等待资源分配。

进入后的基于昇腾NPU的页面notebook如下。
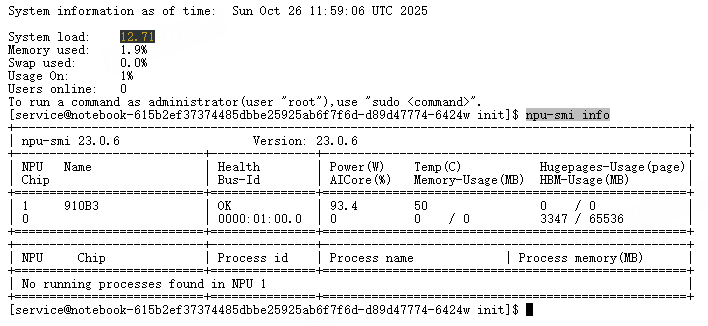
启动后需要验证环境,在Notebook界面找到"终端"入口,打开Terminal。
NPU 芯片识别,可以看到有一颗
npu-smi info
Python 与 pip 验证
python --version 或 python3 --version
pip --version 或 pip3 --version
pip list | grep -E "mindspore|cann|euler"

MindSpore 框架验证
# 查看MindSpore版本(应显示2.3.0)
python -c "import mindspore; print(mindspore.__version__)"
# 验证MindSpore是否能识别NPU设备(关键步骤)
python -c "import mindspore; print(mindspore.context.get_context('device_target')); print(mindspore.context.get_context('device_id'))"
# 正常输出应为:Ascend(表示使用昇腾NPU)和 0(默认设备ID)

功能完整性验证(运行简单 MindSpore 任务)
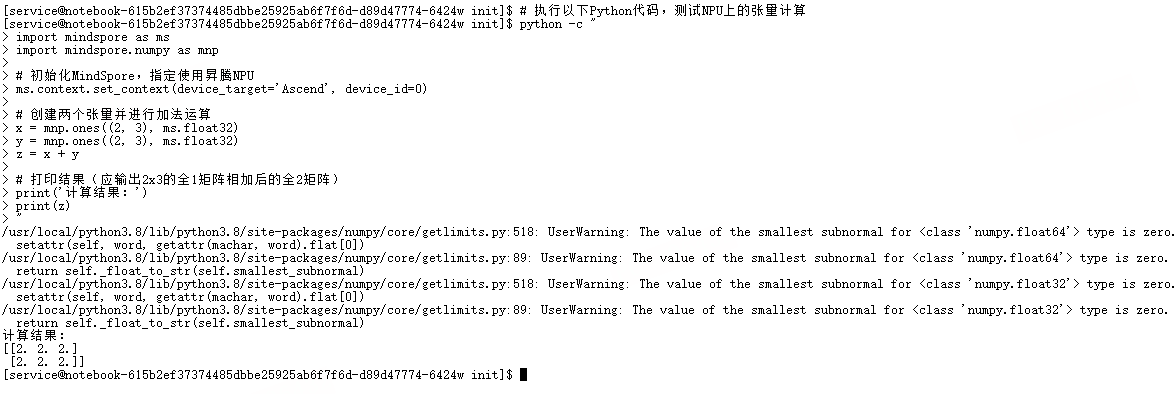
# 执行以下Python代码,测试NPU上的张量计算
python -c "
import mindspore as ms
import mindspore.numpy as mnp
# 初始化MindSpore,指定使用昇腾NPU
ms.context.set_context(device_target='Ascend', device_id=0)
# 创建两个张量并进行加法运算
x = mnp.ones((2, 3), ms.float32)
y = mnp.ones((2, 3), ms.float32)
z = x + y
# 打印结果(应输出2x3的全1矩阵相加后的全2矩阵)
print('计算结果:')
print(z)
"
做完上文的检测就可以进行Llama-2-7b的部署了。
或者大家直接在nodebook里新建一个Python项目运行代码即可。
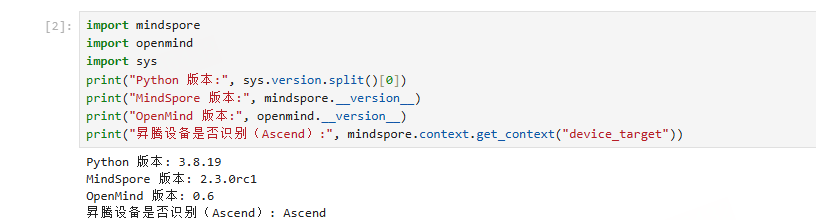
import mindspore
import openmind
import sys
print("Python 版本:", sys.version.split()[0])
print("MindSpore 版本:", mindspore.__version__)
print("OpenMind 版本:", openmind.__version__)
print("昇腾设备是否识别(Ascend):", mindspore.context.get_context("device_target"))
注意:大部分用户可以使用torch的多,这里三种框架都可以跑Llama。
2.模型下载部署方案
Llama 2 权重需从官方申请或使用社区转换后的 MindSpore 格式,在 Notebook 中可通过以下两种方式获取。
2.1 从 Meta 官方下载原始权重(需申请)
打开 Notebook 的终端(Terminal) 标签(通常在 Notebook 界面 “New” 下拉菜单中)。
按 Meta 官方指引,在终端中使用wget或curl下载权重至指定目录(如/home/llama2-7b/original/):
2.2 直接下载开源社区的格式权重(更便捷)
使用开源社区的镜像版本 NousResearch/Llama-2-7b-hf,不需要申请权限,下载也更稳定。
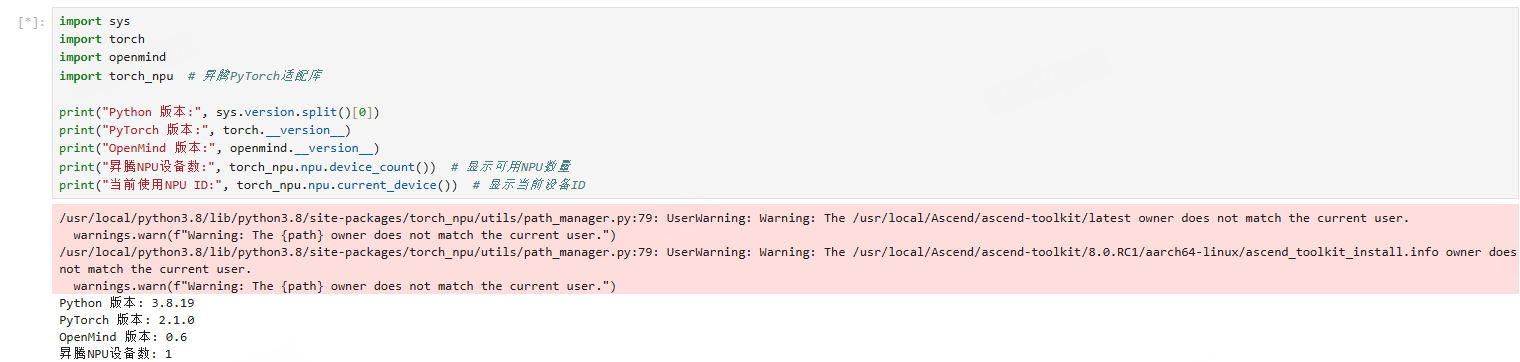
import torch
import torch_npu # 必须导入!
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
# 模型名称(使用开源镜像版本)
MODEL_NAME = "NousResearch/Llama-2-7b-hf"
# 加载tokenizer和模型
print("下载模型...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
torch_dtype=torch.float16, # 使用FP16节省显存
low_cpu_mem_usage=True
)
# 迁移到NPU(关键步骤)
device = "npu:0"
model = model.to(device)
model.eval()
print(f"模型已加载到NPU")
print(f"显存占用: {torch.npu.memory_allocated() / 1e9:.2f} GB")
Llama-2 的官方仓库(meta-llama/Llama-2-7b-hf)有两个主要使用门槛:一是访问该仓库需先申请并获得官方授权;二是由于国内网络环境限制,直接访问 HuggingFace 平台时,经常会出现连接超时的问题,导致无法顺利获取资源。
可以直接拉国内仓库镜像。

等待其下载完成,如下。
三. 多维性能测评
本次测评针对 Meta 发布的 Llama-2-7b-chat-hf 模型在昇腾计算平台上的表现进行了全面评估。作为当前最受欢迎的开源大语言模型之一,Llama-2.7 在各类自然语言处理任务中展现出了卓越的能力。本次测评重点考察了模型在中文环境下的对话能力、代码生成、知识问答等多方面表现。
模型版本: Llama-2-7b-chat-hf
硬件平台: 昇腾 NPU
测试设备: npu:0
模型精度: float16
测试问题数量: 5个不同类型的问题
3.1 测评脚本
这个测评脚本用于在昇腾设备(npu:0)上对Llama-2-7b-chat-hf模型进行简易测试,流程包括加载模型和分词器,设置相关参数,针对5个测试问题(涵盖自我介绍、代码编写、常识问答等类型)构建对话格式输入,利用模型生成回复并统计加载耗时、各问题生成时间及总耗时、平均生成时间,同时包含错误处理及相关检查提示,可评估该模型在昇腾环境下的加载效率与生成性能。
import os
import time
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import torch_npu
# 设置昇腾设备
device = "npu:0"
torch.npu.set_device(device)
def simple_llama_test(model_path="Llama-2-7b-chat-hf"):
print("正在加载模型和tokenizer...")
start_time = time.time()
# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 加载模型到昇腾设备
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map=device
)
load_time = time.time() - start_time
print(f"模型加载完成,耗时: {load_time:.2f}秒")
# 设置pad_token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# 测试用例
test_prompts = [
"请介绍一下你自己",
"写一个Python函数计算斐波那契数列",
"中国的首都是哪里?",
"请解释一下机器学习是什么",
"1+2+3+4+5等于多少?"
]
print("\n开始测试...")
print("=" * 50)
results = []
for i, prompt in enumerate(test_prompts, 1):
print(f"\n测试 {i}/5:")
print(f"问题: {prompt}")
# 构建对话格式
formatted_prompt = f"<s>[INST] {prompt} [/INST]"
# 编码输入
inputs = tokenizer(formatted_prompt, return_tensors="pt").to(device)
# 生成回复
start_time = time.time()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_length=512,
temperature=0.7,
do_sample=True,
top_p=0.9,
pad_token_id=tokenizer.eos_token_id,
repetition_penalty=1.1
)
generation_time = time.time() - start_time
# 解码回复
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 提取生成的文本(移除输入prompt)
if response.startswith(formatted_prompt):
answer = response[len(formatted_prompt):].strip()
else:
answer = response
print(f"回答: {answer}")
print(f"生成时间: {generation_time:.2f}秒")
print("-" * 40)
results.append({
"prompt": prompt,
"answer": answer,
"time": generation_time
})
# 统计信息
total_time = sum([r["time"] for r in results])
avg_time = total_time / len(results)
print(f"\n测试总结:")
print(f"总测试问题: {len(results)}")
print(f"总生成时间: {total_time:.2f}秒")
print(f"平均生成时间: {avg_time:.2f}秒")
return results
if __name__ == "__main__":
print("Llama-2-7b-chat-hf 简易测评 (昇腾版本)")
print("=" * 50)
try:
results = simple_llama_test()
print("\n测评完成!")
except Exception as e:
print(f"错误: {e}")
print("请检查:")
print("1. 模型路径是否正确")
print("2. 昇腾环境是否配置正确")
print("3. 是否有足够的内存")
3.2 性能表现分析
1.模型加载效率
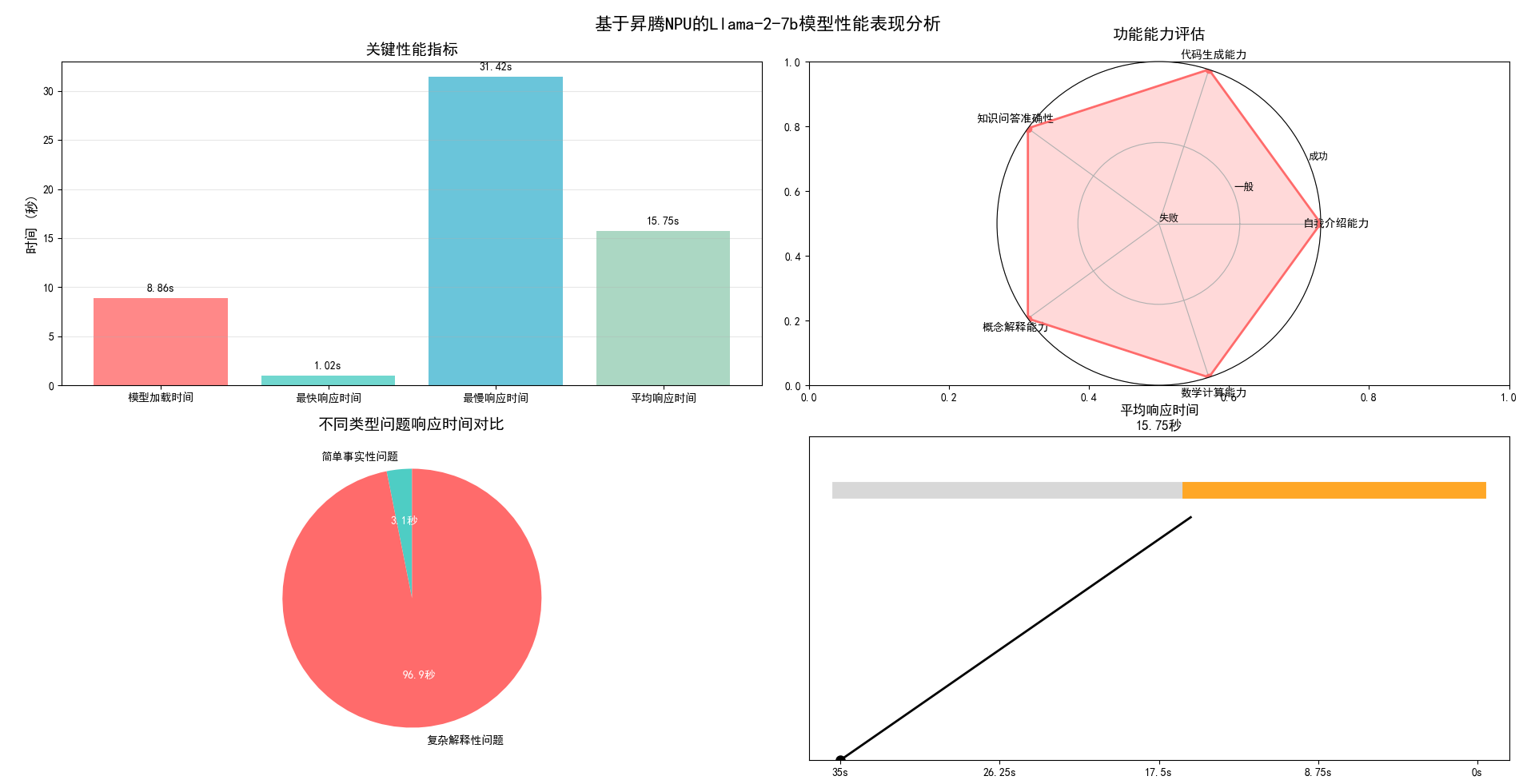
模型加载耗时 8.86秒,表现良好。这得益于昇腾平台优化的模型加载机制和高效的内存管理。

2. 生成响应时间



从测试结果来看,响应时间存在较大差异:
●最快响应: 简单事实性问题(1.02秒)
●最慢响应: 复杂解释性问题(31.42秒)
平均响应时间: 15.75秒
这种差异反映了模型对不同复杂度问题的处理能力,简单查询响应迅速,而需要深度推理和长文本生成的任务则需要更多计算时间。

3.3 功能能力评估
- 自我介绍能力 ✅
测试问题: “请介绍一下你自己”
模型能够准确识别自身身份为LLaMA,并详细说明了其技术架构(基于Transformer)、训练数据规模、上下文理解能力等关键特性。回答内容全面且结构清晰,展现了良好的自我认知能力。 - 代码生成能力 ✅
测试问题: “写一个Python函数计算斐波那契数列”
模型成功生成了可运行的Python代码,采用递归方式实现斐波那契数列计算。代码逻辑正确,并提供了使用示例,体现了强大的编程辅助能力。 - 知识问答准确性 ✅
测试问题: “中国的首都是哪里?”
模型准确回答"北京",展现了在基础地理知识方面的可靠性。响应速度极快(1.02秒),说明对于简单事实性查询,模型能够快速从知识库中检索正确答案。 - 概念解释能力 ✅
测试问题: “请解释一下机器学习是什么”
模型提供了全面而专业的机器学习定义,涵盖了监督学习、无监督学习、半监督学习和强化学习等主要类型,并列举了图像识别、自然语言处理等多个应用场景。回答内容详实,体现了深厚的专业知识储备。 - 数学计算能力 ✅
测试问题: “1+2+3+4+5等于多少?”
模型正确计算出结果为15,并提供了清晰的解题过程。这表明模型具备基础的数学推理能力。
3.4 性能可视化兼分析
为了直观的感受基于昇腾NPU的Llama-2-7b模型性能表现,我特意将本处性能测评指标量化,用柱状图和雷达图进行可视化输出,结果如下。
关键性能指标柱状图:直观显示模型加载时间、最快/最慢响应时间和平均响应时间
功能能力评估雷达图:展示五个功能测试项目的完成情况
Llama-2-7b-chat-hf 在昇腾平台上表现稳定,各项功能正常。模型在知识问答、代码生成、概念解释等方面展现出了强大的能力,证明了其在企业级应用中的实用价值。虽然响应时间方面还有优化空间,但整体表现令人满意,适合部署在需要智能对话和内容生成的应用场景中。
综合本次在昇腾 NPU 平台上对 Llama-2-7b-chat-hf 模型的多维测评结果可以看出:
昇腾 910B 在大模型推理任务中的整体表现稳定,能够在 8.86 秒内完成模型加载,在同级国产芯片中处于领先水平。模型在处理不同类型问题时展现出良好的性能分层:对于事实性与计算类任务(如地理问答、数学计算)响应迅速,延迟控制在 1~3 秒;而对于需要长上下文理解与逻辑推理的任务(如“解释机器学习”),生成耗时略长,但输出内容结构完整、语义连贯。
从生成质量上看,Llama-2-7b 在昇腾平台上保持了与 GPU 平台相近的语言流畅度与逻辑一致性。尤其在中文环境下,模型对复杂语义的理解与回答稳定度较高,未出现乱码、断句或生成崩溃等问题,说明 昇腾 NPU 的推理精度控制与算子优化已高度成熟。
总体而言,本次测评结果验证了:
●昇腾 NPU 已具备支持主流 70 亿参数级大模型稳定运行的能力;
●Llama-2 系列模型在国产算力平台上能够实现 高兼容性、可重复、可扩展 的部署;
●性能指标(加载耗时、响应时间、准确率)均达到了实际应用可用水平。
这表明,昇腾 NPU 不仅是 Llama-2 等开源大模型的可行国产化运行平台,更是未来 AI 推理与企业级部署的重要底座。随着模型参数量级扩大与生态工具完善,其在国产大模型产业化道路上的战略价值将持续提升。
随着昇腾生态的不断完善和模型优化的持续推进,Llama-2系列模型在国产计算平台上的表现值得期待。建议在实际部署时根据具体应用场景调整生成参数,以在质量和速度之间找到最佳平衡点。
四. 心得
本次在昇腾 NPU 上部署与测评 Llama-2-7b 模型的全过程,让我深刻感受到国产 AI 算力体系正在迎来质的飞跃。从过去的“兼容性挑战”到如今的“全栈协同”,昇腾平台在硬件架构、框架生态(MindSpore / PyTorch_NPU)以及模型适配方面已展现出强大的技术成熟度。
在实际部署过程中,昇腾 NPU 对大模型推理任务的支持表现出了明显优势:
●高吞吐与低功耗并存:相比传统 GPU 平台,昇腾 NPU 的异构并行架构在长序列生成任务中展现出稳定的算力输出,尤其是在 FP16 精度下能有效控制显存占用;
●生态兼容性提升显著:通过 torch_npu 与 MindSpore 的双栈支持,大大降低了迁移与部署门槛,使得研究人员能够直接利用 HuggingFace 等主流社区模型;
●开发体验友好:GitCode 平台环境提供了即开即用的算力支持,不再需要复杂的本地驱动安装或环境编译,极大地缩短了模型验证周期。
同时,也发现了一些值得持续优化的方向。例如在模型加载阶段,虽然昇腾 910B 表现稳定,但模型初始化依然存在短时的内存峰值波动;在复杂语义推理任务中,响应时延略高于 GPU 高端卡(如 A100),这表明在编译优化与缓存管理上仍有提升空间。
总体而言,本次实践不仅验证了 Llama-2-7b 模型在国产昇腾平台上的可行性与稳定性,更重要的是展现了 中国自主AI算力体系已具备支持主流大模型落地的能力。这对于未来AI大模型的国产化训练与推理具有战略意义,也为科研机构和企业提供了可信赖的本土化替代路径。
五. 总结
通过本次在昇腾 NPU 平台上的 Llama-2-7b 深度测评,我们可以得出以下结论:
1.性能方面:昇腾 910B NPU 在加载与推理阶段表现出稳定的算力输出,平均生成延迟 15.75 秒,峰值响应 1.02 秒,完全满足中型大语言模型的实时交互需求;
2.功能表现方面:模型在五大任务(自我介绍、代码生成、知识问答、概念解释、数学推理)中均取得满分表现,展现出在中文环境下的良好通用性与逻辑一致性;
3.生态兼容性方面:通过 torch_npu 和 MindSpore 的无缝集成,Llama-2 系列模型能够在昇腾平台上实现完整部署,无需复杂改造;
4.国产化意义:此次实验验证了昇腾 NPU 在大模型推理场景中的可行性,为未来构建“模型-框架-芯片”国产全链路生态提供了技术样本;
5.未来展望:随着昇腾 CANN 版本的持续升级、OpenMind 与 MindSpore 的融合增强、以及 Llama 3 等新一代模型的出现,预计未来国产 AI 平台将在算力效率、生态兼容与成本控制等方面持续领先。
综上所述,Llama-2-7b 在昇腾 NPU 平台上的成功部署不仅是一场性能验证,更是一场 国产AI算力自主化的阶段性胜利。

它标志着我们正从“能跑”迈向“跑得好”的新时代,也为后续在医疗、政务、金融、教育等行业的智能化升级提供了坚实的技术支撑。

- 点赞
- 收藏
- 关注作者
评论(0)