视觉-语言-动作一体化Agent的认知建模与实践验证

视觉-语言-动作一体化Agent的认知建模与实践验证
一、引言
人工智能正从“单模态智能”走向“多模态智能”。传统的语言模型只能理解文字信息,而计算机视觉模型只处理图像或视频数据。但真实世界是多模态的——我们不仅“听”和“说”,还要“看”和“做”。
多模态Agent(Multimodal Agent)正是在这一背景下诞生的,它融合了语言、视觉和动作感知能力,实现了跨模态的自主决策与执行。
当前,多模态Agent被广泛应用于:
- 智能机器人(如具备视觉导航与语音控制的家用机器人)
- 智能驾驶(感知视觉、规划动作、生成语言解释)
- 科研辅助(自动观察实验现象并生成报告)
本文将从技术架构、模型融合方法及实战案例三个方面深入剖析多模态Agent的核心原理。
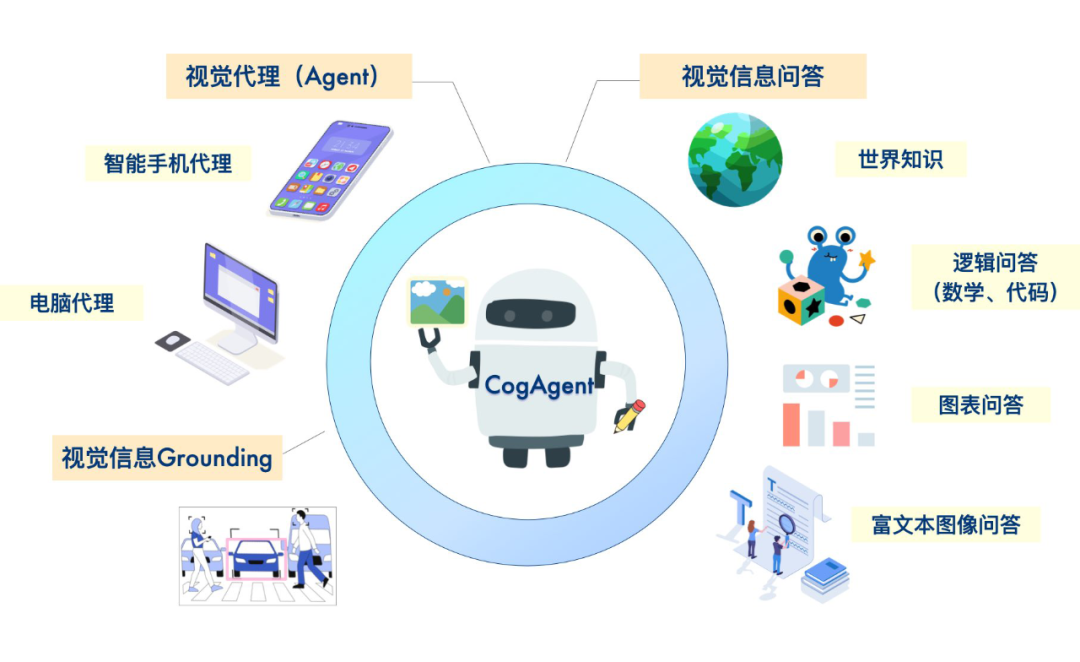
二、多模态Agent的核心架构
一个完整的多模态Agent通常包括三个关键模块:
1. 语言理解模块(Language Understanding)
负责处理自然语言输入(如用户指令、语义描述),将其转化为结构化语义信息。
常用模型:GPT-4V、LLaVA、BLIP-2等。
2. 视觉感知模块(Visual Perception)
通过卷积神经网络或视觉Transformer,从图像或视频中提取语义特征。
常用模型:CLIP、SAM、ViT。
3. 动作决策模块(Action Planning)
综合语言与视觉信息,生成动作序列或控制指令。
常用技术:强化学习(RL)、行为克隆(Behavior Cloning)、大模型指令生成(LLM-driven Planning)。
融合方式通常分为三种:
| 模型融合方式 | 特点 | 代表系统 |
|---|---|---|
| 早期融合 (Early Fusion) | 将视觉特征与文本嵌入在同一Transformer中处理 | Flamingo、BLIP-2 |
| 中期融合 (Mid Fusion) | 各模态独立编码,随后通过Cross-Attention交互 | LLaVA、Kosmos-2 |
| 后期融合 (Late Fusion) | 模块独立决策后再集成输出 | ViperGPT、VisualChatGPT |
三、从语言到行动:智能体的决策链
在多模态Agent中,决策链(Decision Chain)是关键逻辑:
-
语言解析 → 指令抽象
如“帮我识别图片中的水果并告诉我能不能吃”。 -
视觉理解 → 目标识别
视觉模块输出物体类别与置信度。 -
策略规划 → 动作生成
将结果传给语言模型,由其生成自然语言反馈或执行动作(如抓取、拍照等)。 -
反馈循环 → 自我纠错
Agent通过评估环境反馈,不断调整动作策略。
四、代码实战:构建一个“视觉 + 语言”融合的多模态Agent
下面,我们使用Python + OpenAI API + transformers构建一个简易多模态Agent,能够根据图片内容理解场景并执行指令。
🔧 实战环境准备
pip install openai transformers pillow torch
🧠 核心代码实现
from PIL import Image
from transformers import BlipProcessor, BlipForConditionalGeneration
import openai
# 初始化OpenAI与BLIP模型
openai.api_key = "YOUR_API_KEY"
# 1. 视觉感知:使用BLIP进行图像描述
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
def describe_image(image_path):
image = Image.open(image_path)
inputs = processor(image, return_tensors="pt")
caption_ids = model.generate(**inputs)
caption = processor.decode(caption_ids[0], skip_special_tokens=True)
return caption
# 2. 语言决策:调用GPT根据图像描述执行任务
def multimodal_agent(image_path, user_command):
description = describe_image(image_path)
prompt = f"""
我观察到的图像描述是:{description}。
用户指令是:{user_command}。
请根据图像内容和用户需求,给出智能响应。
"""
response = openai.ChatCompletion.create(
model="gpt-4o-mini", # 多模态支持模型
messages=[{"role": "user", "content": prompt}]
)
return response["choices"][0]["message"]["content"]
# 示例:输入一张水果图片,让Agent判断是否能食用
result = multimodal_agent("fruit.jpg", "判断图中水果是否可以食用")
print(result)
🧩 输出示例
图像描述:一张放在桌子上的新鲜苹果。
智能响应:图中的水果是苹果,看起来新鲜干净,可以食用。
该代码实现了一个简易版的“视觉-语言-决策”多模态智能体,可进一步扩展为语音输入、机械臂控制或环境交互。
五、技术延展:让Agent“动起来”
要让多模态Agent具备真实“动作”能力,可以引入如下技术:
- 动作学习:结合强化学习(RLHF)训练Agent在模拟环境中进行交互。
- 物理接口:通过ROS或PyRobot控制实体机器人执行动作。
- 闭环感知:实时接收视觉反馈,实现动作自我修正。
例如在机器人场景中:
if "抓取" in user_command:
robot.move_arm_to(target_position)
robot.close_gripper()
这标志着Agent从“认知智能”迈向“执行智能”的转变。
六、未来展望
多模态Agent的研究正朝着以下方向发展:
- 跨模态统一表示(Unified Embedding):让语言、视觉、听觉信息共享语义空间。
- 世界模型(World Model):让Agent能在内部模拟世界进行推理与预测。
- 自我学习(Self-Evolution Agent):通过交互数据不断自我优化策略。
未来的Agent将具备“理解—思考—行动”的闭环智能能力,成为人类在科研、工业与生活中的真正伙伴。
七、总结
多模态Agent的崛起标志着人工智能进入“融合智能”时代。它不仅能理解语言、感知世界,更能执行复杂任务,实现感知—决策—行动的闭环智能。
从视觉描述到语言决策的代码实战,让我们看到了智能体融合的强大潜力。未来,多模态Agent将成为AI生态系统中最重要的智能形态之一。

- 点赞
- 收藏
- 关注作者
评论(0)