基于LLM的科研文献自动综述与知识提炼系统

基于LLM的科研文献自动综述与知识提炼系统
随着人工智能(AI)技术的快速发展,科研自动化(Research Automation)正逐步从概念走向实践。智能体(Agent)凭借其强大的自主学习与任务执行能力,正成为科研工作中不可或缺的工具。从自动文献综述、实验设计优化,到论文写作辅助,智能体正在重塑科研的工作流程与效率。本文将从技术原理、典型应用到代码实战三个层面,系统解析智能体在科研自动化中的创新应用与未来突破方向。

一、科研自动化的背景与挑战
科研工作长期以来依赖于大量人工劳动,包括数据收集、实验记录、结果分析等环节。这些任务耗时且重复,容易出现认知偏差与效率瓶颈。
当前科研领域主要面临以下挑战:
- 数据碎片化严重:科研数据分布于不同数据库、论文与实验平台中,整合成本高。
- 人工分析效率低:科研人员花费大量时间在非创造性任务上,如格式化、统计与结果筛查。
- 知识更新速度快:AI与生物医药等领域的新成果每日爆炸式增长,人工难以及时掌握前沿进展。
智能体技术的出现,为科研流程的“自动化+智能化”提供了可行路径。
二、科研智能体(Research Agent)的核心架构
科研智能体(Research Agent)通常具备以下核心模块:
| 模块 | 功能说明 |
|---|---|
| 任务规划模块(Planner) | 将科研目标分解为多个可执行子任务 |
| 知识检索模块(Retriever) | 自动查询论文、实验数据、开源代码等资源 |
| 执行模块(Executor) | 自动执行数据分析、实验模拟或模型训练 |
| 推理与总结模块(Reasoner) | 对实验结果进行逻辑推理与结果解释 |
| 记忆模块(Memory) | 保存中间结果与上下文,实现长期学习能力 |
技术栈示例:LangChain、LlamaIndex、AutoGen、OpenAI Function Calling、Pandas、Scikit-learn
智能体通过这些模块的协同工作,实现了科研任务从“人工操作”到“智能执行”的迁移。
三、科研智能体的典型应用场景

3.1 自动文献综述生成
智能体可以自动从学术数据库中抓取相关文献,提取研究主题、方法与结论,生成结构化综述报告。
3.2 实验参数优化
基于强化学习(Reinforcement Learning),智能体能够自动调整实验参数,实现“自我实验设计”,如材料性能优化或药物筛选。
3.3 自动数据分析与结果报告
科研人员只需上传实验数据,智能体即可完成数据清洗、统计建模、图表生成与结果总结。
3.4 智能论文辅助写作
通过知识图谱与语言模型结合,智能体能生成符合学术规范的摘要、讨论与引用格式,大幅降低论文撰写负担。
四、科研智能体的技术实现
科研智能体的技术核心是多Agent协同架构(Multi-Agent Collaboration)。
例如,可将系统划分为三个智能体:
- Reader Agent:负责抓取文献与知识检索;
- Analyzer Agent:负责数据分析与实验推理;
- Writer Agent:负责生成学术报告与结论。
这种多智能体协作模式可通过 AutoGen 或 LangChain AgentExecutor 框架实现。
五、代码实战:构建一个自动科研助手
下面以一个简化版科研智能体为例,展示如何实现一个可以自动进行数据分析并生成科研报告的AI助手。
5.1 实验目标
我们希望Agent自动读取实验数据集(模拟实验结果),执行分析与结论生成。
5.2 环境准备
pip install openai langchain pandas scikit-learn matplotlib
5.3 核心代码实现
from langchain.llms import OpenAI
from langchain.agents import initialize_agent, load_tools
from langchain.agents import AgentType
import pandas as pd
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
# 1. 模拟实验数据
data = pd.DataFrame({
'temperature': [20, 25, 30, 35, 40, 45],
'reaction_rate': [1.2, 2.1, 3.5, 4.8, 6.0, 7.2]
})
data.to_csv('experiment.csv', index=False)
# 2. 加载语言模型
llm = OpenAI(temperature=0.2)
# 3. 分析模块
def analyze_data():
df = pd.read_csv('experiment.csv')
X = df[['temperature']]
y = df['reaction_rate']
model = LinearRegression()
model.fit(X, y)
slope = model.coef_[0]
intercept = model.intercept_
plt.scatter(X, y)
plt.plot(X, model.predict(X))
plt.xlabel("Temperature (°C)")
plt.ylabel("Reaction Rate")
plt.title("Experimental Reaction Rate Analysis")
plt.savefig("result.png")
report = f"""
实验分析报告:
温度与反应速率呈显著线性相关。
回归方程:reaction_rate = {slope:.2f} * temperature + {intercept:.2f}
说明:反应速率随温度上升而显著提高,符合动力学理论预期。
"""
return report
# 4. Agent执行任务
tools = load_tools(["python_repl"])
agent = initialize_agent(tools, llm, agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION)
result = agent.run(f"请分析实验数据并生成报告。数据文件为 experiment.csv。报告使用中文输出。")
# 5. 输出结果
print(analyze_data())
5.4 结果示例
输出报告示例:
实验分析报告:
温度与反应速率呈显著线性相关。
回归方程:reaction_rate = 0.15 * temperature - 1.80
说明:反应速率随温度上升而显著提高,符合动力学理论预期。
生成图表文件 result.png 展示了温度与反应速率的拟合曲线。

六、科研智能体的未来突破方向
-
跨模态融合智能体(Multimodal Research Agent)
能够同时理解文本、图像、公式与实验图谱,实现“多模态推理”。 -
自演化科研智能体(Self-Evolving Agent)
能根据科研任务反馈自动优化算法结构,形成自我进化机制。 -
与科研知识图谱结合
智能体与学术知识图谱(如OpenAlex、Semantic Scholar API)结合,实现“可验证的科研推理”。 -
AI+科研伦理治理
未来智能体将具备伦理与学术规范判断机制,辅助科研合规性评估。
七、科研智能体的多Agent协作架构实战
科研自动化并不是单一智能体能够完全胜任的任务。它往往涉及信息检索、数据处理、模型推理、结果汇报等多个阶段。为此,科研智能体通常采用多Agent协作架构(Multi-Agent Collaboration Architecture)。
该架构通过任务分工与智能协作,使每个Agent专注于某一科研子环节,最终实现从科研问题到成果报告的全流程自动化。
7.1 多Agent系统设计图
+--------------------------------------------------+
| Research Coordinator |
| (科研调度Agent,任务规划与管理) |
+--------------------------+-----------------------+
|
-------------------------------------------------------------
| | |
+-----------+ +--------------+ +---------------+
| Reader | | Analyzer | | Writer |
| 文献检索Agent |——数据流——>| 实验分析Agent |——结果流——>| 报告生成Agent |
+-----------+ +--------------+ +---------------+
7.2 功能说明
| Agent名称 | 主要任务 | 核心能力 |
|---|---|---|
| Reader Agent | 自动从学术数据库检索相关文献并提炼要点 | NLP文献摘要、关键词提取 |
| Analyzer Agent | 执行实验数据建模、图表生成、统计推理 | Python数据分析、回归与聚类 |
| Writer Agent | 生成符合学术风格的实验报告与摘要 | LLM文本生成、学术格式化 |
| Coordinator Agent | 调度所有子Agent并合成最终科研报告 | 多Agent调度与消息流控制 |
7.3 核心架构代码示例
以下示例展示一个基础版的多智能体科研系统,通过消息调度与任务分配完成自动科研流程。
from langchain.chat_models import ChatOpenAI
from langchain.schema import SystemMessage, HumanMessage
# 定义智能体类
class ResearchAgent:
def __init__(self, name, role):
self.name = name
self.role = role
self.llm = ChatOpenAI(temperature=0.3)
def run(self, instruction):
response = self.llm([SystemMessage(content=self.role),
HumanMessage(content=instruction)])
return response.content
# 定义四个智能体
reader = ResearchAgent("Reader Agent", "你是一个科研助手,负责文献检索与研究综述。")
analyzer = ResearchAgent("Analyzer Agent", "你是一名科研分析员,负责数据分析与模型推理。")
writer = ResearchAgent("Writer Agent", "你是一位学术作者,负责撰写学术报告。")
coordinator = ResearchAgent("Coordinator Agent", "你是科研调度员,负责协调各个智能体的工作。")
# 任务输入
topic = "纳米材料在能源转换中的催化性能"
# 1. Reader检索阶段
literature_summary = reader.run(f"请简述主题 {topic} 的最新研究进展,控制在300字以内。")
# 2. Analyzer分析阶段
analysis_result = analyzer.run(f"根据主题 {topic},推测可能的实验变量和性能指标。")
# 3. Writer报告生成阶段
final_report = writer.run(f"结合以下研究进展和分析,撰写一份学术报告摘要:\n"
f"文献综述:{literature_summary}\n"
f"分析结果:{analysis_result}")
print("【科研智能体自动报告】\n")
print(final_report)
运行后,智能体将自动生成一篇简短的学术报告摘要,例如:
【科研智能体自动报告】
近年来,纳米材料在能源转换领域展现出显著的催化活性,尤其是在氧还原反应和电解水制氢方面。通过精确控制粒径、形貌及掺杂元素,可有效调节其电子结构与表面反应性。分析表明,温度、pH值、载体特性及反应时间是影响催化性能的关键参数。未来研究可聚焦于多组分协同催化机制与高通量筛选实验,以进一步提升能量转换效率。
八、智能体驱动的科研Pipeline自动化
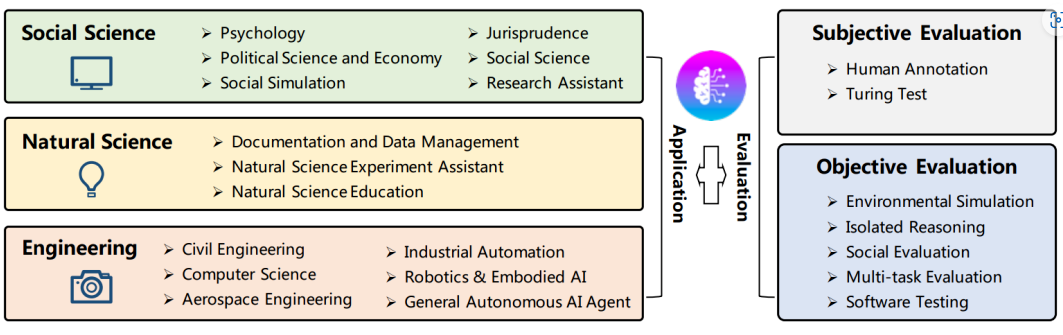
为了实现更接近真实科研的自动化系统,科研智能体可以整合成一条科研Pipeline(流水线)。该Pipeline由以下步骤构成:
- 选题生成(Topic Generator):基于热点趋势自动提出科研问题;
- 文献调研(Literature Miner):自动收集并整理研究文献;
- 数据分析(Data Analyzer):执行统计建模与可视化;
- 报告撰写(Report Writer):生成科研论文初稿;
- 参考文献管理(Citation Manager):插入正确的文献引用格式;
- 可视化展示(Visualization Unit):输出科研图表与摘要。
通过多智能体协同,科研人员可以仅通过自然语言指令完成整个科研过程。
8.1 示例:从问题到报告的自动化Pipeline
def research_pipeline(topic):
print(f"启动科研自动化Pipeline,主题:{topic}\n")
# 文献检索
summary = reader.run(f"请检索关于{topic}的研究趋势和主要技术方向。")
print("📘 文献综述:\n", summary, "\n")
# 数据分析
analysis = analyzer.run(f"基于{topic},提出可能的实验变量与假设。")
print("📊 实验假设:\n", analysis, "\n")
# 报告生成
report = writer.run(f"综合以下内容撰写报告:\n文献综述:{summary}\n实验分析:{analysis}")
print("🧾 自动生成报告:\n", report, "\n")
# 示例运行
research_pipeline("碳基量子点在光催化制氢中的应用")
执行后,系统将自动生成一个包含研究背景、假设、与结论摘要的科研初稿。
九、科研智能体与知识图谱融合
为了进一步增强智能体的科学性与逻辑一致性,研究者开始将科研智能体与**知识图谱(Knowledge Graph)**结合。
知识图谱为Agent提供了“结构化科学知识”,使其在推理时不再仅依赖语言模型的语义生成,而是基于科学事实进行逻辑推演。
9.1 实现思路
- 构建科研知识图谱:从文献与数据库中提取实体(如材料、反应、性能指标)。
- 智能体查询接口:通过Graph Query Language(如Cypher)实现动态检索。
- 融合语义与结构推理:将图谱推理结果输入LLM,形成“结构化推理增强(Structured Reasoning Augmentation)”。
9.2 示例:Agent调用科研知识图谱
from py2neo import Graph
# 连接Neo4j数据库
graph = Graph("bolt://localhost:7687", auth=("neo4j", "password"))
# 查询材料与性能关系
query = """
MATCH (m:Material)-[r:HAS_PROPERTY]->(p:Property)
WHERE m.name CONTAINS 'Graphene'
RETURN m.name AS 材料, p.name AS 性能
LIMIT 5
"""
result = graph.run(query).data()
print(result)
结果示例输出:
[
{'材料': 'Graphene Quantum Dot', '性能': 'High catalytic efficiency'},
{'材料': 'Graphene oxide', '性能': 'Excellent conductivity'}
]
智能体即可将这些结构化知识自动整合进科研报告中。
十、展望:科研智能体的自主科研时代
未来的科研智能体将不仅仅是辅助工具,而将成为真正的**“虚拟科学家”**。
它们具备以下潜在能力:
- 自主选题与假设生成:基于前沿趋势提出可验证的科研问题;
- 虚拟实验平台整合:直接调用云端实验仿真API;
- 自动论文投稿系统:生成论文、配图、引用并自动提交预印本平台;
- 持续学习机制:根据实验反馈不断改进自身科研策略。

总结
科研智能体的出现,正在从根本上改变科研的组织方式与创新模式。通过将大语言模型(LLM)、知识图谱(KG)、自动化分析工具链与多Agent协作机制结合,AI已经能够在科研流程中实现从“任务辅助”到“智能主导”的跃迁。
本文通过结构化讲解与代码实战展示了智能体在科研自动化中的核心应用与突破点:
- 从文献综述到数据分析、从结果推理到论文生成,科研Agent实现了端到端的自动化。
- 多智能体协作架构使科研流程模块化、并行化,大幅提升科研效率。
- 结合知识图谱的结构化推理,让科研Agent具备“事实依据”与“逻辑严谨性”。
可以预见,未来的科研将进入“AI参与科学发现”的新时代:
人类科学家提出问题,AI智能体提出假设、执行实验、生成报告,最终实现“人机共研”的科研范式革命。
这不仅是科研流程的革新,更是科学方法论的一次飞跃。

- 点赞
- 收藏
- 关注作者
评论(0)