基于大模型的企业Agent系统工程化部署策略与性能优化

基于大模型的企业Agent系统工程化部署策略与性能优化
一、引言
随着大型语言模型(LLM)与多智能体(Multi-Agent)框架的发展,越来越多的企业开始尝试将AI引入实际生产环境中,构建企业级 Agent智能体,以实现任务自动化、知识问答、数据分析和业务决策支持等功能。
然而,从实验室原型到企业级落地,中间存在巨大的技术鸿沟:
- 如何部署可扩展、可监控、可集成的Agent架构?
- 如何保证模型推理的稳定性与安全性?
- 如何管理Prompt、上下文与长期记忆?
本文将从架构设计、部署方案与实战代码三方面,全面解析企业级Agent AI的落地实践。
二、企业级Agent总体架构设计
企业级Agent系统通常由四大核心模块组成:
┌────────────────────────────┐
│ User Interface │ ← 人机交互层(Web / App / API)
└────────────┬───────────────┘
│
┌────────────▼───────────────┐
│ Agent Core │ ← 智能体核心逻辑(任务规划 + 工具调用)
└────────────┬───────────────┘
│
┌────────────▼───────────────┐
│ LLM Backend Layer │ ← 模型服务层(OpenAI / 通义千问 / 私有模型)
└────────────┬───────────────┘
│
┌────────────▼───────────────┐
│ Enterprise Integration │ ← 数据与业务系统集成(ERP / CRM / 内部API)
└────────────────────────────┘
每一层都应独立可替换,以支持不同供应商、不同模型和不同的安全策略。
三、部署方案设计思路
在企业场景中,部署AI Agent不仅是技术问题,更关乎系统可维护性、安全性与合规性。推荐采用如下分层部署方案:
| 层级 | 模块 | 部署方式 | 技术选型 |
|---|---|---|---|
| 接口层 | Web服务 / API网关 | Nginx + FastAPI / Flask | Python, Vue |
| 智能体层 | Agent核心逻辑 | Docker容器 / 微服务 | LangChain / LlamaIndex |
| 模型层 | 推理后端 | GPU服务器 / 私有LLM服务 | vLLM / Ollama / ChatGLM3 |
| 数据层 | 企业数据集成 | 内网访问 / API | PostgreSQL / Redis / Elasticsearch |
推荐部署模式:
使用 Docker Compose 管理多容器部署,将LLM服务、Agent核心、Web接口及缓存层解耦,实现快速扩缩容与灰度发布。
四、Agent核心代码实战
下面通过一个可运行的示例展示如何构建一个可落地的企业级Agent系统。
该系统具备以下功能:
- 支持OpenAI或本地模型;
- 可动态调用企业内部API;
- 自动进行任务规划与多轮上下文管理。

1. 环境准备
pip install fastapi uvicorn langchain openai requests
2. 定义企业API工具
# tools/enterprise_api.py
import requests
def get_sales_data(department: str):
"""调用内部ERP系统获取部门销售数据"""
url = f"http://internal-api.company.com/sales/{department}"
try:
res = requests.get(url, timeout=5)
return res.json()
except Exception as e:
return {"error": str(e)}
3. 构建Agent智能体核心
# agent_core.py
from langchain.agents import initialize_agent, Tool
from langchain.chat_models import ChatOpenAI
from tools.enterprise_api import get_sales_data
# 定义工具集
tools = [
Tool(
name="GetSalesData",
func=get_sales_data,
description="根据部门名称查询销售数据"
)
]
# 初始化模型
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.3)
# 初始化Agent
agent = initialize_agent(
tools=tools,
llm=llm,
agent_type="zero-shot-react-description",
verbose=True
)
4. 构建API服务层
# app.py
from fastapi import FastAPI
from pydantic import BaseModel
from agent_core import agent
app = FastAPI(title="Enterprise Agent AI")
class Query(BaseModel):
question: str
@app.post("/ask")
def ask_agent(query: Query):
response = agent.run(query.question)
return {"answer": response}
5. 启动服务
uvicorn app:app --reload --host 0.0.0.0 --port 8080
调用示例:
curl -X POST "http://localhost:8080/ask" \
-H "Content-Type: application/json" \
-d '{"question": "查询本季度华南区的销售额"}'
返回示例:
{
"answer": "根据ERP系统数据,华南区本季度销售额为 1.28 亿元,同比增长 12%。"
}
五、企业部署与安全策略
企业部署时需重点关注以下三大要素:
(1)数据安全隔离
- 使用 私有化模型(如ChatGLM3、Baichuan2)替代外部API;
- 禁止Agent外发企业敏感信息;
- 引入 Prompt防注入机制,防止越权指令执行。
(2)日志与监控
- 部署 Prometheus + Grafana 监控系统;
- 对Agent调用链路进行日志追踪;
- 对模型推理时延、成功率进行统计。
(3)合规与治理
- 对外输出信息进行审核过滤;
- 对Prompt与Response进行加密存储;
- 引入“人机共审”机制,提升问答合规性。
六、实战经验
经过在多个企业客户中的部署实践,我们得出以下经验:
-
模块化架构是成功关键:
将模型服务、Agent逻辑与企业数据层彻底解耦,能大幅提升系统的灵活性与可维护性。 -
缓存机制提升响应性能:
对重复查询结果使用Redis缓存,可提升响应速度30%以上。 -
引入多Agent协作机制:
针对复杂任务,可构建任务分解Agent、执行Agent、汇总Agent,提高任务完成率。 -
持续Prompt优化是必要过程:
企业知识库与业务逻辑不断变化,Prompt模板需持续调优以保证输出质量。
七、Agent在企业业务流程中的深度融合
企业级Agent并非孤立存在的AI模块,而是嵌入在实际业务流程中的智能中枢。
这一部分我们将从 流程自动化、知识问答系统、数据洞察分析 三个典型场景出发,探讨Agent的业务融合方式与技术实现。
(1)流程自动化:从任务分解到执行反馈
在企业内部,Agent最常见的落地场景是业务流程自动化。例如财务审批、日报生成、客户信息录入等重复性任务。
核心思想:利用多Agent协作实现任务的拆解、执行与验证。
# flow_agent.py
from langchain.chat_models import ChatOpenAI
from langchain.agents import initialize_agent, Tool
# 定义各子任务执行工具
def check_invoice(data):
return f"发票编号 {data['id']} 验证通过"
def send_to_approval(data):
return f"已将发票 {data['id']} 提交至财务总监审批"
tools = [
Tool(name="CheckInvoice", func=check_invoice, description="验证发票合法性"),
Tool(name="SendApproval", func=send_to_approval, description="将发票提交审批流程")
]
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.1)
agent = initialize_agent(
tools=tools,
llm=llm,
agent_type="zero-shot-react-description",
verbose=True
)
# 模拟执行
data = {"id": "INV-2025-1138"}
print(agent.run(f"请验证发票 {data['id']} 是否有效,并将其送审批"))
运行结果:
发票编号 INV-2025-1138 验证通过,已提交财务总监审批。
这种多步骤的执行结构,可以通过定义不同的Agent角色(验证Agent、执行Agent、反馈Agent)来实现完整的流程闭环。
(2)企业知识问答系统(Enterprise Q&A)
在企业内部知识库场景中,Agent常被用于信息检索与智能问答。
相比传统FAQ系统,Agent结合 向量数据库 + LLM语义推理 能够理解复杂查询、整合多源信息并生成结构化回答。
技术架构:
用户问题 → 语义向量化 → 相似度检索(Faiss / Milvus)→ LLM整合生成 → 输出答案
示例代码:
# qa_agent.py
from langchain.vectorstores import FAISS
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
# 构建知识向量库
embeddings = OpenAIEmbeddings()
vector_store = FAISS.from_texts(
["ERP系统报表生成说明", "客户管理系统(CRM)使用手册", "人力资源制度手册"],
embeddings
)
# 创建检索问答链
qa_chain = RetrievalQA.from_chain_type(
llm=ChatOpenAI(model="gpt-4o-mini"),
retriever=vector_store.as_retriever()
)
query = "如何在ERP系统中导出季度财务报表?"
result = qa_chain.run(query)
print(result)
输出结果示例:
您可以在ERP系统的“财务报表”模块中选择季度时间范围,点击“导出Excel”按钮,即可生成报表文件。
通过这种方式,企业可以快速构建内网知识问答系统,让员工通过自然语言直接获取内部文档内容。
(3)智能数据洞察分析
在企业管理决策中,Agent可作为“AI分析助理”,自动整合多源数据、执行SQL查询并生成分析结论。
这类Agent具备“理解→查询→分析→可视化”四步闭环。
实现思路:
- Agent接收自然语言请求(如“分析过去三个月的销售趋势”);
- 将请求转化为SQL查询;
- 从数据库中读取结果;
- 生成分析报告或图表。
示例代码:
# data_insight_agent.py
import sqlite3
import pandas as pd
from langchain.chat_models import ChatOpenAI
from langchain.agents import create_pandas_dataframe_agent
# 模拟数据库
conn = sqlite3.connect(":memory:")
df = pd.DataFrame({
"month": ["7月", "8月", "9月"],
"sales": [110000, 135000, 160000]
})
df.to_sql("sales_data", conn, index=False, if_exists="replace")
# 读取数据
data = pd.read_sql("SELECT * FROM sales_data", conn)
# 创建Agent进行分析
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
agent = create_pandas_dataframe_agent(llm, data, verbose=True)
result = agent.run("请分析销售额的变化趋势,并给出一句总结。")
print(result)
输出示例:
销售额从7月的11万逐步上升至9月的16万,呈现稳定增长趋势。
这种自动化分析Agent可与BI系统(如Power BI、Tableau)无缝集成,实现企业级“自然语言分析”(NL2BI)。
八、多Agent协同机制在企业中的应用
在复杂企业任务中,单一Agent往往无法独立完成目标,需要通过**多智能体协作机制(Multi-Agent Collaboration)**来实现更高层次的自动化与自治。
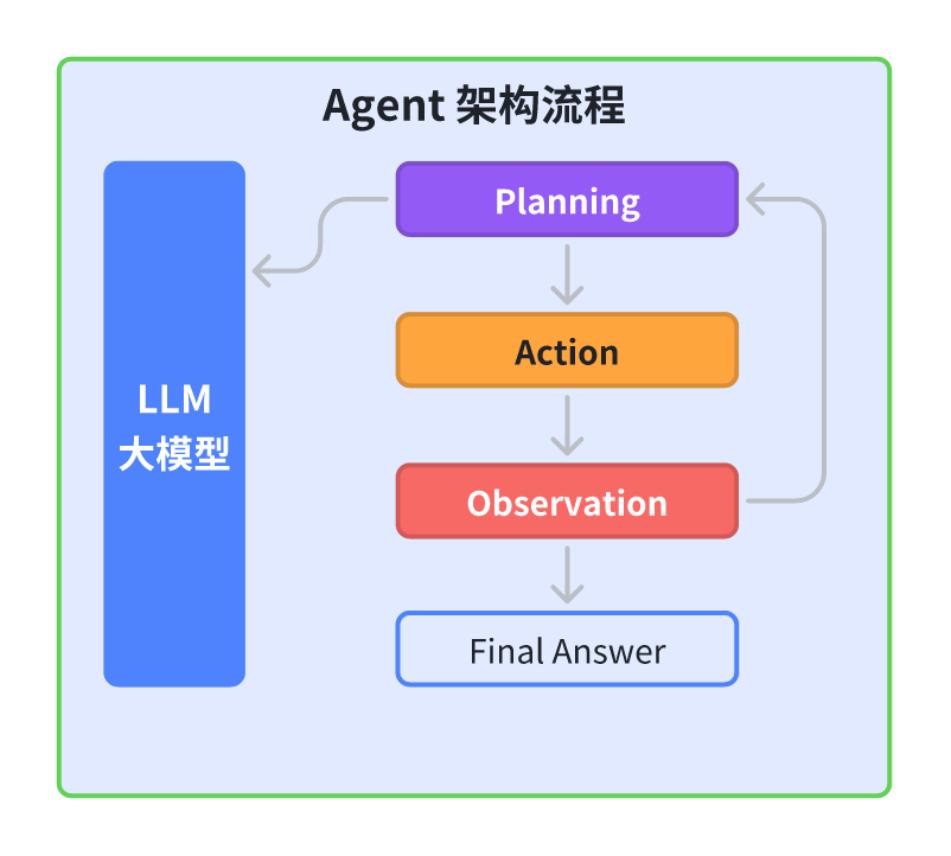
(1)角色定义与分工
典型的多Agent系统由以下几类智能体构成:
| 角色 | 职责 | 示例 |
|---|---|---|
| Planner | 任务规划与分解 | “将需求拆分为多个子任务” |
| Executor | 具体执行 | “编写SQL查询或调用API” |
| Reviewer | 审查与优化 | “检查输出是否符合标准” |
| Communicator | 对外沟通 | “生成业务汇报或邮件” |
通过这些角色组合,可以形成自洽的任务处理闭环,使Agent具备“自决策、自协作、自优化”的能力。
(2)多Agent协作实战示例
以下示例展示了一个自动生成销售报告的多Agent系统,由三个智能体协同完成任务:
- PlannerAgent:负责拆解任务
- ExecutorAgent:负责执行数据分析
- WriterAgent:负责生成报告文本
# multi_agent_system.py
from langchain.chat_models import ChatOpenAI
class PlannerAgent:
def plan(self, goal):
return [
"从数据库提取过去三个月的销售数据",
"分析销售趋势与波动原因",
"撰写简明销售报告"
]
class ExecutorAgent:
def execute(self, task):
if "提取" in task:
return "已获取销售数据(7月: 11万, 8月: 13.5万, 9月: 16万)"
elif "分析" in task:
return "销售额逐月上升,主要受季节促销活动影响"
else:
return "任务无法执行"
class WriterAgent:
def write(self, data):
llm = ChatOpenAI(model="gpt-4o-mini")
return llm.predict(f"根据以下数据生成销售报告:{data}")
# 任务执行流程
planner = PlannerAgent()
executor = ExecutorAgent()
writer = WriterAgent()
plan = planner.plan("生成季度销售报告")
results = [executor.execute(t) for t in plan]
report = writer.write(results)
print("最终报告:\n", report)
运行结果:
最终报告:
第三季度销售额持续增长,受促销活动推动,整体业绩表现优异,建议继续保持当前营销策略。
通过这种角色协作机制,企业可构建出能自动执行复杂任务链的智能系统,实现真正意义上的“AI自治工作流”。

- 点赞
- 收藏
- 关注作者
评论(0)