多智能体系统中的博弈理论与协作机制-集体智能的构建

多智能体系统中的博弈理论与协作机制-集体智能的构建
在人工智能领域,多个智能体(AI Agents)相互协作形成的多智能体系统(MAS)已成为一个重要的研究方向。多智能体协同系统通过模拟复杂系统中的交互,能够更高效地解决一些传统单一智能体无法胜任的任务。本文将从理论和实践两方面探讨多智能体协同系统的基本原理,并通过代码示例展示如何实现一个简单的多智能体协同系统。
一、什么是多智能体协同系统?
1.1 多智能体系统的定义
多智能体系统(MAS)是由多个智能体组成的系统,每个智能体都是一个独立的实体,能够感知环境并作出决策。智能体通过一定的协议和机制相互协作、竞争或共享信息,以达成整体目标。
在多智能体协同系统中,智能体之间的协作可以显著提高系统的整体性能。例如,在智能交通系统中,各个交通信号灯作为独立的智能体,通过协作来减少交通拥堵。
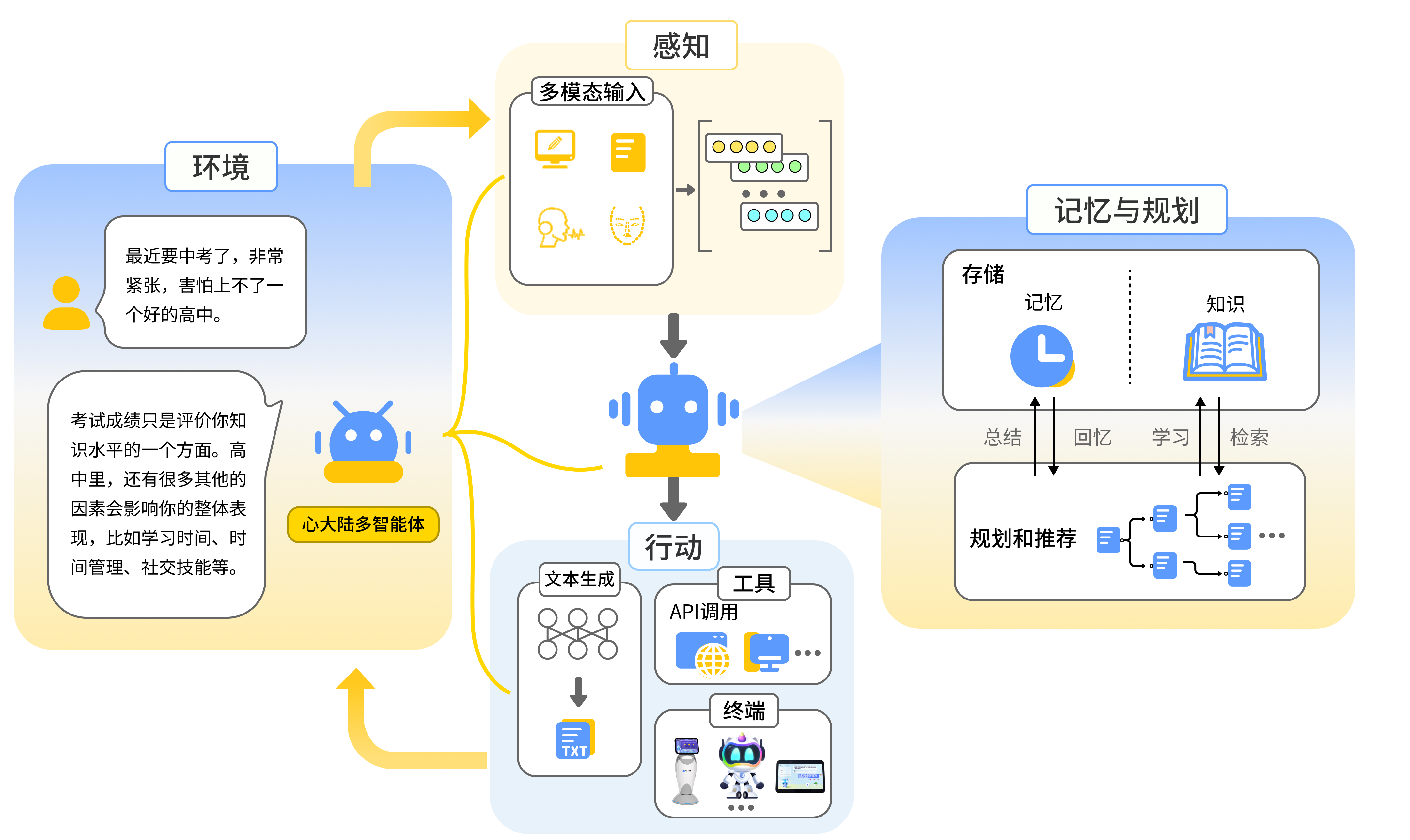
1.2 多智能体协同系统的特点
- 分布性:每个智能体都是独立的,并且可能具有不同的目标。
- 协作性:智能体需要协调工作,以完成一个集体目标。
- 自治性:每个智能体都有独立的决策能力。
- 适应性:智能体能够根据环境变化调整行为。
二、多智能体系统的核心技术
2.1 协同与竞争
在多智能体协同系统中,智能体可能处于合作或竞争状态。合作型智能体共享信息以共同达成目标,而竞争型智能体则可能相互对抗,甚至存在博弈行为。常见的协同机制包括任务分配、信息共享和共同决策等。
2.2 策略学习
多智能体系统中,每个智能体可能有不同的策略。为了实现高效的协同,各智能体需要通过不断地学习来优化策略,常见的学习方法包括:
- 强化学习(RL):通过奖励和惩罚来优化智能体的行为。
- 博弈论:用于研究智能体在竞争和合作中的最优策略。
2.3 任务分配与调度
在多智能体系统中,任务分配是一个重要的问题。合理的任务分配可以有效地提高系统的效率。常见的任务分配方法包括基于拍卖的机制、拍卖博弈模型以及市场机制。
三、代码实战:基于强化学习的多智能体协同
在本节中,我们将通过一个简单的示例来展示如何利用强化学习实现一个多智能体协同系统。假设我们有两个智能体,它们需要协作完成一个目标任务——例如,一个智能体负责寻找目标位置,另一个智能体负责到达并执行任务。
3.1 环境设计
首先,我们需要定义一个简单的环境,这个环境包含两个智能体和一个目标。智能体将通过学习来决定如何移动,以尽可能快地完成任务。
import numpy as np
class MultiAgentEnvironment:
def __init__(self):
self.agent_positions = np.array([0, 0, 0, 0]) # Two agents, initial positions
self.goal = np.array([10, 10]) # Target position
self.done = False
def step(self, actions):
# Update the agent positions based on the actions
self.agent_positions[0] += actions[0]
self.agent_positions[1] += actions[1]
self.agent_positions[2] += actions[2]
self.agent_positions[3] += actions[3]
# Calculate the distance to the goal
distance = np.linalg.norm(self.agent_positions[:2] - self.goal)
# Check if the goal has been reached
if distance < 1:
self.done = True
reward = 10 # Reward for reaching the goal
else:
reward = -distance # Negative reward for being far from the goal
return self.agent_positions, reward, self.done
def reset(self):
self.agent_positions = np.array([0, 0, 0, 0])
self.done = False
return self.agent_positions
3.2 强化学习智能体
接下来,我们需要实现两个智能体的强化学习算法。为简化模型,我们使用Q-learning算法来优化每个智能体的行为。
import random
class QLearningAgent:
def __init__(self, action_space, learning_rate=0.1, discount_factor=0.99, epsilon=0.1):
self.action_space = action_space
self.learning_rate = learning_rate
self.discount_factor = discount_factor
self.epsilon = epsilon
self.q_table = np.zeros((10, 10, len(action_space))) # Q-table for each state-action pair
def choose_action(self, state):
if random.uniform(0, 1) < self.epsilon:
return random.choice(self.action_space)
else:
state_x, state_y = state
return np.argmax(self.q_table[state_x, state_y, :])
def update(self, state, action, reward, next_state):
state_x, state_y = state
next_state_x, next_state_y = next_state
best_next_action = np.argmax(self.q_table[next_state_x, next_state_y, :])
# Update Q-value
self.q_table[state_x, state_y, action] = self.q_table[state_x, state_y, action] + self.learning_rate * (
reward + self.discount_factor * self.q_table[next_state_x, next_state_y, best_next_action] - self.q_table[state_x, state_y, action]
)
3.3 训练过程
在训练过程中,我们将两个智能体的协作通过不断交互来优化。每次通过环境返回的奖励来调整智能体的Q值,从而优化它们的决策。
# 初始化环境和智能体
env = MultiAgentEnvironment()
agent1 = QLearningAgent(action_space=[0, 1, 2]) # Example action space: 0: Left, 1: Right, 2: Stay
agent2 = QLearningAgent(action_space=[0, 1, 2])
# 训练过程
for episode in range(1000):
state = env.reset()
done = False
while not done:
# 两个智能体选择动作
action1 = agent1.choose_action(state[:2]) # Agent 1 chooses action based on its state
action2 = agent2.choose_action(state[2:]) # Agent 2 chooses action based on its state
actions = [action1, action2] # Combine actions for both agents
next_state, reward, done = env.step(actions) # Perform the step in the environment
# 更新智能体的Q表
agent1.update(state[:2], action1, reward, next_state[:2])
agent2.update(state[2:], action2, reward, next_state[2:])
state = next_state # Update the state for the next iteration
四、 多智能体协同系统的应用场景
4.1 智能交通系统
在智能交通领域,多个智能体可以代表不同的交通信号灯、交通监控摄像头、无人驾驶汽车等。它们通过协作来优化交通流量,减少交通拥堵。例如,各个信号灯智能体可以通过交换实时交通数据,调整红绿灯的切换时长,以最优化整个路网的交通效率。
实现思路:
- 任务分配:每个智能体(交通信号灯)根据路口的车流量,自动调整红绿灯时长。
- 信息共享:交通信号灯之间共享交通数据和流量预测,从而协调绿灯周期。
- 决策优化:通过多智能体协同和强化学习,实现最优的交通信号策略。
4.2 无人机群体协同
在无人机(UAV)集群的协作任务中,多智能体系统被广泛应用于无人机编队、巡逻、搜救等任务。每个无人机都作为一个独立的智能体,能够在与其他无人机的协作中完成复杂任务,如目标追踪、区域探索等。
实现思路:
- 状态感知:每个无人机通过传感器获取自身的状态(位置、速度、周围障碍物等)。
- 协作决策:无人机之间通过通信来协调各自的运动轨迹,以避免碰撞并优化任务执行效率。
- 强化学习:使用强化学习算法优化无人机的飞行策略,通过奖励信号来促进合作行为。
4.3 智能制造与工业自动化
在智能制造领域,多个机器人或自动化设备可以作为智能体,通过协作实现高效的生产线管理、库存管理及维护任务。智能体之间通过信息交流和任务协调,可以自动调整工作任务,提升生产效率。
实现思路:
- 任务分配与调度:通过多智能体协同系统,自动化设备根据生产任务的优先级与剩余时间,分配各自的工作负载。
- 实时反馈与调整:设备能够实时反馈工作状态并与其他设备共享数据,及时调整生产流程以应对突发情况。
- 协作与竞争:多台机器人可以协作共同完成复杂任务,或者在竞争情况下合理安排优先级。
五、多智能体协同系统的挑战与未来发展
5.1 持续学习与自适应能力
在多智能体协同系统中,如何让智能体在动态环境中持续学习并适应变化是一个重要挑战。由于智能体可能需要应对复杂的环境变化(如交通流量、无人机任务变化等),如何使其不断优化策略,适应新的任务需求,是系统设计的一个核心难点。
未来方向:
- 增量学习:通过增量学习,智能体可以在实时的环境反馈下不断更新其策略。
- 自适应机制:设计能够自动适应环境变化的机制,如自动调整学习率、选择新的学习策略等。
5.2 安全性与隐私保护
在实际应用中,多个智能体往往需要共享数据,这可能导致隐私泄露和安全问题。例如,在智能交通系统中,各个信号灯或交通监控设备之间的通信可能会暴露车辆的实时位置,造成隐私泄露或恶意攻击。
未来方向:
- 加密通信:通过安全的加密通信协议,确保智能体之间的信号传输不受攻击。
- 隐私保护:设计智能体能够在确保隐私的前提下进行信息共享,避免敏感数据泄露。
5.3 高效的协作机制
随着智能体数量的增多,如何高效地进行任务分配和协调成为一个技术难点。传统的集中式控制方法难以应对大规模系统的需求,分布式协作方法将是未来的趋势。
未来方向:
- 分布式优化:开发能够在去中心化的环境下高效工作的协作机制,智能体之间能够自发地达成最优协作策略。
- 多层次协作:结合低层次的局部协作和高层次的全局规划,以提高协作效率和系统的可扩展性。
六、实际案例分析
6.1 Google DeepMind的AlphaStar
AlphaStar是DeepMind开发的一个多智能体协同系统,专门用于实时策略游戏《星际争霸2》。在这个系统中,多个智能体通过深度强化学习和自我对战来学习游戏的战略技巧。通过大量的游戏对抗,AlphaStar最终超越了职业玩家,在游戏中达到了人类顶级水平。
实现细节:
- 多智能体学习:AlphaStar通过训练多个智能体,模拟真实的对战环境,利用强化学习算法不断优化策略。
- 协作与对抗:每个智能体不仅需要与其他智能体竞争,还要在团队任务中进行协作。
- 自我对抗:智能体通过自我对抗和模拟训练来不断提升其游戏水平,最终通过大量数据积累提高智能体的策略水平。
6.2 智能交通中的多智能体协同
在一些智能城市中,智能交通管理系统采用了多智能体协同系统来优化交通流量。例如,在某些城市的试点项目中,交通信号灯作为智能体相互协调,通过共享路口交通状况和拥堵信息,动态调整信号灯的切换时长,从而减少交通拥堵。
实现细节:
- 信息共享与决策协调:每个交通信号灯通过无线网络共享实时路况信息,根据交通流量动态调整信号灯时长。
- 多智能体优化:系统利用强化学习来优化信号灯之间的协作策略,使得在高流量时段,交通流量最大化,减少等候时间。

七、结语
多智能体协同系统正快速成为现代人工智能的一个重要研究方向。无论是在智能交通、无人机编队还是工业自动化领域,系统中的智能体协作能力都极大地提升了效率和性能。尽管目前多智能体协同系统还面临一些技术挑战,但随着算法和硬件的发展,未来这些问题有望得到解决,并推动更多创新应用的落地。

- 点赞
- 收藏
- 关注作者
评论(0)