AI Agent自主决策机制及其在复杂环境中的应用研究

【摘要】 在简单的策略网络中,Agent对环境的状态和动作选择较为基础,难以处理高维或连续动作空间。深度强化学习(DRL)可以利用深度神经网络近似策略函数或价值函数,从而提升Agent自主学习能力。
AI Agent自主决策机制及其在复杂环境中的应用研究
引言
- AI Agent的定义与发展历程
- 自主学习的重要性与应用场景
- 本文目标:结合原理解析与Python代码实战,构建可自主学习的AI Agent
AI Agent基础原理
-
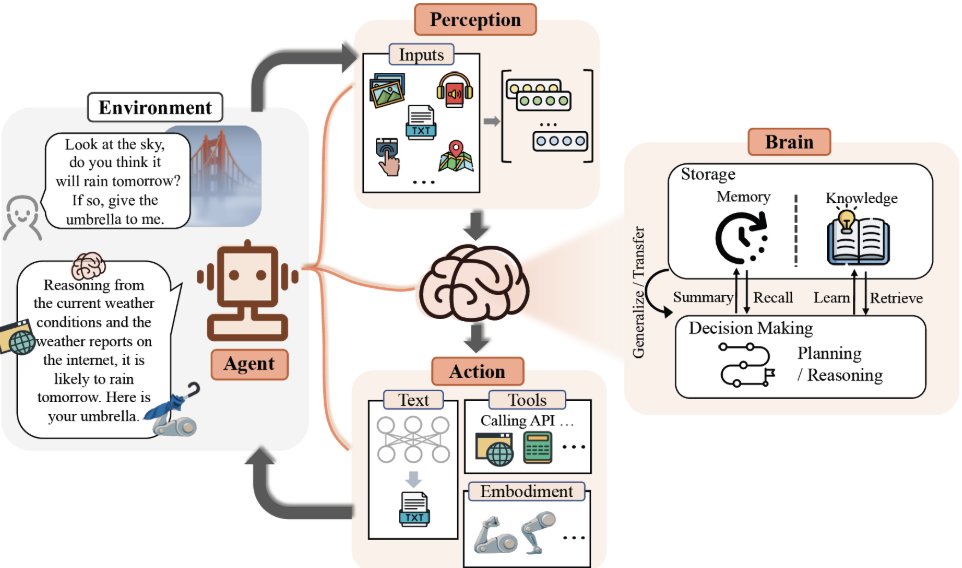
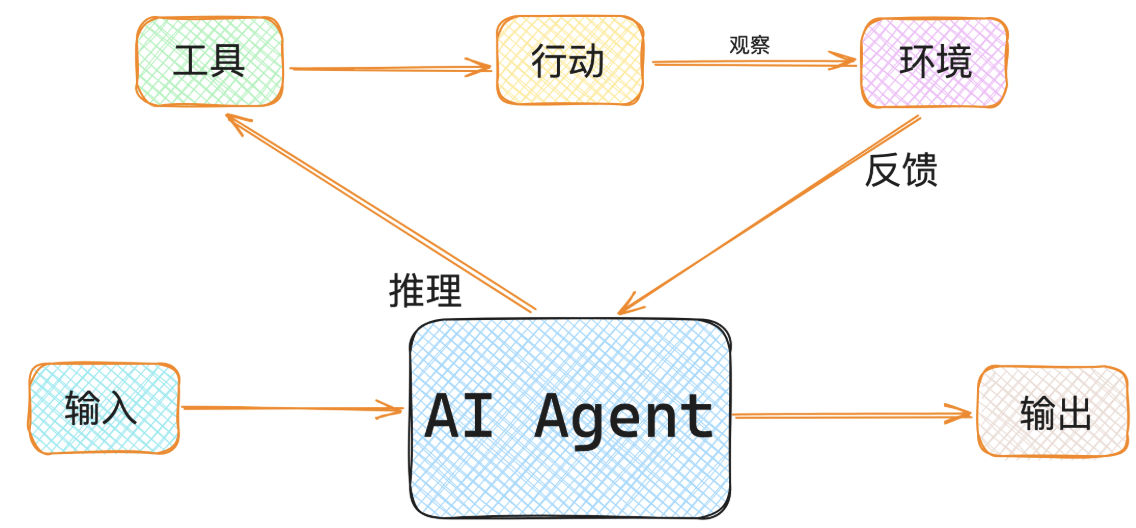
Agent架构概览
- 感知(Perception)
- 决策(Decision Making)
- 行动(Action)
-
自主学习机制
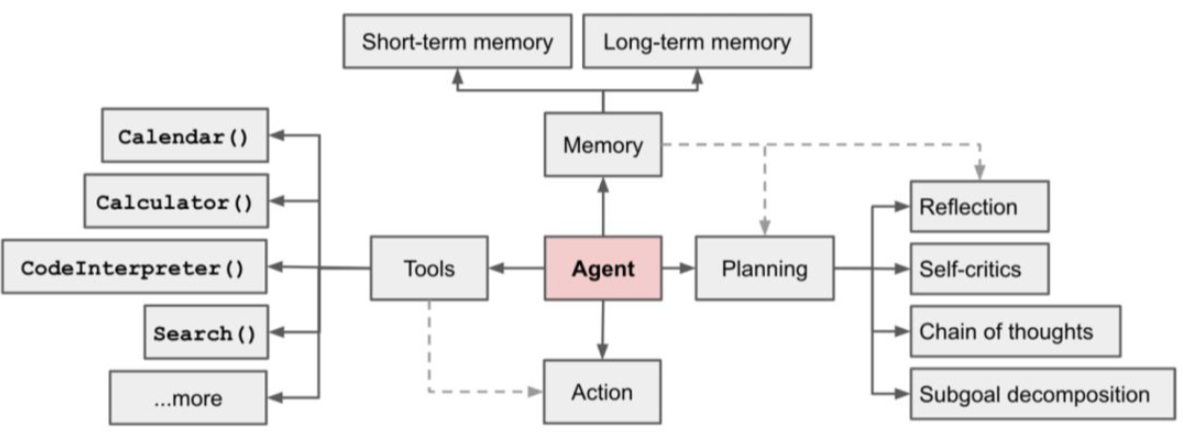
- 强化学习(Reinforcement Learning, RL)
- 模型自适应与策略更新

环境与工具准备
- Python环境搭建
- 必要库安装
pip install gym numpy torch matplotlib
- 环境选择示例:OpenAI Gym经典环境(CartPole-v1)
设计可自主学习的AI Agent
- Agent类设计
- 状态、动作与奖励定义
- 策略网络与Q-learning基础
代码实战:训练自主学习的CartPole Agent
import gym
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
# 定义简单的神经网络策略
class PolicyNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
self.fc = nn.Sequential(
nn.Linear(state_dim, 128),
nn.ReLU(),
nn.Linear(128, action_dim)
)
def forward(self, x):
return self.fc(x)
# 初始化环境
env = gym.make("CartPole-v1")
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
policy_net = PolicyNetwork(state_dim, action_dim)
optimizer = optim.Adam(policy_net.parameters(), lr=0.01)
loss_fn = nn.CrossEntropyLoss()
# 简单训练循环
for episode in range(100):
state = env.reset()
done = False
while not done:
state_tensor = torch.FloatTensor(state).unsqueeze(0)
action_probs = policy_net(state_tensor)
action = torch.argmax(action_probs).item()
next_state, reward, done, _ = env.step(action)
# 损失示例(为了演示)
target = torch.tensor([action])
loss = loss_fn(action_probs, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
state = next_state
print("训练完成!")
训练结果与可视化
- 训练过程指标监控(奖励变化曲线)
import matplotlib.pyplot as plt
plt.plot(rewards_list)
plt.xlabel("Episode")
plt.ylabel("Reward")
plt.show()
- 模型效果分析与调优建议
扩展与优化
深度强化学习(Deep Reinforcement Learning)引入
在简单的策略网络中,Agent对环境的状态和动作选择较为基础,难以处理高维或连续动作空间。深度强化学习(DRL)可以利用深度神经网络近似策略函数或价值函数,从而提升Agent自主学习能力。
-
DQN(Deep Q-Network)
- 利用深度神经网络近似Q函数 (Q(s,a;\theta))
- 使用经验回放(Replay Buffer)缓解样本相关性
- 通过目标网络(Target Network)稳定训练
import random
from collections import deque
# 创建经验回放缓冲区
replay_buffer = deque(maxlen=10000)
batch_size = 32
# 假设已有Q网络和环境
for episode in range(200):
state = env.reset()
done = False
while not done:
# ε-greedy策略选择动作
if random.random() < 0.1:
action = env.action_space.sample()
else:
state_tensor = torch.FloatTensor(state).unsqueeze(0)
action = torch.argmax(policy_net(state_tensor)).item()
next_state, reward, done, _ = env.step(action)
replay_buffer.append((state, action, reward, next_state, done))
state = next_state
# 训练Q网络
if len(replay_buffer) >= batch_size:
batch = random.sample(replay_buffer, batch_size)
states, actions, rewards, next_states, dones = zip(*batch)
states_tensor = torch.FloatTensor(states)
next_states_tensor = torch.FloatTensor(next_states)
rewards_tensor = torch.FloatTensor(rewards)
dones_tensor = torch.FloatTensor(dones)
actions_tensor = torch.LongTensor(actions)
q_values = policy_net(states_tensor)
next_q_values = policy_net(next_states_tensor).max(1)[0].detach()
target_q = rewards_tensor + (1 - dones_tensor) * 0.99 * next_q_values
loss = ((q_values.gather(1, actions_tensor.unsqueeze(1)).squeeze() - target_q) ** 2).mean()
optimizer.zero_grad()
loss.backward()
optimizer.step()
多智能体协作学习(Multi-Agent RL)
在现实场景中,通常存在多个Agent需要协作或竞争。通过多智能体强化学习(MARL),Agent可以学习到协作策略或竞争策略:
- 通信机制:Agent之间可共享部分状态信息
- 集中训练、分散执行:训练阶段共享经验,执行阶段各自决策
- 奖励设计:通过全局奖励或局部奖励引导协作行为
示例代码框架:
agents = [PolicyNetwork(state_dim, action_dim) for _ in range(3)]
for episode in range(100):
states = [env.reset() for _ in agents]
done = False
while not done:
actions = []
for i, agent in enumerate(agents):
state_tensor = torch.FloatTensor(states[i]).unsqueeze(0)
actions.append(torch.argmax(agent(state_tensor)).item())
next_states, rewards, done, _ = env.step(actions)
# 更新每个Agent的策略
for i, agent in enumerate(agents):
# 这里可以使用集中式经验或局部经验更新
pass
states = next_states
模型迁移与自适应能力
Agent在训练完成后,可以通过迁移学习适应新环境,提高泛化能力:
- 冻结部分网络:只训练输出层或部分隐藏层
- 微调策略:在新环境中快速更新策略
- 元学习(Meta-Learning):让Agent学会如何快速适应新任务
示例代码(微调策略):
# 假设policy_net已在CartPole环境训练完成
new_env = gym.make("Acrobot-v1")
# 冻结前两层,只训练最后一层
for name, param in policy_net.named_parameters():
if "fc.2" not in name:
param.requires_grad = False
optimizer = optim.Adam(filter(lambda p: p.requires_grad, policy_net.parameters()), lr=0.001)
# 在新环境中微调
for episode in range(50):
state = new_env.reset()
done = False
while not done:
state_tensor = torch.FloatTensor(state).unsqueeze(0)
action = torch.argmax(policy_net(state_tensor)).item()
next_state, reward, done, _ = new_env.step(action)
# 简单训练示例
target = torch.tensor([action])
loss = loss_fn(policy_net(state_tensor), target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
state = next_state
总结
本文从理论与实践两个层面,系统介绍了如何构建一个可自主学习的AI Agent。我们首先分析了Agent的基础架构,包括感知、决策和行动模块,并讲解了自主学习机制及强化学习的核心原理。
在实战部分,通过Python和OpenAI Gym环境,我们展示了如何设计Agent类、定义状态、动作和奖励,并实现了一个基础策略网络的训练示例。随后,文章进一步拓展到深度强化学习(DQN)、多智能体协作学习以及模型迁移与自适应能力的优化策略,通过代码示例展示了如何在复杂或新环境中提升Agent的学习能力。
通过这些实践,读者可以理解:
- 自主学习AI Agent不仅依赖算法设计,还依赖训练环境的构建与奖励设计。
- 深度强化学习和多智能体学习能够显著提升Agent在高维或动态场景下的决策能力。
- 模型迁移和微调可以让Agent具备跨场景适应能力,为实际应用提供可行性方案。
总体而言,构建可自主学习的AI Agent是一项系统工程,需要理论知识、实践技能和持续调优相结合。本文提供的代码示例和优化思路,可作为开发自主学习Agent的入门指南,并为进一步研究与应用打下坚实基础。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)