Wasserstein GAN提升图像生成质量的理论与实践

Wasserstein GAN提升图像生成质量的理论与实践
生成对抗网络(GANs,Generative Adversarial Networks)自2014年由Ian Goodfellow等人提出以来,已经在图像生成、图像修复、图像转换等领域取得了巨大的进展。GAN的独特结构,即由生成器(Generator)和判别器(Discriminator)组成的对抗性训练过程,使其在生成逼真图像方面表现出了强大的能力。
本文将重点探讨基于生成对抗网络的图像生成技术的现状与未来发展,分析当前的主流方法,并通过代码实例演示GAN在图像生成中的应用。
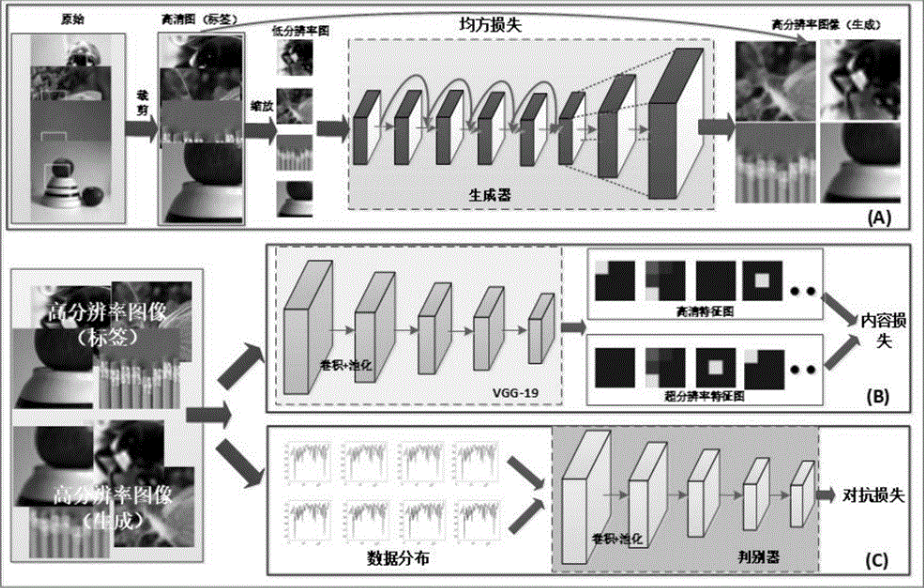
一、生成对抗网络(GAN)的基本原理
1.1 GAN的结构与工作原理
生成对抗网络由两部分组成:
- 生成器(Generator):负责从随机噪声中生成图像。
- 判别器(Discriminator):用于判定输入图像是否为真实图像。
这两部分通过对抗训练来优化。生成器通过不断学习如何生成越来越逼真的图像,而判别器则不断学习如何辨别图像的真伪,直到生成器能够生成几乎无法与真实图像区分的图像。
1.2 训练过程
训练过程可以视为一个博弈过程。生成器试图生成“骗过”判别器的图像,而判别器试图分辨这些图像是否真实。随着训练的进行,生成器和判别器不断提升自己的能力,最终使生成的图像越来越逼真。
1.3 损失函数
GAN的目标是通过最小化生成器和判别器之间的损失函数来实现优化。通常,生成器的目标是最大化判别器的错误,而判别器的目标则是最小化其错误。
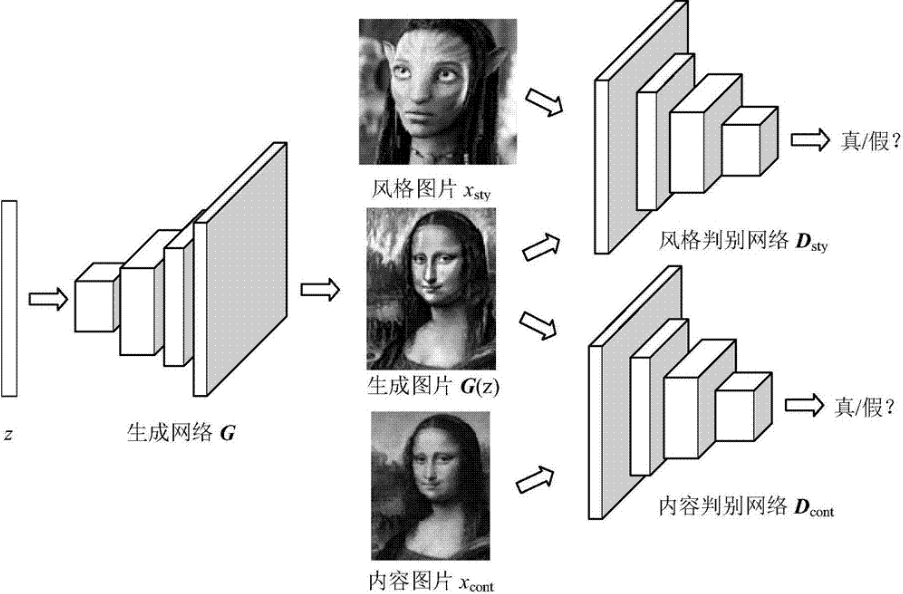
二、基于GAN的图像生成技术应用
2.1 图像生成
GAN的最经典应用之一是从随机噪声生成图像。通过训练,生成器能够生成非常接近真实的图像,广泛应用于艺术创作、游戏设计、广告等领域。
代码示例:简单的GAN实现(基于Keras)
以下代码演示了一个简单的GAN实现,其中使用了Keras框架进行训练:
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LeakyReLU, BatchNormalization
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import mnist
# 加载MNIST数据集
(X_train, _), (_, _) = mnist.load_data()
X_train = X_train / 127.5 - 1.0 # 数据归一化到[-1, 1]
X_train = X_train.reshape(X_train.shape[0], 784)
# 生成器模型
def build_generator():
model = Sequential()
model.add(Dense(256, input_dim=100))
model.add(LeakyReLU(0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(784, activation='tanh'))
return model
# 判别器模型
def build_discriminator():
model = Sequential()
model.add(Dense(1024, input_dim=784))
model.add(LeakyReLU(0.2))
model.add(Dense(512))
model.add(LeakyReLU(0.2))
model.add(Dense(256))
model.add(LeakyReLU(0.2))
model.add(Dense(1, activation='sigmoid'))
return model
# GAN模型(生成器和判别器的组合)
def build_gan(generator, discriminator):
discriminator.trainable = False
model = Sequential()
model.add(generator)
model.add(discriminator)
return model
# 编译模型
discriminator = build_discriminator()
discriminator.compile(loss='binary_crossentropy', optimizer=Adam(0.0002, 0.5), metrics=['accuracy'])
generator = build_generator()
gan = build_gan(generator, discriminator)
gan.compile(loss='binary_crossentropy', optimizer=Adam(0.0002, 0.5))
# 训练模型
def train_gan(epochs=1, batch_size=128):
batch_count = X_train.shape[0] // batch_size
for epoch in range(epochs):
for _ in range(batch_count):
# 训练判别器
noise = np.random.normal(0, 1, (batch_size, 100))
generated_images = generator.predict(noise)
real_images = X_train[np.random.randint(0, X_train.shape[0], batch_size)]
real_labels = np.ones((batch_size, 1))
fake_labels = np.zeros((batch_size, 1))
d_loss_real = discriminator.train_on_batch(real_images, real_labels)
d_loss_fake = discriminator.train_on_batch(generated_images, fake_labels)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# 训练生成器
noise = np.random.normal(0, 1, (batch_size, 100))
g_loss = gan.train_on_batch(noise, real_labels)
print(f"{epoch}/{epochs} [D loss: {d_loss[0]} | D accuracy: {100 * d_loss[1]}] [G loss: {g_loss}]")
if epoch % 10 == 0:
plot_generated_images(epoch)
# 可视化生成的图像
def plot_generated_images(epoch, examples=10, dim=(1, 10), figsize=(10, 1)):
noise = np.random.normal(0, 1, (examples, 100))
generated_images = generator.predict(noise)
plt.figure(figsize=figsize)
for i in range(examples):
plt.subplot(dim[0], dim[1], i + 1)
plt.imshow(generated_images[i].reshape(28, 28), cmap='gray')
plt.axis('off')
plt.tight_layout()
plt.savefig(f"gan_generated_image_epoch_{epoch}.png")
plt.close()
train_gan(epochs=1000, batch_size=128)
2.2 图像修复与增强
GAN在图像修复和增强方面也得到了广泛应用。通过训练,GAN能够恢复丢失的图像信息,或者对图像进行去噪、超分辨率等增强操作。像Pix2Pix、CycleGAN等模型就是在这一领域中应用的典型代表。
2.3 图像风格转换
GAN还被广泛应用于图像风格转换,例如将一张照片转换成油画风格或将夏天的场景转换为冬天的场景。CycleGAN正是专门为无监督的图像到图像转换任务设计的。
三、未来的发展方向
3.1 高效GAN模型
尽管现有的GAN在图像生成方面取得了巨大成功,但仍然存在训练不稳定、计算资源消耗大等问题。未来的GAN研究将更加注重如何提高训练效率,减少计算成本,优化训练过程。
3.2 多模态图像生成
当前的GAN主要用于单一模态的图像生成,未来的发展将朝着多模态图像生成方向迈进。例如,如何根据不同的输入条件(如文本、音频等)生成图像,成为一个重要研究方向。
3.3 生成对抗网络的可解释性
随着生成对抗网络的广泛应用,可解释性问题也日益成为研究的重点。如何理解生成器和判别器的决策过程,如何确保生成图像符合特定的要求,将是未来研究的重要方向。
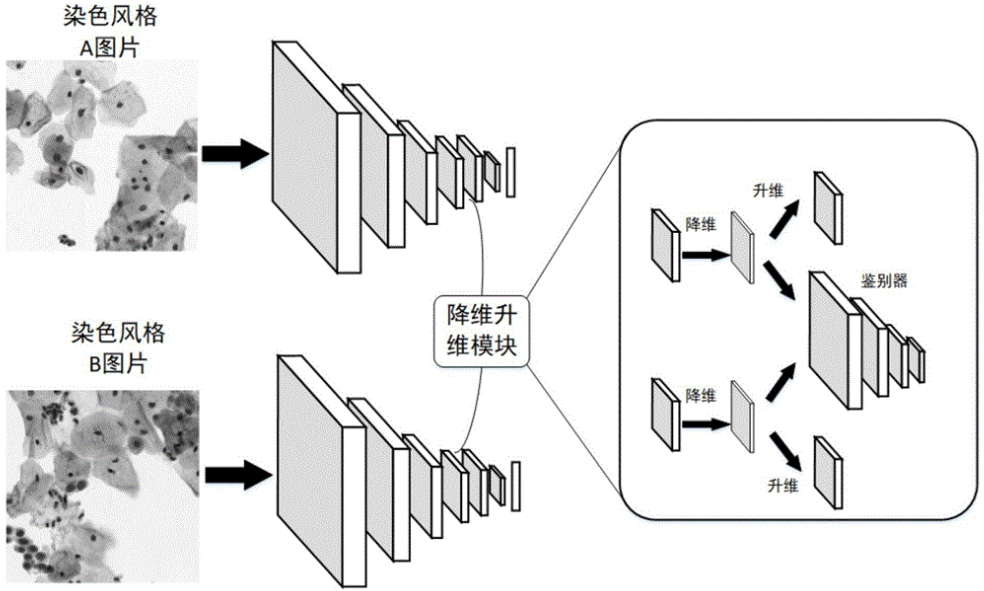
四、挑战与解决方案
4.1 GAN的训练不稳定性
训练GAN时,最常见的问题之一就是生成器和判别器之间的训练不平衡。判别器的性能过强可能导致生成器无法有效学习,反之,生成器过强可能使判别器的判别能力下降。为了解决这个问题,研究者们提出了多种方法,包括:
- 梯度惩罚(Gradient Penalty):通过在判别器的损失函数中加入惩罚项,限制其梯度的大小,避免判别器过于强大。
- 谱归一化(Spectral Normalization):对判别器的权重进行谱归一化,使得模型的训练过程更加稳定。
4.2 模型的收敛速度慢
GAN的训练通常非常缓慢,尤其是对于深层网络。生成器和判别器的训练需要大量的时间和计算资源。为了解决这个问题,以下是几种常见的优化方案:
- 小批量训练(Mini-batch Training):将训练数据划分成更小的批次,从而加速训练过程。
- 预训练(Pre-training):可以通过预训练生成器和判别器的部分网络,来帮助加速训练的收敛过程。
4.3 模型生成的图像质量
尽管GAN在生成图像方面已经取得了显著进展,但生成的图像质量仍然存在差距,尤其是在生成细节复杂或者高分辨率图像时。为了解决这一问题,研究者们提出了许多创新的架构,例如:
- Wasserstein GAN(WGAN):引入Wasserstein距离作为损失函数,能够稳定训练过程,并提高生成图像的质量。
- 渐进式生成(Progressive Growing GANs):通过逐渐增加生成器和判别器的网络层数,从低分辨率图像开始训练,最终生成高分辨率图像。
4.4 模型的计算资源需求
高质量的图像生成通常需要非常大的计算资源,尤其是在训练大规模的网络时。例如,生成一张高分辨率的图像需要大量的GPU内存和计算时间。为了解决这个问题,以下是几种解决策略:
- 模型压缩与量化:通过压缩和量化模型,减少模型的大小,从而减少计算资源的需求。
- 迁移学习:使用已经训练好的GAN模型进行迁移学习,减少从零开始训练的计算开销。
五、生成对抗网络的多样化应用
5.1 医学图像分析
GAN在医学图像分析中的应用得到了广泛关注,尤其是在医学影像数据的增强、生成和修复方面。通过训练GAN,研究者可以生成缺失的医学图像区域,或生成特定病变的图像,从而帮助医生进行疾病诊断。
代码示例:医学图像修复
from tensorflow.keras.layers import Conv2D, UpSampling2D
from tensorflow.keras.models import Sequential
# 简单的图像修复生成器
def build_image_inpainting_generator():
model = Sequential()
model.add(Conv2D(64, (3, 3), padding='same', input_shape=(256, 256, 3)))
model.add(UpSampling2D(size=(2, 2)))
model.add(Conv2D(128, (3, 3), padding='same'))
model.add(UpSampling2D(size=(2, 2)))
model.add(Conv2D(256, (3, 3), padding='same'))
model.add(Conv2D(3, (3, 3), activation='sigmoid', padding='same'))
return model
# 假设我们已经有了缺失部分的医学图像,使用生成器修复图像
generator = build_image_inpainting_generator()
reconstructed_image = generator.predict(missing_image_data)
5.2 视频生成与预测
除了静态图像生成,GAN在视频生成和预测方面也有重要应用。例如,可以使用GAN生成视频中的下一帧图像,或者通过训练GAN生成整个视频序列。视频生成可以在影视制作、虚拟现实等领域得到广泛应用。
5.3 数据增强与合成
GAN还可以用于数据增强,特别是在数据集不平衡的情况下。例如,在图像分类任务中,GAN可以生成少数类的图像样本,进而平衡训练数据集,从而提高分类器的性能。
5.4 生成艺术与创意
近年来,生成对抗网络在艺术创作中也得到了应用,尤其是在生成绘画、设计风格转换等方面。例如,著名的ArtGAN模型能够根据用户输入的风格生成艺术作品。此外,GAN还被应用于自动化设计中,如图像中的家具、服装、建筑等元素的生成。
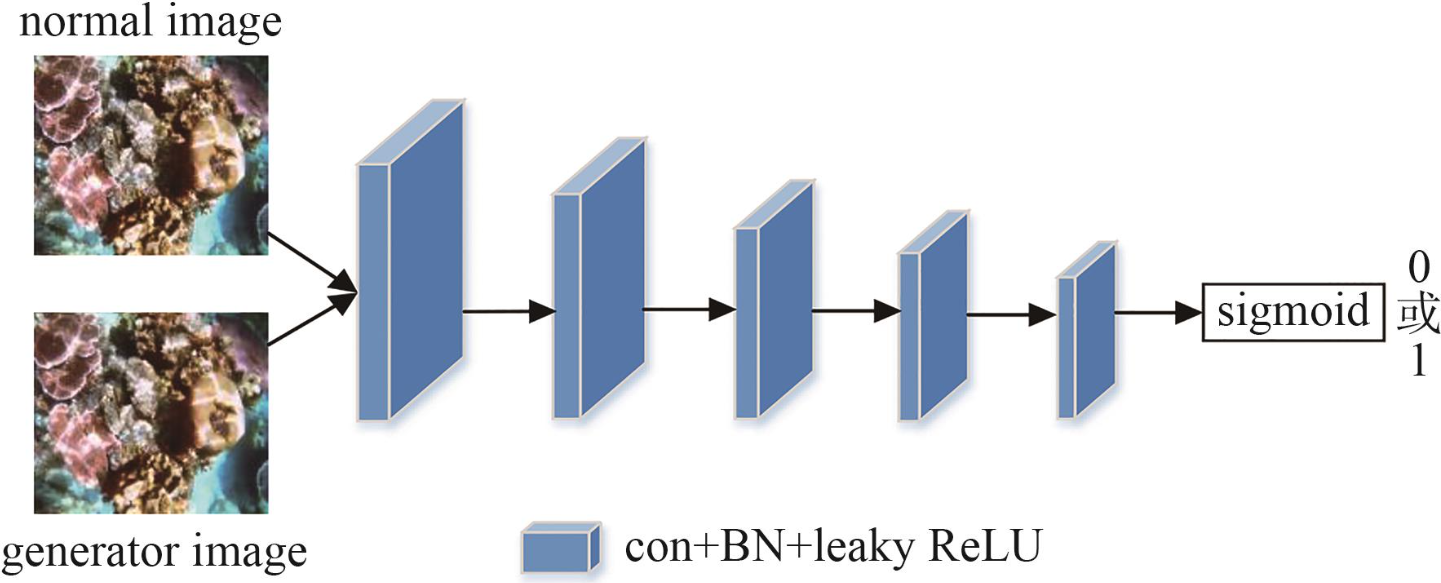
六、结论
生成对抗网络(GAN)作为一种强大的图像生成技术,在多个领域取得了显著进展。从图像生成到图像修复,再到数据增强和视频生成,GAN的应用已经渗透到艺术创作、医学分析、虚拟现实等多个行业。然而,GAN模型仍面临着训练不稳定、生成图像质量不高、计算资源消耗大等挑战。未来,随着优化算法和硬件的发展,GAN的训练效率和生成图像的质量有望进一步提高。通过跨学科的合作和不断创新,GAN将在更广泛的应用场景中发挥重要作用。

- 点赞
- 收藏
- 关注作者
评论(0)