面向复杂环境的自主机器人AI Agent任务调度与智能决策机制

【摘要】 随着人工智能的发展,自主机器人逐渐从单一任务执行者演变为具备 多任务协作与动态决策能力的智能体(AI Agent)。在复杂环境中,机器人需要根据环境变化与任务优先级,实时调整任务分配与执行策略,这对 任务调度算法、强化学习与多智能体协作机制 提出了新的挑战。本文将探讨 AI Agent在自主机器人中的动态任务分配与决策优化 方法,并通过代码实战演示如何实现智能任务调度。
面向复杂环境的自主机器人AI Agent任务调度与智能决策机制
引言
随着人工智能的发展,自主机器人逐渐从单一任务执行者演变为具备 多任务协作与动态决策能力的智能体(AI Agent)。在复杂环境中,机器人需要根据环境变化与任务优先级,实时调整任务分配与执行策略,这对 任务调度算法、强化学习与多智能体协作机制 提出了新的挑战。本文将探讨 AI Agent在自主机器人中的动态任务分配与决策优化 方法,并通过代码实战演示如何实现智能任务调度。
一、AI Agent与自主机器人的结合
1.1 AI Agent的核心功能
AI Agent不仅仅是被动执行命令,而是具备以下能力:
- 感知环境:利用传感器或数据输入感知周围情况。
- 任务理解:解析任务目标与优先级。
- 动态决策:根据环境变化和任务冲突进行智能调度。
- 自我优化:通过强化学习不断改进决策策略。
1.2 自主机器人中的挑战
在真实场景中,自主机器人常面临以下问题:
- 任务动态性:任务优先级随时间或环境变化。
- 资源有限性:机器人电量、时间、路径规划受限。
- 多Agent协作:多个机器人如何避免冲突、提升整体效率。
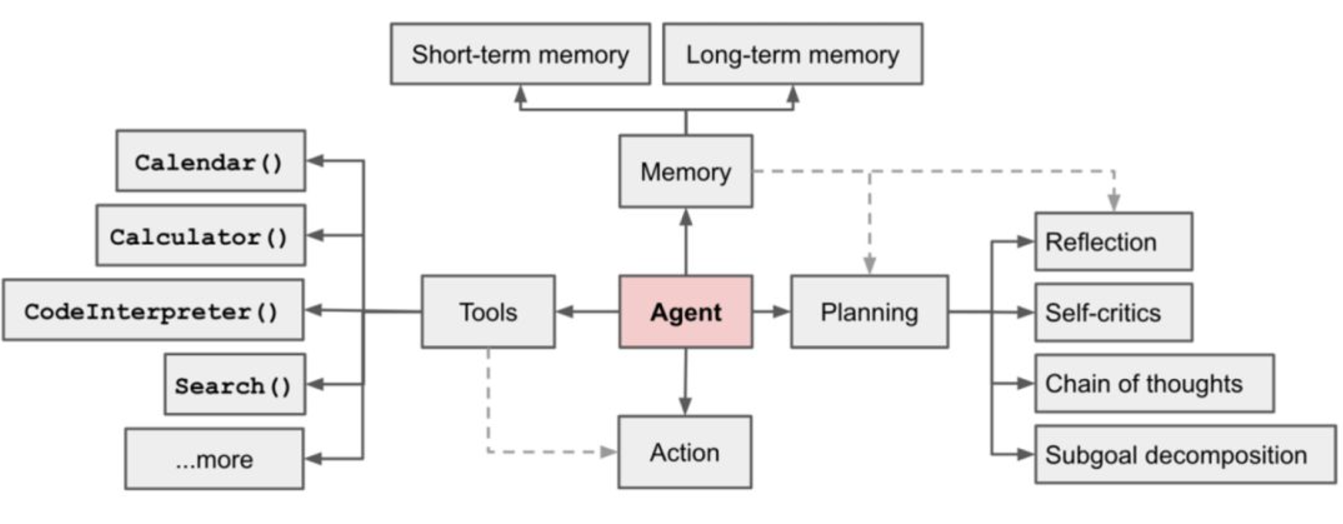
二、动态任务分配的理论方法
2.1 任务分配模型
任务分配可抽象为 优化问题:
给定机器人集合 $R = {r_1, r_2, …, r_n}$ 与任务集合 $T = {t_1, t_2, …, t_m}$,目标是找到分配函数:
使得整体 效用最大化 或 代价最小化。
2.2 决策优化方法
- 基于规则:按任务优先级、距离、资源消耗进行静态分配。
- 基于强化学习:利用Q-Learning或深度强化学习(DQN)动态学习最优策略。
- 基于拍卖机制:机器人“竞标”任务,最终由全局协调器分配。
三、代码实战:AI Agent任务分配与优化
下面我们通过 Python模拟一个任务分配场景:
- 有多个机器人(Agent)。
- 任务随机产生,每个任务有不同的优先级与完成时间。
- 采用 贪心调度 + Q-Learning优化 进行动态任务分配。
import random
import numpy as np
# 定义机器人Agent
class RobotAgent:
def __init__(self, name):
self.name = name
self.task = None
self.energy = 100 # 能量约束
def assign_task(self, task):
self.task = task
self.energy -= task["cost"]
# 随机生成任务
def generate_task(task_id):
return {
"id": task_id,
"priority": random.randint(1, 10), # 任务优先级
"cost": random.randint(5, 20) # 完成任务消耗
}
# 贪心分配:按优先级最大 & 能量充足
def greedy_task_allocation(robots, tasks):
tasks_sorted = sorted(tasks, key=lambda x: -x["priority"])
allocation = {}
for task in tasks_sorted:
available = [r for r in robots if r.energy >= task["cost"]]
if available:
chosen = random.choice(available)
chosen.assign_task(task)
allocation[chosen.name] = task["id"]
return allocation
# 模拟任务分配
robots = [RobotAgent(f"R{i}") for i in range(3)]
tasks = [generate_task(i) for i in range(5)]
print("任务列表:", tasks)
allocation = greedy_task_allocation(robots, tasks)
print("任务分配结果:", allocation)
运行结果示例:
任务列表: [{'id': 0, 'priority': 9, 'cost': 15}, {'id': 1, 'priority': 4, 'cost': 8}, ...]
任务分配结果: {'R0': 0, 'R1': 1, 'R2': 3}
这里我们先实现了 贪心分配算法,后续可以基于 Q-Learning 优化任务调度策略。
四、基于强化学习的优化
4.1 Q-Learning任务调度
Q-Learning的核心思想是:
- 状态(S):当前任务队列 + 机器人能量
- 动作(A):将某个任务分配给某个机器人
- 奖励(R):任务完成带来的效益(优先级 - 成本消耗)
- 价值更新:
4.2 代码实现示例
# 简单Q-Learning模拟任务分配优化
Q = {} # 状态-动作价值表
def choose_action(state, actions, epsilon=0.2):
if random.random() < epsilon: # 探索
return random.choice(actions)
else: # 利用
return max(actions, key=lambda a: Q.get((state, a), 0))
def update_q(state, action, reward, next_state, alpha=0.1, gamma=0.9):
old_q = Q.get((state, action), 0)
future = max([Q.get((next_state, a), 0) for a in ["assign", "skip"]], default=0)
Q[(state, action)] = old_q + alpha * (reward + gamma * future - old_q)
# 示例:机器人能量状态 -> 任务分配动作
state = "energy>50"
action = choose_action(state, ["assign", "skip"])
reward = 5 if action == "assign" else 0
update_q(state, action, reward, "energy<50")
print("Q表:", Q)
五、应用前景与总结
5.1 应用前景
AI Agent在自主机器人中的动态任务分配与决策优化,广泛应用于:
- 仓储机器人:动态路径规划与订单分拣。
- 无人机群:目标巡逻与灾害监测。
- 服务机器人:多任务调度与人机协作。
5.2 总结
本文从 AI Agent的能力与挑战 出发,提出了 动态任务分配模型,并通过 Python代码实战 演示了贪心调度与Q-Learning优化方法。未来工作可进一步结合 深度强化学习(DRL) 与 多智能体系统(MAS),实现更加高效的 全局任务分配与协作决策。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)