AI Agent在复杂网络中的自组织学习机制研究

【摘要】 随着人工智能(AI)的快速发展,AI Agent(智能体)在分布式系统、社交网络、物联网以及多智能体协作系统中的应用日益广泛。复杂网络环境下,节点间交互频繁、关系动态变化,传统的集中式学习方式难以应对这种高动态性和不确定性。因此,研究 AI Agent的自组织学习与适应机制 具有重要意义。
AI Agent在复杂网络中的自组织学习机制研究
引言
随着人工智能(AI)的快速发展,AI Agent(智能体)在分布式系统、社交网络、物联网以及多智能体协作系统中的应用日益广泛。复杂网络环境下,节点间交互频繁、关系动态变化,传统的集中式学习方式难以应对这种高动态性和不确定性。因此,研究 AI Agent的自组织学习与适应机制 具有重要意义。
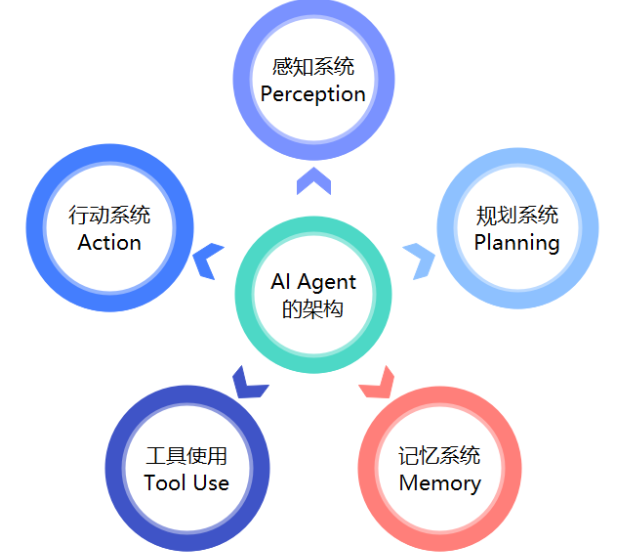
一、复杂网络与AI Agent
1.1 复杂网络的特点
复杂网络常见于现实世界的诸多系统中,如社交网络、电力网络、交通网络和通信网络。它们具有以下显著特征:
- 小世界性:任意两个节点之间的路径较短;
- 无标度性:少数节点的连接度极高(枢纽节点);
- 动态性:节点和边随时间不断变化。
1.2 AI Agent的角色
在复杂网络中,AI Agent通常扮演以下角色:
- 学习者:基于环境反馈不断更新策略;
- 适应者:根据网络结构和任务动态变化进行调整;
- 协作者:与其他Agent进行信息交换与合作。
二、自组织学习机制
2.1 自组织学习的概念
自组织学习是指AI Agent无需外部监督或集中控制,而是通过局部规则与交互,逐步形成全局最优或次优的适应策略。
核心特征包括:
- 局部规则驱动:仅基于邻居节点信息;
- 全局涌现:复杂的群体行为从简单规则中自发涌现;
- 动态适应:随网络环境变化自动调整。
2.2 典型方法
- 强化学习(Reinforcement Learning, RL):Agent通过奖励与惩罚不断改进策略。
- 进化学习(Evolutionary Learning):基于遗传算法或群体智能算法实现自适应优化。
- 图神经网络(Graph Neural Network, GNN):通过图结构学习节点表示,促进全局适应。
三、适应机制设计
3.1 局部适应
每个Agent只依赖邻居节点的状态来更新自己的策略,例如:
- 基于邻居的奖励平均值调整行动;
- 基于局部网络拓扑调整信息传播路径。
3.2 全局适应
通过多智能体交互形成整体协作模式,如:
- 集体共识(Consensus)机制;
- 网络扩散学习(Diffusion Learning)。
四、代码实战:基于复杂网络的AI Agent自组织学习
下面我们通过一个简单的模拟实验,展示多个AI Agent在复杂网络中通过强化学习实现自组织学习与适应。
4.1 实验目标
- 构建一个复杂网络(小世界网络);
- 在每个节点上放置一个AI Agent;
- Agent通过与邻居交互并使用Q-learning更新策略;
- 观察整体系统的适应过程。
4.2 Python代码示例
import networkx as nx
import numpy as np
import random
import matplotlib.pyplot as plt
# 构建小世界网络
G = nx.watts_strogatz_graph(n=20, k=4, p=0.3)
# 定义Agent类
class Agent:
def __init__(self, actions=[0, 1]): # 0=合作,1=背叛
self.q_table = {a: 0.0 for a in actions}
self.actions = actions
self.epsilon = 0.2 # 探索率
self.alpha = 0.1 # 学习率
self.gamma = 0.9 # 折扣因子
def choose_action(self):
if random.random() < self.epsilon:
return random.choice(self.actions)
return max(self.q_table, key=self.q_table.get)
def update(self, action, reward):
predict = self.q_table[action]
target = reward + self.gamma * max(self.q_table.values())
self.q_table[action] += self.alpha * (target - predict)
# 初始化Agent
agents = {node: Agent() for node in G.nodes}
# 模拟交互
def interaction(a1, a2):
# 定义奖励规则(囚徒困境)
if a1 == 0 and a2 == 0:
return (3, 3) # 双方合作
elif a1 == 0 and a2 == 1:
return (0, 5) # A合作 B背叛
elif a1 == 1 and a2 == 0:
return (5, 0) # A背叛 B合作
else:
return (1, 1) # 双方背叛
# 训练过程
episodes = 200
coop_rate = []
for ep in range(episodes):
coop_count = 0
for node in G.nodes:
neighbors = list(G.neighbors(node))
if not neighbors: continue
opponent = random.choice(neighbors)
a1 = agents[node].choose_action()
a2 = agents[opponent].choose_action()
r1, r2 = interaction(a1, a2)
agents[node].update(a1, r1)
agents[opponent].update(a2, r2)
if a1 == 0: coop_count += 1
coop_rate.append(coop_count / len(G.nodes))
# 可视化合作率随时间变化
plt.plot(coop_rate)
plt.xlabel("Episodes")
plt.ylabel("Cooperation Rate")
plt.title("Self-Organized Learning in Complex Network")
plt.show()
4.3 实验结果分析
从模拟结果中可以看到:
- 初始阶段,Agent的行为较为随机;
- 随着训练进行,合作率逐渐上升,表明Agent在复杂网络中能够通过局部交互逐渐实现全局性的自组织适应;
- 该过程反映了 简单局部规则 → 群体复杂行为涌现 的典型模式。
五、应用场景与前景展望
5.1 应用场景
- 社交网络推荐系统:自适应推荐用户感兴趣的内容;
- 物联网设备协同:设备间自组织学习,实现高效资源调度;
- 分布式控制系统:无人机群体或机器人群体的协作任务执行。
5.2 前景展望
未来的AI Agent将更多地依赖 自组织学习机制,摆脱对集中式控制的依赖,实现:
- 更强的鲁棒性与适应性;
- 在动态复杂环境中的实时决策能力;
- 与人类社会和技术系统的深度融合。
结论
AI Agent在复杂网络中的自组织学习与适应机制,为解决大规模动态系统中的协作与优化问题提供了全新思路。本文通过理论分析与代码实战,展示了基于复杂网络的AI Agent如何通过局部交互实现全局适应,这不仅具有理论意义,也对未来分布式AI应用具有广阔前景。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)