面向电子竞技的深度强化学习游戏智能体研究

面向电子竞技的深度强化学习游戏智能体研究
引言
人工智能(Artificial Intelligence, AI)在游戏领域的应用一直是学术界和工业界的研究热点。传统的游戏AI往往依赖于手工编写的规则或搜索算法,而深度强化学习(Deep Reinforcement Learning, DRL)的兴起,为游戏AI带来了全新的可能性。AI Agent通过与虚拟环境的交互不断学习,可以实现复杂策略的形成,展现出接近甚至超过人类水平的游戏表现。本文将重点探讨基于深度强化学习的AI Agent在游戏智能体中的应用,分析其关键技术框架,并提供代码实战示例。
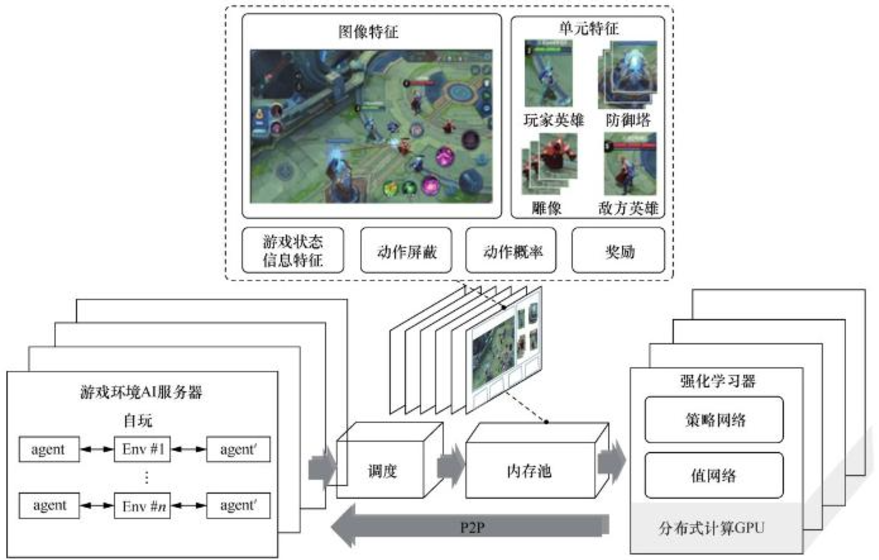
一、深度强化学习的基本原理
(一)强化学习的核心框架
强化学习的核心在于 智能体(Agent) 与 环境(Environment) 的交互。智能体通过采取动作(Action)影响环境状态(State),并根据奖励(Reward)进行策略(Policy)的更新。
关键要素:
- 状态空间(State Space, S)
- 动作空间(Action Space, A)
- 奖励函数(Reward Function, R)
- 策略(Policy, π)
- 价值函数(Value Function, V)
(二)深度学习在强化学习中的作用
深度神经网络用于近似复杂的价值函数和策略函数,从而使强化学习能够在高维状态空间(如游戏图像)中进行有效的学习。常见方法包括:
- DQN(Deep Q-Network):基于Q-learning的深度版本。
- Policy Gradient(策略梯度):直接优化策略分布。
- Actor-Critic架构:结合值函数和策略函数,提升稳定性和收敛速度。
二、深度强化学习在游戏智能体中的应用
(一)经典游戏中的应用
- Atari游戏:DQN最早在Atari 2600游戏中实现突破,人类水平甚至超越人类。
- 围棋与棋类:AlphaGo通过深度强化学习与蒙特卡洛树搜索结合,实现了超人类水平的围棋对弈。
(二)现代3D游戏中的应用
在复杂的3D环境(如Dota2、星际争霸II)中,AI Agent需要处理连续动作空间和部分可观测性问题。此时,A3C(异步优势Actor-Critic)、PPO(Proximal Policy Optimization)等算法表现优异。
(三)游戏AI智能体的优势
- 自动学习复杂策略,无需人工规则。
- 可适应不同场景和任务,具备迁移能力。
- 提升游戏的智能化程度,增强玩家体验。
三、代码实战:基于PPO的游戏智能体实现
下面以经典的 CartPole 平衡杆游戏 为例,使用 stable-baselines3 实现一个基于PPO的AI Agent。
(一)环境准备
import gym
from stable_baselines3 import PPO
# 创建游戏环境
env = gym.make("CartPole-v1")
# 初始化AI Agent
model = PPO("MlpPolicy", env, verbose=1)
# 训练智能体
model.learn(total_timesteps=20000)
# 保存模型
model.save("ppo_cartpole")
(二)智能体测试
# 加载模型
model = PPO.load("ppo_cartpole")
obs = env.reset()
for _ in range(1000):
action, _states = model.predict(obs)
obs, rewards, dones, info = env.step(action)
env.render() # 可视化运行效果
(三)结果分析
经过数万步训练后,AI Agent能够学会保持杆子的平衡,游戏表现显著提升。该实验验证了深度强化学习在简单游戏环境中的有效性。
四、挑战与未来方向
(一)现存挑战
1. 样本效率问题
深度强化学习在训练过程中通常需要数百万次环境交互才能收敛到有效策略。例如,在Atari游戏实验中,DQN需要数百万帧的训练才能获得接近人类的表现。这一问题使得算法在计算成本和训练时间上开销巨大,限制了在高复杂度游戏中的应用。
2. 泛化能力不足
大多数AI Agent在训练环境中表现良好,但在面对稍有差异的环境时性能显著下降。例如,游戏关卡的背景变化、动作延迟等,都会影响Agent的稳定性。这表明现有模型缺乏良好的迁移与泛化能力。
3. 奖励稀疏与探索困难
在复杂游戏(如星际争霸II)中,奖励通常极为稀疏,只有在完成特定任务后才能获得反馈。智能体在训练早期往往无法接触到奖励,从而陷入随机探索的困境。
4. 训练稳定性与超参数敏感性
深度强化学习算法在训练中容易出现发散现象,且对学习率、折扣因子、批量大小等超参数高度敏感。这使得AI Agent的稳定训练过程具有较高的技术门槛。
(二)未来发展方向
1. 高效的样本利用方法
研究者正在探索利用 模型辅助的强化学习(Model-based RL),通过对环境动力学建模减少与真实环境的交互需求。同时,离线强化学习(Offline RL) 也在尝试直接利用历史数据进行学习,从而大幅降低采样成本。
2. 多智能体协同与竞争
在多人游戏(如Dota2、星际争霸II)中,多智能体强化学习(Multi-Agent Reinforcement Learning, MARL)成为重要方向。智能体不仅要学会独立决策,还需要具备合作与博弈能力。典型应用如 OpenAI Five 展示了多智能体在复杂策略博弈中的巨大潜力。
3. 融合模仿学习与人类先验知识
为了应对奖励稀疏问题,模仿学习(Imitation Learning, IL)与逆强化学习(Inverse Reinforcement Learning, IRL)成为热点。通过模仿人类专家数据,智能体可以快速学习有效策略,并减少无效探索。
4. 泛化与迁移学习
通过 元学习(Meta-Learning) 和 领域自适应(Domain Adaptation),研究者希望赋予AI Agent更强的泛化能力,使其在不同游戏或新关卡中仍能保持高效表现。例如,利用在某类游戏中学到的知识迁移到另一类游戏。
5. 神经符号结合与可解释性
未来AI Agent的设计可能融合 符号推理 与 深度学习,以增强可解释性和鲁棒性。通过在神经网络之上叠加规则系统,可以在保证高性能的同时实现更透明的决策过程。
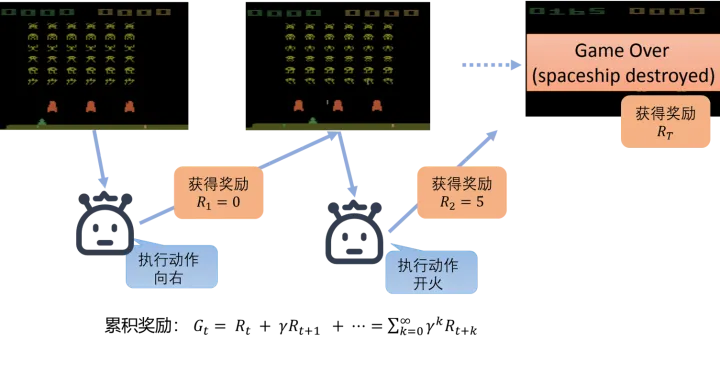
五、扩展实验与案例研究
(一)Atari游戏中的应用
以 Breakout 打砖块 为例,深度Q网络(DQN)实现了自动学习击球策略。通过卷积神经网络对图像状态进行特征提取,AI Agent逐渐学会了“打洞”策略,即专门在墙体边缘开口,从而获得更高分数。这类实验验证了深度强化学习在高维视觉输入下的有效性。
(二)复杂环境:星际争霸II
DeepMind与暴雪联合开发的 StarCraft II Learning Environment (SC2LE) 成为多智能体强化学习的重要平台。智能体需要同时处理资源采集、兵种调度和战斗策略。AlphaStar作为代表性成果,通过PPO和分层策略,首次在星际争霸II中击败职业选手,展示了DRL在高复杂度博弈中的潜力。
(三)代码示例:Atari游戏训练
下面演示一个基于DQN训练Atari游戏的案例(以Pong为例):
import gym
from stable_baselines3 import DQN
# 创建Atari环境
env = gym.make("PongNoFrameskip-v4")
# 使用DQN进行训练
model = DQN("CnnPolicy", env, verbose=1, buffer_size=100000, learning_rate=1e-4, batch_size=32)
model.learn(total_timesteps=500000)
# 保存模型
model.save("dqn_pong")
# 测试模型
obs = env.reset()
for _ in range(10000):
action, _ = model.predict(obs)
obs, reward, done, info = env.step(action)
env.render()
if done:
obs = env.reset()
经过数十万次迭代后,AI Agent能从完全随机策略进化到接近人类的水平。
六、结论
基于深度强化学习的AI Agent在游戏智能体中的应用展示了从 简单规则学习 到 复杂策略形成 的跨越式发展。通过DQN、PPO、A3C等算法,AI Agent在Atari、Dota2、星际争霸II等环境中取得了突破性成果。然而,当前仍面临样本效率、泛化能力和可解释性等挑战。未来的发展方向包括 高效采样方法、多智能体协同、模仿学习与人类先验结合、迁移学习和神经符号融合。随着算法与算力的不断进步,深度强化学习驱动的AI Agent将在游戏智能体乃至更广泛的人工智能应用领域中发挥更加重要的作用。
基于深度强化学习的AI Agent在游戏智能体中的应用展现了强大的潜力。通过深度神经网络与强化学习的结合,智能体能够自动学习复杂策略并适应多样化的环境。尽管仍面临数据效率、泛化能力和稳定性等挑战,但随着算法的不断优化与硬件算力的提升,深度强化学习驱动的游戏AI将在未来迎来更加广阔的发展前景。

- 点赞
- 收藏
- 关注作者
评论(0)