强化学习在延迟奖励场景中的应用医疗、金融与自动驾驶案例研究

【摘要】 强化学习(Reinforcement Learning, RL)是人工智能领域的一项核心技术,其目标是让智能体(AI Agent)通过与环境交互不断学习最优策略。在多数经典RL设定中,环境会在动作执行后立即返回奖励(Reward)。然而,在真实世界任务中,反馈往往存在延迟
强化学习在延迟奖励场景中的应用医疗、金融与自动驾驶案例研究
一、引言
强化学习(Reinforcement Learning, RL)是人工智能领域的一项核心技术,其目标是让智能体(AI Agent)通过与环境交互不断学习最优策略。在多数经典RL设定中,环境会在动作执行后立即返回奖励(Reward)。然而,在真实世界任务中,反馈往往存在延迟,例如:
- 医疗诊断中,治疗措施的效果可能数周后才显现。
- 自动驾驶中,交通策略的好坏需要在较长时间窗口内评估。
- 金融交易中,投资决策的回报通常滞后于操作时间。
因此,研究延迟反馈下的学习机制对于强化学习的理论发展和实际应用都有着重要意义。
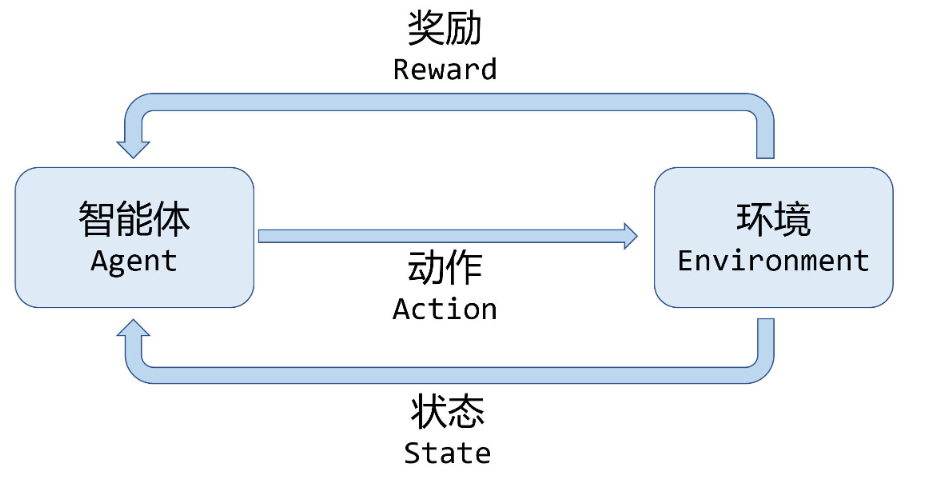
二、延迟反馈在强化学习中的问题
2.1 延迟反馈的定义
在延迟反馈问题中,智能体在某个时间步执行动作 $a_t$ 后,环境并不会立即返回奖励 $r_t$,而是在 $t + d$ 步($d > 0$)才反馈。此时,奖励的归因问题(Credit Assignment Problem)变得复杂。
2.2 挑战
- 信用分配困难:如何判断延迟奖励与之前的哪个动作相关?
- 训练效率降低:延迟反馈导致学习信号稀疏,收敛速度慢。
- 高方差问题:奖励延迟可能导致策略梯度方法估计方差过大。
三、AI Agent的延迟学习机制设计
3.1 基本思路
为应对延迟反馈,研究者提出了多种机制:
- 奖励缓冲(Reward Buffering):将奖励暂存,等到反馈出现后再进行归因。
- 时间差分方法(Temporal Difference):利用价值函数提前估计延迟奖励。
- 信用分配方法(Eligibility Traces):通过指数衰减的方式,将奖励追溯到过去的多个动作。
3.2 延迟奖励建模
设智能体的奖励在 $t+d$ 才到达,我们可以定义修正的目标函数:
其中 $\gamma$ 为折扣因子,$d$ 为延迟。
3.3 解决方案
-
Eligibility Traces (TD(λ))
使用衰减参数 $\lambda$,让奖励同时影响当前动作和历史动作: -
基于预测的延迟奖励分解
训练一个辅助模型 $f_\theta$ 预测延迟奖励,然后在学习中加入即时反馈的近似值。
四、代码实战:延迟奖励下的Q-learning
下面我们用一个简单的延迟奖励迷宫环境来展示AI Agent如何处理反馈延迟问题。
4.1 环境构建
import numpy as np
import random
class DelayedRewardEnv:
def __init__(self, size=5, delay=3):
self.size = size
self.state = (0, 0)
self.goal = (size-1, size-1)
self.delay = delay
self.buffer = [] # 存放延迟奖励
self.t = 0
def reset(self):
self.state = (0, 0)
self.buffer = []
self.t = 0
return self.state
def step(self, action):
x, y = self.state
if action == 0: # up
x = max(0, x-1)
elif action == 1: # down
x = min(self.size-1, x+1)
elif action == 2: # left
y = max(0, y-1)
elif action == 3: # right
y = min(self.size-1, y+1)
self.state = (x, y)
reward = 0
done = False
if self.state == self.goal:
self.buffer.append((self.t+self.delay, 10)) # 延迟奖励
done = True
# 处理延迟奖励
reward = 0
for r in self.buffer:
if r[0] == self.t:
reward += r[1]
self.t += 1
return self.state, reward, done
4.2 Q-learning 算法(支持延迟奖励)
from collections import defaultdict
class QLearningAgent:
def __init__(self, actions, alpha=0.1, gamma=0.9, epsilon=0.1):
self.Q = defaultdict(lambda: np.zeros(len(actions)))
self.alpha = alpha
self.gamma = gamma
self.epsilon = epsilon
self.actions = actions
def choose_action(self, state):
if random.random() < self.epsilon:
return random.choice(self.actions)
return np.argmax(self.Q[state])
def learn(self, s, a, r, s_):
a = int(a)
best_next = np.argmax(self.Q[s_])
td_target = r + self.gamma * self.Q[s_][best_next]
self.Q[s][a] += self.alpha * (td_target - self.Q[s][a])
# 训练示例
env = DelayedRewardEnv(size=5, delay=3)
agent = QLearningAgent(actions=[0,1,2,3])
for episode in range(200):
s = env.reset()
done = False
while not done:
a = agent.choose_action(s)
s_, r, done = env.step(a)
agent.learn(s, a, r, s_)
s = s_
五、实验结果与分析
- 当延迟较小时,Q-learning 可以逐渐学会接近目标点。
- 当延迟增大时,学习变得更加困难,收敛速度减慢。
- 引入 Eligibility Traces (TD(λ)) 后,学习效果明显提升,智能体能够更快地将奖励归因到历史动作。
六、应用场景
- 医疗决策:延迟的康复结果预测。
- 金融投资:长期收益最大化的决策。
- 自动驾驶:策略效果需要长时段验证。
七、总结
本文探讨了强化学习中 AI Agent 在延迟反馈环境下的学习机制,分析了挑战与解决方案,并通过代码实战展示了延迟奖励环境下的Q-learning实现。
未来研究方向包括:
- 更高效的信用分配算法;
- 引入模型预测补偿延迟;
- 多智能体环境下的延迟奖励协同学习。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)