基于AI Agent的多模态情感分析深度学习框架研究

【摘要】 情感分析(Sentiment Analysis)是自然语言处理(NLP)与计算机视觉(CV)中一项重要任务。传统的情感分析主要依赖于文本数据,但在现实应用中,情感往往通过 语言、语音、表情、姿态 等多模态信号共同传达。因此,结合 多模态深度学习 的 AI Agent 在情感理解中具有广阔的前景。
本文将探讨AI Agent如何在多模态情感分析中建模,并通过深度学习方法实现高效的情感识别。
基于AI Agent的多模态情感分析深度学习框架研究
一、引言
情感分析(Sentiment Analysis)是自然语言处理(NLP)与计算机视觉(CV)中一项重要任务。传统的情感分析主要依赖于文本数据,但在现实应用中,情感往往通过 语言、语音、表情、姿态 等多模态信号共同传达。因此,结合 多模态深度学习 的 AI Agent 在情感理解中具有广阔的前景。
本文将探讨AI Agent如何在多模态情感分析中建模,并通过深度学习方法实现高效的情感识别。
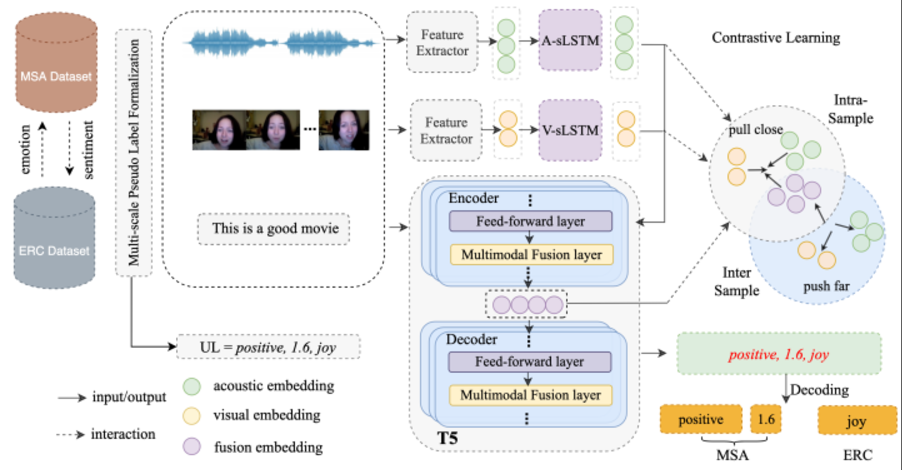
二、AI Agent与多模态情感分析框架
2.1 AI Agent在情感分析中的角色
AI Agent可被视为一个具备 感知、推理、交互 能力的智能体。在多模态情感分析中,它的任务包括:
- 感知:获取文本、语音、图像等多模态数据。
- 推理:利用深度学习模型融合不同模态的特征。
- 交互:根据情感结果进行反馈(如客服机器人根据用户情绪调整语气)。
2.2 多模态情感分析的流程
- 数据采集:获取文本(评论)、图像(表情)、语音(语调)等数据。
- 特征提取:使用预训练模型(如BERT、ResNet、Wav2Vec)提取模态特征。
- 特征融合:采用早期融合(拼接特征)或后期融合(决策级融合)。
- 情感分类:通过深度学习分类器(如Transformer或多模态注意力机制)预测情绪类别。
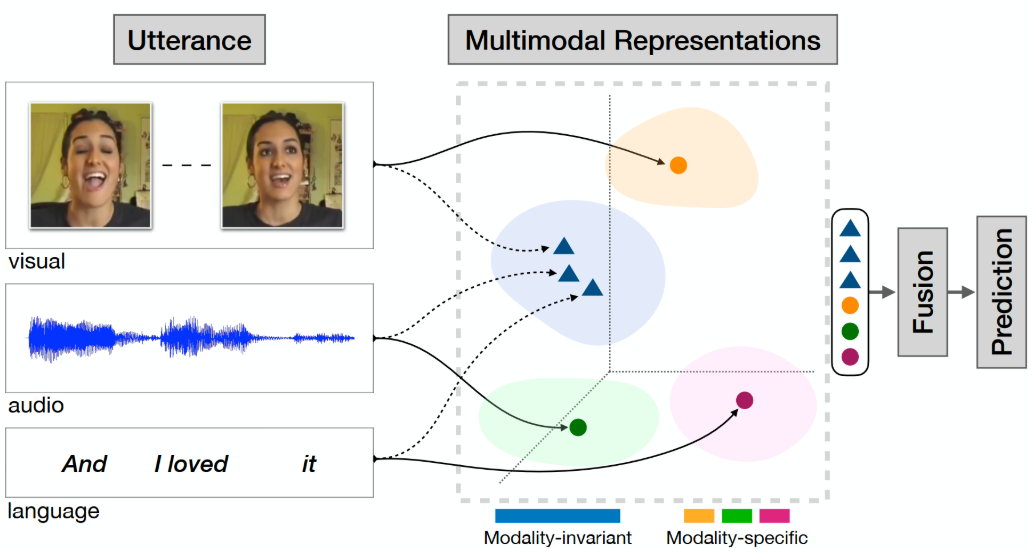
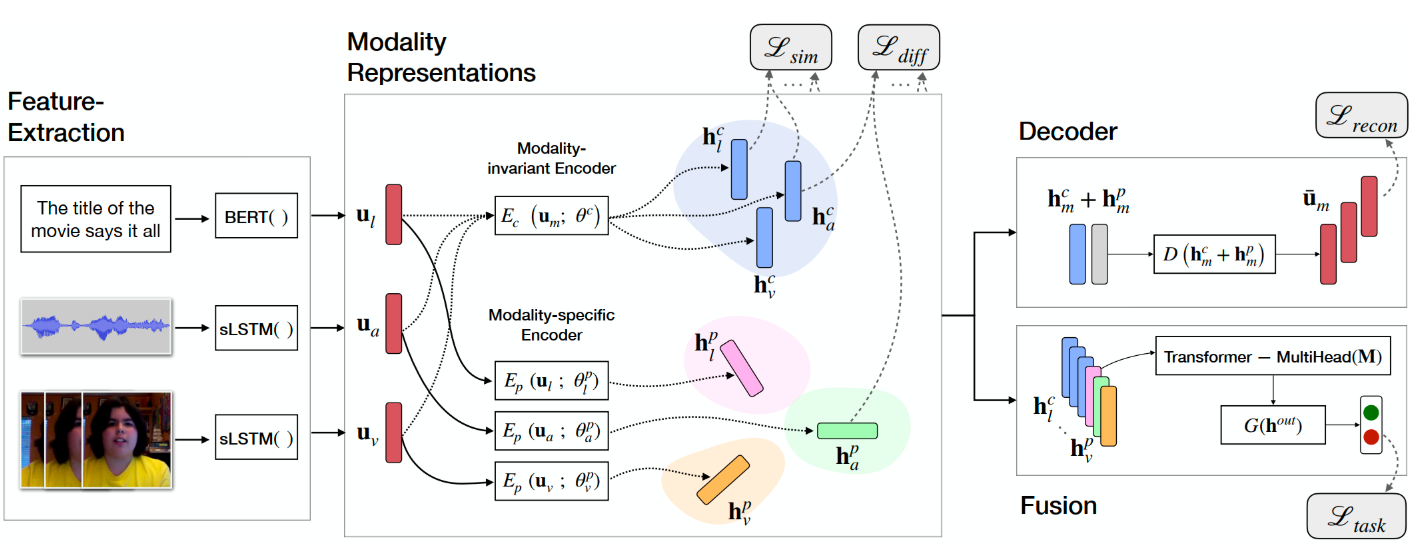
三、深度学习方法在多模态情感分析中的应用
3.1 文本特征提取
- 使用 BERT 或 RoBERTa 获取上下文语义表示。
- 文本模态在捕捉讽刺、隐喻和上下文情绪时尤为重要。
3.2 图像特征提取
- 使用 ResNet50 或 ViT(Vision Transformer) 提取面部表情特征。
- 通过卷积神经网络识别 笑容、皱眉、眼神变化 等情绪线索。
3.3 多模态融合机制
- Early Fusion:直接拼接文本和图像特征。
- Late Fusion:分别预测情感,再综合投票或加权。
- Attention Fusion:通过多头注意力机制,动态选择重要模态特征。
四、代码实战:文本 + 图像的多模态情感分析
下面给出一个简化的 PyTorch 示例,展示如何融合文本与图像特征进行情感分类。
import torch
import torch.nn as nn
from transformers import BertTokenizer, BertModel
from torchvision import models, transforms
from PIL import Image
# 1. 文本编码 (BERT)
class TextEncoder(nn.Module):
def __init__(self):
super(TextEncoder, self).__init__()
self.bert = BertModel.from_pretrained("bert-base-uncased")
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
return outputs.pooler_output # [batch, hidden_size]
# 2. 图像编码 (ResNet50)
class ImageEncoder(nn.Module):
def __init__(self):
super(ImageEncoder, self).__init__()
resnet = models.resnet50(pretrained=True)
self.feature_extractor = nn.Sequential(*list(resnet.children())[:-1])
def forward(self, x):
x = self.feature_extractor(x)
return x.view(x.size(0), -1) # [batch, feature_dim]
# 3. 多模态融合 + 分类
class MultiModalSentiment(nn.Module):
def __init__(self, text_dim=768, img_dim=2048, hidden_dim=512, num_classes=3):
super(MultiModalSentiment, self).__init__()
self.fc = nn.Sequential(
nn.Linear(text_dim + img_dim, hidden_dim),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(hidden_dim, num_classes)
)
def forward(self, text_feat, img_feat):
fusion = torch.cat([text_feat, img_feat], dim=1)
return self.fc(fusion)
# 4. 模拟推理
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
text = "I am very happy today!"
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)
# 文本编码
text_encoder = TextEncoder()
text_feat = text_encoder(inputs["input_ids"], inputs["attention_mask"])
# 图像编码
img = Image.open("happy_face.jpg").convert("RGB")
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor()
])
img_tensor = transform(img).unsqueeze(0)
img_encoder = ImageEncoder()
img_feat = img_encoder(img_tensor)
# 融合模型
model = MultiModalSentiment()
logits = model(text_feat, img_feat)
pred = torch.argmax(logits, dim=1)
print("Predicted sentiment:", pred.item()) # 输出 0=负面,1=中性,2=正面
在该示例中:
- 文本由 BERT 编码得到
[768维]特征。 - 图像由 ResNet50 编码得到
[2048维]特征。 - 两者拼接后通过全连接层分类为 负面、中性、正面。
五、挑战与未来方向
5.1 挑战
- 模态不完整问题:有时缺失图像或语音模态。
- 跨模态对齐难题:不同模态的信息存在时序和语义差异。
- 数据稀缺问题:高质量多模态标注数据较少。
5.2 未来发展
- 大规模预训练多模态模型(如 CLIP, Flamingo, GPT-4V)将成为主流。
- 情感因果推理:不仅识别情绪,还要理解其原因。
- 可解释性:让AI Agent解释“为什么判定为某种情绪”。
六、结论
AI Agent在多模态情感分析中的应用,为智能交互、虚拟助手、心理健康监测等场景提供了强大支持。借助深度学习与多模态融合技术,Agent能够更准确地理解人类情绪,实现 人机情感共鸣。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)