Python爬虫驱动高斯数据库GaussDB-小说章节采集与存储案例解析【华为根技术】

Python爬虫驱动高斯数据库GaussDB-小说章节采集与存储案例解析【华为根技术】
背景
在当今信息化高速发展的时代,数据已经成为最重要的生产力之一。无论是企业还是个人开发者,如何高效、安全地存储和管理数据,都是构建应用的关键环节。随着人工智能、大数据和云计算的普及,传统的单机数据库逐渐难以满足海量数据处理与高并发访问的需求。因此,分布式数据库应运而生,并成为各类应用系统的重要支撑。
在实际项目中,很多开发者希望通过网络爬虫获取有价值的数据,并将其存入数据库中,以便后续的数据分析与应用展示。例如,小说类数据具有文本量大、更新频繁、访问量高的特点,非常适合作为数据库存储和查询的实验案例。本次实战将通过Python爬虫采集小说内容,并存入华为云GaussDB数据库,完整演示从数据获取到数据存储的全流程。
什么是GaussDB数据库
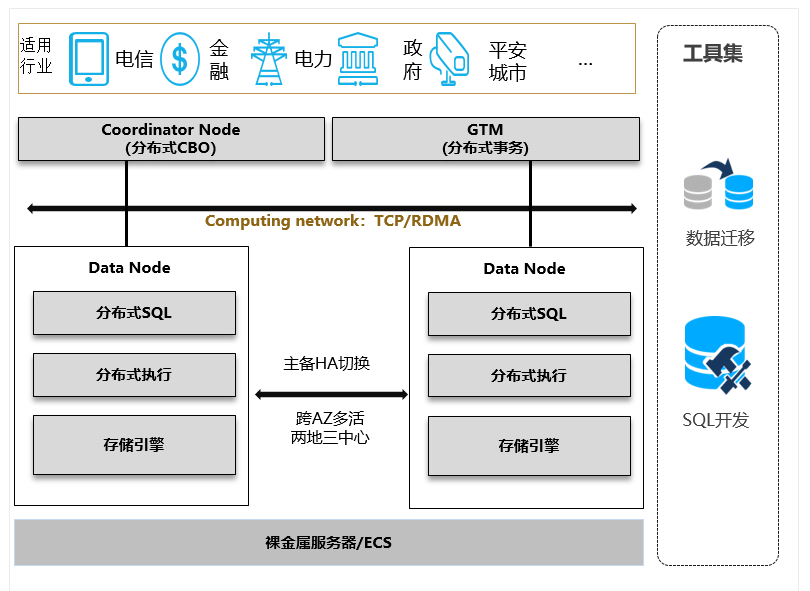
GaussDB 是华为自主研发的一款新一代分布式关系型数据库,具有高性能、高可用、高安全的特点。它基于华为多年在分布式系统、数据库内核和存储引擎方面的技术积累,支持企业级应用的关键业务场景。
主要特性包括:
-
分布式架构
GaussDB采用分布式架构,支持大规模并行处理(MPP),能够轻松扩展至数百节点,适合海量数据存储和计算场景。 -
高可用与容灾
内置多副本机制和故障转移机制,支持同城双活、跨地域容灾,确保数据零丢失和业务高可靠。 -
兼容性强
GaussDB兼容PostgreSQL、Oracle语法和生态,开发者无需大幅修改代码即可迁移现有应用,降低了学习和迁移成本。 -
弹性伸缩
根据业务需求可动态扩容或缩容,按需分配计算和存储资源,适用于云原生环境。 -
安全合规
支持全链路加密、访问控制和细粒度权限管理,满足金融、电信、政企等行业的安全要求。 -
AI赋能运维
通过智能化诊断与自优化机制,能够自动识别潜在风险并进行调优,减少了数据库管理人员的运维压力。
在实际应用中,GaussDB不仅可以支撑电商、金融、政务、游戏等行业的核心业务,还能与大数据、人工智能、区块链等技术深度结合,成为数据驱动创新的重要基石。
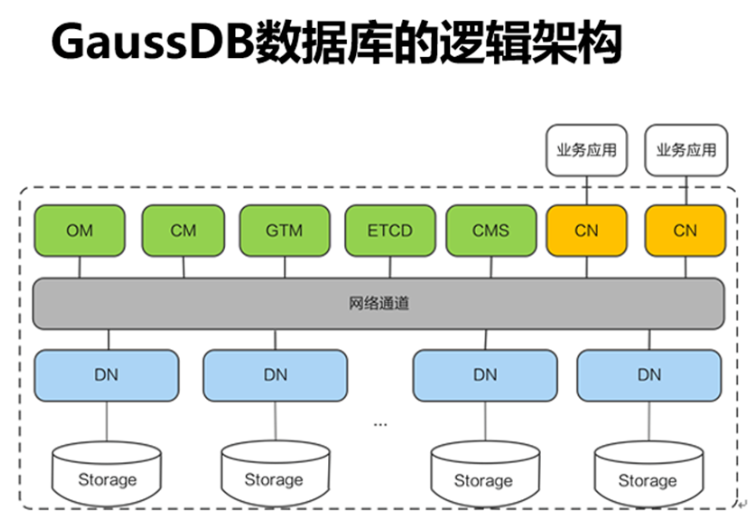
小说数据采集与GaussDB数据库存储实战
在大数据与云原生数据库广泛应用的背景下,文本类数据的采集与管理成为开发者的重要任务之一。小说文本由于体量庞大、更新频繁,既是爬虫入门的常见案例,也是数据库性能与稳定性验证的良好素材。将结合华为云 GaussDB 分布式数据库,演示一个完整的实践案例:如何通过爬虫采集小说章节,并存入 GaussDB 数据库中进行统一管理。
GaussDB 是华为自研的企业级分布式数据库,具备高性能事务处理、弹性扩展、PB级数据存储等能力,能够很好地支持高并发和大规模数据场景。本实战将展示数据库表设计、Python 连接、爬虫抓取及数据入库的完整过程。
1. 数据库初始化
在数据库端,我们首先需要创建一张用于存放小说章节的表。为保证数据唯一性和可扩展性,采用 UUID 作为主键,同时设计 title 与 content 字段来存储小说章节标题与正文。
-- 切换到默认 schema
SET search_path TO public;
-- 创建存储小说的表结构
CREATE TABLE IF NOT EXISTS public.novel (
id VARCHAR(36) PRIMARY KEY, -- 全局唯一ID
title VARCHAR(100) NOT NULL, -- 章节标题
content TEXT NOT NULL -- 章节正文
);
2. Python 连接 GaussDB
在应用端,我们通过 psycopg2 驱动完成对 GaussDB 的连接,配置信息需要替换为实际的数据库参数。
# 数据库连接配置
GAUSSDB_CONFIG = {
"host": "your_gaussdb_host",
"port": 5432,
"database": "your_db",
"user": "your_user",
"password": "your_password"
}
3. 数据写入逻辑
在核心逻辑中,程序会先检查表是否存在,不存在则自动创建。随后将小说章节批量插入数据库,并通过 ON CONFLICT 保证不会出现重复数据。
def main():
try:
# 建立连接
conn = psycopg2.connect(**GAUSSDB_CONFIG)
cursor = conn.cursor()
print("成功连接 GaussDB 数据库!")
# 创建小说表
cursor.execute("""
CREATE TABLE IF NOT EXISTS public.novel (
id VARCHAR(36) PRIMARY KEY,
title VARCHAR(100) NOT NULL,
content TEXT NOT NULL
);
""")
print("表结构检查完成")
# 插入小说数据
insert_sql = """
INSERT INTO public.novel (id, title, content)
VALUES (%s, %s, %s)
ON CONFLICT (id) DO NOTHING;
"""
cursor.executemany(insert_sql, novel_data)
conn.commit()
print("章节内容已写入数据库")
except Exception as e:
print("数据库操作失败:", e)
finally:
if cursor:
cursor.close()
if conn:
conn.close()
print("连接已关闭")
4. 爬虫抓取实现
小说章节的采集主要依赖于 requests + BeautifulSoup。首先获取目录页中所有章节链接,再依次请求正文页面并提取内容,最后调用数据库写入函数完成存储。
# 请求头,伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36'
}
server = 'XXXX'
book = 'XXX'
# 抓取章节正文
def get_contents(chapter_url):
resp = requests.get(url=chapter_url)
html = str(resp.content, 'gbk')
soup = BeautifulSoup(html, 'html.parser')
texts = soup.find_all('div', id="content")
return texts[0].text.replace('\xa0' * 4, '\n')
# 主流程
def main():
res = requests.get(book, headers=headers)
soup = BeautifulSoup(str(res.content, 'gbk'), 'html.parser')
chapters = soup.find('div', id='list').find_all('a')
print(f"共发现章节数: {len(chapters)}")
for each in chapters:
try:
url = server + each.get('href')
content = get_contents(url)
title = each.string
write_db(title, content)
except Exception as e:
print("章节处理失败:", e)
mysql.dispose()
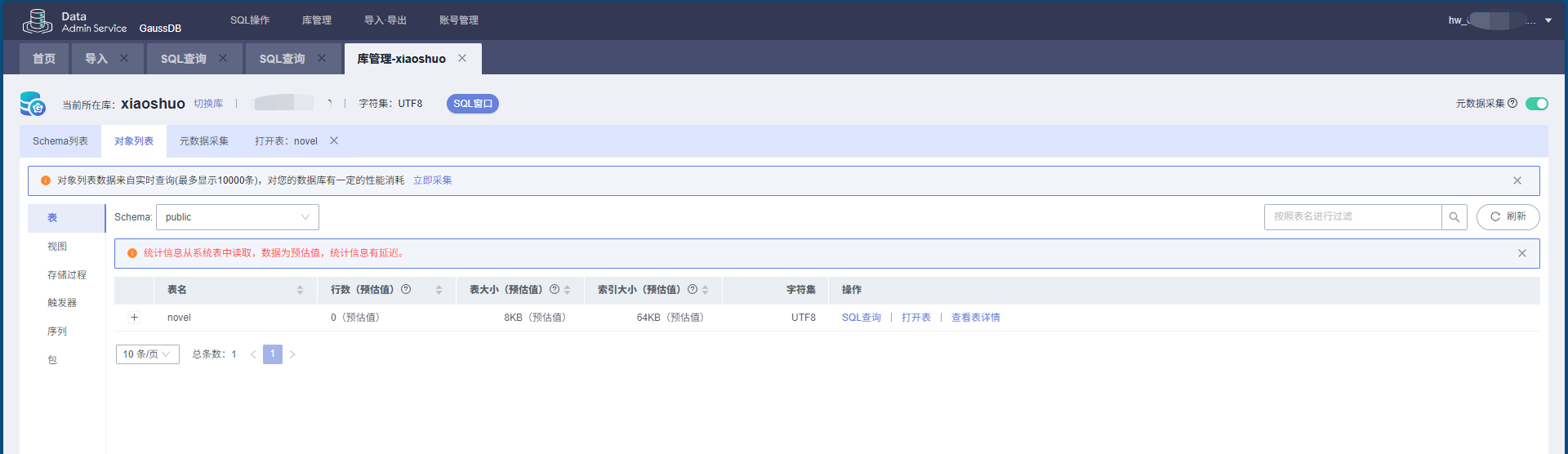
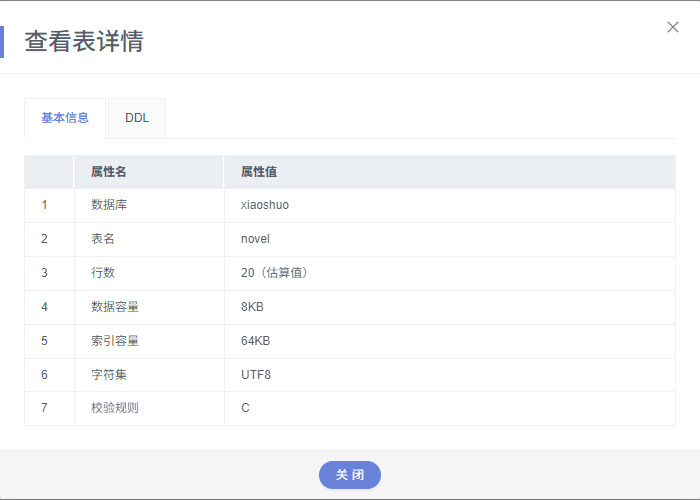
5. 数据库运行效果
当脚本执行完成后,所有的小说章节将被写入 GaussDB 数据库,可以通过数据库管理界面或 SQL 查询查看。
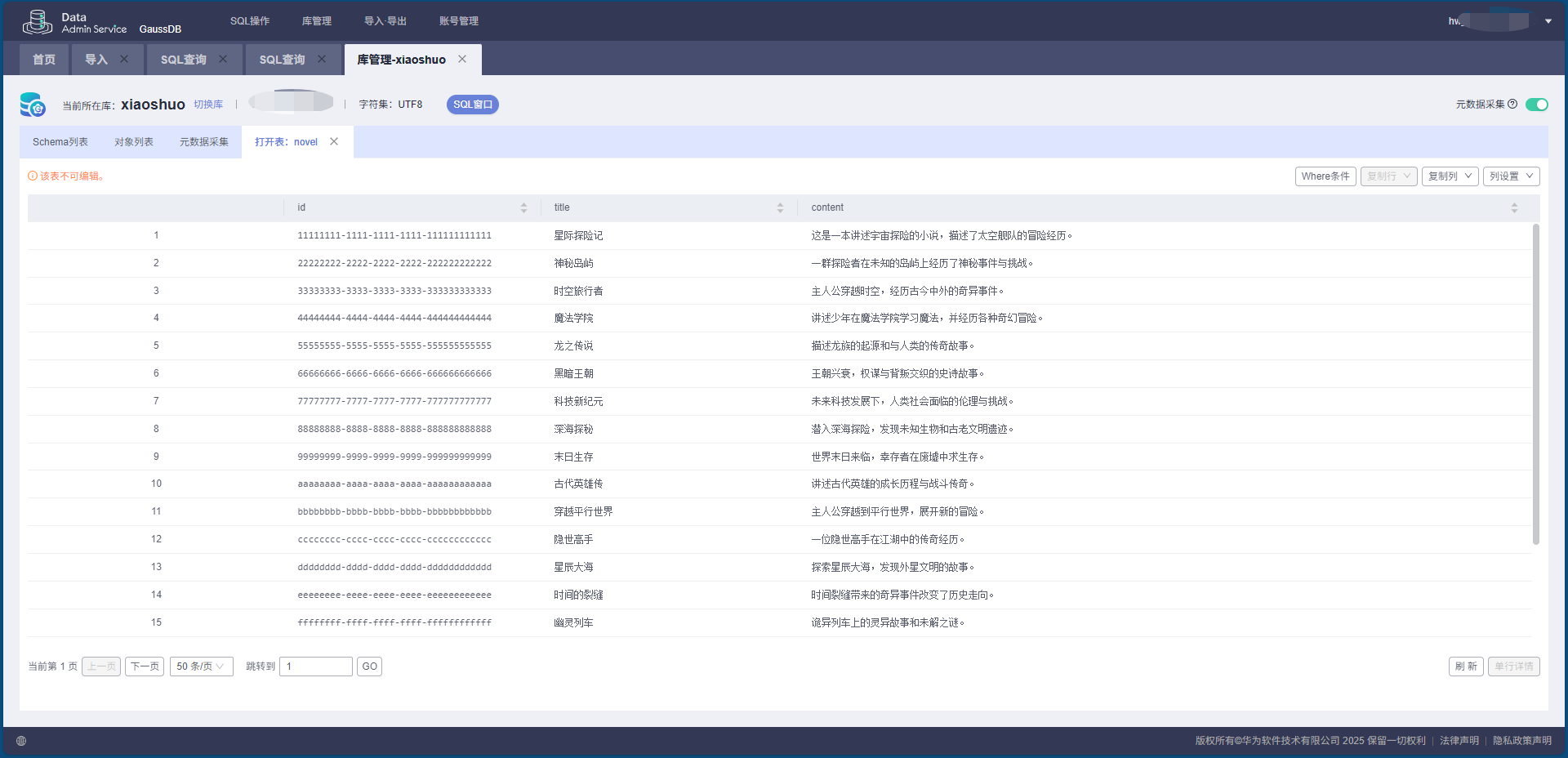
6. 实战总结
通过本次实验,我们完成了从数据采集 → 数据清洗 → 数据库存储的全链路实践,得到如下经验:
-
数据库设计方面
采用 UUID 主键与合理的字段定义,保证了数据唯一性和可维护性。 -
连接与写入方面
使用psycopg2完成数据库连接和事务提交,ON CONFLICT保证了重复数据不会造成异常。 -
爬虫抓取方面
借助requests与BeautifulSoup高效解析页面,提取并清洗章节正文,保证存储数据的规范性。 -
实践价值
将爬虫与 GaussDB 相结合,不仅能验证数据库的稳定性与扩展性,还能为文本数据存储、检索与分析提供一个清晰的解决方案。

- 点赞
- 收藏
- 关注作者
评论(0)