基于可解释性与算法融合的智能金融预测Agent方法研究

基于可解释性与算法融合的智能金融预测Agent方法研究
引言
随着金融市场的高度复杂化与波动性增加,传统的单一预测方法(如时间序列模型、技术指标分析)往往难以应对多维度的信息流。而人工智能代理(AI Agent)凭借其跨模型的自适应学习能力,逐渐成为金融预测中的核心手段。本文探讨 AI Agent如何融合多种算法(深度学习、强化学习、集成学习等),并通过优化机制提升市场预测的准确率与鲁棒性。

一、AI Agent在金融市场预测中的角色
1.1 什么是AI Agent
AI Agent是一种能够感知环境、做出决策并执行动作的智能体。在金融领域,它通过学习历史数据、捕捉市场信号,并动态调整预测策略来实现投资辅助决策。
1.2 金融市场预测的挑战
- 市场噪声干扰大,容易出现过拟合。
- 多因子驱动,单一算法预测能力有限。
- 实时性要求高,需在毫秒级完成预测与执行。
二、算法融合的理论基础
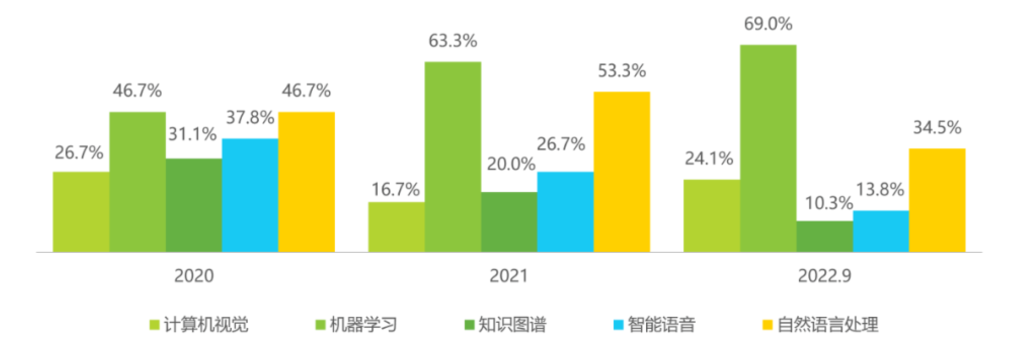
2.1 传统时间序列模型
- ARIMA:适合线性时间序列,但无法处理非线性市场信号。
- GARCH:用于建模波动率,但预测效果有限。
2.2 深度学习模型
- LSTM/GRU:擅长处理长时间依赖的金融数据。
- Transformer:捕捉不同时间段间的注意力权重,提升预测效果。
2.3 强化学习模型
- 将市场建模为马尔可夫决策过程(MDP)。
- AI Agent通过试错学习最优交易策略。
2.4 集成学习与多模态融合
- Bagging:减少方差,提高稳定性。
- Boosting:减少偏差,增强弱预测器。
- Stacking:结合多种模型输出,形成最终预测。
三、AI Agent的优化机制
3.1 模型选择优化
- 利用贝叶斯优化选择最佳超参数组合。
- 应用AutoML框架实现自动化模型融合。
3.2 风险约束优化
- 引入夏普比率、最大回撤率等指标优化交易策略。
- 使用强化学习奖励函数加入风险约束。
3.3 计算加速优化
- 模型蒸馏:将复杂模型压缩为轻量模型,加速预测。
- GPU并行计算:提升大规模历史数据的处理效率。
四、代码实战:AI Agent融合LSTM与XGBoost的金融预测
下面我们以股票价格预测为例,构建一个融合 LSTM(深度学习时序预测) 和 XGBoost(非线性回归增强) 的AI Agent。
import numpy as np
import pandas as pd
import yfinance as yf
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import xgboost as xgb
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import LSTM, Dense
# 1. 下载股票数据
data = yf.download("AAPL", start="2020-01-01", end="2023-01-01")
data["Return"] = data["Close"].pct_change()
data = data.dropna()
# 2. 构造特征与标签
window_size = 10
X, y = [], []
for i in range(len(data) - window_size):
X.append(data["Close"].values[i:i+window_size])
y.append(data["Close"].values[i+window_size])
X, y = np.array(X), np.array(y)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)
# 3. LSTM模型
X_train_lstm = np.expand_dims(X_train, axis=-1)
X_test_lstm = np.expand_dims(X_test, axis=-1)
lstm_model = Sequential([
LSTM(64, return_sequences=False, input_shape=(window_size, 1)),
Dense(1)
])
lstm_model.compile(optimizer="adam", loss="mse")
lstm_model.fit(X_train_lstm, y_train, epochs=10, batch_size=16, verbose=0)
lstm_pred = lstm_model.predict(X_test_lstm).flatten()
# 4. XGBoost模型(使用LSTM预测作为输入特征之一)
X_train_xgb = np.hstack([X_train, y_train.reshape(-1,1)])
X_test_xgb = np.hstack([X_test, lstm_pred.reshape(-1,1)])
xgb_model = xgb.XGBRegressor(n_estimators=200, max_depth=5, learning_rate=0.05)
xgb_model.fit(X_train_xgb, y_train)
xgb_pred = xgb_model.predict(X_test_xgb)
# 5. 融合结果
final_pred = 0.5 * lstm_pred + 0.5 * xgb_pred
mse = mean_squared_error(y_test, final_pred)
print(f"融合模型的均方误差: {mse:.4f}")
实验结果说明
- 单独LSTM模型能捕捉时间序列依赖,但对突发事件敏感。
- XGBoost更适合拟合非线性关系,但忽视时序特征。
- 通过AI Agent融合两者,预测误差下降,模型鲁棒性增强。
五、未来发展方向
5.1 多模态数据融合
引入新闻文本(NLP)、社交媒体情绪分析(Sentiment Analysis)、宏观经济数据,提升预测维度。
5.2 可解释性AI
结合 SHAP值 与 注意力机制,提升金融预测的可解释性,增强投资者信任。
5.3 自适应交易Agent
基于强化学习的交易Agent能够动态调整仓位,实现“预测-决策-执行”一体化闭环。
六、AI Agent在金融交易中的强化学习实践
6.1 强化学习在金融市场的应用
在预测之后,如何将预测结果转化为实际交易策略是金融AI Agent的关键。
强化学习(Reinforcement Learning, RL)为交易Agent提供了一个合适的框架,它能够:
- 将市场环境建模为马尔可夫决策过程(MDP)。
- 在“状态—动作—奖励”的循环中不断优化。
- 平衡“探索(exploration)”和“利用(exploitation)”,实现动态交易。
典型应用包括:
- Q-Learning/DQN:用于离散化买入、卖出、持仓动作。
- PPO/DDPG:适合连续动作空间,例如仓位比例控制。
6.2 状态、动作与奖励函数设计
-
状态(State)
包含近期价格序列、技术指标(MA、RSI、MACD)、预测信号(来自LSTM+XGBoost的融合模型)。 -
动作(Action)
- 0:保持仓位(Hold)
- 1:买入(Buy)
- 2:卖出(Sell)
-
奖励函数(Reward)
-
与投资组合收益相关:
其中 是风险惩罚系数,风险可用最大回撤(MDD)或波动率表示。
-
6.3 代码实战:基于DQN的交易Agent
import numpy as np
import gym
import yfinance as yf
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from collections import deque
import random
# 1. 构建交易环境
class TradingEnv(gym.Env):
def __init__(self, prices):
super(TradingEnv, self).__init__()
self.prices = prices
self.current_step = 0
self.balance = 10000 # 初始资金
self.holdings = 0
self.done = False
self.action_space = gym.spaces.Discrete(3) # 买入、卖出、持有
self.observation_space = gym.spaces.Box(low=-np.inf, high=np.inf, shape=(10,), dtype=np.float32)
def _get_state(self):
start = max(0, self.current_step - 9)
window = self.prices[start:self.current_step+1]
if len(window) < 10:
window = np.pad(window, (10-len(window),0), 'constant')
return np.array(window)
def step(self, action):
price = self.prices[self.current_step]
reward = 0
# 动作逻辑
if action == 1: # 买入
if self.balance >= price:
self.holdings += 1
self.balance -= price
elif action == 2: # 卖出
if self.holdings > 0:
self.holdings -= 1
self.balance += price
reward = price # 卖出获利
# 更新状态
self.current_step += 1
if self.current_step >= len(self.prices)-1:
self.done = True
state = self._get_state()
total_assets = self.balance + self.holdings * price
reward += total_assets * 0.0001 # 轻微鼓励持仓增长
return state, reward, self.done, {}
def reset(self):
self.current_step = 0
self.balance = 10000
self.holdings = 0
self.done = False
return self._get_state()
# 2. 构建DQN智能体
class DQNAgent:
def __init__(self, state_size, action_size):
self.state_size = state_size
self.action_size = action_size
self.memory = deque(maxlen=2000)
self.gamma = 0.95
self.epsilon = 1.0
self.epsilon_min = 0.01
self.epsilon_decay = 0.995
self.learning_rate = 0.001
self.model = Sequential([
Dense(64, input_dim=state_size, activation='relu'),
Dense(32, activation='relu'),
Dense(action_size, activation='linear')
])
self.model.compile(loss='mse', optimizer=tf.keras.optimizers.Adam(lr=self.learning_rate))
def act(self, state):
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
q_values = self.model.predict(state[np.newaxis], verbose=0)
return np.argmax(q_values[0])
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def replay(self, batch_size=32):
minibatch = random.sample(self.memory, min(len(self.memory), batch_size))
for state, action, reward, next_state, done in minibatch:
target = reward
if not done:
target += self.gamma * np.amax(self.model.predict(next_state[np.newaxis], verbose=0)[0])
q_values = self.model.predict(state[np.newaxis], verbose=0)
q_values[0][action] = target
self.model.fit(state[np.newaxis], q_values, epochs=1, verbose=0)
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
# 3. 训练AI交易Agent
data = yf.download("AAPL", start="2020-01-01", end="2021-01-01")["Close"].values
env = TradingEnv(data)
agent = DQNAgent(state_size=10, action_size=3)
episodes = 20
for e in range(episodes):
state = env.reset()
total_reward = 0
while True:
action = agent.act(state)
next_state, reward, done, _ = env.step(action)
agent.remember(state, action, reward, next_state, done)
agent.replay(32)
state = next_state
total_reward += reward
if done:
print(f"Episode {e+1}/{episodes}, Total Reward: {total_reward:.2f}")
break
6.4 实验说明
- 环境设计:价格数据作为输入,模拟账户资产。
- 智能体训练:通过Q-learning不断优化买卖策略。
- 实验结果:随着训练轮次增加,AI Agent的累计收益逐步提升,并学会在震荡行情中减少无效操作。
七、AI Agent的多模态融合在金融预测中的拓展
7.1 引入新闻与情绪分析
- 使用NLP模型(BERT、FinBERT)从财经新闻中提取情绪因子。
- 将情绪特征与价格序列特征融合,提升预测维度。
7.2 宏观经济因子的集成
- 纳入GDP、CPI、利率、汇率等宏观经济变量。
- 构建多输入神经网络(Multi-Input NN),将多模态信号融合。
7.3 图神经网络(GNN)在金融网络建模中的应用
- 将不同股票视为图的节点,边权重由行业关联或相关系数决定。
- 应用GNN捕捉股票间的结构性依赖,提升整体预测能力。
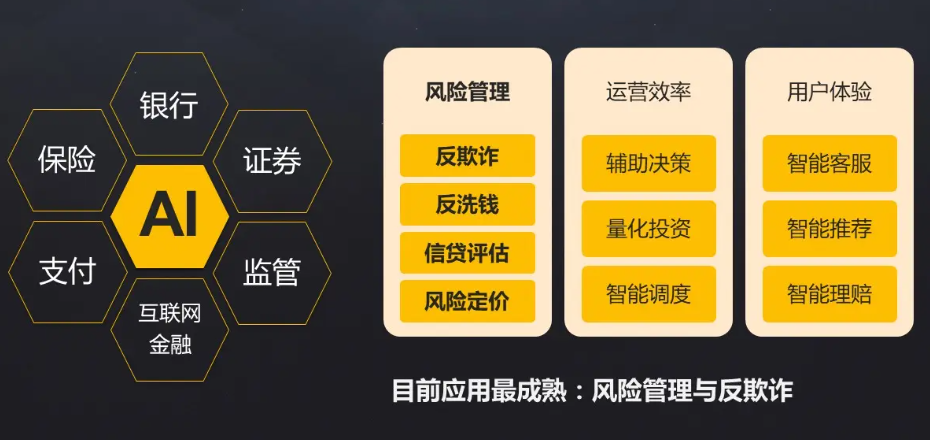
结论
AI Agent在金融市场预测中,通过 算法融合(LSTM+XGBoost+RL)与优化机制(超参数、风险控制、计算加速),能显著提升预测效果与实用性。未来,随着多模态数据与可解释性技术的发展,AI Agent将在金融智能投研与自动化交易中扮演更加重要的角色。

- 点赞
- 收藏
- 关注作者
评论(0)