如何使用 Python 开发 AI 图编排应用

如何使用 Python 开发 AI 图编排应用
本文将介绍使用Python开发一个简单的AI图编排应用,我们的目标是实现AI应用在RK3588上灵活编排和高效部署。首先我们定义的图是由边和节点组成的有向无环图,边代表任务队列,表示数据在节点之间的流动关系,每个节点都是一个计算单元,用于处理特定的任务。之后我们可以定义一组的处理特定任务的函数节点也称为计算单元,例如:read_frame、model_infer、kf_tracker、draw_boxes、push_frame、redis_push,分别用于读取视频、模型检测、目标跟踪、图像绘制、视频输出以及结果推送。每个节点可以有一个输入和多个输出,数据在节点之间是单向流动的,节点之间通过边进行连接,每个节点通过队列消费和传递数据。
代码地址:https://github.com/HouYanSong/modelbox-rk3588
一. 计算节点的实现
我们在Json文件中定义每一个节点的的数据结构并使用Python进行代码实现:
- 读流计算单元有4个参数:
pull_video_url、height、width、fps,分别代表视频地址、视频高度和宽度以及读取帧率,它仅作为生产者,产生的数据可以输出到多个队列。
"read_frame": {
"config": {
"pull_video_url": {
"type": "str",
"required": true,
"default": null,
"desc": "pull video url",
"source": "mp4|flv|rtmp|rtsp"
},
"height": {
"type": "int",
"required": true,
"default": null,
"max": 1440,
"min": 720,
"desc": "video height"
},
"width": {
"type": "int",
"required": true,
"default": null,
"max": 1920,
"min": 960,
"desc": "video width"
},
"fps": {
"type": "int",
"required": true,
"default": null,
"max": 15,
"min": 5,
"desc": "frame rate"
}
},
"multi_output": []
}
函数代码的实现如下,我们可以对视频文件或者视频流使用ffmpeg进行硬件解码,并将解码后的帧数据写入到队列中,用于后续任务节点的计算。
def read_frame(share_dict, flowunit_data, queue_dict, data):
pull_video_url = flowunit_data["config"]["pull_video_url"]
height = flowunit_data["config"]["height"]
width = flowunit_data["config"]["width"]
fps = flowunit_data["config"]["fps"]
ffmpeg_cmd = [
'ffmpeg',
'-c:v', 'h264_rkmpp',
'-i', pull_video_url,
'-r', f'{fps}',
'-loglevel', 'info',
'-s', f'{width}x{height}',
'-an', '-f', 'rawvideo', '-pix_fmt', 'bgr24', 'pipe:'
]
ffmpeg_process = sp.Popen(ffmpeg_cmd, stdout=sp.PIPE, stderr=sp.DEVNULL, bufsize=10**7)
index = 0
while True:
index += 1
raw_frame = ffmpeg_process.stdout.read(width * height * 3)
if not raw_frame:
break
else:
frame = np.frombuffer(raw_frame, dtype=np.uint8).reshape((height, width, -1))
data["frame"] = frame
for queue_name in flowunit_data["multi_output"]:
queue_dict[queue_name].put(data)
# 读取结束,图片数据置为None
data["frame"] = None
for queue_name in flowunit_data["multi_output"]:
queue_dict[queue_name].put(data)
ffmpeg_process.stdout.close()
ffmpeg_process.terminate()
- 推理计算单元的函数定义如下,它有一个输入和多个输出,我们可以指定模型和配置文件路径以及单次图像推理的批次大小等参数。
"model_infer": {
"config": {
"model_file": {
"type": "str",
"required": true,
"default": null,
"desc": "model file path, rk3588 mostly ends with .rknn"
},
"model_info": {
"type": "str",
"required": true,
"default": null,
"desc": "model info file path, mostly use json file"
},
"batch_size": {
"type": "int",
"required": true,
"default": null,
"max": 8,
"min": 1,
"desc": "batch size"
}
},
"single_input": null,
"multi_output": []
}
对应的函数实现如下,这里我们通过创建线程池的方式对图像进行批量推理,BatchSize的大小代表创建线程池的数量,将一个批次的推理结果写入到输出队列中,输出队列不唯一,可以为空或有多个输出队列。
def model_infer(share_dict, flowunit_data, queue_dict, data):
model_file = flowunit_data["config"]["model_file"]
model_info = flowunit_data["config"]["model_info"]
batch_size = flowunit_data["config"]["batch_size"]
rknn_lite_list = []
for i in range(batch_size):
rknn_lite = RKNNLite()
rknn_lite.load_rknn(model_file)
rknn_lite.init_runtime(core_mask=RKNNLite.NPU_CORE_0_1_2)
rknn_lite_list.append(rknn_lite)
with open(model_info, "r") as f:
model_info = json.load(f)
labels = []
for label in list(model_info["model_classes"].values()):
labels.append(label)
IMG_SIZE = model_info["input_shape"][0][-2:]
OBJ_THRESH = model_info["conf_threshold"]
NMS_THRESH = model_info["nms_threshold"]
exist = False
index = 0
while True:
index += 1
image_batch = []
if flowunit_data["single_input"] is not None:
for i in range(batch_size):
data = queue_dict[flowunit_data["single_input"]].get()
# 图片数据为None就退出循环
if data["frame"] is None:
exist = True
break
image_batch.append(data)
else:
break
with ThreadPoolExecutor(max_workers=batch_size) as executor:
results = list(executor.map(infer_single_image,
[(data["frame"], rknn_lite_list[i % batch_size],
IMG_SIZE, OBJ_THRESH, NMS_THRESH) for i, data in enumerate(image_batch)]))
for i, (boxes, classes, scores) in enumerate(results):
classes = [labels[class_id] for class_id in classes]
data = image_batch[i]
if data.get("boxes") is None:
data["boxes"] = boxes
data["classes"] = classes
data["scores"] = scores
else:
data["boxes"].extend(boxes)
data["classes"].extend(classes)
data["scores"].extend(scores)
for queue_name in flowunit_data["multi_output"]:
queue_dict[queue_name].put(data)
if exist:
break
# 读取结束,图片数据置为None
data["frame"] = None
for queue_name in flowunit_data["multi_output"]:
queue_dict[queue_name].put(data)
for rknn_lite in rknn_lite_list:
rknn_lite.release()
- 跟踪功能单元的可以对推理结果添加跟踪ID,如果没有推理结果,则直接返回原始数据,其定义如下:
"kf_tracker": {
"config": {},
"single_input": null,
"multi_output": []
}
对应的函数代码实现如下:
def kf_tracker(share_dict, flowunit_data, queue_dict, data):
tracker = CentroidKF_Tracker(max_lost=30)
index = 0
while True:
index += 1
if flowunit_data["single_input"] is not None:
data = queue_dict[flowunit_data["single_input"]].get()
else:
break
# 图片数据为None就退出循环
if data["frame"] is None:
break
boxes, classes, scores = data.get("boxes"), data.get("classes"), data.get("scores")
boxes = np.array(boxes)
classes = np.array(classes)
scores = np.array(scores)
boxes[:, 2] = boxes[:, 2] - boxes[:, 0]
boxes[:, 3] = boxes[:, 3] - boxes[:, 1]
results = tracker.update(boxes, scores, classes)
boxes = []
classes = []
scores = []
tracks = []
for result in results:
frame_num, id, bb_left, bb_top, bb_width, bb_height, confidence, x, y, z, class_id = result
boxes.append([bb_left, bb_top, bb_left + bb_width, bb_top + bb_height])
classes.append(class_id)
scores.append(confidence)
tracks.append(id)
data["boxes"] = boxes
data["classes"] = classes
data["scores"] = scores
data["tracks"] = tracks
for queue_name in flowunit_data["multi_output"]:
queue_dict[queue_name].put(data)
# 读取结束,图片数据置为None
data["frame"] = None
for queue_name in flowunit_data["multi_output"]:
queue_dict[queue_name].put(data)
- 绘制功能单元可以对检测和跟踪结果进行绘制,如果检测结果或跟踪结果为空,则直接返回原始数据,其定义如下:
"draw_boxes": {
"single_input": null,
"config": {},
"multi_output": []
}
代码逻辑如下:
def draw_boxes(share_dict, flowunit_data, queue_dict, data):
index = 0
while True:
index += 1
if flowunit_data["single_input"] is not None:
data = queue_dict[flowunit_data["single_input"]].get()
else:
break
# 图片数据为None就退出循环
if data["frame"] is None:
break
boxes, classes, scores = data.get("boxes"), data.get("classes"), data.get("scores")
if boxes is not None:
tracks = data.get("tracks")
if tracks is not None:
for boxe, clss, track in zip(boxes, classes, tracks):
cv2.rectangle(data["frame"], (boxe[0], boxe[1]), (boxe[2], boxe[3]), (0, 255, 0), 2)
cv2.putText(data["frame"], f"{clss} {track}", (boxe[0], boxe[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
else:
for boxe, clss, conf in zip(boxes, classes, scores):
cv2.rectangle(data["frame"], (boxe[0], boxe[1]), (boxe[2], boxe[3]), (0, 255, 0), 2)
cv2.putText(data["frame"], f"{clss} {conf * 100:.2f}%", (boxe[0], boxe[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
for queue_name in flowunit_data["multi_output"]:
queue_dict[queue_name].put(data)
# 读取结束,图片数据置为None
data["frame"] = None
for queue_name in flowunit_data["multi_output"]:
queue_dict[queue_name].put(data)
- 输出功能单元可以将视频帧编码成视频输到到视频文件或者推流到
RTMP服务器,其参数定义如下:
"push_frame": {
"config": {
"push_video_url": {
"type": "str",
"required": true,
"default": null,
"desc": "push video url",
"source": "rtmp|flv|mp4"
},
"format": {
"type": "str",
"required": true,
"default": null,
"desc": "vodeo format",
"source": "flv|mp4"
},
"height": {
"type": "int",
"required": true,
"default": null,
"max": 1920,
"min": 720,
"desc": "video height"
},
"width": {
"type": "int",
"required": true,
"default": null,
"max": 1920,
"min": 960,
"desc": "video width"
},
"fps": {
"type": "int",
"required": true,
"default": null,
"max": 15,
"min": 5,
"desc": "frame rate"
}
},
"single_input": null
}
push_video_url参数是推流地址,也可以输出到本地视频文件。format参数指定视频格式,支持flv和mp4。height和width为视频分辨率,fps是输出帧率。它仅作为消费者,具体函数代码实现如下:
def push_frame(share_dict, flowunit_data, queue_dict, data):
push_video_url = flowunit_data["config"]["push_video_url"]
format = flowunit_data["config"]["format"]
height = flowunit_data["config"]["height"]
width = flowunit_data["config"]["width"]
fps = flowunit_data["config"]["fps"]
process_stdin = (
ffmpeg
.input('pipe:',
format='rawvideo',
pix_fmt='bgr24',
s="{}x{}".format(width, height),
framerate=fps)
.filter('fps',
fps=fps,
round='up')
.output(
push_video_url,
vcodec='h264_rkmpp',
bitrate='2500k',
f=format,
g=fps,
an=None,
timeout='0'
)
.overwrite_output()
.run_async(cmd=["ffmpeg", "-re"], pipe_stdin=True)
)
index = 0
while True:
index += 1
if flowunit_data["single_input"] is not None:
data = queue_dict[flowunit_data["single_input"]].get()
else:
break
# 图片数据为None就退出循环
if data["frame"] is None:
break
frame = data["frame"]
frame = cv2.resize(frame, (width, height))
process_stdin.stdin.write(frame.tobytes())
process_stdin.stdin.close()
process_stdin.terminate()
- 消息功能单元可以将检测或跟踪结果发送到
Redis服务器,具体可以根据实际情况进行调整。
"redis_push": {
"config": {
"task_id": {
"type": "str",
"required": true,
"default": null,
"desc": "task id"
},
"host": {
"type": "str",
"required": true,
"default": null,
"desc": "redis host"
},
"port": {
"type": "int",
"required": true,
"default": null,
"desc": "redis port"
},
"username": {
"type": "str",
"required": true,
"default": null,
"desc": "redis username"
},
"password": {
"type": "str",
"required": true,
"default": null,
"desc": "redis password"
},
"db": {
"type": "int",
"required": true,
"default": null,
"desc": "redis db"
}
},
"single_input": null
}
同样,它也仅作为消费者,只有一个输入,具体函数代码如下:
def redis_push(share_dict, flowunit_data, queue_dict, data):
task_id = flowunit_data["config"]["task_id"]
host = flowunit_data["config"]["host"]
port = flowunit_data["config"]["port"]
username = flowunit_data["config"]["username"]
password = flowunit_data["config"]["password"]
db = flowunit_data["config"]["db"]
r = redis.Redis(
host = host,
port = port,
username = username,
password = password,
db = db,
decode_responses = True
)
index = 0
while True:
index += 1
if flowunit_data["single_input"] is not None:
data = queue_dict[flowunit_data["single_input"]].get()
else:
break
# 图片数据为None就退出循环
if data["frame"] is None:
break
track_objs = []
height, width = data["frame"].shape[:2]
boxes, classes, scores, tracks = data.get("boxes"), data.get("classes"), data.get("scores"), data.get("tracks")
if boxes is not None:
for boxe, clss, conf, track in zip(boxes, classes, scores, tracks):
x1 = float(boxe[0] / width)
y1 = float(boxe[1] / height)
x2 = float(boxe[2] / width)
y2 = float(boxe[3] / height)
track_obj = {
"bbox": [x1, y1, x2, y2],
"track_id": int(track),
"class_id": 0,
"class_name": str(clss)
}
track_objs.append(track_obj)
key = 'vision:track:' + str(task_id) + ':frame:' + str(index)
value = json.dumps({"track_result": track_objs})
r.set(key, value)
r.expire(key, 2)
print(track_objs)
r.close()
二、流程图编排
定义好节点,我们就可以定义管道也就是“边”将“节点”的输入和输出连接起来,这里我们定义6条边也就是实例化6个队列,在配置文件中声明每条管道的名称以及队列的最大容量。
"queue_size": 16,
"queue_list": [
"frame_queue",
"infer_queue_1",
"infer_queue_2",
"track_queue",
"draw_queue_1",
"draw_queue_2"
]
之后就是对每一个节点的参数进行配置,并定义功能单元的输入和输出。
"graph_edge": {
"读流功能单元": {
"read_frame": {
"config": {
"pull_video_url": "/home/orangepi/workspace/modelbox/data/car.mp4",
"height": 720,
"width": 1280,
"fps": 20
},
"multi_output": [
"frame_queue"
]
}
},
"推理功能单元": {
"model_infer": {
"config": {
"model_file": "/home/orangepi/workspace/modelbox/model/yolov8n_800x800_int8.rknn",
"model_info": "/home/orangepi/workspace/modelbox/model/yolov8n_800x800_int8.json",
"batch_size": 8
},
"single_input": "frame_queue",
"multi_output": [
"infer_queue_1",
"infer_queue_2"
]
}
},
"跟踪功能单元_2": {
"kf_tracker": {
"config": {},
"single_input": "infer_queue_2",
"multi_output": [
"track_queue"
]
}
},
"绘图功能单元_1": {
"draw_boxes": {
"config": {},
"single_input": "infer_queue_1",
"multi_output": [
"draw_queue_1"
]
}
},
"绘图功能单元_2": {
"draw_boxes": {
"single_input": "track_queue",
"config": {},
"multi_output": [
"draw_queue_2"
]
}
},
"推流功能单元_1": {
"push_frame": {
"config": {
"push_video_url": "/home/orangepi/workspace/modelbox/output/det_result.mp4",
"format": "mp4",
"height": 720,
"width": 1280,
"fps": 20
},
"single_input": "draw_queue_1"
}
},
"推流功能单元_2": {
"push_frame": {
"config": {
"push_video_url": "/home/orangepi/workspace/modelbox/output/track_result.mp4",
"format": "mp4",
"height": 720,
"width": 1280,
"fps": 20
},
"single_input": "draw_queue_2"
}
}
}
每个功能单元需要起一个节点名称用于功能单元的创建,每个节点名称保证全局唯一,正如字典中的键值不能重复。之后根据这份图文件编排启动AI应用,Python代码如下:
import os
import sys
import json
import argparse
sys.path.append(os.path.join(os.path.dirname(__file__), '..'))
from etc.flowunit import *
from multiprocessing import Process, Queue, Manager
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('graph_path', type=str, nargs='?', default='/home/orangepi/workspace/modelbox/graph/person_car.json')
args = parser.parse_args()
# 初始化数据
data = {"frame": None}
config = {}
# 读取流程图
with open(args.graph_path) as f:
graph = json.load(f)
# 创建队列
queue_dict = {}
queue_size = graph["queue_size"]
for queue_name in graph["queue_list"]:
queue_dict[queue_name] = Queue(maxsize=queue_size)
with Manager() as manager:
# 创建共享字典
share_dict = manager.dict()
# 创建进程
process_list = []
graph_edge = graph["graph_edge"]
for process in graph_edge.keys():
p = Process(target=eval(list(graph_edge[process].keys())[0]), args=(share_dict, list(graph_edge[process].values())[0], queue_dict, data,))
process_list.append(p)
print("=============Start Process...=============")
# 启动进程
for p in process_list:
p.start()
# 等待进程结束
for p in process_list:
p.join()
print("==========All Process Finished.===========")
这里我们读取一段测试视频分别将检测结果和跟踪结果保存为两个视频文件输出到output目录下:
(python-3.9.15) orangepi@orangepi5plus:~$ python /home/orangepi/workspace/modelbox/graph/graph.py /home/orangepi/workspace/modelbox/graph/person_car.json
=============Start Process...=============
ffmpeg version 04f5eaa Copyright (c) 2000-2023 the FFmpeg developers
built with gcc 11 (Ubuntu 11.4.0-1ubuntu1~22.04)
configuration: --prefix=/usr --enable-gpl --enable-version3 --enable-libdrm --enable-rkmpp --enable-rkrga
libavutil 58. 29.100 / 58. 29.100
libavcodec 60. 31.102 / 60. 31.102
libavformat 60. 16.100 / 60. 16.100
libavdevice 60. 3.100 / 60. 3.100
libavfilter 9. 12.100 / 9. 12.100
libswscale 7. 5.100 / 7. 5.100
libswresample 4. 12.100 / 4. 12.100
libpostproc 57. 3.100 / 57. 3.100
ffmpeg version 04f5eaa Copyright (c) 2000-2023 the FFmpeg developers
built with gcc 11 (Ubuntu 11.4.0-1ubuntu1~22.04)
configuration: --prefix=/usr --enable-gpl --enable-version3 --enable-libdrm --enable-rkmpp --enable-rkrga
libavutil 58. 29.100 / 58. 29.100
libavcodec 60. 31.102 / 60. 31.102
libavformat 60. 16.100 / 60. 16.100
libavdevice 60. 3.100 / 60. 3.100
libavfilter 9. 12.100 / 9. 12.100
libswscale 7. 5.100 / 7. 5.100
libswresample 4. 12.100 / 4. 12.100
libpostproc 57. 3.100 / 57. 3.100
W rknn-toolkit-lite2 version: 2.3.2
I RKNN: [13:10:47.190] RKNN Runtime Information, librknnrt version: 2.3.2 (429f97ae6b@2025-04-09T09:09:27)
I RKNN: [13:10:47.191] RKNN Driver Information, version: 0.9.6
I RKNN: [13:10:47.192] RKNN Model Information, version: 2, toolkit version: 1.4.0-22dcfef4(compiler version: 1.4.0 (3b4520e4f@2022-09-05T12:50:09)), target: RKNPU v2, target platform: rk3588, framework name: ONNX, framework layout: NCHW, model inference type: static_shape
W RKNN: [13:10:47.248] query RKNN_QUERY_INPUT_DYNAMIC_RANGE error, rknn model is static shape type, please export rknn with dynamic_shapes
W Query dynamic range failed. Ret code: RKNN_ERR_MODEL_INVALID. (If it is a static shape RKNN model, please ignore the above warning message.)
W rknn-toolkit-lite2 version: 2.3.2
I RKNN: [13:10:47.338] RKNN Runtime Information, librknnrt version: 2.3.2 (429f97ae6b@2025-04-09T09:09:27)
I RKNN: [13:10:47.338] RKNN Driver Information, version: 0.9.6
I RKNN: [13:10:47.339] RKNN Model Information, version: 2, toolkit version: 1.4.0-22dcfef4(compiler version: 1.4.0 (3b4520e4f@2022-09-05T12:50:09)), target: RKNPU v2, target platform: rk3588, framework name: ONNX, framework layout: NCHW, model inference type: static_shape
W RKNN: [13:10:47.384] query RKNN_QUERY_INPUT_DYNAMIC_RANGE error, rknn model is static shape type, please export rknn with dynamic_shapes
W Query dynamic range failed. Ret code: RKNN_ERR_MODEL_INVALID. (If it is a static shape RKNN model, please ignore the above warning message.)
W rknn-toolkit-lite2 version: 2.3.2
I RKNN: [13:10:47.459] RKNN Runtime Information, librknnrt version: 2.3.2 (429f97ae6b@2025-04-09T09:09:27)
I RKNN: [13:10:47.459] RKNN Driver Information, version: 0.9.6
I RKNN: [13:10:47.460] RKNN Model Information, version: 2, toolkit version: 1.4.0-22dcfef4(compiler version: 1.4.0 (3b4520e4f@2022-09-05T12:50:09)), target: RKNPU v2, target platform: rk3588, framework name: ONNX, framework layout: NCHW, model inference type: static_shape
W RKNN: [13:10:47.504] query RKNN_QUERY_INPUT_DYNAMIC_RANGE error, rknn model is static shape type, please export rknn with dynamic_shapes
W Query dynamic range failed. Ret code: RKNN_ERR_MODEL_INVALID. (If it is a static shape RKNN model, please ignore the above warning message.)
W rknn-toolkit-lite2 version: 2.3.2
I RKNN: [13:10:47.606] RKNN Runtime Information, librknnrt version: 2.3.2 (429f97ae6b@2025-04-09T09:09:27)
I RKNN: [13:10:47.606] RKNN Driver Information, version: 0.9.6
I RKNN: [13:10:47.608] RKNN Model Information, version: 2, toolkit version: 1.4.0-22dcfef4(compiler version: 1.4.0 (3b4520e4f@2022-09-05T12:50:09)), target: RKNPU v2, target platform: rk3588, framework name: ONNX, framework layout: NCHW, model inference type: static_shape
W RKNN: [13:10:47.658] query RKNN_QUERY_INPUT_DYNAMIC_RANGE error, rknn model is static shape type, please export rknn with dynamic_shapes
W Query dynamic range failed. Ret code: RKNN_ERR_MODEL_INVALID. (If it is a static shape RKNN model, please ignore the above warning message.)
W rknn-toolkit-lite2 version: 2.3.2
I RKNN: [13:10:47.761] RKNN Runtime Information, librknnrt version: 2.3.2 (429f97ae6b@2025-04-09T09:09:27)
I RKNN: [13:10:47.761] RKNN Driver Information, version: 0.9.6
I RKNN: [13:10:47.762] RKNN Model Information, version: 2, toolkit version: 1.4.0-22dcfef4(compiler version: 1.4.0 (3b4520e4f@2022-09-05T12:50:09)), target: RKNPU v2, target platform: rk3588, framework name: ONNX, framework layout: NCHW, model inference type: static_shape
W RKNN: [13:10:47.814] query RKNN_QUERY_INPUT_DYNAMIC_RANGE error, rknn model is static shape type, please export rknn with dynamic_shapes
W Query dynamic range failed. Ret code: RKNN_ERR_MODEL_INVALID. (If it is a static shape RKNN model, please ignore the above warning message.)
W rknn-toolkit-lite2 version: 2.3.2
I RKNN: [13:10:47.910] RKNN Runtime Information, librknnrt version: 2.3.2 (429f97ae6b@2025-04-09T09:09:27)
I RKNN: [13:10:47.910] RKNN Driver Information, version: 0.9.6
I RKNN: [13:10:47.912] RKNN Model Information, version: 2, toolkit version: 1.4.0-22dcfef4(compiler version: 1.4.0 (3b4520e4f@2022-09-05T12:50:09)), target: RKNPU v2, target platform: rk3588, framework name: ONNX, framework layout: NCHW, model inference type: static_shape
W RKNN: [13:10:47.962] query RKNN_QUERY_INPUT_DYNAMIC_RANGE error, rknn model is static shape type, please export rknn with dynamic_shapes
W Query dynamic range failed. Ret code: RKNN_ERR_MODEL_INVALID. (If it is a static shape RKNN model, please ignore the above warning message.)
W rknn-toolkit-lite2 version: 2.3.2
I RKNN: [13:10:48.069] RKNN Runtime Information, librknnrt version: 2.3.2 (429f97ae6b@2025-04-09T09:09:27)
I RKNN: [13:10:48.070] RKNN Driver Information, version: 0.9.6
I RKNN: [13:10:48.071] RKNN Model Information, version: 2, toolkit version: 1.4.0-22dcfef4(compiler version: 1.4.0 (3b4520e4f@2022-09-05T12:50:09)), target: RKNPU v2, target platform: rk3588, framework name: ONNX, framework layout: NCHW, model inference type: static_shape
W RKNN: [13:10:48.122] query RKNN_QUERY_INPUT_DYNAMIC_RANGE error, rknn model is static shape type, please export rknn with dynamic_shapes
W Query dynamic range failed. Ret code: RKNN_ERR_MODEL_INVALID. (If it is a static shape RKNN model, please ignore the above warning message.)
W rknn-toolkit-lite2 version: 2.3.2
I RKNN: [13:10:48.228] RKNN Runtime Information, librknnrt version: 2.3.2 (429f97ae6b@2025-04-09T09:09:27)
I RKNN: [13:10:48.228] RKNN Driver Information, version: 0.9.6
I RKNN: [13:10:48.229] RKNN Model Information, version: 2, toolkit version: 1.4.0-22dcfef4(compiler version: 1.4.0 (3b4520e4f@2022-09-05T12:50:09)), target: RKNPU v2, target platform: rk3588, framework name: ONNX, framework layout: NCHW, model inference type: static_shape
W RKNN: [13:10:48.280] query RKNN_QUERY_INPUT_DYNAMIC_RANGE error, rknn model is static shape type, please export rknn with dynamic_shapes
W Query dynamic range failed. Ret code: RKNN_ERR_MODEL_INVALID. (If it is a static shape RKNN model, please ignore the above warning message.)
Input #0, rawvideo, from 'pipe:':
Duration: N/A, start: 0.000000, bitrate: 442368 kb/s
Stream #0:0: Video: rawvideo (BGR[24] / 0x18524742), bgr24, 1280x720, 442368 kb/s, 20 tbr, 20 tbn
Stream mapping:
Stream #0:0 (rawvideo) -> fps:default
fps:default -> Stream #0:0 (h264_rkmpp)
Output #0, mp4, to '/home/orangepi/workspace/modelbox/output/det_result.mp4':
Metadata:
encoder : Lavf60.16.100
Stream #0:0: Video: h264 (High) (avc1 / 0x31637661), bgr24(progressive), 1280x720, q=2-31, 2000 kb/s, 20 fps, 10240 tbn
Metadata:
encoder : Lavc60.31.102 h264_rkmpp
Input #0, rawvideo, from 'pipe:': 0kB time=N/A bitrate=N/A speed=N/A
Duration: N/A, start: 0.000000, bitrate: 442368 kb/s
Stream #0:0: Video: rawvideo (BGR[24] / 0x18524742), bgr24, 1280x720, 442368 kb/s, 20 tbr, 20 tbn
Stream mapping:
Stream #0:0 (rawvideo) -> fps:default
fps:default -> Stream #0:0 (h264_rkmpp)
Output #0, mp4, to '/home/orangepi/workspace/modelbox/output/track_result.mp4':
Metadata:
encoder : Lavf60.16.100
Stream #0:0: Video: h264 (High) (avc1 / 0x31637661), bgr24(progressive), 1280x720, q=2-31, 2000 kb/s, 20 fps, 10240 tbn
Metadata:
encoder : Lavc60.31.102 h264_rkmpp
[out#0/mp4 @ 0x558f2625e0] video:2330kB audio:0kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.062495%
frame= 132 fps= 19 q=-0.0 Lsize= 2331kB time=00:00:06.55 bitrate=2915.8kbits/s speed=0.924x
Exiting normally, received signal 15.
[out#0/mp4 @ 0x557e4875e0] video:1990kB audio:0kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.072192%
frame= 131 fps= 18 q=-0.0 Lsize= 1991kB time=00:00:06.50 bitrate=2509.6kbits/s speed= 0.9x
==========All Process Finished.===========
Exiting normally, received signal 15.
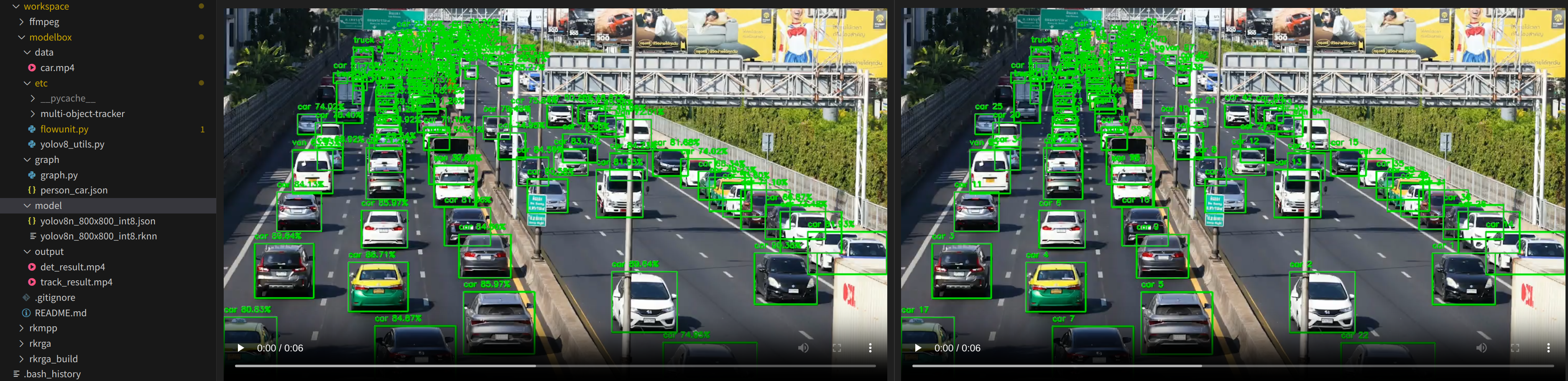
应用推理的帧率取决于视频读取的帧率以及耗时最久的功能单元,实测FPS约为20左右,满足AI实时检测的场景。

- 点赞
- 收藏
- 关注作者
评论(0)