AI Agent在资源受限环境中的轻量化蒸馏与高效部署研究

【摘要】 随着人工智能(AI)模型的规模不断扩大,AI Agent 在自然语言处理、智能决策和多模态推理等场景中展现出了强大的能力。然而,大规模模型往往伴随着 庞大的参数量、推理延迟和高昂的计算成本。如何在保证性能的同时,实现 模型压缩与加速,成为AI Agent落地的关键问题。
AI Agent在资源受限环境中的轻量化蒸馏与高效部署研究
一、引言
随着人工智能(AI)模型的规模不断扩大,AI Agent 在自然语言处理、智能决策和多模态推理等场景中展现出了强大的能力。然而,大规模模型往往伴随着 庞大的参数量、推理延迟和高昂的计算成本。如何在保证性能的同时,实现 模型压缩与加速,成为AI Agent落地的关键问题。
模型蒸馏(Knowledge Distillation, KD) 作为一种经典的模型压缩技术,能够在保持模型精度的同时,大幅度减少计算开销,为AI Agent提供轻量化的推理能力。
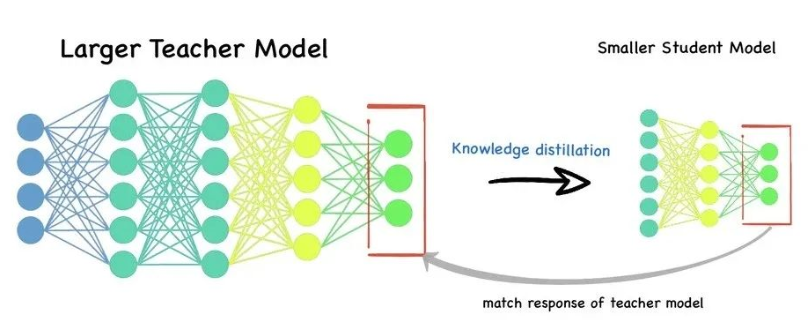
二、模型蒸馏的基本原理
模型蒸馏的核心思想是:
- 教师模型(Teacher Model):通常为性能优越的大模型,拥有强大的表达能力。
- 学生模型(Student Model):轻量化的小模型,目标是学习教师模型的知识。
通过蒸馏过程,学生模型不仅学习真实标签(Hard Label),还学习教师模型的 输出分布(Soft Label),从而获得更强的泛化能力。
蒸馏的损失函数一般形式为:
其中:
- :交叉熵损失(真实标签监督)
- :Kullback–Leibler 散度(教师与学生预测分布差异)
- :温度系数,用于平滑教师模型的预测分布
- :权重系数

三、AI Agent中的模型蒸馏应用
AI Agent 系统中常见的模型蒸馏应用包括:
- 语言模型蒸馏:将GPT类大模型蒸馏为轻量化模型,加速对话响应。
- 强化学习Agent蒸馏:在复杂环境中,用大模型指导小模型策略学习。
- 多模态蒸馏:在视觉-语言Agent中,将视觉模型和语言模型的知识压缩到统一的学生模型。

四、代码实战:基于PyTorch的模型蒸馏实现
下面我们以 文本分类任务 为例,演示如何实现模型蒸馏。
1. 数据准备
import torch
from torch.utils.data import DataLoader, Dataset
import torch.nn as nn
import torch.nn.functional as F
# 模拟数据集
class SimpleDataset(Dataset):
def __init__(self, size=2000):
self.data = torch.randn(size, 100) # 100维输入
self.labels = torch.randint(0, 2, (size,)) # 二分类
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.labels[idx]
train_loader = DataLoader(SimpleDataset(), batch_size=32, shuffle=True)
2. 定义教师模型和学生模型
class TeacherModel(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Sequential(
nn.Linear(100, 256),
nn.ReLU(),
nn.Linear(256, 2)
)
def forward(self, x):
return self.fc(x)
class StudentModel(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Sequential(
nn.Linear(100, 64),
nn.ReLU(),
nn.Linear(64, 2)
)
def forward(self, x):
return self.fc(x)
teacher = TeacherModel()
student = StudentModel()
3. 定义蒸馏损失函数
def distillation_loss(student_logits, teacher_logits, labels, T=2.0, alpha=0.5):
# 交叉熵损失(真实标签)
hard_loss = F.cross_entropy(student_logits, labels)
# 蒸馏损失(教师-学生分布差异)
soft_loss = F.kl_div(
F.log_softmax(student_logits / T, dim=1),
F.softmax(teacher_logits / T, dim=1),
reduction="batchmean"
) * (T * T)
return alpha * hard_loss + (1 - alpha) * soft_loss
4. 训练循环
optimizer = torch.optim.Adam(student.parameters(), lr=1e-3)
# 先训练教师模型(此处简化为预训练)
for epoch in range(3):
for x, y in train_loader:
loss = F.cross_entropy(teacher(x), y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 蒸馏训练学生模型
for epoch in range(5):
for x, y in train_loader:
with torch.no_grad():
teacher_logits = teacher(x)
student_logits = student(x)
loss = distillation_loss(student_logits, teacher_logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item():.4f}")
通过蒸馏,学生模型可以在 参数量减少 70%+ 的情况下,仍然保持接近教师模型的性能,同时推理速度显著提升。
五、优势与挑战
优势
- 高效性:减少参数量和计算量,加速推理。
- 泛化性:通过学习教师的“软标签”,提升学生模型泛化能力。
- 适应性:便于在边缘设备或移动端部署AI Agent。
挑战
- 教师模型选择:教师模型越强,学生模型蒸馏效果越好,但训练成本也更高。
- 蒸馏策略设计:如何结合多任务、多模态蒸馏仍是研究难点。
- 性能-效率权衡:过度压缩可能导致性能下降。
六、结论
基于模型蒸馏的模型压缩与加速技术,为AI Agent在资源受限环境中的部署提供了有效的解决方案。未来,结合 自蒸馏(Self-distillation)、多模态蒸馏 与 量化、剪枝等方法,将进一步推动AI Agent走向高效、智能的实际应用。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)