高并发场景下缓存与数据库一致性问题的消息队列方案

一、问题背景
在使用 缓存(Redis 等)+ 数据库(MySQL 等) 的架构中,常见的操作顺序有两种:
-
先更新数据库,再删除缓存
- 数据库操作成功,但缓存删除失败,可能会导致数据不一致。
- 解决方法:加重试机制、异步补偿。
-
先删除缓存,再更新数据库
- 如果更新数据库失败,缓存已被删除,后续请求可能会从数据库读到旧值并写入缓存,依然出现不一致。
所以,仅靠顺序操作,无法完全解决一致性问题。
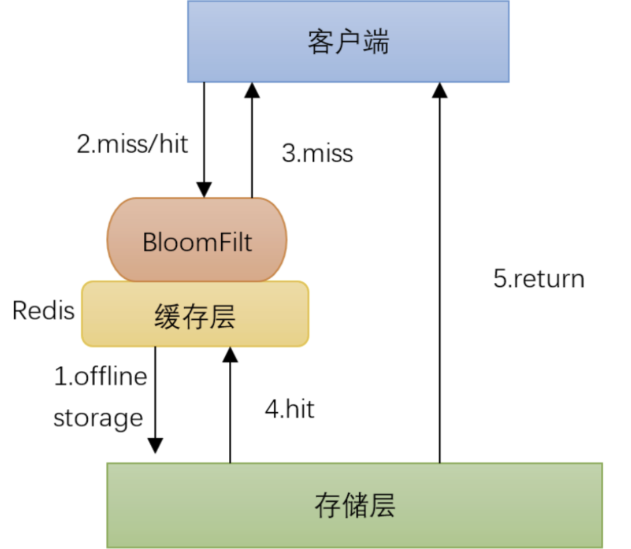
二、消息队列解决思路
通过 消息队列(Kafka、RabbitMQ、RocketMQ 等),我们可以把数据库和缓存的更新/删除动作进行解耦,并利用消息的 可靠投递和顺序性 保证最终一致性。
方案流程
以“写请求更新数据”为例:
- 业务服务更新数据库(必须确保数据库事务成功)。
- 业务服务发送一条消息到消息队列,内容是“需要删除/更新某个缓存 key”。
- 缓存服务订阅消息队列,消费到消息后进行缓存更新或删除操作。
- 如果缓存删除失败,可以依赖 MQ 的重试机制 或者 写入死信队列(DLQ)做人工/定时补偿。
三、核心要点
1. 保证消息的可靠投递
-
数据库更新成功后,必须保证消息一定进入 MQ。
-
常见做法:
- 本地消息表(事务消息):数据库表里记录需要投递的消息,事务和业务 SQL 一起提交,再由后台任务扫描表并投递到 MQ。
- MQ 事务消息:支持事务的 MQ(如 RocketMQ 事务消息),和数据库事务进行“两阶段提交”。
2. 消费端保证幂等
缓存更新/删除可能被重复消费,因此需要保证 幂等性,通常根据消息中的 唯一 ID 去重。
3. 处理乱序问题
消息可能乱序,导致缓存被覆盖为旧值。
- 可以在消息中加入 版本号/时间戳,消费者只更新比当前缓存更新的版本。
四、代码示例(Python + Redis + Kafka 简化版)
import json
import redis
from kafka import KafkaProducer, KafkaConsumer
# Redis 连接
r = redis.Redis(host='localhost', port=6379, db=0)
# Kafka Producer
producer = KafkaProducer(
bootstrap_servers='localhost:9092',
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
def update_db_and_send_message(user_id, new_name):
# 1. 更新数据库(此处伪代码,假设已成功)
print(f"DB: update user {user_id} name={new_name}")
# 2. 发送缓存删除消息
msg = {"user_id": user_id, "action": "del_cache"}
producer.send("cache_sync", msg)
producer.flush()
# Kafka Consumer
consumer = KafkaConsumer(
'cache_sync',
bootstrap_servers='localhost:9092',
value_deserializer=lambda v: json.loads(v.decode('utf-8')),
group_id="cache_group"
)
def consume_messages():
for message in consumer:
data = message.value
user_id = data["user_id"]
if data["action"] == "del_cache":
cache_key = f"user:{user_id}"
r.delete(cache_key)
print(f"Redis: deleted cache {cache_key}")
# 示例调用
update_db_and_send_message(1, "Alice")
consume_messages()
五、典型实现方案对比
在实际工程中,使用消息队列来保证缓存与数据库一致性有多种实现方式。不同方案有不同的权衡:
5.1 本地消息表方案
- 思路:在数据库中建一张
message_table,写业务数据时,将待发送消息同时插入该表,与业务 SQL 在同一事务中提交。 - 实现:后台定时任务扫描
message_table,将未发送的消息写入消息队列,发送成功后标记状态。 - 优点:保证数据库更新与消息写入原子性。
- 缺点:需要额外维护本地消息表,增加扫描和清理逻辑,运维成本高。
5.2 事务消息方案
-
思路:依赖支持事务消息的 MQ(如 RocketMQ)。
-
流程:
- 先发送半消息(消息暂不投递)。
- 执行业务数据库事务。
- 数据库事务成功后,再确认提交 MQ 消息;如果事务失败,回滚消息。
-
优点:不需要额外表,交由 MQ 保证原子性。
-
缺点:需要 MQ 支持事务机制,系统复杂度高。
5.3 异步补偿方案
- 思路:数据库更新后直接发送消息,如果失败则依赖定时任务或补偿机制重发。
- 优点:实现简单,延迟低。
- 缺点:补偿逻辑必须健全,否则存在数据不一致风险。
六、常见问题与优化
6.1 消息丢失
-
场景:Producer 在发送过程中宕机,或者 MQ 出现异常。
-
优化:
- 开启 Kafka 的 acks=all 配置,保证消息写入多数副本。
- 配合 Producer 重试机制 与 幂等性(enable.idempotence)。
6.2 消息乱序
-
场景:同一条数据的更新消息被乱序消费,可能导致缓存被旧值覆盖。
-
优化:
- 按业务主键(如 user_id)做分区,保证相同 key 的消息进入同一分区,单线程消费。
- 在消息中带上 时间戳/版本号,消费端只应用最新版本。
6.3 消息重复消费
-
场景:MQ 重试机制导致同一条消息被多次投递。
-
优化:
- 在缓存更新逻辑中引入 幂等校验,如用 Redis
SETNX或利用消息唯一 ID 去重。
- 在缓存更新逻辑中引入 幂等校验,如用 Redis
6.4 缓存更新延迟
-
场景:消息在 MQ 中排队,消费者延迟导致缓存短暂与数据库不一致。
-
优化:
- 提高消费者并发消费能力。
- 对部分强一致性业务,可以采用 读请求走数据库兜底。
七、案例演示
下面展示一个更完整的案例,采用 本地消息表 + 定时补偿 方案,语言使用 Java(Spring Boot + MyBatis + Redis + Kafka):
7.1 数据库表设计
CREATE TABLE user (
id BIGINT PRIMARY KEY,
name VARCHAR(50),
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE message_table (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
business_key VARCHAR(50),
payload TEXT,
status TINYINT DEFAULT 0, -- 0=待发送, 1=已发送
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
7.2 业务更新逻辑
@Transactional
public void updateUser(Long userId, String newName) {
// 1. 更新业务数据
userMapper.updateName(userId, newName);
// 2. 插入本地消息表
Message msg = new Message();
msg.setBusinessKey("user:" + userId);
msg.setPayload("{\"userId\":" + userId + "}");
msg.setStatus(0);
messageMapper.insert(msg);
}
7.3 定时任务扫描并发送消息
@Scheduled(fixedDelay = 5000)
public void sendPendingMessages() {
List<Message> messages = messageMapper.findPending();
for (Message msg : messages) {
kafkaTemplate.send("cache_sync", msg.getPayload());
messageMapper.updateStatus(msg.getId(), 1);
}
}
7.4 消费者删除缓存
@KafkaListener(topics = "cache_sync", groupId = "cache_group")
public void handleMessage(String payload) {
JSONObject json = new JSONObject(payload);
Long userId = json.getLong("userId");
String cacheKey = "user:" + userId;
redisTemplate.delete(cacheKey);
}
这样就实现了数据库更新 → 本地消息表落库 → Kafka 投递 → 缓存删除的完整链路。
八、适用场景
- 高并发写多读多的场景:例如用户资料修改、商品库存更新等。
- 需要最终一致性而非强一致性的场景:如电商、社交系统。
- 对延迟容忍度较高的业务:允许缓存延迟几百毫秒到几秒钟更新。
总结
利用 消息队列 来解决缓存与数据库一致性问题,本质上是通过 异步解耦 + 最终一致性保证 来降低复杂度并提升系统可靠性。核心设计要点包括:
- 消息投递可靠性:可选本地消息表、事务消息、异步补偿等方式,确保数据库操作成功后,消息必达。
- 消费端幂等性:缓存更新/删除要避免重复消费带来的错误,可通过唯一 ID、Redis 原子操作实现幂等。
- 顺序性保证:防止旧消息覆盖新数据,可通过分区策略或版本号机制解决乱序问题。
- 延迟与补偿机制:通过定时补偿、死信队列(DLQ)、消费者扩展并发能力,降低缓存与数据库之间的延迟差异。
这种模式适用于 对强一致性要求不高,但需要高并发性能与最终一致性保障 的场景(如电商商品、用户资料、订单状态等)。在实际工程落地时,通常结合 Redis + Kafka/RabbitMQ/RocketMQ 构建一套 高可用、可恢复、具备补偿机制 的一致性保障体系。

- 点赞
- 收藏
- 关注作者
评论(0)