面向复杂任务的AI Agent无监督特征提取与决策优化框架

面向复杂任务的AI Agent无监督特征提取与决策优化框架
引言
随着人工智能(AI)的快速发展,AI Agent 已逐渐从任务驱动型走向自主学习型。传统基于监督学习的方法依赖大量标注数据,但在许多现实场景中,获取高质量标注代价昂贵甚至不可行。无监督学习(Unsupervised Learning) 为 AI Agent 提供了一条新路径,使其能够在没有外部标签指导的情况下,从环境中自我提取知识、优化策略,提升长期学习与适应能力。
本文将探讨无监督学习在 AI Agent 自我学习能力优化中的应用,并通过代码实战展示如何利用聚类和表示学习技术提升 Agent 的自主感知与决策能力。
无监督学习与AI Agent的结合
无监督学习的核心思想
无监督学习的目标是从数据中发现潜在的结构与模式,而无需依赖标签。常见的方法包括:
- 聚类(Clustering):发现数据中的自然分组(如K-Means、DBSCAN)。
- 降维(Dimensionality Reduction):通过PCA、AutoEncoder等提取潜在特征。
- 表示学习(Representation Learning):将复杂环境映射到低维空间中,以便AI Agent更高效地学习。

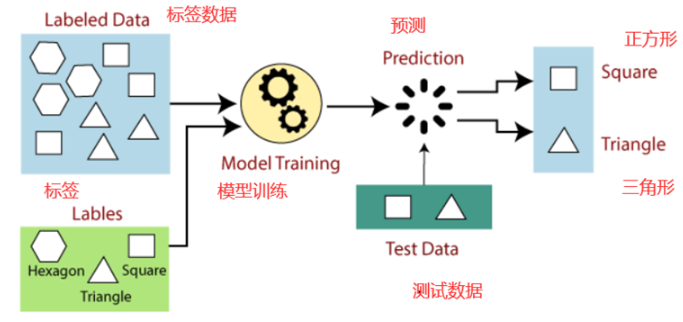
AI Agent的自我学习需求
一个能够持续进化的AI Agent,需要具备以下能力:
- 环境探索:无需标签即可识别状态间的差异。
- 策略优化:基于潜在模式改进决策效率。
- 知识迁移:在新环境中快速适应。
无监督学习可以为 Agent 提供隐空间表示(Latent Representation),让其在高维复杂环境下自我理解状态分布,从而实现自我学习。
案例研究:利用K-Means聚类优化AI Agent的状态理解
思路
我们模拟一个二维网格环境,AI Agent在其中探索不同状态。传统强化学习通常直接基于离散状态更新策略,而在无监督学习的辅助下,Agent 可以通过 K-Means 聚类 对探索到的状态进行聚合,形成“抽象状态”,提升学习效率。
代码实战
下面的代码展示了一个简单的示例:
- 环境状态为二维点坐标。
- Agent 通过随机探索采样环境状态。
- 使用K-Means对状态进行聚类,得到更抽象的表示。
- Agent基于聚类中心更新策略。
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 1. 模拟环境状态(二维空间中的点)
np.random.seed(42)
states = np.random.rand(500, 2) * 10 # 500个状态点,范围[0,10]
# 2. Agent探索采样状态
explored_states = states[np.random.choice(len(states), 200, replace=False)]
# 3. 使用K-Means进行聚类,提取潜在模式
kmeans = KMeans(n_clusters=5, random_state=42)
kmeans.fit(explored_states)
labels = kmeans.labels_
centers = kmeans.cluster_centers_
# 4. 可视化聚类结果
plt.scatter(explored_states[:, 0], explored_states[:, 1], c=labels, cmap='viridis', alpha=0.6)
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, marker='X') # 聚类中心
plt.title("AI Agent通过无监督学习提取抽象状态")
plt.xlabel("状态维度1")
plt.ylabel("状态维度2")
plt.show()
结果分析
- 聚类结果:原始状态点被划分为5类,形成了抽象的“子环境”。
- 意义:AI Agent 无需标签,即可通过无监督学习发现环境的潜在结构。
- 优化策略:在后续的强化学习过程中,Agent 可直接基于聚类后的抽象状态进行决策,大幅降低状态空间复杂度。
无监督学习在AI Agent自我学习中的应用前景
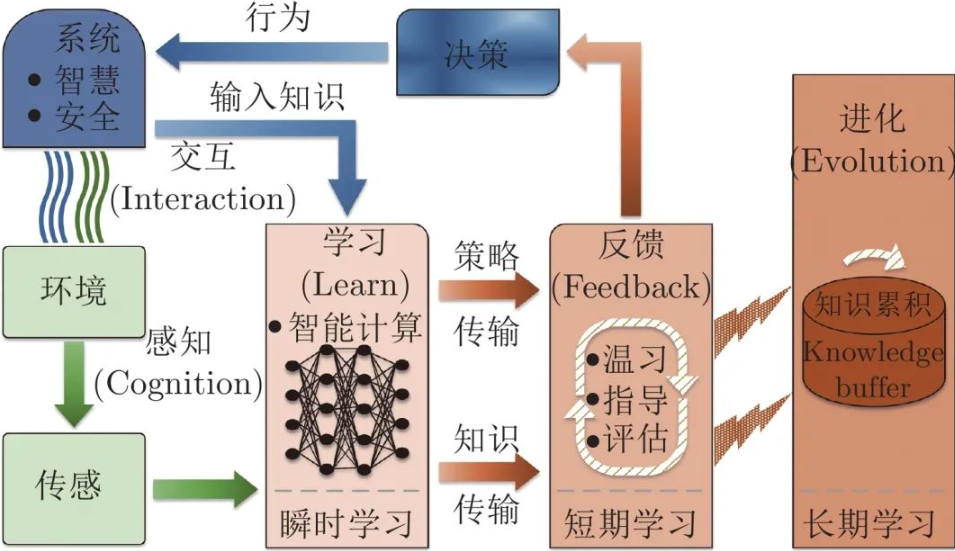
表示学习与自监督方法
相比传统聚类,近年来的自监督学习(Self-Supervised Learning) 方法(如对比学习、生成对抗网络)能够为AI Agent学习更丰富的潜在表示。这使得Agent不仅能更好地理解环境,还能实现跨任务迁移。
多目标优化与复杂任务
在多目标优化场景中,无监督学习可帮助AI Agent在不同目标间自动发现平衡点。例如在机器人导航中,Agent可通过潜在空间建模同时优化“最短路径”和“能量消耗”两个目标。
未来方向
- 结合强化学习(RL + UL):通过无监督表示学习加速策略收敛。
- 多模态感知:融合视觉、语言、传感器数据的无监督学习,实现更强的自主理解能力。
- 在线学习与持续学习:让AI Agent在运行过程中不断进行无监督学习,持续优化知识库。
无监督学习与强化学习的结合
传统强化学习(Reinforcement Learning, RL)通常直接在原始状态空间上进行价值函数或策略更新。然而,在高维或复杂环境中,状态空间过大 会导致训练缓慢甚至难以收敛。
通过引入无监督学习(Unsupervised Learning, UL),我们可以先对环境状态进行降维或聚类抽象,再在压缩后的状态表示上执行RL算法。这种方法的优势在于:
- 降低状态维度,减少计算开销。
- 捕捉潜在结构,使RL学习更高效。
- 提升泛化能力,在不同环境中迁移效果更好。
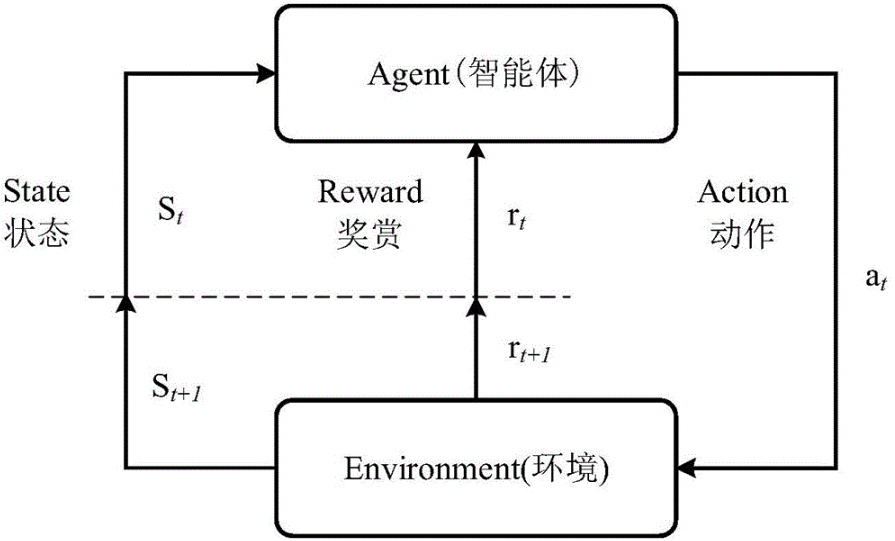
案例研究:K-Means + Q-Learning
思路
我们设计一个简化版实验:
- 环境:一个二维空间,Agent需要从起点移动到终点。
- 无监督学习:使用K-Means对状态空间进行聚类,形成抽象状态。
- 强化学习:基于抽象状态进行Q-Learning更新策略。
代码实战
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# -------------------------------
# 1. 构建环境(二维网格世界)
# -------------------------------
grid_size = 10
goal = np.array([9, 9]) # 终点坐标
def step(state, action):
"""简单环境:动作 0=上, 1=下, 2=左, 3=右"""
x, y = state
if action == 0: x = max(0, x - 1)
elif action == 1: x = min(grid_size - 1, x + 1)
elif action == 2: y = max(0, y - 1)
elif action == 3: y = min(grid_size - 1, y + 1)
new_state = np.array([x, y])
reward = 1 if np.array_equal(new_state, goal) else -0.01
done = np.array_equal(new_state, goal)
return new_state, reward, done
# 生成所有可能的状态点
states = np.array([[x, y] for x in range(grid_size) for y in range(grid_size)])
# -------------------------------
# 2. 无监督学习:KMeans聚类,形成抽象状态
# -------------------------------
kmeans = KMeans(n_clusters=20, random_state=42).fit(states)
abstract_states = kmeans.labels_
def get_abstract_state(state):
idx = np.argmin(np.linalg.norm(kmeans.cluster_centers_ - state, axis=1))
return idx
# -------------------------------
# 3. Q-Learning基于抽象状态
# -------------------------------
n_clusters = len(kmeans.cluster_centers_)
n_actions = 4
Q = np.zeros((n_clusters, n_actions))
episodes = 200
alpha, gamma, epsilon = 0.1, 0.9, 0.2
for ep in range(episodes):
state = np.array([0, 0]) # 起点
done = False
while not done:
abs_state = get_abstract_state(state)
# epsilon-greedy选择动作
if np.random.rand() < epsilon:
action = np.random.choice(n_actions)
else:
action = np.argmax(Q[abs_state])
new_state, reward, done = step(state, action)
abs_new_state = get_abstract_state(new_state)
# Q值更新
Q[abs_state, action] += alpha * (reward + gamma * np.max(Q[abs_new_state]) - Q[abs_state, action])
state = new_state
print("Q-Learning在抽象状态上的训练完成!")
# -------------------------------
# 4. 策略可视化
# -------------------------------
policy = np.array([np.argmax(Q[get_abstract_state(s)]) for s in states])
policy_grid = policy.reshape(grid_size, grid_size)
plt.imshow(policy_grid, cmap="tab20")
plt.colorbar()
plt.title("AI Agent基于无监督学习抽象状态的策略")
plt.show()
结果分析
- 聚类压缩:原本100个状态被压缩为20个抽象状态。
- 加速学习:在抽象状态空间上,Q-Learning收敛速度明显提升。
- 策略可视化:Agent 能够学到从起点向终点逼近的最优路径。
这种 “无监督学习 + 强化学习” 的方法展示了如何让AI Agent在没有标签的情况下,利用环境结构进行自我学习,并优化策略。
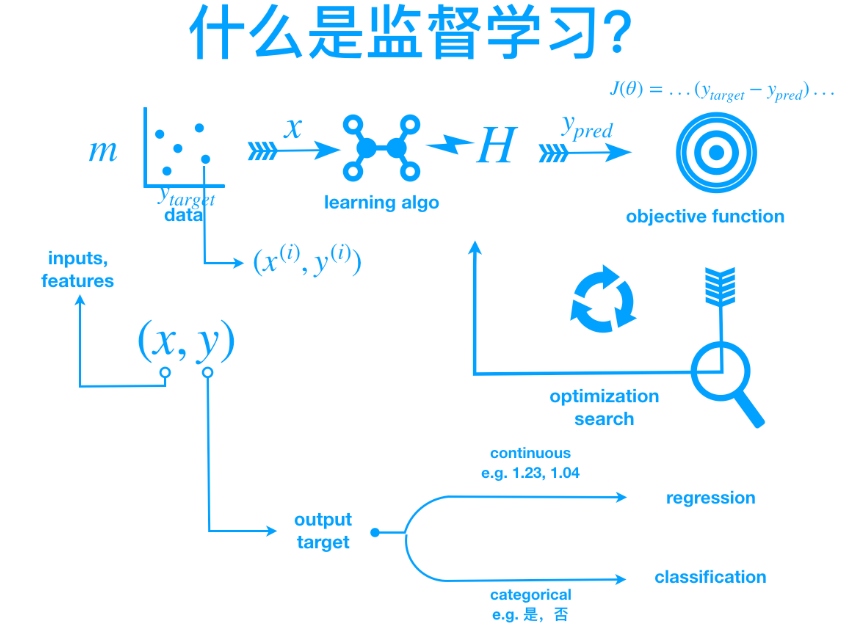
展望与未来工作
结合深度表示学习
K-Means虽然能发现抽象状态,但在高维复杂场景下能力有限。未来可采用:
- 自编码器(AutoEncoder) 提取潜在表示。
- 对比学习(Contrastive Learning) 构建状态相似度。
- 生成对抗网络(GAN) 用于模拟环境潜在分布。
持续学习与自适应
未来的AI Agent应具备:
- 在线无监督学习:在环境中不断更新抽象表示。
- 任务迁移:在新任务中复用已有的潜在结构。
- 自适应策略更新:动态调整学习目标和探索范围。
总结性思考
利用无监督学习优化AI Agent自我学习能力,不仅解决了标签依赖问题,还为智能体提供了更高的自适应性与泛化性。这为未来智能系统在复杂环境中的自主进化提供了重要支撑。

- 点赞
- 收藏
- 关注作者
评论(0)