面向智能搜索的AI Agent技术架构与算法研究

面向智能搜索的AI Agent技术架构与算法研究
前言
随着信息爆炸时代的到来,传统搜索引擎面临着结果泛化、上下文理解不足等问题。AI Agent通过结合自然语言处理(NLP)、知识图谱(Knowledge Graph)、强化学习(RL)等技术,能够在智能搜索中实现更精准的检索、语义理解与动态响应。本篇文章将从技术架构、核心算法以及实战代码三个方面进行深入探讨。
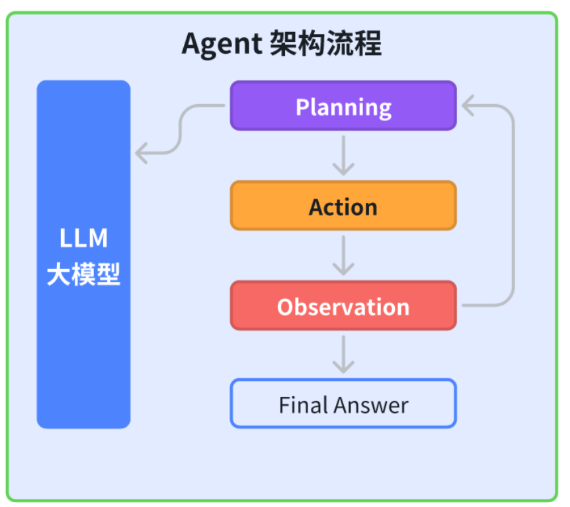
1. AI Agent智能搜索系统架构
1.1 系统总体设计
智能搜索AI Agent通常由以下几个核心模块组成:
-
用户输入理解模块
- 使用NLP技术对用户查询进行意图识别与语义解析。
- 支持问答式、指令式以及多轮对话搜索。
-
知识表示与存储模块
- 利用知识图谱(Graph Database,如Neo4j)存储实体关系。
- 提供快速语义检索和推理能力。
-
搜索与推荐模块
- 集成传统搜索引擎(Elasticsearch、Lucene)与向量检索(FAISS、Milvus)。
- 根据查询意图选择合适的数据源并进行检索。
-
策略决策模块
- 强化学习或规则引擎决定搜索策略,如多轮检索、相关性排序、结果融合。
-
响应生成模块
- 将检索结果与上下文信息融合,通过自然语言生成(NLG)输出最终答案。
整体架构示意图如下:
用户输入 -> NLP理解 -> 检索策略 -> 向量检索/关键词检索 -> 知识图谱推理 -> 响应生成 -> 用户输出
1.2 数据流与交互
用户查询经过解析生成查询向量,AI Agent通过多层策略选择最优检索路径,并动态更新结果的排序与推荐。这种闭环机制保证了搜索的智能化与自适应性。
2. 核心算法研究
2.1 自然语言理解(NLU)
NLU模块主要任务包括:
- 意图识别:BERT、RoBERTa等预训练模型用于分类用户查询意图。
- 实体识别:利用BiLSTM-CRF、spaCy进行关键实体抽取。
- 语义向量化:通过Sentence-BERT或OpenAI Embeddings将查询和文档统一到向量空间。
示例Python代码:
from sentence_transformers import SentenceTransformer, util
# 加载预训练模型
model = SentenceTransformer('all-MiniLM-L6-v2')
# 用户查询与文档
query = "人工智能在搜索引擎中的应用"
documents = ["AI在搜索引擎中的应用包括语义搜索和推荐系统",
"深度学习用于图像识别和自然语言处理"]
# 转化为向量
query_vec = model.encode(query, convert_to_tensor=True)
doc_vecs = model.encode(documents, convert_to_tensor=True)
# 计算相似度
cos_scores = util.pytorch_cos_sim(query_vec, doc_vecs)
print("相似度评分:", cos_scores)
2.2 知识图谱推理
知识图谱通过关系推理提升搜索结果的深度理解。常用算法包括:
- 路径查询:SPARQL查询实体关系路径。
- 图嵌入:TransE、RotatE将图谱节点嵌入向量空间,实现向量相似度搜索。

示例Python代码(Neo4j):
from neo4j import GraphDatabase
uri = "bolt://localhost:7687"
driver = GraphDatabase.driver(uri, auth=("neo4j", "password"))
def find_related_entities(entity):
with driver.session() as session:
result = session.run(
"MATCH (e:Entity {name: $name})-[:RELATED_TO]->(r) RETURN r.name",
name=entity
)
return [record["r.name"] for record in result]
related = find_related_entities("人工智能")
print("相关实体:", related)
2.3 强化学习策略优化
在多轮搜索场景中,AI Agent通过强化学习不断优化搜索策略:
- 状态:当前查询上下文、用户历史点击记录。
- 动作:选择检索模型、排序算法、推荐结果。
- 奖励:点击率、用户满意度或搜索精确度。
简单示例(Q-Learning伪代码):
import numpy as np
# 状态空间和动作空间
states = ["初始查询", "二轮查询"]
actions = ["关键词检索", "向量检索"]
Q = np.zeros((len(states), len(actions)))
alpha = 0.1
gamma = 0.9
# 更新Q值
def update_Q(state_idx, action_idx, reward, next_state_idx):
Q[state_idx, action_idx] += alpha * (reward + gamma * np.max(Q[next_state_idx, :]) - Q[state_idx, action_idx])
3. AI Agent智能搜索实战示例
假设我们构建一个简易智能搜索Agent,结合向量检索与知识图谱:
query = "搜索引擎如何利用AI优化结果"
# 1. 查询向量化
query_vec = model.encode(query, convert_to_tensor=True)
# 2. 向量检索
cos_scores = util.pytorch_cos_sim(query_vec, doc_vecs)
top_idx = cos_scores.argmax()
print("最相关文档:", documents[top_idx])
# 3. 知识图谱推理
related_entities = find_related_entities("搜索引擎")
print("知识图谱相关实体:", related_entities)
该示例展示了AI Agent从查询理解、语义检索到知识推理的完整流程,实现了智能化搜索的基本功能。
4. 多轮搜索与上下文管理
在复杂查询场景中,用户往往需要通过多轮交互才能得到满意结果。AI Agent需要具备上下文管理能力,以保证每轮搜索结果与用户意图一致。
4.1 上下文状态表示
多轮搜索的关键是上下文状态表示。常用方法包括:
- 向量化上下文:将历史查询、点击行为和文档信息编码为上下文向量。
- 记忆网络:使用Transformer或RNN维护用户会话历史。
- 缓存机制:针对同一用户或相似查询,缓存检索结果加速响应。
示例Python代码(简单上下文向量融合):
from sentence_transformers import SentenceTransformer
import numpy as np
model = SentenceTransformer('all-MiniLM-L6-v2')
# 假设历史查询
history_queries = ["AI在搜索引擎中的应用", "语义搜索技术"]
# 当前查询
current_query = "如何提高搜索结果准确性"
# 将历史和当前查询向量融合
history_vecs = model.encode(history_queries)
current_vec = model.encode([current_query])
context_vec = np.mean(np.vstack([history_vecs, current_vec]), axis=0)
print("上下文向量:", context_vec)
4.2 多轮检索策略
多轮检索策略主要包括:
-
递进式检索
- 第一轮使用关键词或向量检索,快速获取候选文档。
- 后续轮次根据上下文向量重新排序候选文档。
-
交互式反馈优化
- 利用用户点击和评分信息更新检索策略(在线学习)。
- 强化学习可用于动态调整检索动作选择。
-
多模型融合
- 结合不同检索模型(向量检索、BM25、知识图谱推理)
- 对结果进行加权融合,提高精确度和覆盖率。
5. 个性化搜索与推荐
智能搜索不仅需要理解用户查询,还应考虑用户偏好与历史行为,实现个性化推荐。
5.1 用户画像构建
- 行为数据:点击、浏览、收藏等行为。
- 兴趣标签:通过主题模型(LDA、BERTopic)生成兴趣分布。
- 上下文特征:时间、设备、地理位置等。
示例Python代码(简单兴趣标签生成):
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import TruncatedSVD
documents = [
"搜索引擎优化与AI技术结合",
"深度学习在图像识别中的应用",
"自然语言处理与问答系统"
]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(documents)
# LSA降维提取主题
svd = TruncatedSVD(n_components=2)
topics = svd.fit_transform(X)
print("文档主题分布:\n", topics)
5.2 个性化检索与排序
- 向量相似度加权:结合查询向量与用户兴趣向量计算综合相似度。
- 实时排序调整:根据用户点击反馈,动态调整排序策略。
示例代码:
user_interest_vec = np.array([0.6, 0.4]) # 假设兴趣向量
doc_topic_vecs = topics
# 加权相似度
scores = doc_topic_vecs @ user_interest_vec
top_idx = scores.argmax()
print("推荐文档:", documents[top_idx])
6. 系统优化与部署
在实际应用中,AI Agent智能搜索系统需考虑高效、可扩展的部署策略。
6.1 向量检索优化
- 索引结构:使用FAISS或Milvus构建高效向量索引。
- 压缩与聚类:IVF、PQ、HNSW等索引方法减少内存和搜索时间。
6.2 并行与分布式部署
- 多节点部署搜索引擎与知识图谱数据库。
- 使用消息队列(Kafka、RabbitMQ)处理用户请求和反馈。
6.3 模型更新与在线学习
- 定期更新向量模型和知识图谱。
- 在线学习机制让模型自适应用户行为变化。
示例代码(FAISS向量索引):
import faiss
import numpy as np
# 构建向量库
vectors = np.random.rand(100, 128).astype('float32')
index = faiss.IndexFlatL2(128)
index.add(vectors)
# 查询向量
query_vec = np.random.rand(1, 128).astype('float32')
distances, indices = index.search(query_vec, k=5)
print("最相似向量索引:", indices)
总结
本研究系统性地探讨了面向智能搜索的AI Agent技术架构与核心算法。从自然语言理解、知识图谱推理到多轮搜索策略与个性化推荐,本研究展示了AI Agent在复杂搜索场景中的应用潜力。通过向量化表示、强化学习优化、多模型融合以及上下文管理,智能搜索系统能够实现对用户意图的精准捕捉与动态响应。此外,系统在向量检索优化、分布式部署以及在线学习机制方面的探索,为实际应用提供了高效、可扩展的解决方案。本研究为未来多模态搜索、自适应策略优化以及知识推理能力提升提供了理论基础与实践指导。

- 点赞
- 收藏
- 关注作者
评论(0)