强化学习算法在AI Agent智能代理中的深入应用

【摘要】 强化学习算法在AI Agent智能代理中的深入应用 一、引言近年来,人工智能(Artificial Intelligence, AI)正在从单纯的感知与识别任务,逐渐迈向自主决策与执行阶段。其中,**AI Agent(智能代理)**作为一种能够感知环境、制定决策并执行动作的系统,在游戏对战、自动驾驶、机器人控制、自动交易等场景中展现了巨大潜力。在众多算法中,**强化学习(Reinforce...
强化学习算法在AI Agent智能代理中的深入应用
一、引言
近年来,人工智能(Artificial Intelligence, AI)正在从单纯的感知与识别任务,逐渐迈向自主决策与执行阶段。其中,**AI Agent(智能代理)**作为一种能够感知环境、制定决策并执行动作的系统,在游戏对战、自动驾驶、机器人控制、自动交易等场景中展现了巨大潜力。
在众多算法中,**强化学习(Reinforcement Learning, RL)**成为驱动AI Agent实现自主决策的核心技术。它模拟人类“试错—总结—优化”的学习模式,使智能代理能够通过与环境的持续交互,学习最优策略。
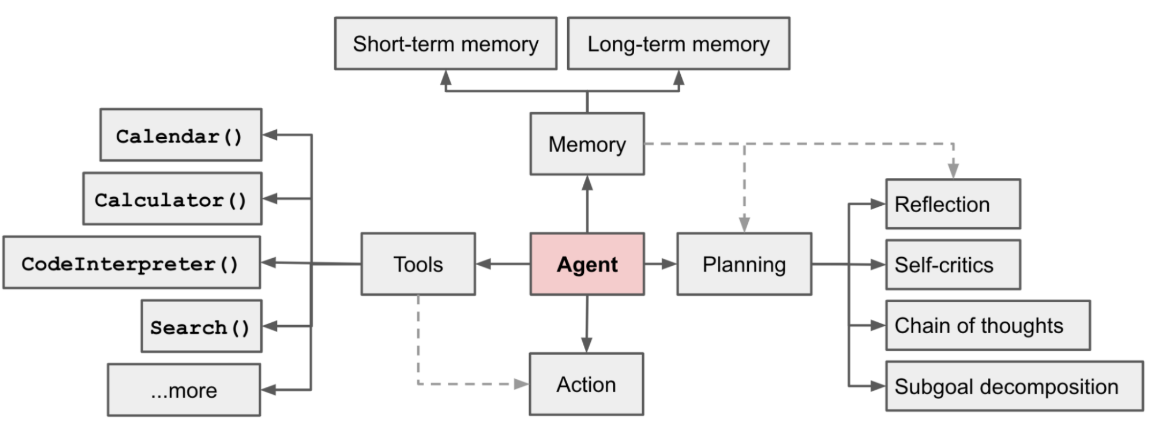
二、强化学习与AI Agent的结合原理
1. 什么是强化学习
强化学习是一种通过与环境交互来最大化累计奖励(Cumulative Reward)的机器学习方法。它的关键组成包括:
- Agent(智能体):做出动作的决策者。
- Environment(环境):接收动作并返回奖励与新状态。
- State(状态):描述当前环境信息的变量集合。
- Action(动作):Agent可执行的操作集合。
- Reward(奖励):环境对Agent动作的反馈,用于指导学习。
- Policy(策略):Agent从状态到动作的映射规则。
2. AI Agent中的强化学习流程
- 感知环境(获取State)
- 选择动作(基于Policy)
- 执行动作(影响环境)
- 接收反馈(Reward和新的State)
- 更新策略(优化决策)
这种循环过程被称为马尔可夫决策过程(Markov Decision Process, MDP)。
三、主流强化学习算法在AI Agent中的应用
1. 基于值的算法(Value-based)
- Q-Learning:学习一个状态-动作值函数 ,找到最优策略。
- Deep Q-Network (DQN):使用深度神经网络近似Q值,解决大规模状态空间问题。
2. 基于策略的算法(Policy-based)
- REINFORCE:直接优化策略参数,适用于连续动作空间。
- PPO(Proximal Policy Optimization):稳定性好,广泛应用于复杂环境。
3. 基于Actor-Critic架构
- 结合值函数与策略优化的优点,兼顾收敛速度与稳定性。
- 代表算法:A2C、A3C、DDPG、SAC。
四、代码实战:基于DQN的AI Agent环境交互
下面,我们用一个经典的CartPole平衡杆任务,来演示DQN算法驱动AI Agent的过程。
1. 环境准备
import gym
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from collections import deque
import random
2. 构建Q网络
class QNetwork(nn.Module):
def __init__(self, state_size, action_size):
super(QNetwork, self).__init__()
self.fc1 = nn.Linear(state_size, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, action_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.fc3(x)
3. 定义DQN Agent
class DQNAgent:
def __init__(self, state_size, action_size):
self.state_size = state_size
self.action_size = action_size
self.memory = deque(maxlen=2000)
self.gamma = 0.99
self.epsilon = 1.0
self.epsilon_min = 0.01
self.epsilon_decay = 0.995
self.model = QNetwork(state_size, action_size)
self.optimizer = optim.Adam(self.model.parameters(), lr=0.001)
self.criterion = nn.MSELoss()
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def act(self, state):
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
state = torch.FloatTensor(state).unsqueeze(0)
act_values = self.model(state)
return torch.argmax(act_values).item()
def replay(self, batch_size):
if len(self.memory) < batch_size:
return
minibatch = random.sample(self.memory, batch_size)
for state, action, reward, next_state, done in minibatch:
target = reward
if not done:
target += self.gamma * torch.max(self.model(torch.FloatTensor(next_state))).item()
target_f = self.model(torch.FloatTensor(state))
target_f = target_f.clone()
target_f[action] = target
output = self.model(torch.FloatTensor(state))
loss = self.criterion(output, target_f)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
4. 训练过程
env = gym.make('CartPole-v1')
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
agent = DQNAgent(state_size, action_size)
episodes = 300
for e in range(episodes):
state = env.reset()[0]
state = np.reshape(state, [state_size])
for time_t in range(500):
action = agent.act(state)
next_state, reward, done, _, _ = env.step(action)
next_state = np.reshape(next_state, [state_size])
agent.remember(state, action, reward, next_state, done)
state = next_state
if done:
print(f"Episode {e+1}/{episodes} - Score: {time_t}")
break
agent.replay(32)
env.close()
五、深度分析与优化建议
-
收敛速度与稳定性
- 可增加经验回放(Replay Buffer)和目标网络(Target Network),减少训练震荡。
-
状态归一化
- 对输入状态进行标准化,有助于网络更快收敛。
-
奖励设计
- 奖励函数直接影响Agent的行为,应合理设计以避免陷入局部最优。
-
迁移学习
- 将在一个环境中训练好的策略迁移到相似环境中,可减少训练时间。
六、应用场景
- 自动驾驶:强化学习可驱动自动驾驶Agent学习车道保持、超车策略。
- 智能游戏对手:在围棋、星际争霸等游戏中实现超越人类的水平。
- 智能交易系统:自动化决策买入卖出时机。
- 机器人控制:学习复杂动作序列(如抓取、搬运、装配)。
七、结语
强化学习与AI Agent的结合,正在推动智能系统从“被动执行”迈向“主动思考”。未来,随着计算能力与算法的进一步发展,AI Agent将不仅仅是执行者,而是具备自主规划与创造能力的智能体。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)