跨模态数据融合在AI Agent中的新兴方法与前景

跨模态数据融合在AI Agent中的新兴方法与前景
一、引言
随着人工智能技术的迅猛发展,AI Agent的应用场景越来越广泛。为了提升其智能决策的能力,跨模态学习作为一种融合多种数据模态的技术,已成为提升AI Agent性能的重要方向。跨模态学习能够使AI Agent在面对不同类型的数据源(如图像、文本、语音等)时,进行高效的信息融合,从而实现更为精确和智能的任务执行。
本文将深入探讨跨模态学习在AI Agent中的集成与优化策略,分析其在多模态数据处理中的优势,并提供相关代码实战,帮助理解如何实现这一技术。
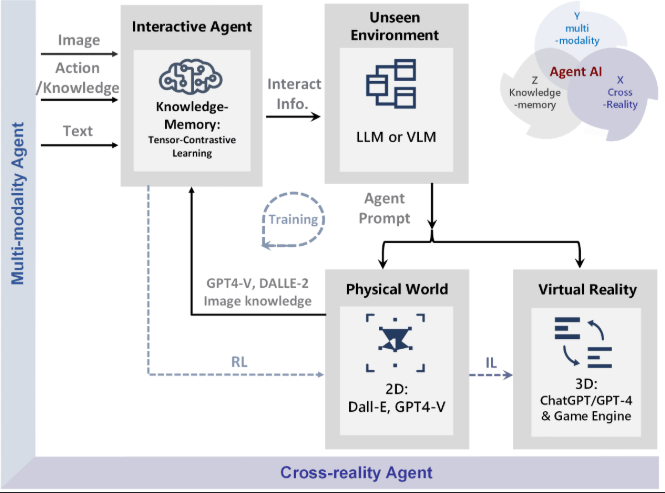
二、跨模态学习概述
2.1 跨模态学习的定义
跨模态学习(Cross-modal Learning)指的是在同一任务中,处理和学习来自不同模态(如视觉、听觉、语言等)的数据,以实现更丰富的信息表示。它主要包含以下几个方面:
- 模态融合:将来自不同来源的信息融合为统一的表示。
- 信息传递:在多模态数据中传递关键信息,增强模型对不同模态的理解能力。
2.2 跨模态学习的应用领域
跨模态学习在以下几个领域中有着广泛应用:
- 智能家居:通过语音、图像等多模态数据实现更加智能的交互。
- 自动驾驶:利用视觉、雷达、传感器等多种信息融合,提升自动驾驶系统的可靠性。
- 医疗健康:整合医学影像、临床数据等多模态信息,辅助诊断和治疗。
三、跨模态学习的AI Agent集成策略
3.1 跨模态学习模型的构建
在构建跨模态学习模型时,通常需要以下几个关键模块:
- 模态特征提取:从每个模态中提取出具有代表性的特征。
- 模态融合:将不同模态的特征进行融合,形成统一的表示。
- 决策模块:根据融合后的信息,进行智能决策和行为生成。
3.2 模态特征提取
针对每种模态,通常使用不同的深度学习模型进行特征提取。例如:
- 图像模态:采用卷积神经网络(CNN)提取图像特征。
- 文本模态:采用Transformer模型(如BERT)提取文本特征。
- 语音模态:采用声学模型(如CNN+RNN)提取语音特征。
3.3 模态融合方法
常见的模态融合方法包括:
- 早期融合:将不同模态的数据在输入层直接进行融合。
- 晚期融合:对每个模态分别进行处理,然后将其输出进行融合。
- 中期融合:在中间层对不同模态的信息进行融合,结合不同模态的上下文信息。
示例代码:图像与文本模态融合
以下是一个简单的图像与文本模态融合示例,采用CNN提取图像特征,BERT提取文本特征,最后通过一个全连接层进行融合。
import torch
import torch.nn as nn
from transformers import BertModel, BertTokenizer
# 图像特征提取模型(CNN)
class CNNFeatureExtractor(nn.Module):
def __init__(self):
super(CNNFeatureExtractor, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(64 * 32 * 32, 256) # 假设输入图片尺寸为64x64
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = x.view(x.size(0), -1)
return torch.relu(self.fc1(x))
# 文本特征提取模型(BERT)
class TextFeatureExtractor(nn.Module):
def __init__(self):
super(TextFeatureExtractor, self).__init__()
self.bert = BertModel.from_pretrained('bert-base-uncased')
self.fc1 = nn.Linear(768, 256) # BERT输出的特征维度为768
def forward(self, x):
outputs = self.bert(x)
last_hidden_state = outputs.last_hidden_state
pooled_output = last_hidden_state[:, 0] # 取[CLS]标记的输出
return torch.relu(self.fc1(pooled_output))
# 跨模态融合模型
class CrossModalFusionModel(nn.Module):
def __init__(self):
super(CrossModalFusionModel, self).__init__()
self.cnn_extractor = CNNFeatureExtractor()
self.text_extractor = TextFeatureExtractor()
self.fc2 = nn.Linear(512, 10) # 假设有10个分类
def forward(self, image, text):
image_features = self.cnn_extractor(image)
text_features = self.text_extractor(text)
combined_features = torch.cat((image_features, text_features), dim=1)
return self.fc2(combined_features)
# 假设数据输入
image_input = torch.randn(8, 3, 64, 64) # 批次大小8,3通道64x64的图像
text_input = torch.randint(0, 1000, (8, 50)) # 批次大小8,序列长度50的文本输入
# 模型训练
model = CrossModalFusionModel()
output = model(image_input, text_input)
print(output)
3.4 优化策略
在跨模态学习中,常见的优化策略包括:
- 自适应模态权重调整:根据每种模态的质量和可靠性动态调整权重,避免过度依赖某一模态。
- 模态特征选择:使用注意力机制或其他技术选择最有用的模态特征,提高模型的泛化能力。
- 多任务学习:通过引入多个相关任务,提升不同模态间的协同学习效果。
四、跨模态学习的挑战与未来方向
4.1 跨模态对齐的难度
不同模态之间的特征差异较大,如何将它们有效对齐是跨模态学习中的一个难点。未来可以通过更先进的对齐技术(如生成对抗网络)来优化这一过程。
4.2 数据稀缺问题
在某些应用中,某种模态的数据可能稀缺,导致模型的训练效果不佳。可以采用数据增强或迁移学习来缓解这一问题。
4.3 模态之间的互补性
如何处理不同模态之间的互补信息,使其协同作用,是提升AI Agent智能决策能力的关键。
五、跨模态学习的挑战与未来方向
5.1 跨模态对齐的难度
不同模态之间的特征差异较大,如何将它们有效对齐是跨模态学习中的一个难点。例如,图像数据具有高维度的空间信息,而文本数据则是顺序的、离散的。这些差异使得信息融合变得复杂。为了解决这一问题,研究者们提出了多种对齐方法,如生成对抗网络(GANs)和自监督学习方法,可以通过模型间的相互训练来提升跨模态对齐的效果。
未来的研究将更多集中在通过深度学习模型,特别是Transformer架构来捕捉跨模态之间的关系,实现高效的对齐机制。
5.2 数据稀缺问题
在许多实际应用中,某些模态的数据往往比其他模态更加稀缺。例如,文本数据通常比图像数据更加容易获得,而在特定领域(如医学影像诊断),高质量的图像数据可能相对匮乏。数据稀缺问题会限制模型在某些模态上的学习效果,从而影响整体性能。
为了解决这一问题,以下几种方法被广泛采用:
- 数据增强:通过生成对抗网络或自监督学习增强稀缺模态的数据。
- 迁移学习:通过从相似领域或任务中迁移预训练的模型,以补充不足的数据。
5.3 模态之间的互补性
不同模态之间可能包含互补的信息。如何有效地将这些信息结合起来,最大限度地提高AI Agent的整体性能,是跨模态学习中的一个重要挑战。某些模态可能包含对任务至关重要的信息,而其他模态则可以提供辅助或上下文信息。
针对这一挑战,研究者提出了几种策略:
- 注意力机制:在多模态融合时,使用注意力机制动态地为每种模态分配不同的权重,以便有效地提取最有用的信息。
- 多任务学习:通过设计多任务学习框架,让模型同时学习多个相关任务,促进模态间的协同学习。
5.4 模型可解释性
跨模态学习模型通常较为复杂,因此如何提高其可解释性,特别是当不同模态进行融合时,理解模型的决策过程尤为重要。通过引入可解释性框架(例如,SHAP或LIME),可以帮助我们理解模型如何根据不同模态的输入进行推理,确保其决策过程对用户是透明和可信的。
未来的研究将在跨模态学习模型的可解释性方面进行更多探索,特别是在深度神经网络中,如何通过可视化技术解释多模态数据的融合过程。
5.5 跨模态学习的实时性
在一些实时应用场景中,如自动驾驶、智能监控等,AI Agent需要在短时间内完成多模态信息的处理与融合。这要求跨模态学习模型不仅要准确,还需要高效。如何在保证性能的同时优化计算资源,提高模型的实时性,是未来研究的一个关键方向。
可以考虑以下技术来解决这一问题:
- 模型压缩:通过量化、剪枝等手段,压缩模型大小,提高计算效率。
- 边缘计算:将一部分模型计算迁移到边缘设备,减少数据传输延迟,提高系统反应速度。
六、跨模态学习在AI Agent中的前景
跨模态学习已经在多个领域展现了其强大的应用潜力,未来随着技术的进步和研究的深入,其在AI Agent中的应用将越来越广泛。通过有效地整合图像、文本、语音等不同模态的信息,AI Agent将能够更好地理解复杂的环境,做出更加智能的决策。
未来,跨模态学习将继续推动人工智能领域的创新,特别是在自动驾驶、智能家居、医疗健康等实际应用中,跨模态学习能够为AI Agent赋能,实现更加复杂和精准的任务执行。

- 点赞
- 收藏
- 关注作者
评论(0)