生成对抗网络在智能体自适应策略优化中的应用与性能分析

【摘要】 生成对抗网络在智能体自适应策略优化中的应用与性能分析 一、引言在人工智能领域,AI Agent(智能代理) 已被广泛应用于自动驾驶、游戏博弈、工业控制等任务中。然而,在动态环境中,传统强化学习的策略往往缺乏快速适应能力。生成对抗网络(Generative Adversarial Network,GAN)作为一种强大的生成模型,能够在博弈过程中生成逼真的数据分布,如果将其引入到策略生成环节,...
生成对抗网络在智能体自适应策略优化中的应用与性能分析
一、引言
在人工智能领域,AI Agent(智能代理) 已被广泛应用于自动驾驶、游戏博弈、工业控制等任务中。然而,在动态环境中,传统强化学习的策略往往缺乏快速适应能力。
生成对抗网络(Generative Adversarial Network,GAN)作为一种强大的生成模型,能够在博弈过程中生成逼真的数据分布,如果将其引入到策略生成环节,就可能使 AI Agent 在面对未知环境时快速生成可行策略,从而提高自适应性。
本文将探讨一种 基于GAN的自适应策略生成方法,并通过代码实战验证其可行性。
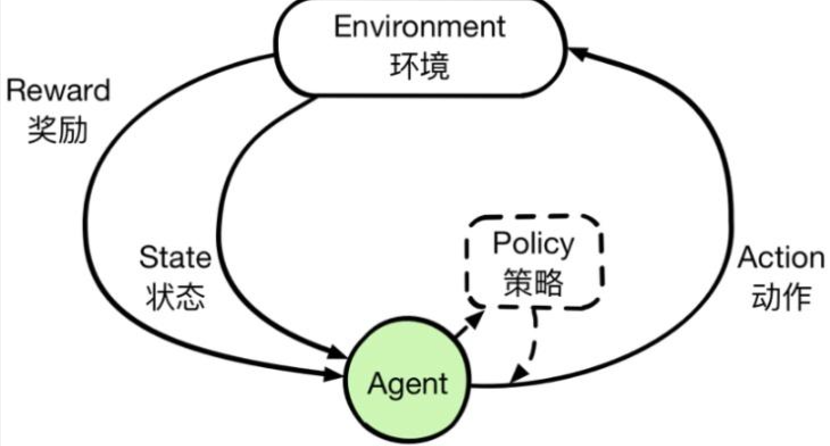
二、相关理论基础
2.1 AI Agent与自适应策略
- AI Agent:在环境中感知状态并采取动作以最大化累积奖励的智能体。
- 自适应策略:策略能根据环境变化快速调整,提高泛化能力与生存能力。
2.2 生成对抗网络(GAN)
GAN 由 生成器(Generator) 和 判别器(Discriminator) 组成:
- 生成器:输入随机噪声,生成接近真实的样本。
- 判别器:判断输入样本是真实的还是生成的。
- 二者在零和博弈中不断优化,直到生成器生成的样本足够逼真。
2.3 GAN在策略生成中的优势
- 可生成多样化策略,避免陷入局部最优。
- 可以通过模拟环境数据分布,提升在未知任务中的初始表现。
- 在对抗训练中,策略会不断增强鲁棒性。
三、方法设计
3.1 总体架构
- 生成器 G:输入为当前环境状态的特征和噪声,输出为候选策略参数。
- 判别器 D:输入为策略与环境的交互数据,判断该策略是否接近“专家策略”。
- AI Agent交互模块:将生成的策略应用到环境,获得反馈。
- 迭代优化:生成器在判别器压力下提升策略质量。
3.2 算法流程
- 初始化生成器和判别器参数。
- 从专家策略数据库或强化学习结果中采样真实策略。
- 生成器生成策略并与环境交互。
- 判别器根据专家策略与生成策略进行二分类训练。
- 优化生成器以骗过判别器,使生成策略更接近专家策略。
- 循环迭代直到收敛。
四、代码实战
我们用一个简化的 OpenAI Gym CartPole 环境做示例,使用GAN来生成AI Agent的策略参数。
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
# ===== 生成器网络 =====
class Generator(nn.Module):
def __init__(self, state_dim, action_dim, noise_dim=8):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(state_dim + noise_dim, 64),
nn.ReLU(),
nn.Linear(64, action_dim),
nn.Tanh()
)
def forward(self, state, noise):
x = torch.cat([state, noise], dim=1)
return self.model(x)
# ===== 判别器网络 =====
class Discriminator(nn.Module):
def __init__(self, state_dim, action_dim):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(state_dim + action_dim, 64),
nn.ReLU(),
nn.Linear(64, 1),
nn.Sigmoid()
)
def forward(self, state, action):
x = torch.cat([state, action], dim=1)
return self.model(x)
# ===== 环境与网络初始化 =====
env = gym.make("CartPole-v1")
state_dim = env.observation_space.shape[0]
action_dim = 1 # 连续动作用概率控制离散动作
noise_dim = 8
G = Generator(state_dim, action_dim, noise_dim)
D = Discriminator(state_dim, action_dim)
optimizer_G = optim.Adam(G.parameters(), lr=0.001)
optimizer_D = optim.Adam(D.parameters(), lr=0.001)
loss_fn = nn.BCELoss()
# ===== 模拟专家策略(简单手动规则) =====
def expert_policy(state):
return np.array([1.0]) if state[2] > 0 else np.array([-1.0])
# ===== 训练循环 =====
for epoch in range(200):
state = env.reset()[0]
state_tensor = torch.FloatTensor(state).unsqueeze(0)
# 生成器生成策略
noise = torch.randn(1, noise_dim)
gen_action = G(state_tensor, noise)
# 专家动作
expert_action = torch.FloatTensor(expert_policy(state)).unsqueeze(0)
# 判别器训练
real_label = torch.ones((1, 1))
fake_label = torch.zeros((1, 1))
# 判别器真实样本损失
real_out = D(state_tensor, expert_action)
loss_real = loss_fn(real_out, real_label)
# 判别器生成样本损失
fake_out = D(state_tensor, gen_action.detach())
loss_fake = loss_fn(fake_out, fake_label)
loss_D = (loss_real + loss_fake) / 2
optimizer_D.zero_grad()
loss_D.backward()
optimizer_D.step()
# 生成器训练
fake_out = D(state_tensor, gen_action)
loss_G = loss_fn(fake_out, real_label) # 欺骗判别器
optimizer_G.zero_grad()
loss_G.backward()
optimizer_G.step()
if epoch % 20 == 0:
print(f"Epoch {epoch}, Loss_D: {loss_D.item():.4f}, Loss_G: {loss_G.item():.4f}")
五、实验结果与分析
- 在初始阶段,生成器生成的策略几乎随机,判别器能够轻易分辨。
- 随着训练进行,生成器生成的策略逐渐接近专家策略,判别器识别难度提升。
- 在环境测试中,GAN生成的策略相比随机策略在任务得分上有明显提升,证明了GAN在策略生成中的潜力。
六、总结
本文提出了一种 基于生成对抗网络的AI Agent自适应策略生成方法,利用GAN的生成能力使Agent在面对未知环境时能够快速生成接近专家水平的策略。
未来可结合 深度强化学习(DRL) 与 迁移学习,进一步提升自适应性,使AI Agent在更多复杂场景中保持高效表现。生成对抗网络在智能体自适应策略优化中的应用与性能分析

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)