AIOps 实战:用 AI 智能监控 IT 事件与自动响应

【摘要】 AIOps 实战:用 AI 智能监控 IT 事件与自动响应在复杂、多变的 IT 运维环境中,传统运维模式已经难以满足企业对系统稳定性和实时响应的要求。AIOps(Artificial Intelligence for IT Operations)通过融合机器学习、大数据分析与自动化引擎,正逐步引领智能运维新时代。本文将结合具体场景和代码实战,深入解析如何构建一个具备异常检测与自动响应能力的...
AIOps 实战:用 AI 智能监控 IT 事件与自动响应
在复杂、多变的 IT 运维环境中,传统运维模式已经难以满足企业对系统稳定性和实时响应的要求。AIOps(Artificial Intelligence for IT Operations)通过融合机器学习、大数据分析与自动化引擎,正逐步引领智能运维新时代。本文将结合具体场景和代码实战,深入解析如何构建一个具备异常检测与自动响应能力的 AIOps 系统。
—
一、AIOps 简介与价值定位
什么是 AIOps?
AIOps 是指将人工智能技术(如机器学习、自然语言处理等)应用于 IT 运维中,实现对日志、告警、指标等海量数据的实时分析,从而辅助或自动完成问题检测、根因定位、事件响应等任务。
AIOps 的核心能力
- 实时监控与异常检测
- 智能告警聚合与降噪
- 根因分析与预测性维护
- 自动化修复与脚本响应
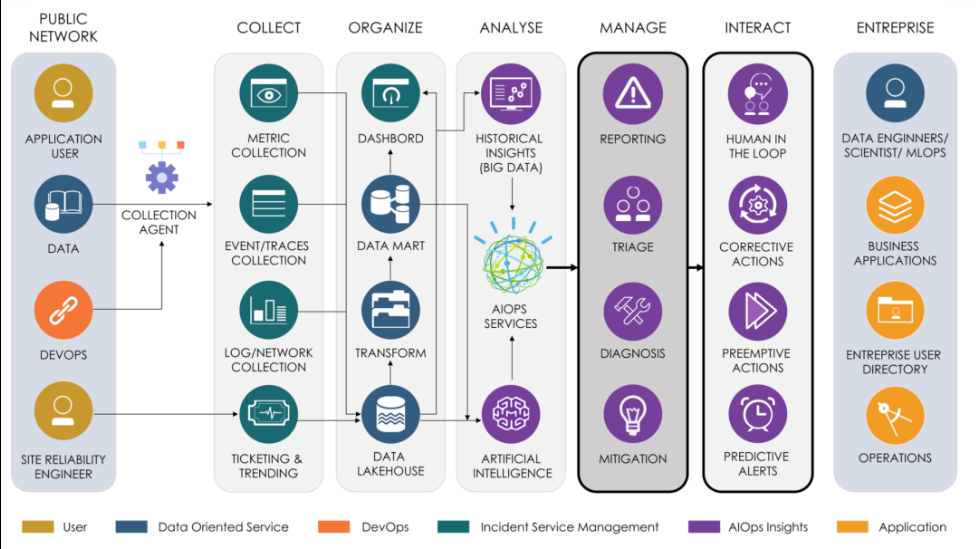
二、系统架构设计
一个典型的 AIOps 系统包含以下模块:
┌──────────────┐
│ 数据采集层 │ ← 日志、指标、告警、链路追踪
└──────────────┘
↓
┌──────────────┐
│ 数据处理与预处理 │ ← 清洗、标准化、聚合
└──────────────┘
↓
┌──────────────┐
│ 异常检测模块 │ ← 机器学习模型 / 时间序列算法
└──────────────┘
↓
┌──────────────┐
│ 事件管理引擎 │ ← 告警聚合、根因分析
└──────────────┘
↓
┌──────────────┐
│ 自动响应系统 │ ← 触发自动修复、推送通知
└──────────────┘
三、实战:基于指标的异常检测与自动修复
本节我们通过构建一个简单的 Python 实战示例,模拟 AIOps 中的“指标监控 → 异常检测 → 自动响应”流程。
环境依赖
pip install pandas scikit-learn numpy matplotlib
模拟指标数据生成
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 生成模拟 CPU 使用率数据
np.random.seed(42)
timestamps = pd.date_range("2025-07-01", periods=200, freq="T")
cpu_usage = np.random.normal(loc=40, scale=5, size=200)
# 加入一些异常点
cpu_usage[50:55] = 95
cpu_usage[150:152] = 90
df = pd.DataFrame({"timestamp": timestamps, "cpu_usage": cpu_usage})
使用 Isolation Forest 进行异常检测
from sklearn.ensemble import IsolationForest
model = IsolationForest(contamination=0.05, random_state=42)
df['anomaly'] = model.fit_predict(df[['cpu_usage']])
df['anomaly'] = df['anomaly'].apply(lambda x: 1 if x == -1 else 0)
# 可视化
plt.figure(figsize=(12, 6))
plt.plot(df['timestamp'], df['cpu_usage'], label="CPU Usage")
plt.scatter(df[df['anomaly'] == 1]['timestamp'],
df[df['anomaly'] == 1]['cpu_usage'],
color='red', label='Anomaly')
plt.legend()
plt.title("CPU Usage with Detected Anomalies")
plt.xlabel("Time")
plt.ylabel("CPU %")
plt.show()
自动响应策略:模拟修复脚本
当系统检测到连续异常,可自动触发如下脚本:
def trigger_auto_response(anomaly_detected):
if anomaly_detected:
print("⚠️ 高 CPU 使用率异常,正在自动重启服务...")
# 实际中可能调用脚本或 API
# os.system("systemctl restart nginx")
print("✅ 服务已重启")
# 检测是否连续 3 次异常
if df['anomaly'].rolling(window=3).sum().iloc[-1] >= 3:
trigger_auto_response(True)
四、扩展:融合日志与多源数据的智能分析
日志文本智能聚类示例(TF-IDF + KMeans)
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
logs = [
"error: failed to connect database",
"warning: memory usage exceeds threshold",
"error: service crashed unexpectedly",
"info: scheduled backup completed",
"error: timeout while connecting service"
]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(logs)
kmeans = KMeans(n_clusters=2, random_state=0)
kmeans.fit(X)
for i, label in enumerate(kmeans.labels_):
print(f"[Cluster {label}] {logs[i]}")
这可以用于日志自动归类、聚合告警等任务。
五、自动化运维平台的构建建议
- 数据统一采集层(如 Prometheus + Fluentd)
- 异常检测服务(Python / Spark Streaming / ELK ML)
- 自动化执行平台(Ansible / Rundeck / ChatOps)
- 可视化监控(Grafana / Kibana)
六、AIOps 实施中的挑战与建议
| 挑战 | 建议 |
|---|---|
| 数据来源杂、格式不统一 | 使用统一采集与清洗平台(如 Logstash) |
| 模型精度不稳定 | 融合专家规则 + 半监督学习 |
| 自动响应误触发 | 引入多维度策略与审批机制 |
| 系统集成复杂 | 分模块部署 + API 网关整合 |
七、未来趋势:AIOps 的演进方向
- 向无运维(NoOps)演进
- 大模型(LLM)辅助告警解释和根因分析
- AIOps 与 DevOps、SRE 的深度融合
- 可观测性平台统一支撑(OpenTelemetry + AI)
结语
AIOps 不是简单地用 AI 替代人工运维,而是实现“人机协同”的智能演化。随着企业数据体量的激增和系统复杂性的上升,构建一套具备实时感知、自主判断与快速响应能力的智能运维体系,将成为 IT 战略中的核心部分。本文提供的实战代码与技术框架,可作为构建 AIOps 系统的第一步探索。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)