华为云之基于DeepSeek搭建Agent智能助手实践指南【玩转华为云】

一、Ollma与DeepSeek介绍
1.1 Ollama简介
Ollama 是一个专注于在本地运行大型语言模型的开源工具和框架。它提供了一种简单的方式,让用户可以在本地计算机上运行、测试和开发基于大语言模型的应用,而无需依赖云端服务。Ollama 支持多种流行的模型,如 Llama 系列,并通过命令行界面(CLI)和 API 接口提供便捷的交互方式,适合开发者和研究人员快速部署和实验大模型。由于其轻量级的设计和对 GPU 的良好支持,Ollama 成为了许多本地 AI 开发者的首选工具。
1.2 DeepSeek简介
DeepSeek 是一家由中国团队开发的大型语言模型公司,致力于构建高性能、大规模的语言模型,提供包括对话理解、文本生成、编程代码生成等多种能力。其核心产品 DeepSeek 系列模型在语言理解与生成方面表现出色,部分版本在性能上可与国际主流模型相媲美。DeepSeek 提供多种模型版本,支持企业级应用场景,并可通过 API 接入,适用于客服、内容创作、智能助手等多个领域。其目标是通过持续的技术创新,推动大模型在更多行业的落地应用。
二、本次实践介绍
2.1 实践环境简介
本次实践将在华为云开发者云实验平台上进行,使用华为云ECS弹性云服务器来搭建运行环境,并选用DeepSeek 1.5b模型版本,其1.1GB的权重文件便于快速部署。该模型在CPU环境下运行流畅,非常适合个人体验和开发Agent科研助手。通过此次实践,我们将掌握掌握Agent科研助手的代码实现。
2.2 本次实践目标
- 熟悉华为云 ECS 服务器的相关知识与操作。
- 熟练运用 Linux 系统环境。
- 掌握通过 Ollama 来部署 DeepSeek R1 模型的方法
- 掌握Agent科研助手的代码实现
2.3 华为云ECS云服务器介绍
华为云弹性云服务器(ECS)作为一种云上计算服务,支持用户随时自助获取,且具备弹性伸缩能力。它能为用户打造出安全、可靠的应用环境,保障应用稳定运行。同时,其灵活、高效的特性,能很好地满足不同场景下的使用需求,为用户提供优质的服务体验。

三、购买ECS云服务器
3.1 登录华为云
查看华为云实验账号信息:进入实验环境后,我们在左侧的实验手册中可以看到华为云实验账号。
进入【实验操作桌面】,打开Chrome浏览器,首次可自动登录并进入华为云控制台页面。
登录完毕后,我们进入华为云控制台管理首页。
3.2 购买弹性云服务器
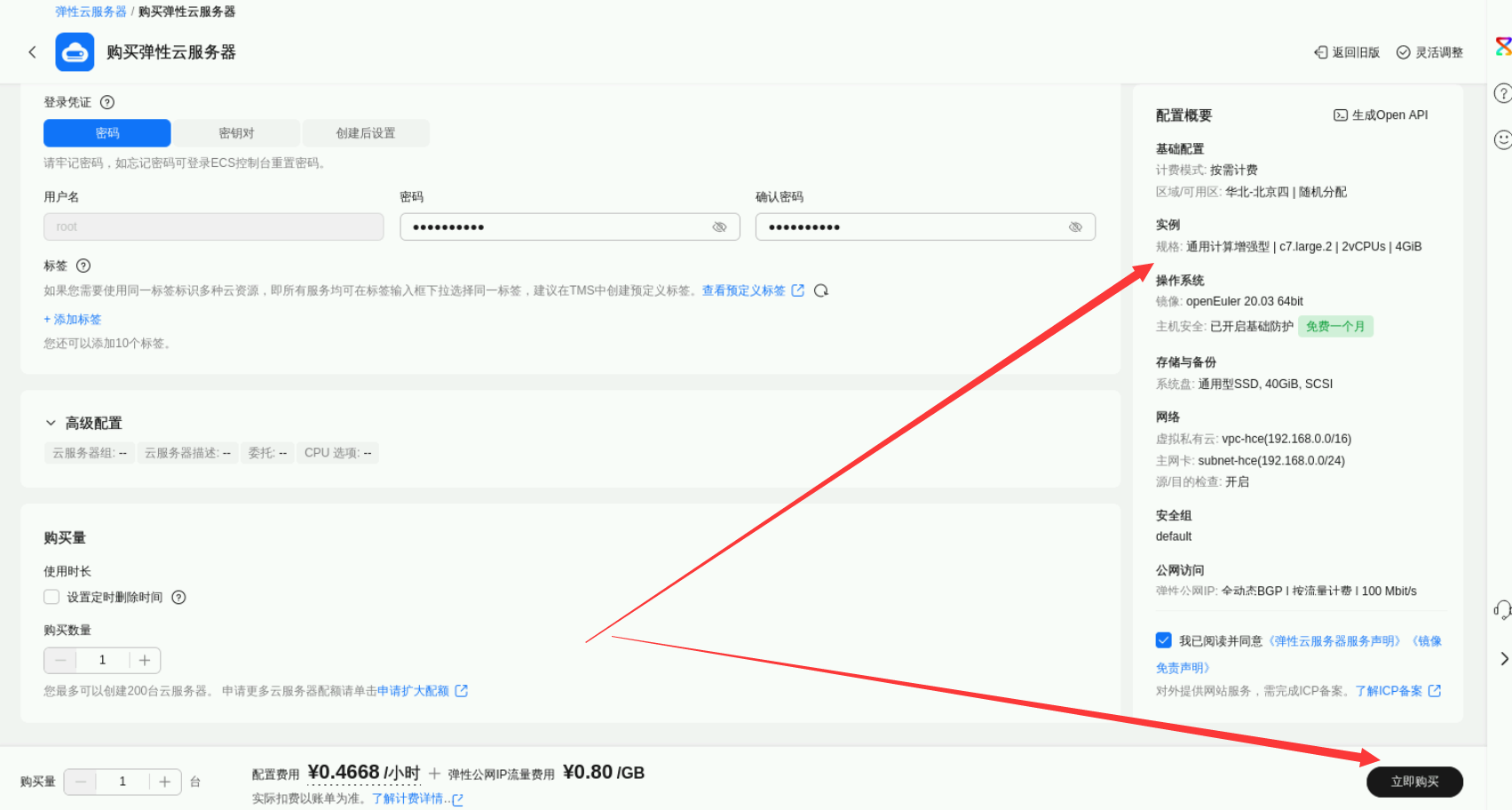
在华为云控制台中,我们点击弹性云服务器ECS【创建】选项,进入ECS购买界面。
购买的ECS实力,可参考以下配置:
- 计费模式:按需计费
- 区域:北京四,可用随机
- 实例规格:CPU架构选择X86架构,规格为c7.xlarge.2
- 系统盘:通用型SSD,40G
- 操作系统:使用镜像为openEuler 22.03 64bit(10GiB)
- 网络配置:VPC均保持默认即可
- 安全组:默认
- 公网访问:弹性公网-购买,全动态BGP,按流量计费,100Mbit/带宽;
- 云服务器管理:服务器名称默认自定义,服务器密码自行设置。
- 其余配置默认即可,配置完毕后,可检查配置概要以检查配置是否正确,点击“立即购买”。
3.3登录ECS弹性云服务器
返回弹性云服务器列表后,可以看到我们购买的弹性云服务器ECS状态正常。
- 安全组配置:在入方向上,放行22端口。
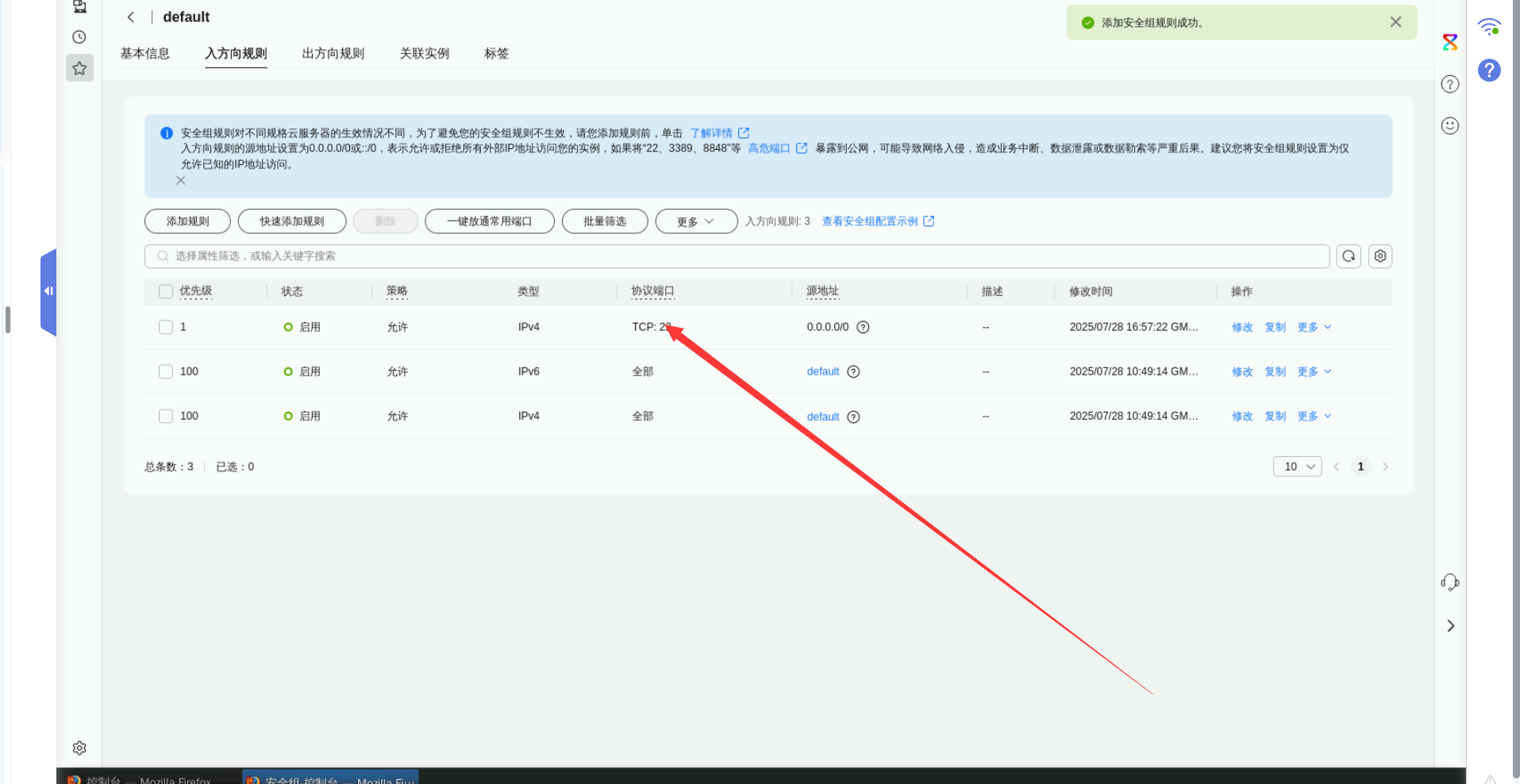
我们通过实验桌面的Xfce工具进行SSH连接ECS,将以下命令的EIP替换我们实际ECS的弹性公网IP地址。如果无法登录,需要修改安全组配置,放行22端口。
ssh root@*EIP*
3.4 检查系统环境
检查操作系统版本和内核版本,如下所示:
[root@ecs-d377 ~]# cat /etc/os-release
NAME="openEuler"
VERSION="20.03 (LTS)"
ID="openEuler"
VERSION_ID="20.03"
PRETTY_NAME="openEuler 20.03 (LTS)"
ANSI_COLOR="0;31"
[root@ecs-d377 ~]# uname -r
4.19.90-2003.4.0.0036.oe1.x86_64
四、安装ollama工具
4.1 下载ollama安装包
下载ollama安装包进行安装,如下所示:
wget https://sandbox-experiment-files.obs.cn-north-4.myhuaweicloud.com/deepseek/ollama-linux-amd64.tgz
- 解压ollama安装包,执行以下命令:
sudo tar -C /usr -xzf ollama-linux-amd64.tgz
4.3 创建用户
设置ollama执行权限和创建ollama用户
sudo chmod +x /usr/bin/ollama
sudo useradd -r -s /bin/false -m -d /usr/share/ollama ollama
4.4 配置ollama服务开机自启
在/etc/systemd/system/ollama.service文件中,编辑服务配置文件。
cat << EOF > /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
[Install]
WantedBy=default.target
EOF
执行以下命令,启动ollama服务并设置开机自启。
sudo systemctl daemon-reload
sudo systemctl enable ollama
sudo systemctl start ollama
4.5 检查Ollama服务状态
检查ollama服务状态,确保正常启动。
sudo systemctl status ollama
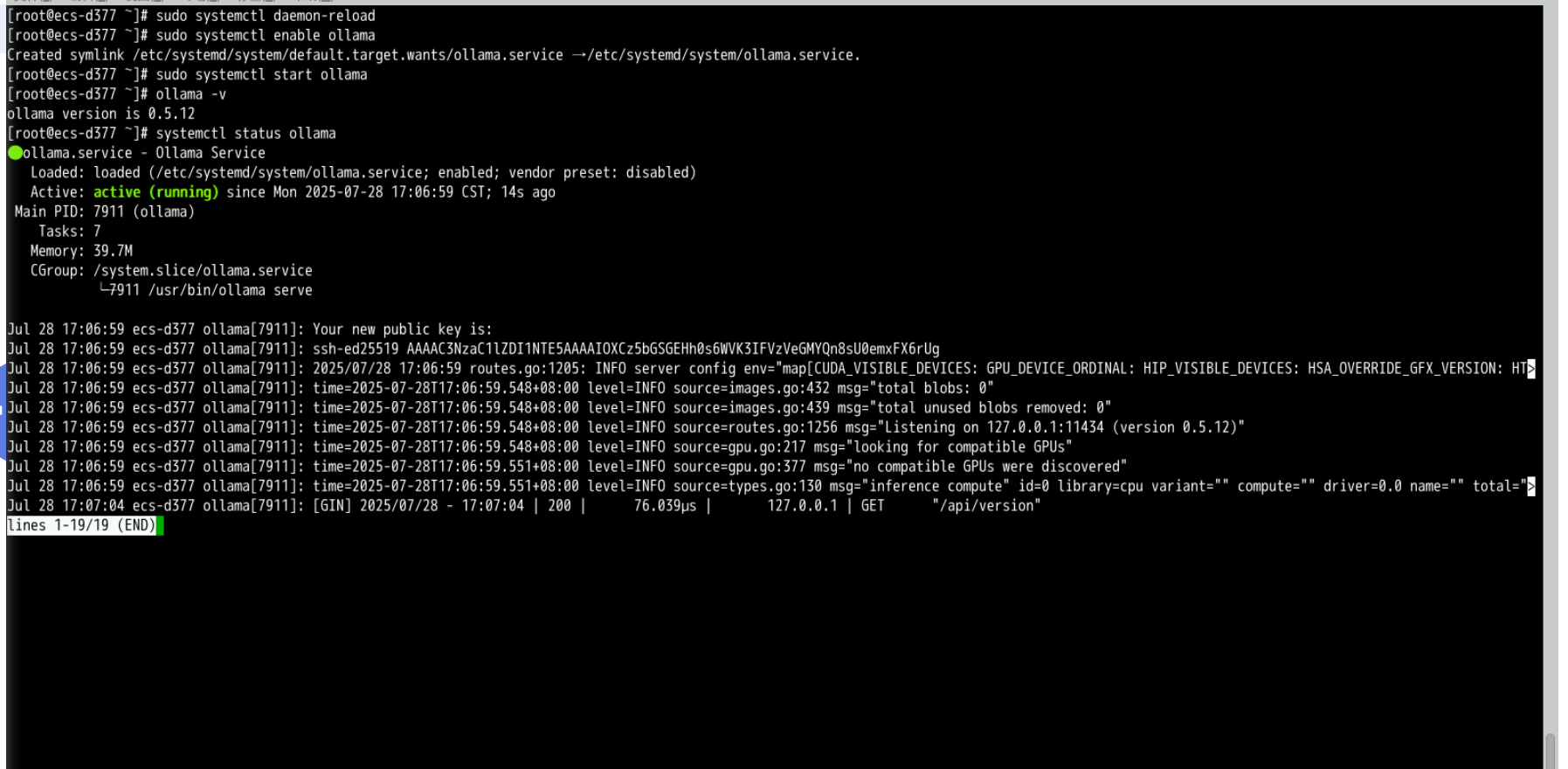
检查ollama安装版本,如下所示:
ollama -v

五、运行DeepSeek大模型
5.1 下载模型文件(方法一,可选)
可使用ollama命令直接拉取deepseek-r1:1.5b模型,简单方便一个命令搞定,需要保证网络环境正常,下载速度比较慢。
ollama pull deepseek-r1:1.5b
5.2 下载模型文件(方法二)
在华为云OBS下载ollama模型文件deepseek-r1:1.5b,如下所示:
wget https://sandbox-experiment-files.obs.cn-north-4.myhuaweicloud.com/deepseek/ollama_deepseek_r1_1.5b.tar.gz
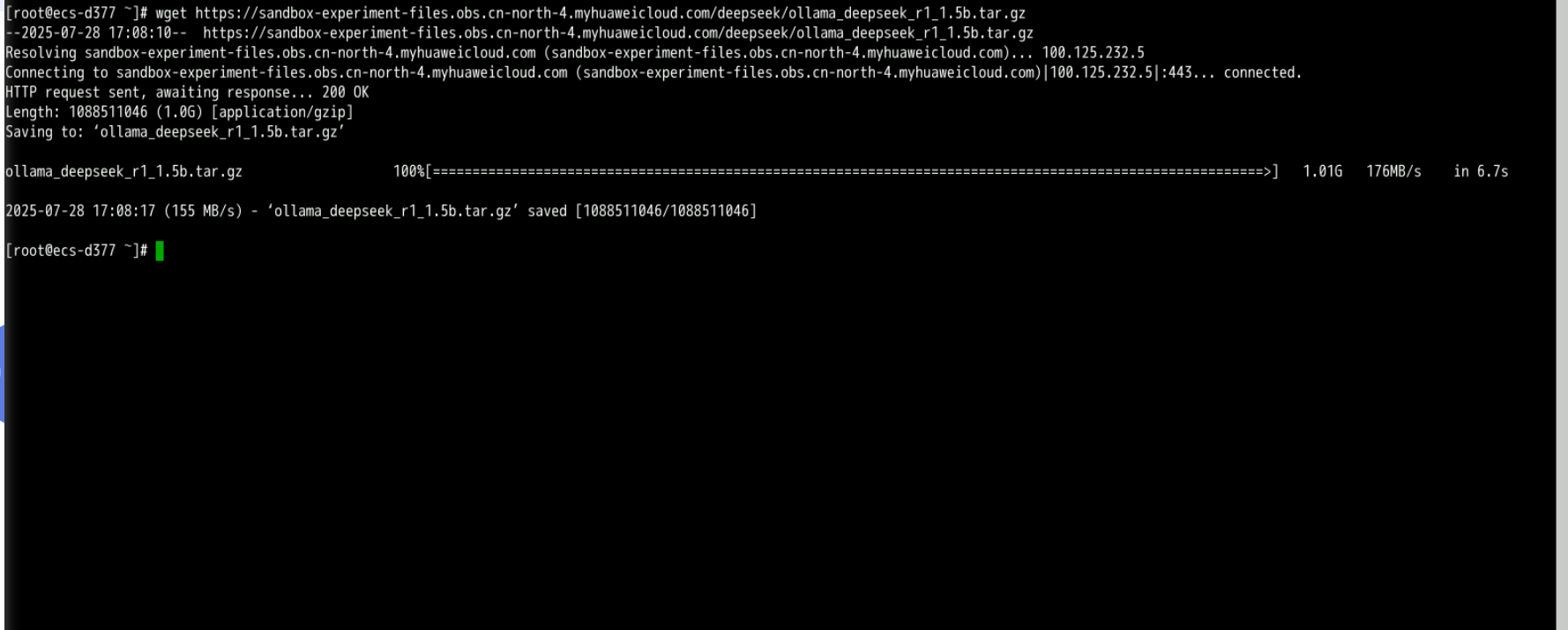
- 进行解压缩操作:
sudo tar -C /usr/share/ollama/.ollama/models -xzf ollama_deepseek_r1_1.5b.tar.gz
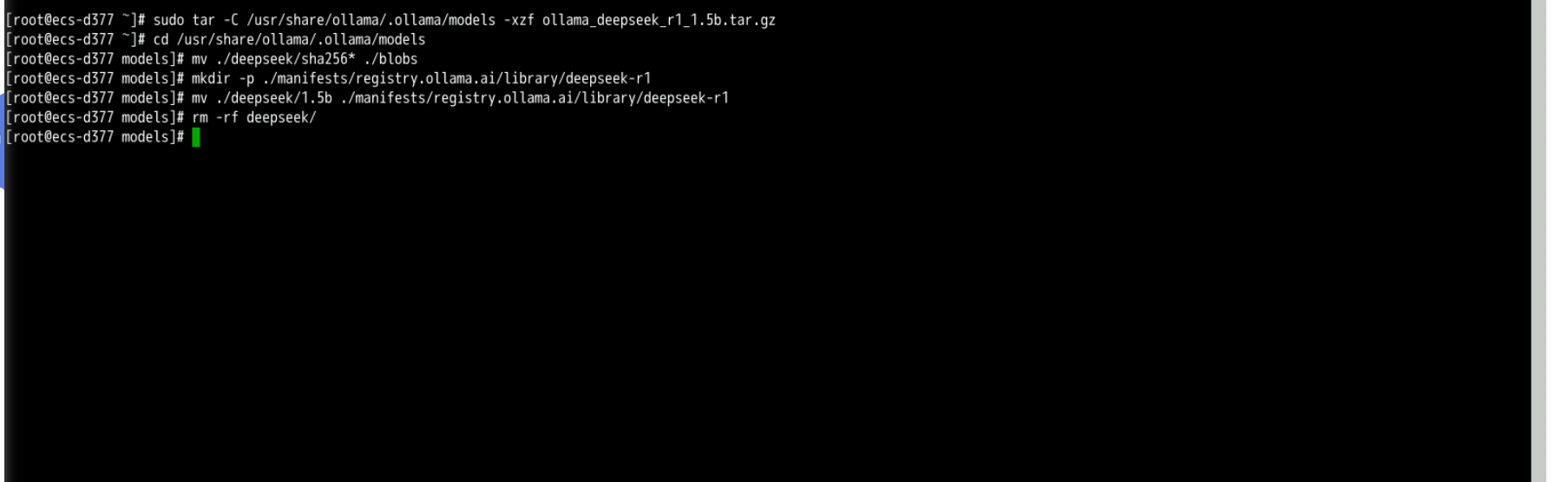
- 将解压后的ollama模型文件放在ollama目录:
cd /usr/share/ollama/.ollama/models
mv ./deepseek/sha256* ./blobs
mkdir -p ./manifests/registry.ollama.ai/library/deepseek-r1
mv ./deepseek/1.5b ./manifests/registry.ollama.ai/library/deepseek-r1
rm -rf deepseek/
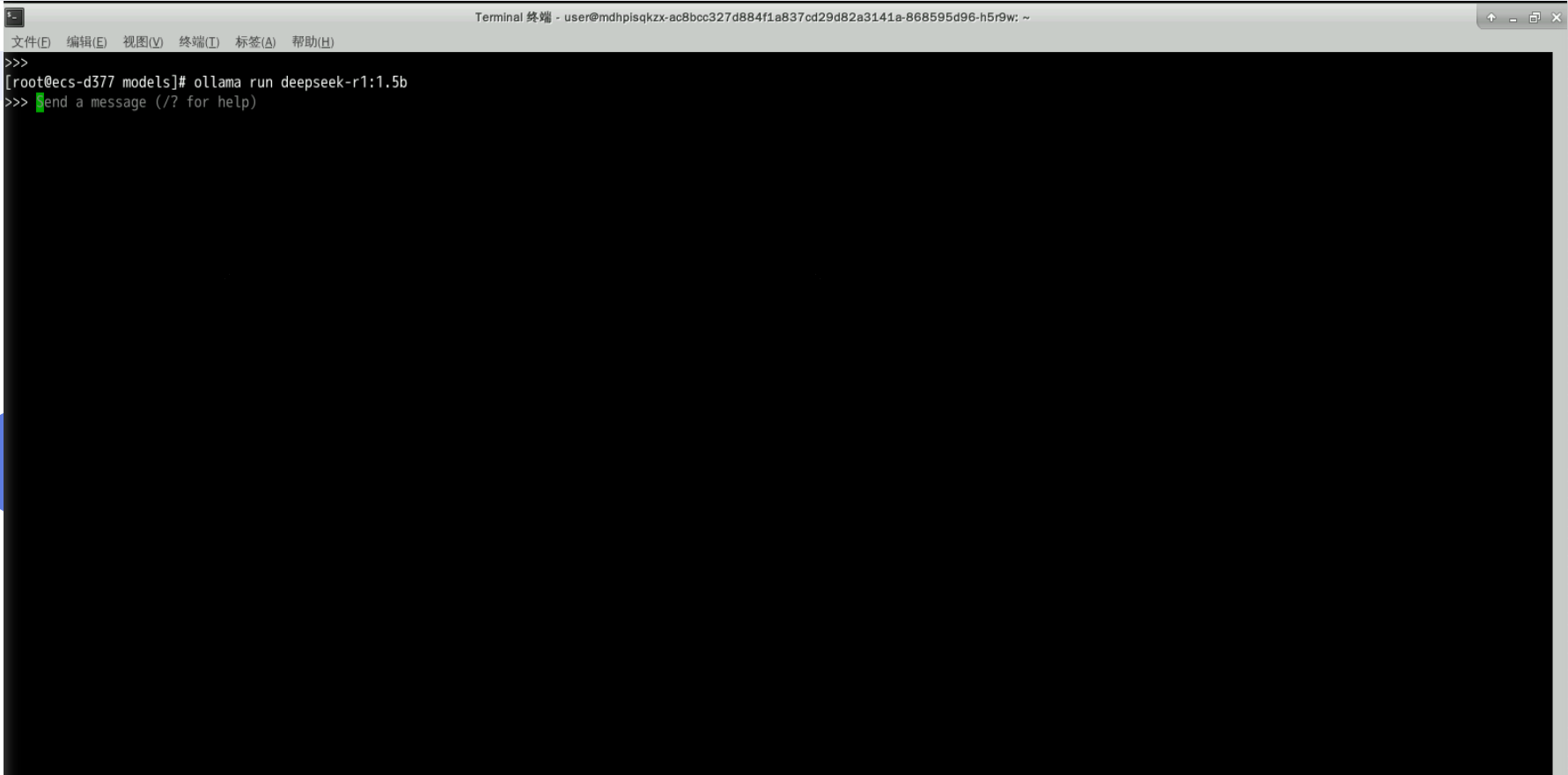
5.3 运行DeepSeek模型
- 执行以下命令,运行deepseek-r1:1.5b
ollama run deepseek-r1:1.5b
注意:运行报错提示权限报错,需要执行以下命令,进行权限授权。
chown -R ollama:ollama /usr/share/ollama/
chown -R ollama:ollama /usr/lib/ollama/
六、部署Agent智能助手
6.1 构建知识库
我们新建及编辑library.txt文件,涉及各种科目的文献资料。
vim library.txt
深度学习在医学影像诊断中的应用:本文探讨了深度学习技术在医学影像诊断中的应用,重点研究了卷积神经网络(CNN)在识别病理图像中的准确性。通过对比传统方法,深度学习模型在检测肿瘤和病变方面表现出更高的敏感性和特异性。研究结果表明,深度学习有望成为未来医学影像诊断的重要工具。
人工智能在疾病预测中的应用:本文研究了人工智能技术在疾病预测中的应用,特别是机器学习算法在分析电子健康记录中的有效性。研究发现,基于机器学习的模型能够准确预测慢性疾病的发生风险,为早期干预提供了重要依据。文章建议进一步优化算法以提高预测精度。
气候变化对全球生物多样性的长期影响:本研究分析了过去50年气候变化对全球生物多样性的长期影响。通过建立生态模型,我们发现温度升高和降水模式的改变对物种分布产生了显著影响。研究预测,如果不采取有效措施,未来几十年内许多物种将面临灭绝风险。文章呼吁加强全球生态保护措施,以应对气候变化带来的挑战。
气候变化与海洋生态系统:本文探讨了气候变化对海洋生态系统的影响,重点关注海洋温度上升和酸化对珊瑚礁和海洋生物的影响。研究发现,珊瑚礁的白化现象与海水温度升高密切相关,而海洋酸化则对贝类生物的生存构成威胁。文章建议采取全球行动以减缓气候变化对海洋生态系统的影响。
量子计算的现状与未来发展趋势:量子计算作为一种新兴技术,正在迅速发展。本文综述了量子计算的基本原理、当前的技术进展以及面临的挑战。研究指出,量子比特的稳定性是实现大规模量子计算的关键。此外,文章还探讨了量子计算在密码学、材料科学和人工智能等领域的潜在应用。
量子通信技术的突破与应用:本文介绍了量子通信技术的最新突破及其在信息安全领域的应用。量子通信利用量子纠缠和不可克隆定理,实现了理论上无条件安全的通信。研究展示了量子通信在金融、军事和政务领域的应用前景,并讨论了其商业化面临的挑战。
人工智能伦理:算法偏见与社会公平:随着人工智能技术的广泛应用,算法偏见问题日益受到关注。本文分析了算法偏见的成因及其对社会公平的影响,提出了几种减少偏见的方法,包括数据增强、模型校准和公平性评估指标。研究强调,确保人工智能的公平性是实现技术可持续发展的关键。
人工智能在司法领域的应用与伦理挑战:本文探讨了人工智能在司法领域的应用,特别是算法辅助判决系统的伦理问题。研究指出,虽然人工智能可以提高司法效率,但也可能因算法偏见导致不公正的结果。文章建议建立伦理框架以规范人工智能在司法领域的应用。
新能源汽车的市场接受度与政策影响:本文通过市场调研和数据分析,探讨了新能源汽车的市场接受度及其受政策影响的程度。研究发现,政府补贴和基础设施建设对消费者购买意愿有显著影响。文章建议进一步完善政策支持体系,以加速新能源汽车的市场普及。
新能源汽车的电池技术与可持续发展:本文研究了新能源汽车的电池技术进展及其对可持续发展的影响。研究指出,电池能量密度的提高和成本的降低是推动新能源汽车普及的关键。文章还讨论了电池回收和再利用的重要性,以减少对环境的影响。
基因编辑技术在农业中的应用与挑战:基因编辑技术为农业发展带来了新的机遇。本文综述了基因编辑在提高作物抗病性、产量和营养价值方面的应用。同时,文章也讨论了基因编辑技术面临的伦理和监管挑战,呼吁建立科学合理的政策框架以推动其可持续发展。
基因编辑技术在医学中的应用与伦理困境:本文探讨了基因编辑技术在医学中的应用,特别是治疗遗传性疾病和癌症的潜力。研究指出,虽然基因编辑技术在治疗方面具有巨大潜力,但也引发了关于人类生殖系编辑的伦理争议。文章呼吁加强伦理审查和公众讨论。
5G通信技术对工业互联网的推动作用:5G通信技术的高速率和低延迟特性使其成为工业互联网的重要支撑。本文分析了5G技术在智能制造、远程控制和物联网中的应用。研究指出,5G技术能够显著提高生产效率和灵活性,但同时也需要解决网络安全和数据隐私问题。
6G通信技术的展望与挑战:本文展望了6G通信技术的发展前景及其面临的挑战。6G技术预计将实现更高的数据传输速率和更低的延迟,支持更广泛的应用场景。研究讨论了6G技术的关键技术方向,包括太赫兹通信和智能反射面技术,并分析了其商业化的时间表和潜在障碍。
海洋微塑料污染的生态影响与治理策略:海洋微塑料污染已成为全球性的环境问题。本文通过实地采样和实验研究,分析了微塑料对海洋生物的生态影响。研究发现,微塑料能够吸附有害物质并进入食物链,对海洋生态系统构成威胁。文章提出了几种治理策略,包括源头控制和生态修复。
微塑料污染对淡水生态系统的威胁:本文研究了微塑料污染对淡水生态系统的影响,重点关注湖泊和河流中的微塑料分布及其对水生生物的影响。研究发现,微塑料通过食物链传递,对淡水生物的健康和生存构成威胁。文章建议加强监测和治理措施,以保护淡水生态系统。
区块链技术在供应链管理中的应用:区块链技术以其去中心化和不可篡改的特性,为供应链管理带来了新的解决方案。本文探讨了区块链在提高供应链透明度、降低成本和增强安全性方面的应用。研究结果表明,区块链技术能够有效优化供应链管理流程,提升企业竞争力。
区块链技术在金融领域的应用与挑战:本文研究了区块链技术在金融领域的应用,特别是去中心化金融(DeFi)的发展。研究指出,区块链技术能够提高金融交易的透明度和效率,但也面临监管和安全挑战。文章讨论了区块链技术在金融领域的未来发展方向。
虚拟现实技术在教育领域的创新应用:虚拟现实(VR)技术为教育领域带来了全新的教学体验。本文研究了VR技术在沉浸式学习、远程教育和职业培训中的应用。研究发现,VR技术能够显著提高学生的学习兴趣和效果,但同时也需要解决设备成本和内容开发的挑战。
增强现实技术在工业培训中的应用:本文探讨了增强现实(AR)技术在工业培训中的应用,特别是通过AR设备提供实时指导和培训。研究发现,AR技术能够提高培训效率和质量,减少人为错误。文章讨论了AR技术在工业领域的未来应用前景。
6.2 编辑prompt.txt文件
编辑prompt.txt文件,如下所示:
vim prompt.txt
你是一个文献综述专家
6.3 智能助手实现
- 构建主文件,内容如下:
vim main.py
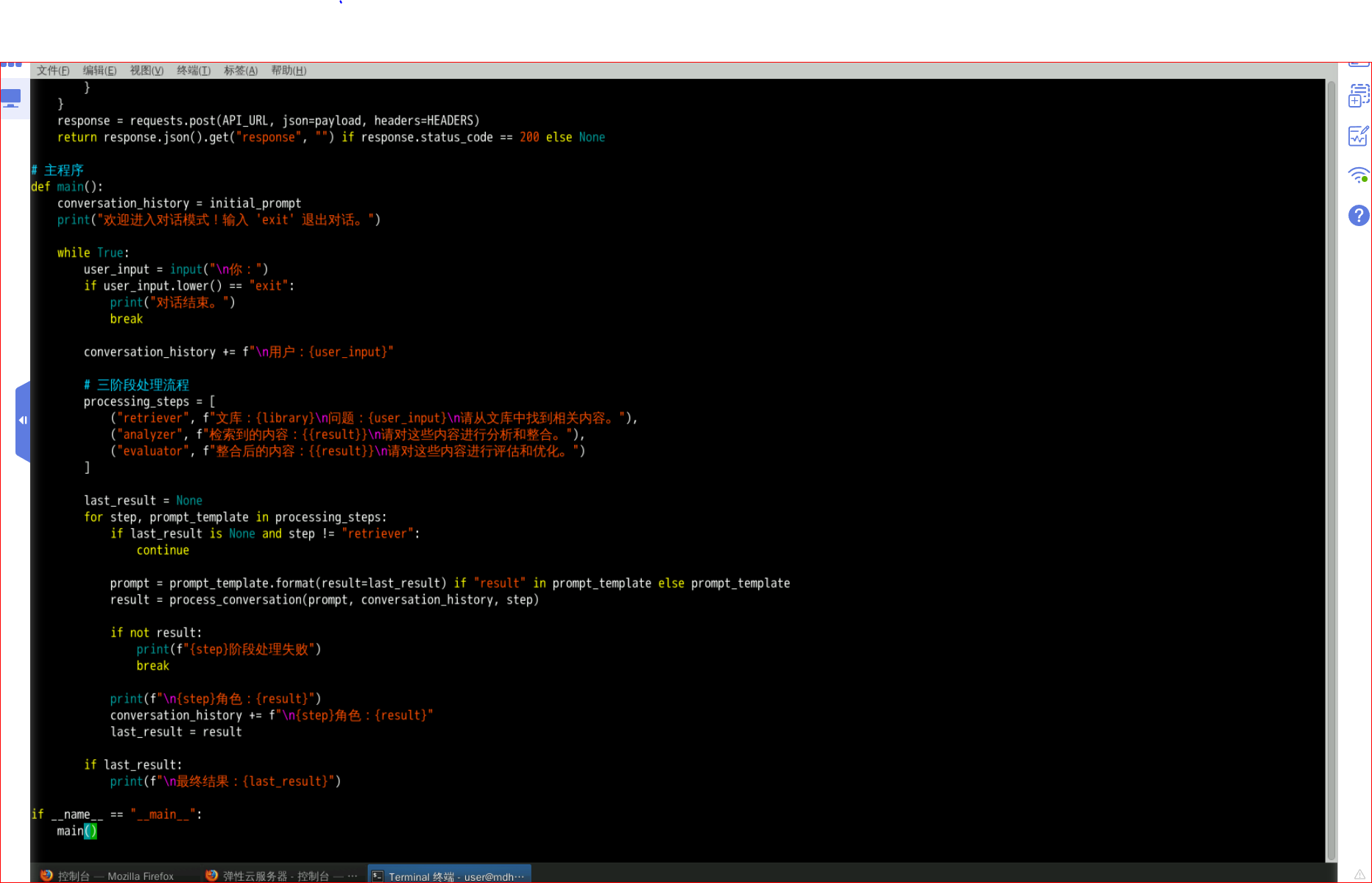
import requests
import json
# ????
API_URL = "http://localhost:11434/api/generate"
HEADERS = {"Content-Type": "application/json"}
MODEL_NAME = "deepseek-r1:1.5b"
# ????
ROLE_PROMPTS = {
"retriever": "??????????????????????????",
"analyzer": "??????????????????????????",
"evaluator": "??????????????????????????"
}
# ?????????
def load_file(filename):
with open(filename, "r", encoding="utf-8") as file:
return file.read().strip()
initial_prompt = load_file("prompt.txt")
library = load_file("library.txt")
# ??????
def process_conversation(prompt, history, role_type):
payload = {
"model": MODEL_NAME,
"prompt": f"{ROLE_PROMPTS[role_type]}\n{history}\n{prompt}",
"stream": False,
"options": {
"temperature": 0.5,
"num_predict": 512,
"seed": 42
}
}
response = requests.post(API_URL, json=payload, headers=HEADERS)
return response.json().get("response", "") if response.status_code == 200 else None
# ???
def main():
conversation_history = initial_prompt
print("??????????? 'exit' ?????")
while True:
user_input = input("\n??")
if user_input.lower() == "exit":
print("?????")
break
conversation_history += f"\n???{user_input}"
# ???????
processing_steps = [
("retriever", f"???{library}\n???{user_input}\n????????????"),
("analyzer", f"???????{{result}}\n??????????????"),
("evaluator", f"???????{{result}}\n??????????????")
]
last_result = None
for step, prompt_template in processing_steps:
if last_result is None and step != "retriever":
continue
prompt = prompt_template.format(result=last_result) if "result" in prompt_template else prompt_template
result = process_conversation(prompt, conversation_history, step)
if not result:
print(f"{step}??????")
break
print(f"\n{step}???{result}")
conversation_history += f"\n{step}???{result}"
last_result = result
if last_result:
print(f"\n?????{last_result}")
if __name__ == "__main__":
main()
- 进行测试效果:
python3 main.py
- 进行提问:
人工智能伦理相关的论文综述
可以看到第一步:检索专家从文档中进行相关内容的检索,此步骤需要等待时间长,需耐心等待几分钟。

在第二步中,分析专家将基于检索专家提供的输入内容进行深入分析。这一阶段的任务是仔细审查检索到的信息,并对其进行解析和提炼,以便准确理解用户的需求并提供有价值的反馈。分析专家不仅要对检索结果进行筛选以去除无关或冗余的数据,还需要识别关键信息点,将其组织成结构化的知识,便于后续处理。此外,分析过程可能包括数据的分类、情感分析、主题提取等高级操作,以确保输出的内容既精确又具有相关性。通过这种方式,分析专家能够为最终用户提供更加精准和个性化的回答。

在第三步中,评估专家将对分析专家输出的内容进行综合评审与优化。该环节旨在确保最终回复的准确性、逻辑性和完整性,提升回答的质量与用户体验。评估专家会检查内容是否存在遗漏、矛盾或模糊之处,并根据需要提出改进建议。同时,可结合用户反馈或预设评价标准进行动态调整,实现结果的持续优化。通过这一过程,系统能够输出更加可靠、专业且贴近用户需求的最终答案。

七、总结
本次基于华为云ECS搭建DeepSeek大模型Agent智能助手的实践顺利完成,成功实现了模型的部署与基础智能问答功能。通过Ollama工具的集成,有效简化了大模型的本地运行与管理流程。构建的多角色Agent框架初步实现了任务的分工协作,展示了良好的应用潜力。未来可通过优化角色分工、增强上下文管理与知识库动态更新机制,进一步提升系统的智能化水平。引入反馈回路和自我纠错机制,将有助于提高Agent的准确性和鲁棒性,为构建更复杂的智能应用奠定基础。

- 点赞
- 收藏
- 关注作者
评论(0)