AI 基础设施弹性设计:容错、混合云与边缘协同机制

AI 基础设施弹性设计:容错、混合云与边缘协同机制
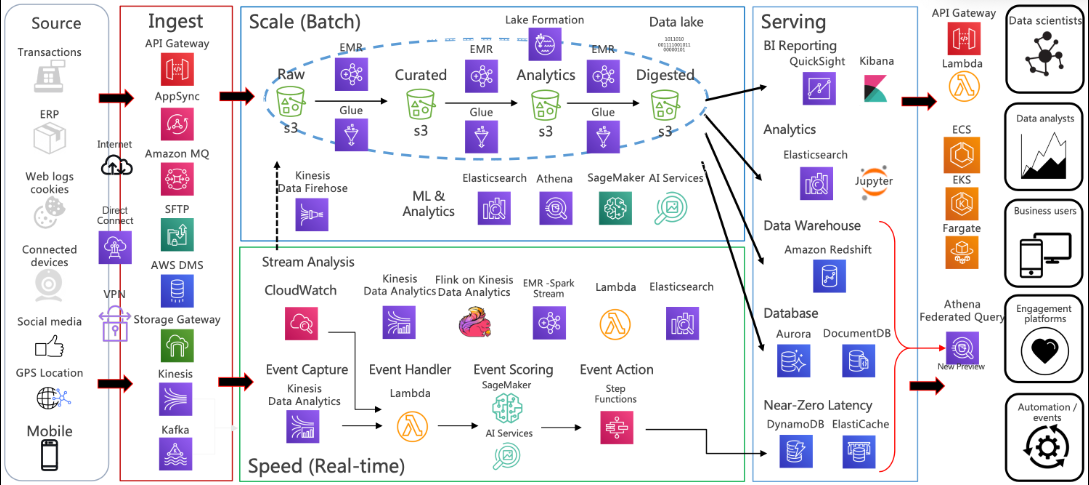
在AI系统日益部署于分布式环境的今天,基础设施的弹性设计成为AI系统稳定性、可用性与可扩展性的核心支撑。本文从容错机制、混合云策略与边缘协同三个维度,探讨AI基础设施的弹性构建方法,结合架构设计与实际代码,提供实操指导。
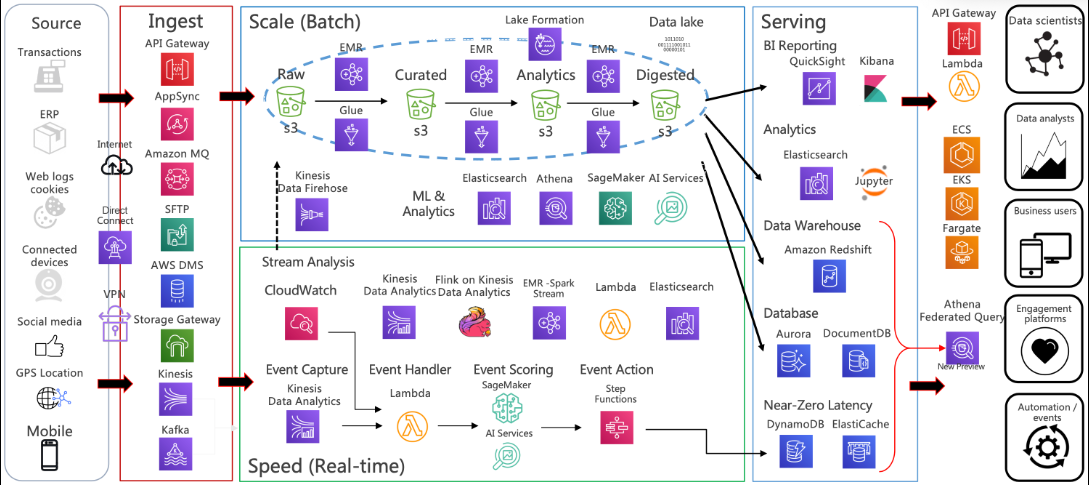
一、引言:为何AI需要弹性基础设施
AI服务常常涉及高并发、海量数据处理、模型高频调用等场景。传统静态部署方案已难以应对以下挑战:
- 服务节点宕机带来的任务中断
- 云服务延迟/成本问题
- 模型推理延迟在边缘侧的性能瓶颈
- 大模型多GPU/多设备部署复杂度
因此,我们需要构建具备容错能力、支持混合部署,并可进行边缘计算协同的AI基础设施,提升系统鲁棒性与服务连续性。
二、容错机制设计:故障检测与自动恢复
容错机制的目标是实现“局部故障不影响整体服务”,可从以下几个层面入手:
1. 节点健康检查与重调度
通过**心跳检测(Heartbeat)**机制,判断服务节点是否存活,并可使用调度器进行容灾重启或转移。
# 简单示例:基于Flask的AI推理API健康检测
from flask import Flask, jsonify
import random
app = Flask(__name__)
@app.route("/health", methods=["GET"])
def health_check():
# 模拟节点偶尔宕机
if random.random() > 0.9:
return jsonify({"status": "fail"}), 500
return jsonify({"status": "ok"}), 200
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000)
可以通过Kubernetes livenessProbe或Prometheus + AlertManager对该API进行周期检测,并触发重启。
2. 推理任务的容错调度(Task Fallback)
推理任务失败后,应支持自动转移至备选节点:
def inference_with_fallback(input_data, primary_node, backup_node):
try:
return call_inference_api(primary_node, input_data)
except Exception as e:
print("Primary node failed, switching to backup.")
return call_inference_api(backup_node, input_data)
三、混合云部署:灵活利用公有云与私有资源
1. 为什么选择混合云
- 公有云适合弹性扩展与大规模训练
- 私有云/本地GPU适合数据敏感、推理低延迟场景
- 成本优化:模型训练上云,推理边缘部署
2. 混合云架构图
+-----------------+
| 公有云(AWS) |
| Model Training |
+-----------------+
||
|| 模型同步/优化
\/
+----------------------+
| 私有云/本地集群 |
| 模型压缩+部署 |
+----------------------+
||
||
+------------------------+
| 边缘节点 / IoT设备 |
| 模型推理服务 |
+------------------------+
3. 自动切换资源:基于负载和成本
def schedule_model_execution(task, load_level):
if load_level > 0.8:
return call_cloud_model(task)
else:
return call_onprem_model(task)
四、边缘协同机制:实时推理与模型分片
1. 模型边缘化:轻量模型部署方案
可使用如ONNX+TensorRT或PyTorch Mobile将主模型裁剪后部署边缘:
# 模型转换为 ONNX
python export_model.py --weights yolov8.pt --img 640 --batch 1 --device 0 --include onnx
2. 模型分片机制(用于边-云协同)
可采用“前处理+主干边缘,决策云端”策略:
# 边缘端执行预处理与特征提取
features = edge_model.extract_features(input_frame)
# 云端做最终分类决策
classification = cloud_model.classify(features)
此方法可以有效压缩带宽,提高响应速度,常用于智能摄像头、无人车等边缘计算场景。
五、案例分析:人脸识别系统的弹性部署
场景设定:
- 边缘摄像头采集人脸图像
- 边缘设备进行预处理、特征提取
- 云服务进行身份识别与聚类分析
- 系统支持容错恢复与跨云热迁移
架构亮点:
- 使用Redis做任务队列缓存,避免数据丢失
- 使用Kubernetes部署微服务并设置重启策略
- 模型采用ONNX在边缘推理,提升实时性
六、前沿趋势:Serverless AI + FaaS 弹性触发
未来的AI基础设施将走向**“即用即起”**的Serverless范式:
- 自动横向扩容
- 零空闲资源浪费
- 与事件触发(如图像上传、IoT信号)深度结合
以AWS Lambda + S3为例的Serverless推理:
def lambda_handler(event, context):
img = decode_from_s3(event['bucket'], event['key'])
result = run_inference(img)
store_to_s3(result)
return {"status": "done"}
七、异构资源统一管理机制:GPU、TPU 与 NPU 的调度挑战
AI基础设施的复杂性不仅体现在网络与存储,还包括计算资源异构化:GPU用于高吞吐并行计算、TPU更适合深度学习矩阵运算,而在边缘场景中,NPU(神经网络处理器)与ASIC更为普遍。
为了实现资源的弹性调度与统一管理,我们必须引入以下机制:
1. 资源抽象层(Hardware Abstraction Layer, HAL)
通过抽象各类计算资源的API,构建统一的调度接口:
class DeviceManager:
def __init__(self):
self.devices = {"gpu": GPURuntime(), "npu": NPURuntime(), "cpu": CPURuntime()}
def infer(self, model, input_data, preferred_device="gpu"):
if preferred_device in self.devices:
return self.devices[preferred_device].run(model, input_data)
return self.devices["cpu"].run(model, input_data)
该机制能屏蔽底层硬件差异,供上层AI服务透明调用。
2. 运行时调度器(Runtime Dispatcher)
调度器可基于负载与可用性动态分配设备:
def auto_dispatch(model, input_data):
device_load = get_device_utilization()
device = min(device_load, key=device_load.get)
return DeviceManager().infer(model, input_data, preferred_device=device)
结合Prometheus、NVIDIA-SMI 或 Ascend Monitor,可实现设备利用率感知的调度策略。
3. 节点能力感知注册(K8s device plugin)
Kubernetes可通过自定义device plugin识别并调度GPU/TPU/NPU:
apiVersion: v1
kind: Pod
spec:
containers:
- name: ai-infer
image: ai-service:latest
resources:
limits:
nvidia.com/gpu: 1
如使用华为昇腾NPU、Google Edge TPU 需编写相应插件注册调度资源池。
八、弹性扩展与模型版本管理体系
AI应用常处于持续迭代与版本更新状态,弹性设计还需应对模型版本管理与服务水平自动扩缩容两大挑战。
1. 模型版本控制与热更新机制
采用 MLflow、TorchServe、TensorFlow Serving 可实现模型版本管理与自动加载:
# 启动 TensorFlow Serving 模型管理
tensorflow_model_server \
--rest_api_port=8501 \
--model_name=my_model \
--model_base_path="/models/my_model/"
热更新策略如下:
- 模型推理过程中监控
/models/my_model/路径 - 检测到新版本自动重新加载
- 支持 A/B 测试切换或 Canary 发布策略
2. 自动弹性扩缩容:结合HPA + 推理请求监控
借助Kubernetes HPA (Horizontal Pod Autoscaler) 实现AI服务的动态扩容:
kubectl autoscale deployment ai-infer-deployment \
--cpu-percent=60 --min=1 --max=10
也可以使用自定义指标扩缩容,例如QPS、GPU使用率等:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
spec:
metrics:
- type: Pods
pods:
metric:
name: gpu_utilization
target:
type: AverageValue
averageValue: 800m
九、安全性与可靠性保障机制
在分布式AI基础设施中,安全性与可靠性是不可妥协的核心目标,尤其涉及:
- 模型防篡改
- 数据传输安全
- 服务端点认证
- 服务恢复与重放机制
1. 模型加密与签名机制
可对模型文件进行加密与完整性校验,防止边缘端部署时被替换:
import hashlib
def verify_model(filepath, expected_hash):
with open(filepath, "rb") as f:
content = f.read()
file_hash = hashlib.sha256(content).hexdigest()
return file_hash == expected_hash
还可使用TPM(受信平台模块)或SGX等可信执行环境运行关键模型。
2. 服务链路追踪与恢复机制
结合OpenTelemetry或Jaeger实现AI服务全链路追踪:
- 请求链路监控(trace_id)
- 错误点定位
- 重放与故障恢复
# 使用OpenTelemetry追踪推理请求
from opentelemetry import trace
tracer = trace.get_tracer(__name__)
with tracer.start_as_current_span("model_inference"):
result = run_model(input_data)
十、AI弹性基础设施的未来趋势展望
在未来的AI基础设施演进中,我们将看到如下趋势:
1. 微服务与模型即服务(Model as a Service)
模型将被封装为微服务,通过REST/gRPC/WebSocket暴露推理接口:
- 快速部署
- 可观测性增强
- 支持跨团队协作与多版本治理
2. AIOps驱动的智能运维
通过机器学习分析系统日志、指标与事件,实现:
- 异常预测
- 根因定位(Root Cause Analysis)
- 资源自适应调整
# 简化版示例:异常检测模型预测CPU过载
anomaly = anomaly_detector.predict(cpu_metrics)
if anomaly:
trigger_scale_out()
3. 多云协同与边缘融合平台
出现如KubeEdge、OpenYurt 等边缘协同框架,未来将:
- 云端统一管理边缘模型
- 自动分发/推理同步
- 保障边云一致性与安全性


- 点赞
- 收藏
- 关注作者
评论(0)