Test‑Time Scaling推理阶段动态资源优化策略

Test‑Time Scaling推理阶段动态资源优化策略
引言
随着深度学习技术的飞速发展,人工智能(AI)模型的推理阶段已经成为实际应用中最关键的部分之一。在推理阶段,模型的计算量通常非常庞大,尤其是在图像识别、语音处理等任务中,模型必须处理大量的输入数据,并在短时间内给出预测结果。传统的推理方式往往是静态的,即无论输入数据的复杂度如何,计算资源都会保持不变,这可能导致资源的浪费或延迟的增加。
为了优化这一过程,Test-Time Scaling(测试时扩展)策略应运而生。这种策略通过动态调整推理时所需的计算资源,使得推理过程能够更加高效并适应不同的输入需求。本文将深入探讨Test‑Time Scaling的原理、应用场景以及实现方法,并通过代码示例来展示如何将这一策略应用到深度学习模型中。
Test-Time Scaling的背景与意义
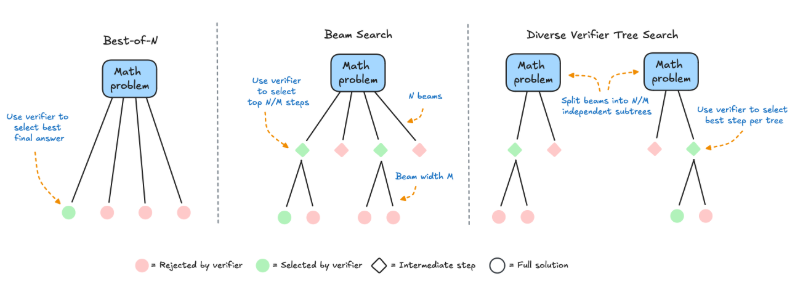
动态调整计算资源
Test-Time Scaling的核心思想是在推理阶段根据输入的具体需求动态调整计算资源。相比静态分配资源的传统方法,动态资源分配能够有效减少计算浪费,提高推理效率。通过根据输入数据的复杂度自动调整计算资源的分配,Test-Time Scaling不仅可以优化推理速度,还能有效降低能源消耗,尤其在大规模部署时尤为重要。
适应性与可伸缩性
Test-Time Scaling使得AI系统具备了更强的适应性。无论是简单的图像还是复杂的场景,模型都能根据任务的难度动态选择合适的计算方式。而在多任务学习的场景下,Test-Time Scaling可以帮助模型根据任务的优先级进行资源的合理分配,提升整体系统的性能。
解决推理阶段的瓶颈
在大部分AI系统中,训练阶段的复杂度通常远高于推理阶段。然而,推理阶段的瓶颈往往出现在计算资源的分配上。Test-Time Scaling正是通过动态调整计算资源,帮助解决推理阶段可能出现的瓶颈问题,使得AI系统能够在推理时达到最优性能。
Test-Time Scaling的实现方法
1. 基于输入复杂度的资源分配
实现Test-Time Scaling的一个重要方法是基于输入数据的复杂度来动态调整计算资源。例如,在图像识别任务中,如果输入的图像较为简单,模型可以选择较少的计算资源进行推理;而当遇到复杂的图像时,模型则会调动更多的计算资源,以保证准确性。
代码示例:
import torch
import torch.nn as nn
# 假设模型为一个简单的卷积神经网络(CNN)
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3)
self.fc1 = nn.Linear(32*24*24, 10)
def forward(self, x):
x = self.conv1(x)
x = torch.flatten(x, start_dim=1)
x = self.fc1(x)
return x
# 动态选择计算资源
def dynamic_resource_allocation(input_data, model):
# 根据输入数据的大小来调整模型的计算资源
if input_data.size(2) < 32: # 假设较小的输入图像复杂度较低
# 使用较少的计算资源,简单的推理
model.fc1 = nn.Linear(32*12*12, 10) # 简化模型
else:
# 使用更多计算资源,较为复杂的推理
model.fc1 = nn.Linear(32*24*24, 10) # 完整模型
return model(input_data)
# 模型初始化
model = SimpleCNN()
# 假设我们有一个输入数据
input_data = torch.randn(1, 1, 28, 28) # 一个较小的图像
# 动态资源分配与推理
output = dynamic_resource_allocation(input_data, model)
print(output)
2. 自适应推理框架
另一种方法是使用自适应推理框架,这种框架能够在推理过程中根据模型的计算需求自动选择合适的硬件资源。例如,在GPU或TPU上进行推理时,可以根据每个任务的计算量自动调节内存和计算核心的分配。
代码示例:
import torch
from torch.utils.data import DataLoader
# 假设模型和数据集已经定义好
model = SimpleCNN().cuda()
data_loader = DataLoader(dataset, batch_size=32, shuffle=True)
# 自动选择计算资源
def adaptive_inference(model, data_loader):
for data in data_loader:
data = data.cuda()
# 假设通过某些机制动态选择设备
if torch.cuda.memory_allocated() > 1e9: # 当内存分配过多时,选择降低资源消耗
model = model.half() # 降低精度以节省内存
output = model(data)
print(output)
adaptive_inference(model, data_loader)
3. 基于模型剪枝的动态推理
Test-Time Scaling的另一种实现方法是结合模型剪枝(Pruning)技术,在推理阶段动态剪枝掉部分不必要的神经网络参数,从而减少计算量和内存消耗。结合剪枝与动态资源分配,可以在推理过程中更加灵活地调整计算资源的使用。
代码示例:
import torch
import torch.nn.utils.prune as prune
# 假设有一个简单的模型
model = SimpleCNN()
# 剪枝某一层的权重
def prune_model(model):
prune.random_unstructured(model.conv1, name="weight", amount=0.5) # 剪枝50%卷积层权重
# 动态调整资源
def dynamic_pruning_inference(model, input_data):
prune_model(model)
return model(input_data)
# 测试剪枝后的推理
input_data = torch.randn(1, 1, 28, 28)
output = dynamic_pruning_inference(model, input_data)
print(output)
Test-Time Scaling的挑战与未来发展
持续性优化
虽然Test-Time Scaling在推理阶段的计算资源优化中起到了重要作用,但如何实现持续性优化仍然是一个挑战。不同硬件平台的差异、复杂的任务依赖性以及不断变化的数据特点都可能影响Test-Time Scaling的效果。未来,可能需要更智能的算法和系统来实现持续的性能提升。
深度学习硬件加速的协同优化
随着硬件加速器(如GPU、TPU、FPGA等)的发展,如何与Test-Time Scaling结合以实现最佳性能也成为了一个重要的研究方向。将硬件加速与动态资源调整相结合,能够进一步提高推理阶段的计算效率。
强化学习在资源分配中的应用
未来,强化学习(Reinforcement Learning, RL)可能会被应用于Test-Time Scaling策略中,通过学习在不同输入情况下如何动态调整资源分配,以实现最优的推理性能。
结论
Test-Time Scaling作为一种推理阶段动态资源优化策略,能够有效提高推理效率并节省计算资源。通过根据输入数据的复杂度调整计算资源、使用自适应推理框架以及结合模型剪枝等技术,Test-Time Scaling为深度学习模型的实际应用提供了更高效、灵活的推理解决方案。随着硬件加速技术和强化学习的进步,Test-Time Scaling将为AI系统的优化和实际部署带来更多可能性。

- 点赞
- 收藏
- 关注作者
评论(0)