openEuler 内存调优之 eBPF 内存监控分析【华为根技术】

写在前面
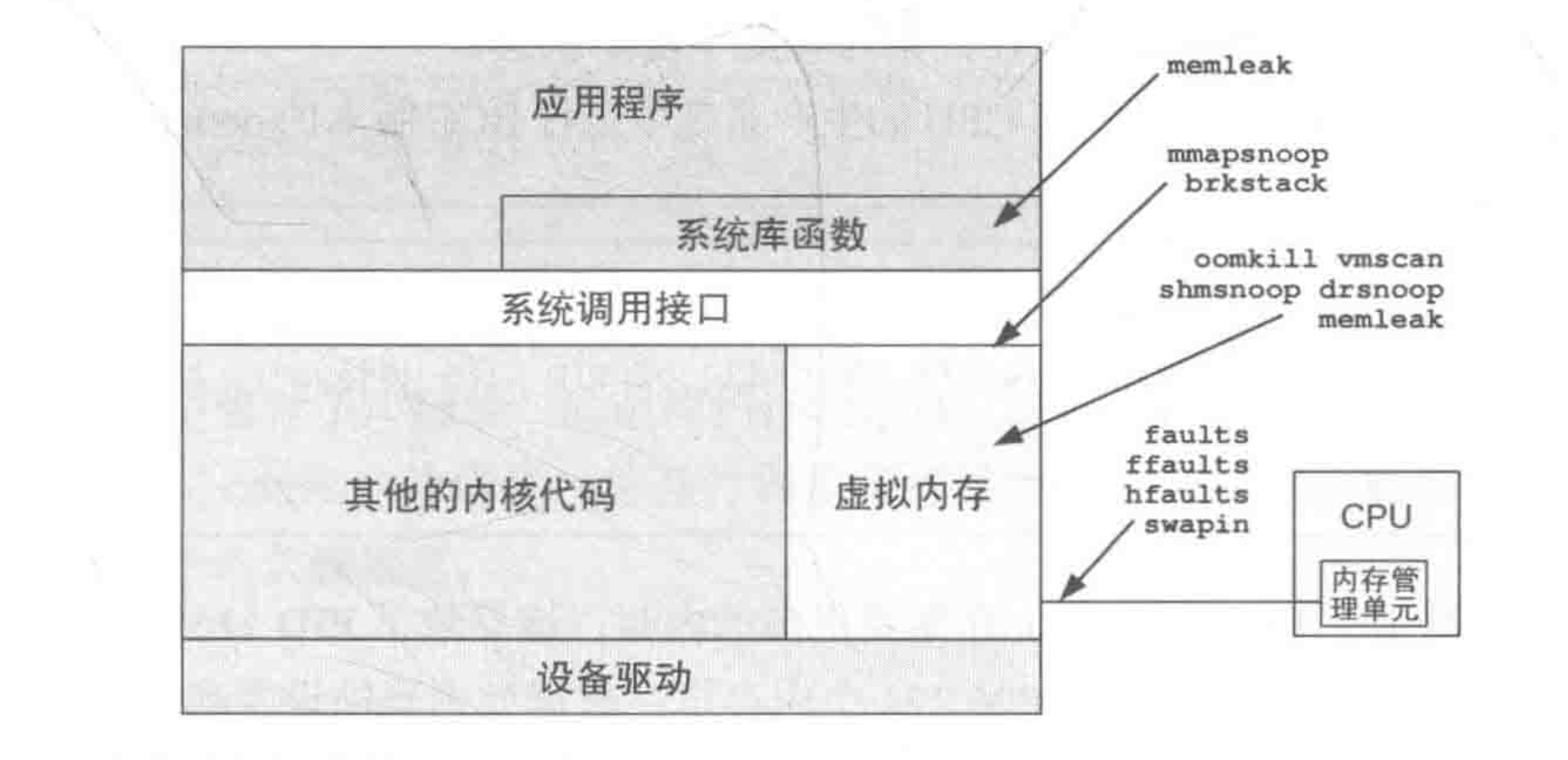
- 博文内容整涉及下面一些内存问题的 BPF 观测 Demo:
- 为什么
进程的物理内存占用(RSS)不停增长? - 哪些代码路径会导致
缺页错误的发生,缺页错误来自哪些文件? 大页的缺页错误来着那些进程,频率统计- 哪些
进程阻塞于页换入操作,那些存在直接回收延迟? - 全系统范围内创建了哪些
内存映射,哪些应用程序代码路径正在申请内存分配? 内存溢出(OOM Kil)事件发生时系统状态如何?- 是否有分配一段时间后还是
没有释放的内存,定位可能内存泄露的进程? - 涉及到的工具整理自
《BPF Performance Tools》书中内存部分 - 理解不足小伙伴帮忙指正 :),生活加油
我看远山,远山悲悯
持续分享技术干货,感兴趣小伙伴可以关注下 ^_^
实验环境
部分实验 openEuler 22.03
[root@developer ~]# hostnamectl
Static hostname: developer
Icon name: computer-vm
Chassis: vm
Machine ID: 7ad73f2b5f7046a2a389ca780f472467
Boot ID: cef15819a5c34efa92443b6eff608cc9
Virtualization: kvm
Operating System: openEuler 22.03 (LTS-SP4)
Kernel: Linux 5.10.0-250.0.0.154.oe2203sp4.aarch64
Architecture: arm64
Hardware Vendor: OpenStack Foundation
Hardware Model: OpenStack Nova
[root@developer ~]#
部分实验 Rocky Linux 9.4
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$hostnamectl
Static hostname: liruilongs.github.io
Icon name: computer-vm
Chassis: vm 🖴
Machine ID: 7deac2815b304f9795f9e0a8b0ae7765
Boot ID: 67932b8e733942d19069be54b76278bd
Virtualization: vmware
Operating System: Rocky Linux 9.4 (Blue Onyx)
CPE OS Name: cpe:/o:rocky:rocky:9::baseos
Kernel: Linux 5.14.0-427.20.1.el9_4.x86_64
Architecture: x86-64
Hardware Vendor: VMware, Inc.
Hardware Model: VMware Virtual Platform
Firmware Version: 6.00
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$
BPF 跟踪工具可以给
各种内存行为提供更多的信息,可以用BPF 跟踪软件事件及系统调用和缺页错误相关的跟踪点来分析;还可以使用kprobes跟踪内核中内存分配的函数;或使用uprobes来跟踪库函数、应用程序运行时,以及应用程序自带的内存分配器;或使用USDT 探针来跟踪libc 内存分配器事件;以及使用PMC对内存访问进行溢出采样。
这里我们简单看看下上面提到的几个BPF关键名词:
动态跟踪点: kprobes 和 uprobes,类似于内核态和用户态的方法埋点,比较灵活,可以任意监控
kprobes: 通过在内核函数入口或指定指令位置插入断点指令(如 x86 的 int3),动态注入回调函数。当内核执行到探测点时,触发回调函数并记录上下文信息(如寄存器状态、参数等)。例如,可监控kmalloc、kfree等内核内存管理函数的行为。uprobes: 通过修改用户程序的 ELF 文件指令,在库函数(如 malloc)或应用程序的自定义内存分配器处插入探测点。其原理类似于 kprobes,但作用于用户态进程。
静态跟踪点:USDT 探针,用户态会将稳定的事件名字编码到软件代码中,监控点都是编译的时候写死的
USDT:探针在程序编译阶段通过宏定义(如 dtrace_probe、stap_probe)插入代码中,形成固定的观测点位。
PMC(Performance Monitoring Counters): 通过 CPU 硬件计数器统计内存访问事件(如缓存未命中、TLB 失效等),支持溢出采样模式。当事件计数达到阈值时触发中断,记录调用栈信息
BPF 可以跟踪各种内存事件,包括内存分配、内存映射、缺页错误、换页操作等:在跟踪这些事件的大部分情况下都可以抓取对应的调用栈信息,以便理解事件发生的原因。
常见的内存活动 事件源
| 事件类型 | 事件源 |
|---|---|
| 用户态内存分配 | 使用 uprobes 跟踪内存分配器函数,使用 USDT probes 跟踪 libc |
| 内核态内存分配 | 使用 kprobes 跟踪内存分配器函数,以及 kmem 跟踪点 |
| 堆内存扩展 | brk 系统调用跟踪点 |
| 共享内存函数 | 系统调用跟踪点 |
| 缺页错误 | kprobes、软件事件,以及 exception 跟踪点 |
| 页迁移 | migration 跟踪点 |
| 页压缩 | compaction 跟踪点 |
| VM 扫描器 | vmscan 跟踪点 |
| 内存访问周期 | PMC |
需要说明: 使用 BPF 的方式,每秒调用事件几百万次仍会
累积成不小的开销。根据所跟踪事件的发生频率不同,以及对应的 BPF 程序,运行时仍有可能造成10%左右的性能损耗。在极端情况下甚至可能将软件运行速度降至原先的1/10。缺页错误,页换出,brk()调用, mmap() 调用等,跟踪这些事件基本开销基本可以忽略不计。
内存溢出(OOM Kil)事件发生时系统状态如何?
oomkill(8) 是一个 BCC 和 bpftrace 工具,用来跟踪内核的 OOM Killer 事件的信息,以及打印出平均负载等详细信息。
OOM Killer 事件: OOM Killer(Out-Of-Memory Killer)是内核在系统内存严重不足时触发的紧急机制,通过终止进程释放内存以维持系统稳定
通过BPF 和 bpftrace oomkill 工具,我们可以在触发 OOM killer 事件之后,观察到系统平均负载等一些其他的信息
平均负载信息可以在 OOM 发生时提供整个系统状态的一些 上下文信息,展示出系统整体是正在变忙还是处于稳定状态,以及那个进程触发了 OOM Killer 和,被 OOM Killer 杀掉的进程是那个等数据。
我们做一个简单测试,这里需要把交换分区禁用掉,要不换页进程(kswapd)疯狂的输出,不太容易触发 OOM Killer
[root@liruilongs.github.io ~]# swapoff -a # 临时禁用
stress-ng 对 Linux 系统内存施加高压负载
[root@liruilongs.github.io ~]# stress-ng --vm 4 --vm-bytes 9.5G --timeout 60s
stress-ng: info: [37336] setting to a 60 second run per stressor
stress-ng: info: [37336] dispatching hogs: 4 vm
^[c^Cstress-ng: info: [37336] successful run completed in 40.87s
[root@liruilongs.github.io ~]#
通过 free 命令观察内存使用情况,中间的那一次输出可以直观的看到内存使用情况
[root@liruilongs.github.io ~]# free -h -s 10 -c 3
total used free shared buff/cache available
Mem: 6.5Gi 815Mi 5.6Gi 37Mi 293Mi 5.7Gi
Swap: 0B 0B 0B
total used free shared buff/cache available
Mem: 6.5Gi 6.4Gi 183Mi 39Mi 113Mi 139Mi
Swap: 0B 0B 0B
total used free shared buff/cache available
Mem: 6.5Gi 4.5Gi 2.0Gi 39Mi 84Mi 2.0Gi
Swap: 0B 0B 0B
[root@liruilongs.github.io ~]#
通过 oomkill 工具观察 OOM Killer 情况
可以看到触发的进程主要是 stress-ng(内存压力测试工具)持续申请内存,导致系统物理内存耗尽。部分系统进程(如 oeaware、Xvnc)也触发 OOM,说明内存竞争激烈,系统整体处于高压状态。通过负载指标:loadavg 值较高(如 4.59),表明 CPU 资源负载在升高 。
[root@liruilongs.github.io ~]# /usr/share/bcc/tools/oomkill
Tracing OOM kills... Ctrl-C to stop.
15:41:14 Triggered by PID 1039 ("oeaware"), OOM kill of PID 39693 ("stress-ng"), 1704429 pages, loadavg: 4.34 2.87 1.77 6/396 39695
15:41:15 Triggered by PID 39692 ("stress-ng"), OOM kill of PID 39692 ("stress-ng"), 1704429 pages, loadavg: 4.34 2.87 1.77 5/396 39696
15:41:16 Triggered by PID 39696 ("stress-ng"), OOM kill of PID 39694 ("stress-ng"), 1704429 pages, loadavg: 4.31 2.89 1.78 5/396 39697
15:41:17 Triggered by PID 39698 ("stress-ng"), OOM kill of PID 39695 ("stress-ng"), 1704429 pages, loadavg: 4.31 2.89 1.78 5/396 39699
15:41:19 Triggered by PID 1039 ("oeaware"), OOM kill of PID 39696 ("stress-ng"), 1704429 pages, loadavg: 4.31 2.89 1.78 5/396 39700
15:41:20 Triggered by PID 2121 ("ibus-ui-gtk3"), OOM kill of PID 39697 ("stress-ng"), 1704429 pages, loadavg: 4.31 2.89 1.78 6/396 39701
15:41:22 Triggered by PID 39699 ("stress-ng"), OOM kill of PID 39698 ("stress-ng"), 1704429 pages, loadavg: 4.29 2.91 1.80 5/396 39701
15:41:23 Triggered by PID 39700 ("stress-ng"), OOM kill of PID 39700 ("stress-ng"), 1704429 pages, loadavg: 4.29 2.91 1.80 6/396 39702
15:41:24 Triggered by PID 39701 ("stress-ng"), OOM kill of PID 39699 ("stress-ng"), 1704429 pages, loadavg: 4.29 2.91 1.80 5/396 39704
15:41:25 Triggered by PID 39702 ("stress-ng"), OOM kill of PID 39701 ("stress-ng"), 1704429 pages, loadavg: 4.29 2.91 1.80 5/396 39704
15:41:26 Triggered by PID 39703 ("stress-ng"), OOM kill of PID 39702 ("stress-ng"), 1704429 pages, loadavg: 4.59 3.00 1.83 5/396 39705
15:41:27 Triggered by PID 39705 ("stress-ng"), OOM kill of PID 39703 ("stress-ng"), 1704429 pages, loadavg: 4.59 3.00 1.83 5/396 39706
15:41:29 Triggered by PID 1304 ("Xvnc"), OOM kill of PID 39704 ("stress-ng"), 1704429 pages, loadavg: 4.59 3.00 1.83 6/396 39708
15:41:30 Triggered by PID 1492 ("lightdm-gtk-gre"), OOM kill of PID 39705 ("stress-ng"), 1704429 pages, loadavg: 4.59 3.00 1.83 5/395 39708
15:41:31 Triggered by PID 39709 ("stress-ng"), OOM kill of PID 39706 ("stress-ng"), 1704429 pages, loadavg: 4.94 3.10 1.87 8/395 39710
看下一下数据信息,已第一条日志为例
15:41:14 Triggered by PID 1039 ("oeaware"), OOM kill of PID 39693 ("stress-ng"), 1704429 pages, loadavg: 4.34 2.87 1.77 6/396 39695。
| 字段 | 含义 |
|---|---|
Triggered by PID |
触发 OOM 的进程 PID(如内存申请者) |
OOM kill of PID |
被 OOM Killer 终止的进程 PID |
1704429 pages |
被终止进程占用的物理内存页数(1页=4KB,换算为 6.8GB) |
loadavg |
系统负载(1分钟/5分钟/15分钟平均负载) |
6/396 |
当前可运行进程数/总进程数 |
39695 |
最后被创建的进程 PID |
下面我们看看上面的功能是如何实现的
bpftrace 对应的工具
[root@liruilongs.github.io ~]# cat /usr/share/bpftrace/tools/oomkill.bt
#!/usr/bin/bpftrace
/*
* oomkill Trace OOM killer.
* For Linux, uses bpftrace and eBPF.
*
* This traces the kernel out-of-memory killer, and prints basic details,
* including the system load averages. This can provide more context on the
* system state at the time of OOM: was it getting busier or steady, based
* on the load averages? This tool may also be useful to customize for
* investigations; for example, by adding other task_struct details at the
* time of the OOM, or other commands in the system() call.
*
* This currently works by using kernel dynamic tracing of oom_kill_process().
*
* USAGE: oomkill.bt
*
* Copyright 2018 Netflix, Inc.
* Licensed under the Apache License, Version 2.0 (the "License")
*
* 07-Sep-2018 Brendan Gregg Created this.
*/
#include <linux/oom.h>
BEGIN
{
printf("Tracing oom_kill_process()... Hit Ctrl-C to end.\n");
}
kprobe:oom_kill_process
{
$oc = (struct oom_control *)arg0;
time("%H:%M:%S ");
printf("Triggered by PID %d (\"%s\"), ", pid, comm);
printf("OOM kill of PID %d (\"%s\"), %d pages, loadavg: ",
$oc->chosen->pid, $oc->chosen->comm, $oc->totalpages);
cat("/proc/loadavg");
}
[root@liruilongs.github.io ~]#
通过动态插桩内核函数 oom_kill_process(),捕获 OOM Killer 触发事件
是否有分配一段时间后还是没有释放的内存?
有分配一段时间后还是没有释放的内存,这意味着可能是泄漏的内存。
memleak(8)'是一个 BCC 工具,可以用来跟踪内存分配和释放事件对应的调用栈信息。随着时间的推移,这个工具可以显示长期不被释放的内存。
源码地址:
https://github.com/iovisor/bcc/blob/master/tools/memleak.py
帮助文档:
https://github.com/iovisor/bcc/blob/master/tools/memleak_example.txt
看一个 Demo
┌──[root@liruilongs.github.io]-[~]
└─$vim memory_leak_demo.c
┌──[root@liruilongs.github.io]-[~]
└─$vim memory_leak_demo.c
┌──[root@liruilongs.github.io]-[~]
└─$gcc -g memory_leak_demo.c -o leak_demo
┌──[root@liruilongs.github.io]-[~]
└─$cat memory_leak_demo.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <time.h>
// 内存分配计数器
static int allocation_count = 0;
// 模拟内存分配函数
void* allocate_memory(size_t size) {
void *ptr = malloc(size);
if (ptr) {
allocation_count++;
// 获取当前时间
time_t now = time(NULL);
struct tm *tm_info = localtime(&now);
char time_buf[20];
strftime(time_buf, 20, "%Y-%m-%d %H:%M:%S", tm_info);
// 打印分配日志
printf("[%s] 分配 #%d: %zu 字节 at 地址 %p\n",
time_buf, allocation_count, size, ptr);
} else {
perror("内存分配失败");
}
return ptr;
}
// 模拟内存泄漏的函数
void memory_leak_demo() {
int *data_buffer = NULL;
for (int i = 0; i < 1000; i++) {
// 每次分配1MB内存
data_buffer = (int*)allocate_memory(1024 * 1024);
if (data_buffer) {
// 简单使用内存(实际业务逻辑)
data_buffer[0] = i;
printf("写入值: %d\n", data_buffer[0]);
}
sleep(1); // 暂停1秒观察效果
/* 关键:这里没有释放内存!
下次循环时指针将被覆盖,
导致之前分配的内存无法访问 */
}
// 最后分配的内存也没有释放!
}
int main() {
printf("===== 内存泄漏演示开始 =====\n");
memory_leak_demo();
printf("===== 演示结束(已泄漏 %d 块内存)=====\n", allocation_count);
// 程序退出前不释放任何内存
return 0;
}
使用 memleak 观测内存问题,下面的输出显示
┌──[root@liruilongs.github.io]-[/usr/share/bcc/tools]
└─$./memleak -p $(pgrep leak_demo) --top 3 -s 3 -a 10 -o 20000
Attaching to pid 16369, Ctrl+C to quit.
[10:43:05] Top 3 stacks with outstanding allocations:
addr = 7fb86c2b7010 size = 15
addr = 7fb86ada2000 size = 1048576
addr = 7fb86b3a8000 size = 1048576
addr = 7fb86b7ac000 size = 1048576
addr = 7fb86b6ab000 size = 1048576
addr = 7fb86bbb0010 size = 1048576
addr = 7fb86b8ad000 size = 1052672
addr = 7fb86b1a6000 size = 1052672
addr = 7fb86b5aa000 size = 1052672
addr = 7fb86afa4000 size = 1052672
addr = 7fb86b9ae010 size = 1052672
addr = 7fb86baaf010 size = 1052672
addr = 7fb86b0a5000 size = 1052672
3153935 bytes in 4 allocations from stack
0x00000000004011ae allocate_memory+0x18 [leak_demo]
0x000000000040125f memory_leak_demo+0x23 [leak_demo]
0x00000000004012bd main+0x18 [leak_demo]
0x00007fb870c29590 __libc_start_call_main+0x80 [libc.so.6]
9457664 bytes in 9 allocations from stack
0x00007fb870c980dd sysmalloc+0x7ed [libc.so.6]
[10:43:18] Top 3 stacks with outstanding allocations:
addr = 7fb86c2b7010 size = 15
....................................
0x00007fb870c980dd sysmalloc+0x7ed [libc.so.6]
[10:43:28] Top 3 stacks with outstanding allocations:
addr = 7fb86c2b7010 size = 15
addr = 7fb86ada2000 size = 1048576
addr = 7fb86b3a8000 size = 1048576
addr = 7fb86b7ac000 size = 1048576
addr = 7fb86a095000 size = 1048576
addr = 7fb86a99e000 size = 1048576
addr = 7fb869f94000 size = 1048576
addr = 7fb86b6ab000 size = 1048576
addr = 7fb86bbb0010 size = 1048576
addr = 7fb86b8ad000 size = 1052672
addr = 7fb86a79c000 size = 1052672
addr = 7fb86a89d000 size = 1052672
addr = 7fb86b1a6000 size = 1052672
addr = 7fb86a398000 size = 1052672
addr = 7fb86b5aa000 size = 1052672
addr = 7fb86afa4000 size = 1052672
addr = 7fb869e93000 size = 1052672
addr = 7fb869c91000 size = 1052672
addr = 7fb86a196000 size = 1052672
addr = 7fb86b9ae010 size = 1052672
addr = 7fb86baaf010 size = 1052672
addr = 7fb86b0a5000 size = 1052672
addr = 7fb869a8f000 size = 1052672
addr = 7fb86a297000 size = 1052672
3153935 bytes in 4 allocations from stack
0x00000000004011ae allocate_memory+0x18 [leak_demo]
0x000000000040125f memory_leak_demo+0x23 [leak_demo]
0x00000000004012bd main+0x18 [leak_demo]
0x00007fb870c29590 __libc_start_call_main+0x80 [libc.so.6]
21024768 bytes in 20 allocations from stack
0x00007fb870c980dd sysmalloc+0x7ed [libc.so.6]
[10:43:38] Top 3 stacks with outstanding allocations:
addr = 7fb86c2b7010 size = 15
addr = 7fb86ada2000 size = 1048576
addr = 7fb86b3a8000 size = 1048576
addr = 7fb86b7ac000 size = 1048576
addr = 7fb86a095000 size = 1048576
addr = 7fb86a99e000 size = 1048576
addr = 7fb869f94000 size = 1048576
addr = 7fb86b6ab000 size = 1048576
addr = 7fb86bbb0010 size = 1048576
addr = 7fb86b8ad000 size = 1052672
addr = 7fb86a79c000 size = 1052672
addr = 7fb86a89d000 size = 1052672
addr = 7fb86958a000 size = 1052672
addr = 7fb86b1a6000 size = 1052672
addr = 7fb86a398000 size = 1052672
addr = 7fb86b5aa000 size = 1052672
addr = 7fb86afa4000 size = 1052672
addr = 7fb869e93000 size = 1052672
addr = 7fb869c91000 size = 1052672
addr = 7fb86a196000 size = 1052672
addr = 7fb869085000 size = 1052672
addr = 7fb86b9ae010 size = 1052672
addr = 7fb86baaf010 size = 1052672
addr = 7fb86b0a5000 size = 1052672
addr = 7fb869186000 size = 1052672
addr = 7fb869a8f000 size = 1052672
addr = 7fb86a297000 size = 1052672
3153935 bytes in 4 allocations from stack
0x00000000004011ae allocate_memory+0x18 [leak_demo]
0x000000000040125f memory_leak_demo+0x23 [leak_demo]
0x00000000004012bd main+0x18 [leak_demo]
0x00007fb870c29590 __libc_start_call_main+0x80 [libc.so.6]
24182784 bytes in 23 allocations from stack
0x00007fb870c980dd sysmalloc+0x7ed [libc.so.6]
^C┌──[root@liruilongs.github.io]-[/usr/share/bcc/tools]
└─$
持续增长的未释放内存块(如 1052672 字节 ≈1MB 的多次分配),通过 memleak 打印的 堆栈追踪指向 allocate_memory+0x18 和 memory_leak_demo+0x23 函数
3153935 bytes in 4 allocations from stack
0x00000000004011ae allocate_memory+0x18 [leak_demo] #void* allocate_memory(size_t size)
0x000000000040125f memory_leak_demo+0x23 [leak_demo] #void memory_leak_demo()
0x00000000004012bd main+0x18 [leak_demo]
0x00007fb870c29590 __libc_start_call_main+0x80 [libc.so.6]
正是上面 Demo 中的调用函数 memory_leak_demo()和分配函数 allocate_memory.
跟踪全系统的mmap系统调用
mmapsnoop
mmapsnoop(8)跟踪全系统的mmap(2)系统调用并打印出映射请求的详细信息,这对内存映射调试来说是很有用的。
对应的代码地址:
https://github.com/brendangregg/bpf-perf-tools-book/blob/master/originals/Ch07_Memory/mmapsnoop.py
下面源码
...................
// cache pid+FD -> file for later lookup
// TODO: use a task->files->fdt->fd[] lookup in the mmap tracepoint instead.
// fd_install 探针 缓存文件描述符(FD)与文件对象的映射关系(fd2file 哈希表)
int kprobe__fd_install(struct pt_regs *ctx, int fd, struct file *file)
{
u32 pid = bpf_get_current_pid_tgid() >> 32;
struct fdkey_t key = {.fd = fd, .pid = pid};
fd2file.update(&key, &file);
return 0;
}
// assume this and other events are in PID context
// __close_fd 探针 在文件描述符关闭时清理缓存
int kprobe____close_fd(struct pt_regs *ctx, struct files_struct *files, int fd)
{
u32 pid = bpf_get_current_pid_tgid() >> 32;
struct fdkey_t key = {.fd = fd, .pid = pid};
fd2file.delete(&key);
return 0;
}
// sys_enter_mmap 跟踪点
TRACEPOINT_PROBE(syscalls, sys_enter_mmap) {
struct task_struct *task;
struct file **fpp, *file;
u32 pid = bpf_get_current_pid_tgid() >> 32;
struct fdkey_t key = {.fd = args->fd, .pid = pid};
fpp = fd2file.lookup(&key);
if (fpp == 0)
return 0;
file = *fpp;
struct mmap_data_t data = {
.len = args->len,
.prot = args->prot,
.flags = args->flags,
.off = args->off,
.pid = pid
};
bpf_get_current_comm(&data.comm, sizeof(data.comm));
struct dentry *de = file->f_path.dentry;
struct qstr d_name = {};
bpf_probe_read(&d_name, sizeof(d_name), (void *)&de->d_name);
bpf_probe_read(&data.path, sizeof(data.path), d_name.name);
mmap_events.perf_submit(args, &data, sizeof(data));
return 0;
}
mmapsnoop 通过 eBPF 技术实现了对 Linux 系统内所有 mmap 系统调用的高效跟踪,揭示了:
- 进程如何通过内存映射访问文件或设备;
- 内存保护与共享机制的实时应用;
- 内核与用户态间的高效数据交互机制。
使用方式相对简单,直接通过命令行即可,我们看一个 Demo
下面的 Demo 创建一个匿名内存区域,一般这种场景,常用于分配大块的内存(如缓存、数据结构),进程间共享内存(需配合MAP_SHARED,但这里使用MAP_PRIVATE,内存不可共享),mmap仅分配虚拟地址空间,首次访问时才分配物理页(通过缺页中断)
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$cat anon2mmap.c
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#define GB ((long long) 1024 * 1024 * 1024)
int main() {
long long size = 8 * GB; // 尝试映射8GB
void *ptr = mmap(NULL, size, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (ptr == MAP_FAILED) {
perror("mmap failed");
return 1;
}
// 填充数据以触发实际内存分配
for (long long i = 0; i < size; i += 4096) {
((char *)ptr)[i] = 'A';
if (i % (GB) == 0) {
printf("Allocated %lld GB\n", i / GB);
}
}
printf("Successfully mapped %lld GB\n", size / GB);
munmap(ptr, size);
return 0;
}
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$
如果 mmap 没有映射文件或者设备,不使用大页,那么默认使用标准内存页对齐的方式创建虚拟内存
这里通过循环向标准内存页(4KB)写入数据,选择 4KB(4096 字节)作为步长,是为了确保每个内存页只被访问一次。触发实际的物理内存分配(Linux 采用延迟分配策略,mmap仅分配虚拟地址,首次访问时触发缺页异常才分配物理页)
编译之后运行上面的程序,可以看到在物理内存在分配第 4 GB 内存时 触发了 OOM killer
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$./anon2mmap
Allocated 0 GB
Allocated 1 GB
Allocated 2 GB
Allocated 3 GB
Allocated 4 GB
Killed
通过内核日志我们可以验证这一点, anon2mmap(PID=13365)尝试分配大量内存,导致系统内存耗尽。同时展示了,内存分配标志,OOM 评分等,以及触发 OOM killer 的函数调用栈
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$dmesg --follow -T
[Sat Jun 7 16:54:14 2025] anon2mmap invoked oom-killer: gfp_mask=0x140dca(GFP_HIGHUSER_MOVABLE|__GFP_COMP|__GFP_ZERO), order=0, oom_score_adj=0
[Sat Jun 7 16:54:14 2025] CPU: 1 PID: 13365 Comm: anon2mmap Kdump: loaded Tainted: G OE ------- --- 5.14.0-427.20.1.el9_4.x86_64 #1
[Sat Jun 7 16:54:14 2025] Hardware name: VMware, Inc. VMware Virtual Platform/440BX Desktop Reference Platform, BIOS 6.00 11/12/2020
[Sat Jun 7 16:54:14 2025] Call Trace:
[Sat Jun 7 16:54:14 2025] <TASK>
[Sat Jun 7 16:54:14 2025] dump_stack_lvl+0x34/0x48
[Sat Jun 7 16:54:14 2025] dump_header+0x4a/0x201
[Sat Jun 7 16:54:14 2025] oom_kill_process.cold+0xb/0x10
[Sat Jun 7 16:54:14 2025] out_of_memory+0xed/0x2e0
[Sat Jun 7 16:54:14 2025] __alloc_pages_slowpath.constprop.0+0x6e8/0x960
[Sat Jun 7 16:54:14 2025] __alloc_pages+0x21d/0x250
[Sat Jun 7 16:54:14 2025] __folio_alloc+0x17/0x50
[Sat Jun 7 16:54:14 2025] ? policy_node+0x4f/0x70
[Sat Jun 7 16:54:14 2025] vma_alloc_folio+0xa3/0x390
[Sat Jun 7 16:54:14 2025] do_anonymous_page+0x63/0x520
[Sat Jun 7 16:54:14 2025] __handle_mm_fault+0x32b/0x670
[Sat Jun 7 16:54:14 2025] ? nohz_balancer_kick+0x31/0x250
[Sat Jun 7 16:54:14 2025] handle_mm_fault+0xcd/0x290
[Sat Jun 7 16:54:14 2025] do_user_addr_fault+0x1b4/0x6a0
[Sat Jun 7 16:54:14 2025] ? sched_clock_cpu+0x9/0xc0
[Sat Jun 7 16:54:14 2025] exc_page_fault+0x62/0x150
[Sat Jun 7 16:54:14 2025] asm_exc_page_fault+0x22/0x30
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
[Sat Jun 7 16:54:14 2025] Tasks state (memory values in pages):
[Sat Jun 7 16:54:14 2025] [ pid ] uid tgid total_vm rss pgtables_bytes swapents oom_score_adj name
[Sat Jun 7 16:54:14 2025] [ 701] 0 701 12852 192 114688 288 -250 systemd-journal
[Sat Jun 7 16:54:14 2025] [ 715] 0 715 8274 32 98304 512 -1000 systemd-udevd
[Sat Jun 7 16:54:14 2025] [ 887] 0 887 4539 80 57344 672 -1000 auditd
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
[Sat Jun 7 16:54:14 2025] [ 13058] 48 13058 374632 38 483328 16256 0 /usr/sbin/httpd
[Sat Jun 7 16:54:14 2025] [ 13364] 0 13364 63300 2813 495616 12512 0 mmapsnoop
[Sat Jun 7 16:54:14 2025] [ 13365] 0 13365 2097810 808956 9932800 424160 0 anon2mmap
[Sat Jun 7 16:54:14 2025] oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0,global_oom,task_memcg=/user.slice/user-0.slice/session-9.scope,task=anon2mmap,pid=13365,uid=0
[Sat Jun 7 16:54:14 2025] Out of memory: Killed process 13365 (anon2mmap) total-vm:8391240kB, anon-rss:3235696kB, file-rss:128kB, shmem-rss:0kB, UID:0 pgtables:9700kB oom_score_adj:0
虚拟内存总量 total-vm: 8391240kB(约 8GB),对应代码中的 8GB 内存申请
long long size = 8 * GB; // 尝试映射8GB
void *ptr = mmap(NULL, size, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
匿名物理内存 anon-rss: 3235696kB(约 3.2GB),对应触发OOM killer 的内存消耗
这里我们用 mmapsnoop 去跟踪 mmap 的匿名内存的分配
┌──[root@liruilongs.github.io]-[/usr/share/bcc/tools]
└─$./mmapsnoop -T
TIME PID COMM PROT MAP OFFS(KB) SIZE(KB) FILE
00:42:09 13365 b'anon2mmap' R-- -P-- 0 28 b'ld.so.cache'
00:42:09 13365 b'anon2mmap' R-- -P-- 0 2083 b'libc.so.6'
00:42:09 13365 b'anon2mmap' R-E -PF- 160 1492 b'libc.so.6'
00:42:09 13365 b'anon2mmap' R-- -PF- 1652 352 b'libc.so.6'
00:42:09 13365 b'anon2mmap' RW- -PF- 2004 24 b'libc.so.6'
^C┌──[root@liruilongs.github.io]-[/usr/share/bcc/tools]
└─$
这里脚本有一些问题,可以看到只能跟踪到一些共享库的分配,却看不到实际的匿名内存的分配,这是什么原因?
mmap 映射的匿名内存直接使用的虚拟内存,没有映射文件,所以之前的脚本没有记录这部分, 可以看到代码在 fd2file中没有关联的数据时,直接返回 0,即匿名映射的内存会直接忽略
TRACEPOINT_PROBE(syscalls, sys_enter_mmap) {
......................
fpp = fd2file.lookup(&key);
if (fpp == 0)
return 0;
file = *fpp;
.....................
return 0;
}
这里我们需要修改一下原来的脚本,下面为修改之后的
TRACEPOINT_PROBE(syscalls, sys_enter_mmap) {
u32 pid = bpf_get_current_pid_tgid() >> 32;
struct fdkey_t key = {.fd = args->fd, .pid = pid};
const char *anon_name = "[anon]";
// 调试:打印fd值
bpf_trace_printk("DEBUG: mmap fd=%d, pid=%d ---", args->fd, pid);
// 处理匿名内存映射(fd为-1)
long fd = (long)args->fd;
if ( args->fd == 0xFFFFFFFF ) {
struct mmap_data_t data = {
.len = args->len,
.prot = args->prot,
.flags = args->flags,
.off = args->off,
.pid = pid
};
bpf_trace_printk("DEBUG: mmap len=%d, prot=%d ---", args->len, args->prot);
bpf_get_current_comm(&data.comm, sizeof(data.comm));
bpf_probe_read(&data.path, sizeof(data.path), (void *)anon_name);
mmap_events.perf_submit(args, &data, sizeof(data));
return 0;
}
// 处理文件映射
struct file **fpp = fd2file.lookup(&key);
if (fpp == 0)
return 0;
struct file *file = *fpp;
struct mmap_data_t data = {
.len = args->len,
.prot = args->prot,
.flags = args->flags,
.off = args->off,
.pid = pid
};
bpf_get_current_comm(&data.comm, sizeof(data.comm));
struct dentry *de = file->f_path.dentry;
struct qstr d_name = {};
bpf_probe_read(&d_name, sizeof(d_name), (void *)&de->d_name);
bpf_probe_read(&data.path, sizeof(data.path), d_name.name);
mmap_events.perf_submit(args, &data, sizeof(data));
return 0;
}
分配匿名内存的时候 args->fd 的值为 -1, 需要注意 这里的 if ( args->fd == 0xFFFFFFFF ) ,需要用 32 位的 -1 表示
bpf_trace_printk 用于调试,输出会写入 /sys/kernel/debug/tracing/trace_pipe
下面是修改之后的输出
┌──[root@liruilongs.github.io]-[/usr/share/bcc/tools]
└─$./ano_mmapsoonp
PID COMM PROT MAP OFFS(KB) SIZE(KB) FILE
49103 ano_mmapsoonp RW- S--- 0 260 [perf_event]
49104 anon2mmap RW- -P-A 0 8
49104 anon2mmap R-- -P-- 0 28 ld.so.cache
49104 anon2mmap R-- -P-- 0 2083 libc.so.6
49104 anon2mmap R-E -PF- 160 1492 libc.so.6
49104 anon2mmap R-- -PF- 1652 352 libc.so.6
49104 anon2mmap RW- -PF- 2004 24 libc.so.6
49104 anon2mmap RW- -PFA 0 51
49104 anon2mmap RW- -P-A 0 12
49104 anon2mmap RW- -P-A 0 8388608
可以看到最后一条日志,对应分配虚拟内存 8388608KB/1024/1024 = 8G
`49104 anon2mmap RW- -P-A 0 8388608`
下面为调试日志的输出
^C┌──[root@liruilongs.github.io]-[/usr/share/bcc/tools]
└─$ cat /sys/kernel/debug/tracing/trace_pipe
ano_mmapsoonp-49103 [000] ....2.1 591493.415773: bpf_trace_printk: DEBUG: mmap fd=-1, pid=49103 ---
ano_mmapsoonp-49103 [000] ....2.1 591493.415802: bpf_trace_printk: DEBUG: mmap len=4096, prot=7 ---
ano_mmapsoonp-49103 [000] ....2.1 591493.415963: bpf_trace_printk: DEBUG: mmap fd=12, pid=49103 ---
ano_mmapsoonp-49103 [000] ....2.1 591493.416216: bpf_trace_printk: DEBUG: mmap fd=13, pid=49103 ---
anon2mmap-49104 [001] ....2.1 591496.676898: bpf_trace_printk: DEBUG: mmap fd=-1, pid=49104 ---
anon2mmap-49104 [001] ....2.1 591496.676906: bpf_trace_printk: DEBUG: mmap len=8192, prot=3 ---
anon2mmap-49104 [001] ....2.1 591496.677042: bpf_trace_printk: DEBUG: mmap fd=3, pid=49104 ---
anon2mmap-49104 [001] ....2.1 591496.677532: bpf_trace_printk: DEBUG: mmap fd=3, pid=49104 ---
anon2mmap-49104 [001] ....2.1 591496.677677: bpf_trace_printk: DEBUG: mmap fd=3, pid=49104 ---
anon2mmap-49104 [001] ....2.1 591496.677715: bpf_trace_printk: DEBUG: mmap fd=3, pid=49104 ---
anon2mmap-49104 [001] ....2.1 591496.678286: bpf_trace_printk: DEBUG: mmap fd=3, pid=49104 ---
anon2mmap-49104 [001] ....2.1 591496.678361: bpf_trace_printk: DEBUG: mmap fd=-1, pid=49104 ---
anon2mmap-49104 [001] ....2.1 591496.678368: bpf_trace_printk: DEBUG: mmap len=53168, prot=3 ---
anon2mmap-49104 [001] ....2.1 591496.679738: bpf_trace_printk: DEBUG: mmap fd=-1, pid=49104 ---
anon2mmap-49104 [001] ....2.1 591496.679747: bpf_trace_printk: DEBUG: mmap len=12288, prot=3 ---
anon2mmap-49104 [001] ....2.1 591496.680823: bpf_trace_printk: DEBUG: mmap fd=-1, pid=49104 ---
anon2mmap-49104 [001] ....2.1 591496.680849: bpf_trace_printk: DEBUG: mmap len=0, prot=3 ---
systemd-journal-701 [000] ....2.1 591502.486094: bpf_trace_printk: DEBUG: mmap fd=22, pid=701 ---
in:imjournal-1173 [001] ....2.1 591502.744724: bpf_trace_printk: DEBUG: mmap fd=8, pid=1144 ---
^C
┌──[root@liruilongs.github.io]-[/usr/share/bcc/tools]
└─$
mmapfiles(8)
mmapfles(8) 是一个 bpftrace 工具,同样用于跟踪 mmap(2) 调用,主要统计映射入内存地址范围的文件频率信息, 可以通过这个命令直观的看到频繁分配的进程数据
对应的代码地址:
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$cat mmapfiles.bt
#!/usr/bin/bpftrace
/*
* mmapfiles - Count mmap(2) files.
*
* See BPF Performance Tools, Chapter 8, for an explanation of this tool.
*
* Copyright (c) 2019 Brendan Gregg.
* Licensed under the Apache License, Version 2.0 (the "License").
* This was originally created for the BPF Performance Tools book
* published by Addison Wesley. ISBN-13: 9780136554820
* When copying or porting, include this comment.
*
* 26-Jan-2019 Brendan Gregg Created this.
*/
#include <linux/mm.h>
kprobe:do_mmap
{
$file = (struct file *)arg0;
$name = $file->f_path.dentry;
$dir1 = $name->d_parent;
$dir2 = $dir1->d_parent;
@[str($dir2->d_name.name), str($dir1->d_name.name),
str($name->d_name.name)] = count();
}
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$
这里我们执行一些前面写的 Demo,看下输出
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$./mmapfiles.bt
Attaching 1 probe...
^C
@[locale, C.utf8, LC_PAPER]: 1
@[/, /, my_shared_memory]: 1
。。。。。。。。。。。
@[root, bpfdemo, testfile.txt]: 1
。。。。。。。。。。。。。。。。。。。。
@[locale, C.utf8, LC_ADDRESS]: 1
@[anon_hugepage, anon_hugepage, anon_hugepage]: 2
@[root, bpfdemo, file2mmap]: 4
@[root, bpfdemo, anonhag2mmap]: 4
@[usr, lib64, libpcre2-8.so.0.11.0]: 4
@[root, bpfdemo, shar2mmap]: 4
@[usr, lib64, libselinux.so.1]: 4
@[usr, lib64, libcap.so.2.48]: 4
@[usr, bin, ls]: 4
@[root, bpfdemo, hug2mmap]: 4
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$
前两个列为 当前程序的两个父目录信息,root, bpfdemo,我们的实验在 root 目录的 bpfdemo 目录下完成,第三列为映射的进程名字,最后一列为映射次数
fmapfaults(8)
fmapfault(8) 跟踪内存映射文件的缺页错误,按进程名和文件名来统计,内存映射了之后只有写入数据才会发生缺页错误,所以如果我们想知道那些进程在分配虚拟内存之后进行了读写操作,那么可以通过 fmapfaults 跟踪。
对应的代码地址:
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$vim fmapfault.bt
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$chmod +x fmapfault.bt
#!/usr/local/bin/bpftrace
/*
* fmapfault - Count file map faults.
*
* See BPF Performance Tools, Chapter 8, for an explanation of this tool.
*
* Copyright (c) 2019 Brendan Gregg.
* Licensed under the Apache License, Version 2.0 (the "License").
* This was originally created for the BPF Performance Tools book
* published by Addison Wesley. ISBN-13: 9780136554820
* When copying or porting, include this comment.
*
* 26-Jan-2019 Brendan Gregg Created this.
*/
#include <linux/mm.h>
kprobe:filemap_fault
{
$vf = (struct vm_fault *)arg0;
$file = $vf->vma->vm_file->f_path.dentry->d_name.name;
@[comm, str($file)] = count();
}
这里任然使用之前的 Demo 进行测试
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$./shar2mmap
Parent read: Hello from child process! PID=15816
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$./hug2mmap
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$./file2mmap
当前进程PID: 15818
Original file content:
ABCD.............................IJ
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$
需要注意,文件实际的读写操作频率可能高于缺页错误发生的频率。
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$./fmapfault.bt
Attaching 1 probe...
^C
@[file2mmap, libc.so.6]: 1
@[shar2mmap, shar2mmap]: 1
@[file2mmap, file2mmap]: 1
@[shar2mmap, libc.so.6]: 1
@[file2mmap, testfile.txt]: 1
@[hug2mmap, hug2mmap]: 1
@[hug2mmap, libc.so.6]: 1
@[hug2mmap, ld-linux-x86-64.so.2]: 4
@[file2mmap, ld-linux-x86-64.so.2]: 4
@[shar2mmap, ld-linux-x86-64.so.2]: 4
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$
跟踪用户态小内存 brk 分配调用栈
一般来说,应用程序的数据存放于堆内存中,堆内存通过brk(2)系统调用进行扩展,对于比较常见的 libc 分配器的 malloc 等函数,在内存分配,小内存块使用 brk 分配,一般在空闲列表耗尽时,会上移堆顶指针,扩展虚拟地址空间,对于大块内存,直接调用我们上篇博文讲的 mmap 方式,创建独立的内存段,一般按页对齐,直接映射进程虚拟地址空间。
通过跟踪 brk(2)调用,可以展示对应的用户态调用栈信息,已经调用次数统计。同时还有一个sbrk(2)变体调用。在Linux中,sbrk(2)是以库函数形式实现的,内部仍然使用 brk(2)系统调用。
跟踪 brk(2) 调用的方式有很多,可以通过静态跟踪 tracepoint 对 syscall:syscall_enter_brk 内核跟踪点来跟踪,用 BCC版本的trace(8)来获取每个事件的信息,也可以用stackcount(8)来获取频率统计信息,还可以用bpfrace版本的单行程序来获取,甚至可以用perf(1)命令获取。
这里先准备一个测试脚本,调用 malloc 函数多次分配内存,观察 sbrk(0) 的变化
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$cat ./malloc_free.c
// demo3_malloc_free.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
printf("PID = %d\n", getpid());
printf("Before malloc: brk = %p\n", sbrk(0));
// 分配大块内存(可能触发 brk 增长)
void *ptr1 = malloc (12 * 1024); // 12KB
printf("After malloc 12KB: brk = %p\n", sbrk(0));
// 再分配小块内存
void *ptr2 = malloc(120* 1024); // 120KB
printf("After malloc 120KB: brk = %p\n", sbrk(0));
// 再分配小块内存
void *ptr3 = malloc(4 * 1024); // 4KB
printf("After malloc 4KB: brk = %p\n", sbrk(0));
sleep(30);
return 0;
}
sbrk(0) 为当前堆顶指针,每次分配内存,堆顶指针都会增加,这里分配了 12KB,120KB,4KB,观察堆顶指针的变化。
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$vim malloc_free.c
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$gcc -g malloc_free.c -o malloc_free
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$./malloc_free
PID = 2916
Before malloc: brk = 0x1ae2000
After malloc 12KB: brk = 0x1ae2000
After malloc 120KB: brk = 0x1b03000
After malloc 4KB: brk = 0x1b03000
^C
可以看到上面的输出,只有在分配120KB的时候,堆顶指针发生了变化(0x1ae2000 -> 0x1b03000),说明进行了堆内存的扩展,brk(2)系统调用被调用了。其他位置虽然也有调用,但是并不是进行了堆扩展。
trace
trace 命令是一个 BCC 工具,可以对多个数据源进行跟踪。这里我们使用它来跟踪 内核态跟踪点 sys_enter_brk
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$./malloc_free
PID = 3098
Before malloc: brk = 0x15cf000
After malloc 12KB: brk = 0x15cf000
After malloc 120KB: brk = 0x15f0000
After malloc 4KB: brk = 0x15f0000
^C
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$/usr/share/bcc/tools/trace -U 't:syscalls:sys_enter_brk "brk(0x%lx)", args->brk'
PID TID COMM FUNC -
3098 3098 malloc_free sys_enter_brk brk(0x0)
brk+0xb [ld-linux-x86-64.so.2]
[unknown] [ld-linux-x86-64.so.2]
3098 3098 malloc_free sys_enter_brk brk(0x0)
brk+0xb [libc.so.6]
3098 3098 malloc_free sys_enter_brk brk(0x15cf000)
brk+0xb [libc.so.6]
3098 3098 malloc_free sys_enter_brk brk(0x15f0000)
brk+0xb [libc.so.6]
^C
我们来分析一下上面的输出
brk (0x15f0000) 调用:对应于程序中第二次 120KB 的内存分配,移动了 brk 指针来扩大堆空间。
剩下的 brk 调用,前面两次调用,可能是程序启动时的初始化调用。第三次调用可能是 libc 的内部管理
stackcount
我们通过 stackcount 来统计 brk 调用的次数,确认上面的输出
stackcount(8)也是一个综合工具,可以对导致某事件发生的函数调用栈进行计数。和trace(8)一样,事件源可以是内核态或用户态函数、内核跟踪点或者USDT探针。
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$./malloc_free
PID = 2918
Before malloc: brk = 0x1ca4000
After malloc 12KB: brk = 0x1ca4000
After malloc 120KB: brk = 0x1cc5000
After malloc 4KB: brk = 0x1cc5000
^C
┌──[root@liruilongs.github.io]-[/usr/share/bcc/tools]
└─$/usr/share/bcc/tools/stackcount -TPU t:syscalls:sys_enter_brk
Tracing 1 functions for "t:syscalls:sys_enter_brk"... Hit Ctrl-C to end.
^C
15:15:12
brk
[unknown]
b'malloc_free' [2918]
1
brk
b'malloc_free' [2918]
3
Detaching...
可以看到调用栈,总共有 4 次 brk 调用,其中 3 次直接来自应用程序,1 次通过未知库路径(可能是动态链接器)
brkstack
brkstack 是一个 bpftrace 工具,可以跟踪堆内存分配,包括堆内存的分配和释放。它使用 bpftrace 的 tracepoint 机制,跟踪内核中的 sys_enter_brk事件。
代码地址
https://github.com/brendangregg/bpf-perf-tools-book/blob/master/originals/Ch07_Memory/brkstack.bt
#!/usr/local/bin/bpftrace
/*
* brkstack - Count brk(2) syscalls with user stacks.
*
* See BPF Performance Tools, Chapter 7, for an explanation of this tool.
*
* Copyright (c) 2019 Brendan Gregg.
* Licensed under the Apache License, Version 2.0 (the "License").
* This was originally created for the BPF Performance Tools book
* published by Addison Wesley. ISBN-13: 9780136554820
* When copying or porting, include this comment.
*
* 26-Jan-2019 Brendan Gregg Created this.
*/
tracepoint:syscalls:sys_enter_brk
{
@[ustack, comm] = count();
}
代码比较简单,实际上和上面的工具类似,可以看作是上面两个工具的结合
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$./malloc_free
PID = 2978
Before malloc: brk = 0x14d7000
After malloc 12KB: brk = 0x14d7000
After malloc 120KB: brk = 0x14f8000
After malloc 4KB: brk = 0x14f8000
^C
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$./brkstack.bt
Attaching 1 probe...
^C
@[2978,
__brk+11
0x7f7fc5a42b68
, malloc_free]: 1
@[2978,
brk+11
, malloc_free]: 3
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$
进行了一次堆扩展,所以调用了一次,但是包含着最后三次的中,这里的 Demo 是分配的三次内存,会不会对应 三次 brk 调用? 可以修改上面的脚本验证这一点
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$cat malloc_free.c
// demo3_malloc_free.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
printf("PID = %d\n", getpid());
printf("Before malloc: brk = %p\n", sbrk(0));
// 分配大块内存(可能触发 brk 增长)
void *ptr1 = malloc (12 * 1024); // 12KB
printf("After malloc 12KB: brk = %p\n", sbrk(0));
// 再分配小块内存
void *ptr2 = malloc(120* 1024); // 120KB
printf("After malloc 120KB: brk = %p\n", sbrk(0));
// 再分配小块内存
void *ptr3 = malloc(4 * 1024); // 4KB
printf("After malloc 4KB: brk = %p\n", sbrk(0));
void *ptr4 = malloc(4 * 1024); // 4KB
printf("After malloc 4KB: brk = %p\n", sbrk(0));
void *ptr5 = malloc(120 * 1024); // 4KB
printf("After malloc 120KB: brk = %p\n", sbrk(0));
sleep(30);
return 0;
}
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$
运行之后发现,多次内存分配,但是堆还是只扩展了一次,而且 brk 的调用次数也没有发生改变,还是3 次,所以可以验证我们上面的猜测
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$./malloc_free
PID = 2335
Before malloc: brk = 0x1a46000
After malloc 12KB: brk = 0x1a46000
After malloc 120KB: brk = 0x1a67000
After malloc 4KB: brk = 0x1a67000
After malloc 4KB: brk = 0x1a67000
After malloc 120KB: brk = 0x1a67000
^C
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$./brkstack.bt
Attaching 1 probe...
^C
@[2335,
__brk+11
0x7f1a6dc89b68
, malloc_free]: 1
@[2335,
brk+11
, malloc_free]: 3
这里我们可以看到对于小内存的分配,如果发生的堆扩展,那么我们可以 brk 相关的工具来进行跟踪,如果是通过空闲列表直接获取,那么没有办法跟踪。
SystemV的共享内存的调用跟踪
SystemV 共享内存是 Linux 系统中一种高效的进程间通信(IPC)机制,允许多个进程直接访问同一块物理内存区域, 对共享内存的跟踪 主要使用 shmsnoop BCC 工具,可以跟踪 SystemV的共享内存系统调用:shmget(2)、shmat(2)、shmdt(2)以及 shmctl(2)。这个工具可以用来调试共享内存的用量信息。下面为在一台云主机上执行后的输出
[root@liruilongs.github.io tools]# ./shmsnoop
PID COMM SYS RET ARGs
1710 xfwm4 SHMDT 0 shmaddr: 0xffffb1467000
1710 xfwm4 SHMGET 27 key: 0x0, size: 524288, shmflg: 0x380 (IPC_CREAT|0600)
1710 xfwm4 SHMAT ffffb1467000 shmid: 0x27, shmaddr: 0x0, shmflg: 0x0
1710 xfwm4 SHMCTL 0 shmid: 0x27, cmd: 0, buf: 0x0
1304 Xvnc SHMDT 0 shmaddr: 0xffffaeb64000
1304 Xvnc SHMAT ffffaeb64000 shmid: 0x27, shmaddr: 0x0, shmflg: 0x0
1304 Xvnc SHMCTL 0 shmid: 0x27, cmd: 2, buf: 0xffffc64e9348
1710 xfwm4 SHMDT 0 shmaddr: 0xffffb1467000
1710 xfwm4 SHMGET 28 key: 0x0, size: 524288, shmflg: 0x380 (IPC_CREAT|0600)
1710 xfwm4 SHMAT ffffb1467000 shmid: 0x28, shmaddr: 0x0, shmflg: 0x0
1710 xfwm4 SHMCTL 0 shmid: 0x28, cmd: 0, buf: 0x0
1304 Xvnc SHMDT 0 shmaddr: 0xffffaeb64000
1304 Xvnc SHMAT ffffaeb64000 shmid: 0x28, shmaddr: 0x0, shmflg: 0x0
1304 Xvnc SHMCTL 0 shmid: 0x28, cmd: 2, buf: 0xffffc64e9348
这里我们看一个 Demo,创建共享内存,附加到进程虚拟地址空间
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$cat shm.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#define SHM_SIZE 1024 // 共享内存大小(字节)
#define SHM_KEY 0x1234 // 共享内存键值
int main() {
int shmid;
char *shmaddr;
// 创建共享内存段
shmid = shmget(SHM_KEY, SHM_SIZE, 0666 | IPC_CREAT);
if (shmid == -1) {
perror("shmget failed");
exit(EXIT_FAILURE);
}
printf("Shared memory created with ID: %d\n", shmid);
// 附加共享内存到进程地址空间
shmaddr = shmat(shmid, NULL, 0);
if (shmaddr == (char *)-1) {
perror("shmat failed");
exit(EXIT_FAILURE);
}
printf("Shared memory attached at address: %p\n", shmaddr);
// 向共享内存写入数据
strcpy(shmaddr, "Hello from shared memory!");
printf("Data written: %s\n", shmaddr);
// 分离共享内存
if (shmdt(shmaddr) == -1) {
perror("shmdt failed");
exit(EXIT_FAILURE);
}
printf("Shared memory detached\n");
// 删除共享内存段(通常由创建者执行)
if (shmctl(shmid, IPC_RMID, NULL) == -1) {
perror("shmctl(IPC_RMID) failed");
exit(EXIT_FAILURE);
}
printf("Shared memory deleted\n");
return 0;
}
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$
下面为运行程序的输出
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$./shm
Shared memory created with ID: 2
Shared memory attached at address: 0x7fc2a1a6d000
Data written: Hello from shared memory!
Shared memory detached
Shared memory deleted
shmsnoop 输出部分参数说明
key: 0x1234共享内存的键值(用于进程间识别)7f4477be4000(共享内存在进程中的虚拟地址)
SystemV 共享内存操作流程:
创建 / 获取共享内存(SHMGET):通过唯一键值创建或获取共享内存段,返回 ID附加到进程地址空间(SHMAT):将共享内存映射到进程虚拟地址,返回映射地址数据交互:进程通过映射地址读写共享内存(输出中未显示具体数据操作)分离共享内存(SHMDT):进程不再使用时断开映射控制操作(SHMCTL):管理共享内存属性(如删除、修改权限等)
┌──[root@liruilongs.github.io]-[/usr/share/bcc/tools]
└─$./shmsnoop
PID COMM SYS RET ARGs
3413 shm SHMGET 3 key: 0x1234, size: 1024, shmflg: 0x3b6 (IPC_CREAT|0666)
3413 shm SHMAT 7f4477be4000 shmid: 0x3, shmaddr: 0x0, shmflg: 0x0
3413 shm SHMDT 0 shmaddr: 0x7f4477be4000
3413 shm SHMCTL 0 shmid: 0x3, cmd: 0, buf: 0x0
^C┌──[root@liruilongs.github.io]-[/usr/share/bcc/tools]
└─$
为什么进程的物理内存占用(RSS)不停增长?
当Linux 启动一个程序时,会先给程序分配合适的虚拟地址空间,也就是我们申请的内存大小,不会把所有虚拟地址空间都映射到物理内存,而是把程序在运行中需要的数据,映射到物理内存,需要时可以再动态映射分配物理内存
因为每个进程都维护着自己的虚拟地址空间,每个进程都有一个页表来定位虚拟内存到物理内存的映射,每个虚拟内存也在表中都有一个对应的条目
当进程访问虚拟地址,但是在映射的页面中查不到对应的物理地址时,内核就会产生一个缺页异常(Page Fault),此时会重新分配物理内存,更新映射页表。
在内存访问中,在验证页表项通过之后,查询页表数据标记为不存在,会促发缺页中断,会重新分配物理页帧(从空闲内存或通过页面置换算法如 LRU 淘汰旧页),或者磁盘(如交换分区或文件)加载数据到物理页帧,更新页表项,标记为有效,重新执行触发缺页的指令。
通过页表项获得物理页帧基地址,加上虚拟地址中的页内偏移,可以得到最终物理地址。MMU 将物理地址发送到内存总线,CPU 读取或写入物理内存,同时会更新 TLB,下次使用直接读取 TLB的数据。
内核产生一个 page fault 异常事件分为两种:
minor fualt
当进程缺页事件发生在第一次访问虚拟内存时,虚拟内存已分配但未映射(如首次访问、写时复制、共享内存同步)物理地址,内核会产生一个 minor page fualt,并分配新的物理内存页。minor page fault 产生的开销比较小,minor page fualt 典型场景:
首次访问:进程申请内存后,内核延迟分配物理页(Demand Paging),首次访问时触发。写时复制(COW):fork()创建子进程时共享父进程内存,子进程写操作前触发共享库加载:动态链接库被多个进程共享,首次加载到物理内存时触发,即会共享页表
major fault
当物理页未分配且需从磁盘(Swap分区或文件)加载数据,内核就会产生一个 majorpage fault,比如内核通过Swap分区,将内存中的数据交换出去放到了硬盘,需要时从硬盘中重新加载程序或库文件的代码到内存。涉及到磁盘I/O,因此一个major fault对性能影响比较大,典型场景有
Swap In:物理内存不足时,内核将内存页换出到 Swap 分区,再次访问需换回。文件映射(mmap):通过 mmap 映射文件到内存,首次访问文件内容需从磁盘读取。
Minor Fault 是内存层面的轻量级操作,涉及到实际的物理内存分配,也是今天我们要跟踪的,Major Fault 是涉及磁盘I/O的重型操作。频繁的 Major Fault 就需要考虑性能问题, 对于缺页异常,我们可以通过传统工具比如 ps、vmstat、perf等工具来定位性能瓶颈
下面是我们实验用到的一个 Demo ,通过 perf 跟踪缺页异常
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$perf stat -e minor-faults,major-faults ./anon2mmap
PID = 13619
Allocated 0 GB
Allocated 1 GB
Allocated 2 GB
Allocated 3 GB
Allocated 4 GB
Allocated 5 GB
Allocated 6 GB
Allocated 7 GB
Total iterations: 2097152
Successfully mapped 8 GB
^C./anon2mmap: Interrupt
Performance counter stats for './anon2mmap':
4152 minor-faults
0 major-faults
22.012862749 seconds time elapsed
0.034524000 seconds user
3.493099000 seconds sys
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$
anon2mmap 通过 mmap 分配了8GB匿名内存,可以看到用户态CPU耗时 0.03,内核态 CPU 时间 3.49,缺页异常主要发生在 minor,实际中当前的生产环境中,考虑 交换分区的性能问题,一般在会准备机器的时候关闭交换分区。在内存使用中通过 Cgroup 对资源进行限制。通过 Qos 合理控制内存的超售问题
下面是我们测试用的 Demo,通过 mmap 分配一大块匿名内存,然后填充数据触发缺页异常,下面所有的Demo 都基于这个程序
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$cat anon2mmap.c
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <unistd.h>
#define GB ((long long) 1024 * 1024 * 1024 )
int main() {
printf("PID = %d\n", getpid());
//sleep(30);
long long size = 8 * GB; // 映射64MB内存
void *ptr = mmap(NULL, size, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (ptr == MAP_FAILED) {
perror("mmap failed");
return 1;
}
// 填充数据以触发实际内存分配
for (long long i = 0; i < size; i += 4096) {
((char *)ptr)[i] = 'A';
if (i % (GB) == 0) { //
printf("Allocated %lld GB\n", i / GB);
}
}
printf("Successfully mapped %lld GB\n", size / GB);
munmap(ptr, size);
return 0;
}
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$
跟踪缺页错误和对应的调用栈信息,可以为内存用量分析提供一个新的视角,不同于我们之前讲的 brk 和 mmap 是虚拟内存分配的角度去分析内存用量,缺页异常会直接影响系统常驻内存的的增长,也就是物理内存的增长。
跟踪方式主要利用内核静态跟踪点以及软件跟踪点
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$sudo perf list | grep page_fault
exceptions:page_fault_kernel [Tracepoint event] #用户态触发的缺页异常
exceptions:page_fault_user [Tracepoint event] #内核态触发的缺页异常
iommu:io_page_fault [Tracepoint event] #IOMMU(输入输出内存管理单元)触发的缺页异常(常见于虚拟化或设备直通场景)
软件跟踪点,实际上也是基于内核静态跟踪点,对多种缺页异常进行统计
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$perf list | grep page-faults
page-faults OR faults [Software event]
stackcount
stackcount 可能是我们用的最多的一个 BPF 工具,用于对特定函数进行跟踪,可以是静态跟踪点,也可以是动态跟踪点,下面的命令, -p 指定进程ID,后面为内核静态跟踪点的表达式,这里跟踪用户态的缺页异常 page_fault_user
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$/usr/share/bcc/tools/stackcount -p 9147 t:exceptions:page_fault_user
Tracing 1 functions for "t:exceptions:page_fault_user"... Hit Ctrl-C to end.
^C
exc_page_fault
exc_page_fault
asm_exc_page_fault
[unknown]
[unknown]
4096
Detaching...
默认情况下会同时输出 用户态和内核态的调用栈,内核态调用栈显示缺页异常由 asm_exc_page_fault(汇编层入口)触发,最终调用exc_page_fault(缺页处理函数)。[unknown] 表示用户态调用栈未捕获或符号解析失败,4096 表示该调用路径发生了 4096 次缺页事件。
添加 -U 选项,只输出用户态的调用栈数据,但是这里的用户态调用栈没有解析出函数名
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$/usr/share/bcc/tools/stackcount -p 9190 -U t:exceptions:page_fault_user
Tracing 1 functions for "t:exceptions:page_fault_user"... Hit Ctrl-C to end.
^C
[unknown]
[unknown]
4096
Detaching...
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$
trace
trace 也是一个比较常用的 BPF 工具,用于跟踪函数调用时函数签名相关信息,通过 trace 我们可以获取用户态的调用栈,解决上面的问题,运行程序 Demo
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$./anon2mmap
PID = 9261
Allocated 0 GB
Allocated 1 GB
Allocated 2 GB
Allocated 3 GB
Allocated 4 GB
Allocated 5 GB
Allocated 6 GB
Allocated 7 GB
Total iterations: 2097152
Successfully mapped 8 GB
通过 trace 来跟踪缺页函数调用,通上面的 stackcount 工具我们可以知道调用了 4096 次缺页分配函数,所以通过 teace 跟踪可以看到很多数据,这里我们只展示部分
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$/usr/share/bcc/tools/trace -p 9261 -U t:exceptions:page_fault_user
PID TID COMM FUNC
....................
9261 9261 anon2mmap page_fault_user
main+0x99 [anon2mmap]
__libc_start_call_main+0x80 [libc.so.6]
9261 9261 anon2mmap page_fault_user
main+0x99 [anon2mmap]
__libc_start_call_main+0x80 [libc.so.6]
9261 9261 anon2mmap page_fault_user
main+0x99 [anon2mmap]
__libc_start_call_main+0x80 [libc.so.6]
9261 9261 anon2mmap page_fault_user
main+0x99 [anon2mmap]
__libc_start_call_main+0x80 [libc.so.6]
9261 9261 anon2mmap page_fault_user
main+0x99 [anon2mmap]
__libc_start_call_main+0x80 [libc.so.6]
9261 9261 anon2mmap page_fault_user
main+0x99 [anon2mmap]
__libc_start_call_main+0x80 [libc.so.6]
9261 9261 anon2mmap page_fault_user
main+0x99 [anon2mmap]
__libc_start_call_main+0x80 [libc.so.6]
9261 9261 anon2mmap page_fault_user
main+0x99 [anon2mmap]
__libc_start_call_main+0x80 [libc.so.6]
9261 9261 anon2mmap page_fault_user
main+0x99 [anon2mmap]
__libc_start_call_main+0x80 [libc.so.6]
............................................
9261 9261 anon2mmap page_fault_user
main+0x99 [anon2mmap]
__libc_start_call_main+0x80 [libc.so.6]
9261 9261 anon2mmap page_fault_user
main+0x99 [anon2mmap]
__libc_start_call_main+0x80 [libc.so.6]
9261 9261 anon2mmap page_fault_user
main+0x99 [anon2mmap]
__libc_start_call_main+0x80 [libc.so.6]
PID 9261(进程名 anon2mmap)频繁触发用户态缺页异常(page_fault_user),每次缺页异常的调用栈完全相同,表明所有缺页均源于 main 函数的同一代码位置(偏移 0x99),可能是循环或重复操作中访问未映射的内存区域,
通过 free 命令可以实时的观察 物理内存得变化
┌──[root@liruilongs.github.io]-[~]
└─$free -h -s 0.1 -c 1000
total used free shared buff/cache available
Mem: 15Gi 856Mi 14Gi 11Mi 649Mi 14Gi
Swap: 2.0Gi 0B 2.0Gi
total used free shared buff/cache available
Mem: 15Gi 2.0Gi 12Gi 11Mi 649Mi 13Gi
Swap: 2.0Gi 0B 2.0Gi
total used free shared buff/cache available
Mem: 15Gi 3.3Gi 11Gi 11Mi 649Mi 12Gi
Swap: 2.0Gi 0B 2.0Gi
total used free shared buff/cache available
Mem: 15Gi 4.4Gi 10Gi 11Mi 649Mi 10Gi
Swap: 2.0Gi 0B 2.0Gi
total used free shared buff/cache available
Mem: 15Gi 5.6Gi 9.3Gi 11Mi 649Mi 9.7Gi
Swap: 2.0Gi 0B 2.0Gi
total used free shared buff/cache available
Mem: 15Gi 6.6Gi 8.3Gi 11Mi 649Mi 8.7Gi
Swap: 2.0Gi 0B 2.0Gi
total used free shared buff/cache available
Mem: 15Gi 7.7Gi 7.2Gi 11Mi 649Mi 7.6Gi
Swap: 2.0Gi 0B 2.0Gi
total used free shared buff/cache available
Mem: 15Gi 8.5Gi 6.4Gi 11Mi 649Mi 6.8Gi
Swap: 2.0Gi 0B 2.0Gi
total used free shared buff/cache available
Mem: 15Gi 852Mi 14Gi 11Mi 649Mi 14Gi
Swap: 2.0Gi 0B 2.0Gi
faults
faults 是一个 bpftrace 工具,通过统计软件跟踪点,对缺页异常进行统计,同时会输出缺页异常的调用栈,可以看作是上面两个工具的结合
下面的代码地址
https://github.com/brendangregg/bpf-perf-tools-book/blob/master/originals/Ch07_Memory/faults.bt
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$cat ./faults.bt
#!/usr/bin/bpftrace
/*
* faults - Count page faults with user stacks.
*
* See BPF Performance Tools, Chapter 7, for an explanation of this tool.
*
* Copyright (c) 2019 Brendan Gregg.
* Licensed under the Apache License, Version 2.0 (the "License").
* This was originally created for the BPF Performance Tools book
* published by Addison Wesley. ISBN-13: 9780136554820
* When copying or porting, include this comment.
*
* 27-Jan-2019 Brendan Gregg Created this.
*/
software:page-faults:1
{
@[ustack,pid, comm] = count();
}
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$
输出跟踪结果,返回用户态函数调用栈,以及缺页函数调用次数
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$./faults.bt
Attaching 1 probe...
^C
@[
main+153
__libc_start_call_main+128
, 9684, anon2mmap]: 4096
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$
使用了 Linux 的 perf stat命令来收集关于 sleep 2 命令执行期间的性能计数器统计信息
┌──[root@liruilongs.github.io]-[~]
└─$perf stat sleep 2
Performance counter stats for 'sleep 2':
12.04 msec task-clock # 0.006 CPUs utilized
1 context-switches # 0.083 K/sec
1 cpu-migrations # 0.083 K/sec
74 page-faults # 0.006 M/sec
3,328,860 cycles # 0.276 GHz
0 instructions # 0.00 insn per cycle
289,196 branches # 24.020 M/sec
12,686 branch-misses # 4.39% of all branches
2.034208658 seconds time elapsed
0.000000000 seconds user
0.032226000 seconds sys
┌──[root@liruilongs.github.io]-[~]
└─$
统计信息的解释:
task-clock:任务时钟,表示命令执行的总时间(以毫秒为单位)。context-switches:上下文切换次数,表示在命令执行期间发生的进程上下文切换次数。cpu-migrations:CPU 迁移次数,表示在命令执行期间发生的进程在不同 CPU 之间的迁移次数。page-faults:缺页错误次数,表示在命令执行期间发生的内存页面错误次数(可以简单理解为类似缓存穿透)
缺页错误来自哪些文件?
faults(8) 也是一个 bpftrace 工具,根据文件名来跟踪缺页错误,这里的文件名,是一些文件映射内存的场景,如果使用匿名内存是无法跟踪的。
代码地址:
https://github.com/brendangregg/bpf-perf-tools-book/blob/master/originals/Ch07_Memory/ffaults.bt
这个工具使用 kprobes 来跟踪 handle_mm_fault() 内核函数,并且从该函数的调用参数中提取文件名信息。文件相关的缺页错误的出现频率和系统上运行的程序有关;
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$cat ffaults.bt
#!/usr/bin/bpftrace
/*
* ffaults - Count page faults by filename.
*
* See BPF Performance Tools, Chapter 7, for an explanation of this tool.
*
* Copyright (c) 2019 Brendan Gregg.
* Licensed under the Apache License, Version 2.0 (the "License").
* This was originally created for the BPF Performance Tools book
* published by Addison Wesley. ISBN-13: 9780136554820
* When copying or porting, include this comment.
*
* 26-Jan-2019 Brendan Gregg Created this.
*/
#include <linux/mm.h>
kprobe:handle_mm_fault
{
$vma = (struct vm_area_struct *)arg0;
$file = $vma->vm_file->f_path.dentry->d_name.name;
@[str($file)] = count();
}
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$
我们使用之前的程序测试,跟踪发现无法获取文件名,应该是匿名内存的原因,但是可以统计缺页函数调用次数
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$./anon2mmap
PID = 14284
Allocated 0 GB
..............
Total iterations: 2097152
Successfully mapped 8 GB
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$./ffaults.bt
Attaching 1 probe...
^C
@[]: 4096
对上面的 bpftrace 脚本做简单的修改
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$cat ffaults1.bt
#!/usr/bin/bpftrace
kprobe:handle_mm_fault
{
$vma = (struct vm_area_struct *)arg0;
// 关键修复:检查指针有效性需用 != 0 而非隐式判断 [1,3](@ref)
if ($vma->vm_file != 0) {
$file = str($vma->vm_file->f_path.dentry->d_name.name);
} else {
$file = "anonymous"; // 标记匿名内存(堆/栈)
}
@[comm, pid, $file] = count();
}
END {
printf("%-16s %-8s %-40s %s\n", "COMM", "PID", "FILE", "FAULTS");
//print(@);
}
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$
再次运行,我们可以获取到匿名内存对应的进程相关的数据
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$./ffaults1.bt
Attaching 2 probes...
^CCOMM PID FILE FAULTS
@[anon2mmap, 14655, ld.so.cache]: 1
@[bash, 14655, ld-linux-x86-64.so.2]: 2
@[bash, 13566, libc.so.6]: 2
@[bash, 13566, bash]: 5
@[bash, 14655, libc.so.6]: 5
@[anon2mmap, 14655, anon2mmap]: 6
@[bash, 14655, bash]: 9
@[anon2mmap, 14655, ld-linux-x86-64.so.2]: 9
@[bash, 14655, anonymous]: 10
@[anon2mmap, 14655, libc.so.6]: 27
@[bash, 13566, anonymous]: 76
@[anon2mmap, 14655, anonymous]: 4109
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$
页换出守护进程(kswapd)的跟踪
我们先来理解页换入操作是什么?当系统内存需求超过一定水平时,内核中的页换出守护进程(kswapd)就开始寻找可以释放的内存页. 类似一些编程语言的垃圾回收
[root@liruilongs.github.io ~]# ps -eaf | grep ksw | grep -v col
root 113 2 0 15:02 ? 00:00:00 [kswapd0]
[root@liruilongs.github.io ~]#
当系统内存剩余量低于低水位阈值(pages_low)时,内核的页换出守护进程(kswapd)会被唤醒并开始回收内存。
守护进程(kswapd)会释放以下列出的三种内存页之一:
文件系统页:从磁盘中读出并且是没有修改过的页(术语为有磁盘备份的页(backed by disk),这些页可以立即被释放,等需要的时候可以再读取回来这些页包括应用程序可执行代码、数据,以及文件系统的元数据等。被修改过的文件系统页:这些页被称为脏页,这些页需要先写回磁盘才能被释放。应用程序内存页:这些页被称为匿名页(anonymous memory),因为这些页不是来源于某个文件的。如果系统中有换页设备(swap device),那么这些页可以先存入换页设备,再被释放。将内存页写入换页设备(在 linux系统上)称为换页。
vmscan(8)’ 使用 vmscan 跟踪点来观察页换出守护进程(kswapd)的操作,该进程在系统内存压力上升时负责释放内存以便重用。
它通过跟踪内核 tracepoint,记录 slab 收缩(mm_shrink_slab)、直接内存回收(mm_vmscan_direct_reclaim)、cgroup 内存回收(mm_vmscan_memcg_reclaim)的开始和结束时间,计算各阶段耗时并生成直方图,同时统计唤醒 kswapd 守护进程(mm_vmscan_wakeup_kswapd)和页面写回(mm_vmscan_writepage)的次数。脚本每秒输出一次汇总数据,包括各阶段耗时(转换为毫秒)和事件计数,帮助分析系统内存回收性能与压力情况。
对应的代码地址:
https://github.com/brendangregg/bpf-perf-tools-book/blob/master/originals/Ch07_Memory/vmscan.bt
#!/usr/bin/bpftrace
/*
* vmscan - Measure VM scanner shrink and reclaim times.
*
* See BPF Performance Tools, Chapter 7, for an explanation of this tool.
*
* Also see see Mel Gorman's trace-vmscan-postprocess.pl.
*
* Copyright (c) 2019 Brendan Gregg.
* Licensed under the Apache License, Version 2.0 (the "License").
* This was originally created for the BPF Performance Tools book
* published by Addison Wesley. ISBN-13: 9780136554820
* When copying or porting, include this comment.
*
* 26-Jan-2019 Brendan Gregg Created this.
*/
tracepoint:vmscan:mm_shrink_slab_start { @start_ss[tid] = nsecs; }
tracepoint:vmscan:mm_shrink_slab_end /@start_ss[tid]/
{
$dur_ss = nsecs - @start_ss[tid];
@sum_ss = @sum_ss + $dur_ss;
@shrink_slab_ns = hist($dur_ss);
delete(@start_ss[tid]);
}
tracepoint:vmscan:mm_vmscan_direct_reclaim_begin { @start_dr[tid] = nsecs; }
tracepoint:vmscan:mm_vmscan_direct_reclaim_end /@start_dr[tid]/
{
$dur_dr = nsecs - @start_dr[tid];
@sum_dr = @sum_dr + $dur_dr;
@direct_reclaim_ns = hist($dur_dr);
delete(@start_dr[tid]);
}
tracepoint:vmscan:mm_vmscan_memcg_reclaim_begin { @start_mr[tid] = nsecs; }
tracepoint:vmscan:mm_vmscan_memcg_reclaim_end /@start_mr[tid]/
{
$dur_mr = nsecs - @start_mr[tid];
@sum_mr = @sum_mr + $dur_mr;
@memcg_reclaim_ns = hist($dur_mr);
delete(@start_mr[tid]);
}
tracepoint:vmscan:mm_vmscan_wakeup_kswapd { @count_wk++; }
tracepoint:vmscan:mm_vmscan_writepage { @count_wp++; }
BEGIN
{
printf("%-10s %10s %12s %12s %6s %9s\n", "TIME",
"S-SLABms", "D-RECLAIMms", "M-RECLAIMms", "KSWAPD", "WRITEPAGE");
}
interval:s:1
{
time("%H:%M:%S");
printf(" %10d %12d %12d %6d %9d\n",
@sum_ss / 1000000, @sum_dr / 1000000, @sum_mr / 1000000,
@count_wk, @count_wp);
clear(@sum_ss);
clear(@sum_dr);
clear(@sum_mr);
clear(@count_wk);
clear(@count_wp);
}
这里我们使用 stress-ng 来模拟内存负载,唤醒 kswapd 守护进程
[root@liruilongs.github.io ~]# stress-ng --vm 4 --vm-bytes 9.5G --timeout 60s
stress-ng: info: [1377500] setting to a 60 second run per stressor
stress-ng: info: [1377500] dispatching hogs: 4 vm
stress-ng: info: [1377500] successful run completed in 60.56s (1 min, 0.56 secs)
[root@liruilongs.github.io ~]#
每秒输出的列包括如下几个:
S-SLABms:收缩 slab 所花的全部时间,以毫秒为单位。这是从各种内核缓存中量回收内存。D-RECLAIMms:直接回收所花的时间,以毫秒为单位。这是前台回收过程在此期间内存被换入磁盘中,并且内存分配处于阻塞状态。(需要 重点关注)M-RECLAIMms:内存 cgroup 回收所花的时间,以毫秒为单位。如果使用了内存cgroups,此列显示当cgroup超出内存限制,导致该cgroup进行内存回收的时间。KSWAPD:kswapd 唤醒的次数。WRITEPAGE:kswapd 写入页的数量。
[root@liruilongs.github.io tools]# ./vmscan.bt
Attaching 10 probes...
TIME S-SLABms D-RECLAIMms M-RECLAIMms KSWAPD WRITEPAGE
06:49:10 10 1136 0 11 3
06:49:11 4 470 0 3 0
06:49:12 3 235 0 1 0
06:49:14 1 32 0 3 0
06:49:14 0 0 0 0 0
06:49:15 7 1518 0 8 2
06:49:16 13 3587 0 25 2
06:49:17 2 381 0 4 0
06:49:18 0 0 0 0 0
06:49:19 5 439 0 7 0
06:49:20 4 1009 0 10 0
06:49:21 6 738 0 8 1
06:49:22 5 375 0 5 0
06:49:23 4 440 0 6 0
06:49:24 4 375 0 8 0
06:49:25 4 350 0 4 1
06:49:26 4 285 0 4 0
06:49:27 5 336 0 3 1
06:49:28 0 0 0 0 0
06:49:29 0 0 0 0 0
06:49:30 0 0 0 0 0
06:49:31 0 0 0 0 0
06:49:32 0 0 0 0 0
06:49:33 0 0 0 0 0
06:49:34 0 0 0 0 0
06:49:35 0 0 0 0 0
^C
直接内存回收的直方图
256K-512K 纳秒(0.256-0.5 毫秒)区间出现 4272 次,占比最高,是主要耗时区间,512K-1M 纳秒(0.5-1 毫秒)区间出现 3011 次,次高频,说明多数直接回收操作在 0.25-1 毫秒内完成,属于正常范围
@direct_reclaim_ns:
[64K, 128K) 31 | |
[128K, 256K) 1976 |@@@@@@@@@@@@@@@@@@@@@@@@ |
[256K, 512K) 4272 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[512K, 1M) 3011 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[1M, 2M) 918 |@@@@@@@@@@@ |
[2M, 4M) 193 |@@ |
[4M, 8M) 112 |@ |
[8M, 16M) 45 | |
[16M, 32M) 2 | |
[32M, 64M) 1 | |
[64M, 128M) 55 | |
[128M, 256M) 2 | |
slab 收缩(shrink_slab_ns)耗时分布
256-512 纳秒区间出现 254921 次,占绝对主导(几乎所有操作,说明 slab 收缩操作耗时极短(仅 0.25-0.5 微秒),效率极高
@shrink_slab_ns:
[128, 256) 2494 | |
[256, 512) 254921 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[512, 1K) 18830 |@@@ |
[1K, 2K) 829 | |
[2K, 4K) 168 | |
[4K, 8K) 95 | |
[8K, 16K) 85 | |
[16K, 32K) 48 | |
[32K, 64K) 11 | |
[64K, 128K) 2 | |
[128K, 256K) 0 | |
[256K, 512K) 0 | |
[512K, 1M) 0 | |
[1M, 2M) 1 | |
[root@liruilongs.github.io tools]#
那些进程存在直接回收延迟?
drsnoop(8)'是一个 BCC 工具,用来跟踪内存释放过程中的直接回收部分,可以显示受到影响的进程,以及对应的延迟:直接回收所需的时间。这可以用来定量分析在内存受限的系统中对应用程序的性能影响。
这里的直接回收(Direct Reclaim),即当应用程序尝试分配内存时,若当前内存不足且后台回收未能及时补充,内核会直接阻塞当前进程,同步执行内存回收操作(如扫描页面、释放缓存、交换数据到磁盘等),直至满足分配需求。这种回收方式会对进程的运行造成延迟,即 “直接回收延迟”。
这个工具内部跟踪的是 mm_vmscan_direct_reclaim_begin 和 mm_vmscan_direct_reclaim_end 跟踪点。这些应该都是低频事件(仅在短时间内集中出现),所以这里的额外消耗可以忽略不计。
[root@liruilongs.github.io tools]# ./drsnoop
COMM PID LAT(ms) PAGES
stress-ng 1381737 1.05 62
stress-ng 1381738 1.18 59
stress-ng 1381738 0.31 42
stress-ng 1381740 1.76 50
stress-ng 1381737 0.10 32
stress-ng 1381740 0.10 33
stress-ng 1381739 2.68 40
stress-ng 1381738 0.12 32
stress-ng 1381737 0.23 64
stress-ng 1381738 0.24 61
stress-ng 1381740 0.24 57
stress-ng 1381739 0.29 49
stress-ng 1381739 0.18 52
stress-ng 1381740 0.39 80
stress-ng 1381739 0.18 58
stress-ng 1381740 0.20 51
stress-ng 1381740 0.15 65
xfce4-terminal 32026 0.07 33
stress-ng 1381740 0.05 32
stress-ng 1381740 0.05 32
xfce4-terminal 32026 0.07 32
xfce4-terminal 32026 0.06 32
stress-ng 1381740 0.06 32
.............
stress-ng(PID 1381737~1381740)持续触发回收,单次回收 32-80页(128KB-320KB),延迟多数在 0.05ms-2.68ms之间。这表明内存压力大:进程频繁申请内存,触发内核强制回收。xfce4-terminal(PID 32026)也有回收事件,但延迟较低(0.06-0.07ms),回收量小(32-33页)
可以通过 LAT(ms)/PAGES,做回收效率对比,高延迟低效率,如 stress-ng 的 2.68ms 仅回收 40页 → 回收效率低(阻塞时间长,释放内存少)
哪些进程阻塞于页换入操作?
swapin(8)展示了哪个进程正在从换页设备中换入页,前提是系统中有正在使用的换页设备。这里需要提前确认交换分区,确保交换分区是开启状态
[root@liruilongs.github.io tools]# swapon --show
[root@liruilongs.github.io tools]# swapon -a
[root@liruilongs.github.io tools]# swapon --show
NAME TYPE SIZE USED PRIO
/dev/dm-1 partition 4G 0B -2
这个工具使用kprobes 来跟踪 swap_readpage() 内核函数,这会在触发换页所在的进程上下文中运行
这里任然使用上面的内存压测工具
[root@liruilongs.github.io tools]# ./swapin.bt
Attaching 2 probes...
06:58:08
@[xfce4-terminal, 32026]: 2
@[stress-ng, 1380727]: 1034
06:58:09
@[xfce4-terminal, 32026]: 1
@[xfsettingsd, 1736]: 1
@[xfdesktop, 1758]: 14
@[xfce4-panel, 1743]: 22
@[xfwm4, 1710]: 24
@[stress-ng, 1380727]: 221
06:58:10
@[xfwm4, 1710]: 4
@[xfdesktop, 1758]: 5
@[xfce4-terminal, 32026]: 9
@[xfce4-panel, 1743]: 91
@[stress-ng, 1380727]: 421
06:58:11
@[xfce4-terminal, 32026]: 1
@[xfce4-panel, 1743]: 13
@[stress-ng, 1380727]: 800
06:58:12
06:58:13
@[xfwm4, 1710]: 2
@[ibus-extension-, 2124]: 4
@[xfce4-terminal, 32026]: 7
@[xfdesktop, 1758]: 25
@[stress-ng, 1380727]: 489
06:58:14
@[xfce4-terminal, 32026]: 14
@[xfce4-panel, 1743]: 36
@[stress-ng, 1380727]: 963
06:58:15
^C
@[ibus-extension-, 2124]: 2
@[xfce4-terminal, 32026]: 4
@[xfce4-panel, 1743]: 19
@[ibus-x11, 2126]: 100
@[stress-ng, 1380727]: 1349
[root@liruilongs.github.io tools]# ^C
stress-ng是主要内存压力源,单秒 Swap In 峰值达 1349 次,说明其持续申请内存并触发频繁换页,初期仅 stress-ng 高负载,后期扩散至桌面进程,表明物理内存资源逐步耗尽
大页的缺页错误跟踪
hfaults(8)'通过跟踪巨页相关的缺页错误信息,按进程展示详细信息,同时可以用来确保巨页确实被启用了。
代码地址
https://github.com/brendangregg/bpf-perf-tools-book/blob/master/originals/Ch07_Memory/hfaults.bt
#!/usr/local/bin/bpftrace
/*
* hfaults - Count huge page faults by process.
*
* See BPF Performance Tools, Chapter 7, for an explanation of this tool.
*
* Copyright (c) 2019 Amer Ather.
* Licensed under the Apache License, Version 2.0 (the "License").
* This was originally created for the BPF Performance Tools book
* published by Addison Wesley. ISBN-13: 9780136554820
* When copying or porting, include this comment.
*/
BEGIN
{
printf("Tracing Huge Page faults per process... Hit Ctrl-C to end.\n");
}
kprobe:hugetlb_fault
{
@[pid, comm] = count();
}
大页映射既可以用于文件映射,也可以用于匿名映射,具体取决于使用的场景和参数,使用上面的工具,在这之前我们需要做一些准备工作
┌──[root@liruilongs.github.io]-[~/bpfdemo/mmapdev]
└─$grep -i huge /proc/meminfo | grep -i size
Hugepagesize: 2048 kB
┌──[root@liruilongs.github.io]-[~/bpfdemo/mmapdev]
└─$sysctl -a | grep huge
vm.hugetlb_optimize_vmemmap = 0
vm.hugetlb_shm_group = 0
vm.nr_hugepages = 0
vm.nr_hugepages_mempolicy = 0
vm.nr_overcommit_hugepages = 0
┌──[root@liruilongs.github.io]-[~/bpfdemo/mmapdev]
└─$free -h
total used free shared buff/cache available
Mem: 15Gi 12Gi 2.8Gi 3.0Mi 419Mi 3.0Gi
Swap: 2.0Gi 337Mi 1.7Gi
┌──[root@liruilongs.github.io]-[~/bpfdemo/mmapdev]
└─$sysctl -w vm.nr_hugepages=50
vm.nr_hugepages = 50
┌──[root@liruilongs.github.io]-[~/bpfdemo/mmapdev]
└─$free -h
total used free shared buff/cache available
Mem: 15Gi 12Gi 2.7Gi 3.0Mi 419Mi 2.9Gi
Swap: 2.0Gi 337Mi 1.7Gi
┌──[root@liruilongs.github.io]-[~/bpfdemo/mmapdev]
└─$sysctl -a | grep huge
vm.hugetlb_optimize_vmemmap = 0
vm.hugetlb_shm_group = 0
vm.nr_hugepages = 50
vm.nr_hugepages_mempolicy = 50
vm.nr_overcommit_hugepages = 0
┌──[root@liruilongs.github.io]-[~/bpfdemo/mmapdev]
└─$mkdir -p /dev/hugepages
┌──[root@liruilongs.github.io]-[~/bpfdemo/mmapdev]
└─$mount -t hugetlbfs -o pagesize=2M none /dev/hugepages
上面的命令主要完成了大页内存(Huge Pages)的配置与挂载,具体操作如下:
首先通过grep命令确认系统默认大页大小为2048KB(2MB);接着用sysctl查看大页相关参数,此时vm.nr_hugepages为0,意味着未分配大页内存;随后执行sysctl -w vm.nr_hugepages=50,为系统分配50个大页,每个大小2MB,共100MB内存,此时free -h显示可用内存减少约100MB;
接着通过sysctl -a验证大页分配成功,nr_hugepages和nr_hugepages_mempolicy均变为50;最后创建/dev/hugepages目录,并使用mount命令将大页文件系统(hugetlbfs)挂载到该目录,指定页大小为2MB,以便后续通过该目录使用大页内存。
下面是一个 文件内存映射使用大页的 Demo,可以看到分配2个大页,一个大页 2MB,两个 4MB
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$cat hug2mmap.c
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#define MAP_SIZE (4 * 1024 * 1024) // 4MB,2个2MB大页
int main() {
int fd;
char *map;
char path[] = "/dev/hugepages/test_huge";
// 确保挂载了 hugetlbfs
//system("mount | grep hugetlbfs || mount -t hugetlbfs -o pagesize=2M none /dev/hugepages");
// 打开 hugetlbfs 文件
fd = open(path, O_CREAT | O_RDWR, 0666);
if (fd == -1) {
perror("open");
return EXIT_FAILURE;
}
// 调整文件大小
if (ftruncate(fd, MAP_SIZE) == -1) {
perror("ftruncate");
close(fd);
return EXIT_FAILURE;
}
// 映射内存(无需 MAP_HUGETLB 标志)
map = mmap(NULL, MAP_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (map == MAP_FAILED) {
perror("mmap");
close(fd);
unlink(path);
return EXIT_FAILURE;
}
// 填充数据(触发大页分配)
memset(map, 'A', MAP_SIZE);
// 验证大页使用
//printf("Huge pages usage:\n");
//system("grep -i huge /proc/meminfo");
//system("cat /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages");
// 清理
munmap(map, MAP_SIZE);
close(fd);
unlink(path);
return 0;
}
执行 Demo后观察 HugePages 相关的指标数据,确认是否使用成功
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$vim hug2mmap.c
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$gcc -g hug2mmap.c -o hug2mmap
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$./hug2mmap
┌──[root@liruilongs.github.io]-[~/bpfdemo]
└─$./hug2mmap
hugetlbfs on /dev/hugepages type hugetlbfs (rw,relatime,pagesize=2M)
Huge pages usage:
AnonHugePages: 20480 kB
ShmemHugePages: 0 kB
FileHugePages: 0 kB
HugePages_Total: 50
HugePages_Free: 48
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
Hugetlb: 102400 kB
50
分配了 50 个,使用 2个,空闲大页数为 48 个
HugePages_Total: 50
HugePages_Free: 48
hfaults 工具跟踪,可以看到两次大页的缺页异常
┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools]
└─$./hfaults.bt
Attaching 2 probes...
Tracing Huge Page faults per process... Hit Ctrl-C to end.
^C
@[2311, hug2mmap]: 2
博文部分内容参考
© 文中涉及参考链接内容版权归原作者所有,如有侵权请告知 :)
《BPF Performance Tools》
© 2018-至今, 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)

- 点赞
- 收藏
- 关注作者
评论(0)