小型 LLM 与边缘推理:模型压缩与 on‑device 部署实践

小型 LLM 与边缘推理:模型压缩与 on‑device 部署实践
近年来,大型语言模型(LLM)不断推动人工智能能力向前发展,但其庞大的参数规模和计算资源要求限制了其在边缘设备(如手机、嵌入式系统、IoT 设备)上的部署。随着模型压缩、量化和高效推理引擎的发展,小型 LLM 的 on-device 部署逐渐成为可能。
本文将深入剖析如何将小型语言模型压缩并部署到边缘设备,从理论、工程、代码实践三个层面详解其核心技术路径。
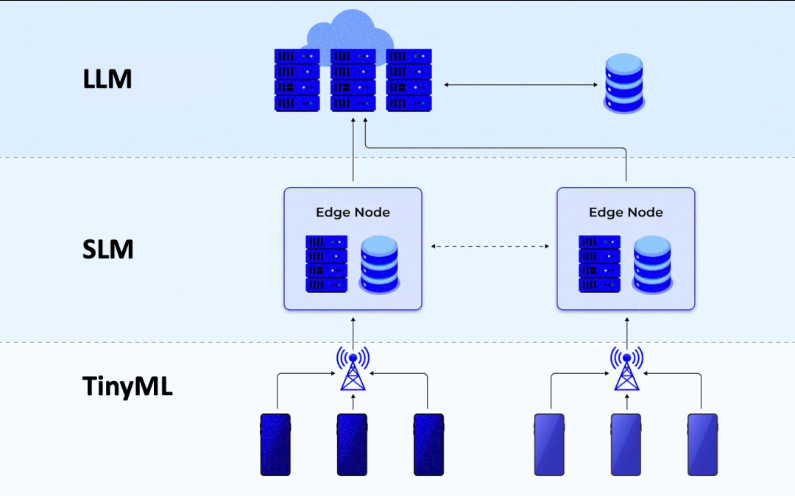
一、为什么要部署小型 LLM 到边缘设备
边缘部署具备如下优势:
- 隐私保护:数据无需上传云端,减少隐私泄露风险。
- 低延迟:本地推理可实现毫秒级响应,无需等待网络传输。
- 离线可用:适用于无网、弱网环境。
- 成本优化:降低带宽、云计算资源消耗。
然而,这也带来显著挑战:内存、算力、存储受限,模型需要极致压缩。
二、小型语言模型的选择
在边缘部署时,以下几种小型语言模型是不错的选择:
- DistilGPT2 / DistilBERT:HuggingFace 出品,压缩版 GPT/BERT。
- TinyLlama:1.1B 参数以内,具备对话和推理能力。
- MobileBERT / TinyBERT:针对移动设备优化的 BERT 变体。
- Phi-1.5 / Mistral 7B (Q4 量化):部分模型经量化后也能部署在高性能边缘设备上。
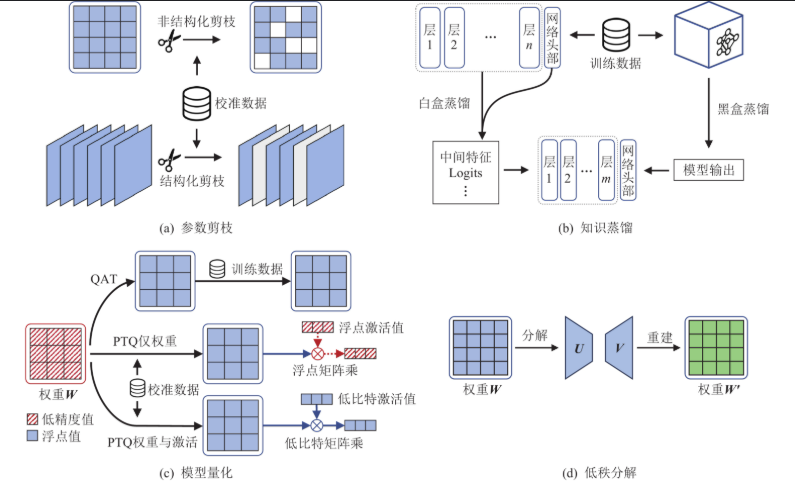
三、模型压缩方法:从几十亿参数到几百MB
模型压缩是边缘部署的前提,包括:
1. 权重量化(Quantization)
将 FP32 转为 INT8/INT4 等低位精度。
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
import bitsandbytes as bnb
model_id = "EleutherAI/gpt-neo-125M"
model = AutoModelForCausalLM.from_pretrained(model_id, load_in_8bit=True, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_id)
使用
bitsandbytes实现 INT8 加载,支持 4/8 bit 权重量化。
2. 权重剪枝(Pruning)
删除不重要的权重连接以减小模型规模。可用 torch.nn.utils.prune 实现。
import torch.nn.utils.prune as prune
prune.random_unstructured(model.transformer.h[0].attn.c_proj, name="weight", amount=0.3)
3. 知识蒸馏(Knowledge Distillation)
训练一个小模型 mimick 大模型的行为。
# 简化伪代码
teacher_logits = teacher(input_ids).logits
student_logits = student(input_ids).logits
loss = nn.KLDivLoss()(F.log_softmax(student_logits), F.softmax(teacher_logits))
四、模型转换与部署格式:ONNX、GGUF 与 TFLite
小型模型训练后需转为适配格式:
1. 转换为 ONNX(适用于 NVIDIA Jetson / PC 边缘推理)
transformers-cli convert --model gpt2 --framework pt --format onnx
或使用 optimum 转换 HuggingFace 模型:
from optimum.exporters.onnx import main_export
main_export(["--model", "gpt2", "--task", "text-generation", "--output", "./onnx_model"])
2. 转为 GGUF 格式(用于 llama.cpp、iOS 和 Android)
# 示例:将 TinyLlama 转为 GGUF 格式
python convert.py --in-dir models/TinyLlama --out-type f16 --out-file tinyllama.gguf
3. 转为 TFLite(适用于 Android 手机)
# 假设已有 keras 模型
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
with open("model.tflite", "wb") as f:
f.write(tflite_model)
五、边缘推理引擎:跑得快才是王道
常见引擎包括:
| 推理引擎 | 支持平台 | 特点 |
|---|---|---|
| GGML/llama.cpp | CPU/iOS/Mac/安卓 | 无需GPU,轻量级运行 |
| ONNX Runtime | x86/ARM/GPU | 高性能通用推理 |
| TensorRT | Jetson/NVIDIA | GPU 推理速度极快 |
| TFLite | Android/iOS | 支持安卓/iOS硬件加速 |
示例:在终端运行 GGUF 模型推理
./main -m tinyllama.gguf -p "Hello, what is the capital of France?"
六、实践案例:部署 TinyLlama 到树莓派 + Web 接口
- 将模型压缩为
gguf格式; - 拷贝至 Raspberry Pi;
- 使用
llama.cpp编译适配 ARM; - 用 Flask 构建本地推理服务:
from flask import Flask, request
import subprocess
app = Flask(__name__)
@app.route('/chat', methods=['POST'])
def chat():
prompt = request.json['prompt']
result = subprocess.check_output(['./main', '-m', 'tinyllama.gguf', '-p', prompt])
return {"response": result.decode('utf-8')}
app.run(host="0.0.0.0", port=5000)
七、挑战与展望
虽然小型 LLM 的边缘部署正在逐步成熟,但在实际落地过程中仍面临诸多挑战和工程瓶颈,具体包括:
1. 上下文窗口受限
目前多数小模型(例如 TinyLlama、DistilGPT2 等)在压缩过程中,为节省显存和计算资源,往往牺牲了上下文长度。例如:
- DistilGPT2 默认上下文为 512 tokens;
- TinyLlama 在极致量化下可能只有 256~512 tokens。
实际影响:
- 多轮对话容易“忘记前文”;
- 长文理解和代码补全效果下降。
解决方案探索:
- Sliding Window 机制(滑动窗口式对话记忆);
- RNN-style Memory Augmentation(引入循环记忆单元);
- 使用外部语义缓存(semantic memory)模拟上下文持久性。
2. 量化误差积累
极致压缩(例如 INT4、二值化)虽然能显著缩小模型尺寸,但也引入明显的数值误差。某些任务(如代码生成、逻辑推理)对精度极其敏感,表现如下:
- 回答出现语义偏差;
- 文本重复、逻辑跳跃;
- 整体 perplexity 值上升。
优化方向:
- 采用 mixed-precision 模式(部分高精度保留);
- QLoRA 等感知型量化(Quantization-Aware Training);
- 引入自适应重参数机制(Adaptive Reparameterization)。
3. 推理效率瓶颈
虽然 llama.cpp 这类轻量引擎已经将 CPU 推理速度优化到极致,但在实际设备中(如 Raspberry Pi 4 或安卓手机),仍容易受到如下因素限制:
- CPU 缓存不足导致上下文重计算;
- 多线程调度不稳定;
- 设备发热严重,频繁降频。
应对策略:
- 使用 KV-Cache 持久保存中间表示;
- 利用 WebGPU / Metal API 在手机上硬件加速;
- 编译适配不同架构(如 ARM Neon、AVX2、WebAssembly SIMD)。
4. 多模态模型边缘部署尚未普及
虽然 LLaVA、MiniGPT 等多模态小模型不断涌现,但将视觉语言融合模型部署到边缘端目前仍处于早期阶段:
- 模型体积偏大(即使压缩后仍需 1GB 以上);
- 对图像推理硬件要求高;
- 没有统一推理框架(音频、视觉、文本三者仍分散处理)。
当前突破口:
- 多模态轻量 backbone 研究(如 MobileViT + TinyLlama);
- 单流模型架构(One-Stream Transformer);
- 使用 EdgeTPU/NPU 专用硬件协同处理多模态数据。
八、开源生态与工具链趋势观察
小型 LLM 的边缘部署得益于一批优秀的开源项目,这些工具逐渐构建出完整生态闭环:
| 项目名称 | 功能描述 | 特色说明 |
|---|---|---|
| llama.cpp | C++ 实现的轻量级 LLM 推理引擎 | 支持 GGUF 格式、量化运行 |
| GGML | 模型张量计算库,支持 INT4/INT8 量化 | 广泛集成到多模型框架 |
| AutoGPTQ | 高精度量化工具,支持 GPTQ/INT4 编码 | 可导出 Transformers 模型 |
| Optimum | HuggingFace 官方导出 & ONNX 优化库 | 一键转换为 TensorRT/ONNX |
| WebLLM | 支持浏览器 LLM 推理,基于 WebGPU | 实现真正 “零安装” 运行模型 |
组合建议:
Transformers + AutoGPTQ + llama.cpp→ GGUF 本地推理;Transformers + Optimum + ONNX Runtime→ Jetson TX2、Nano 等边缘 GPU;TF/Keras + TFLite→ Android/iOS 平台;Mistral/Qwen-Tiny + WebLLM→ 浏览器/前端边缘设备。
九、未来边缘智能场景设想
随着模型进一步压缩、硬件持续进化,小型 LLM 的边缘部署将激发出一系列新应用场景:
场景一:离线语音助手
无需联网即可运行的本地语音助手,可用于:
- 智能车载系统(汽车 AI 驾驶助手);
- 户外无人机控制;
- 工业生产线语音交互。
场景二:智能摄像头边缘处理
结合视觉模型与语言模型,在本地实现自然语言问答:
“昨晚 3 点有陌生人进入车库吗?”
摄像头内置模型直接分析视频并回复。
场景三:IoT 多模态控制中心
微型 LLM 嵌入智能网关,结合传感器数据提供自然语言接口:
“今天家里哪个房间的温湿度异常?”
→ 实时调用传感器数据并做语义分析回答。

- 点赞
- 收藏
- 关注作者
评论(0)