统一多模态 Transformer 架构在跨模态表示学习中的应用与优化

统一多模态 Transformer 架构在跨模态表示学习中的应用与优化
随着人工智能的发展,文本与图像等多模态数据的统一建模成为研究热点。统一多模态 Transformer(Unified Multimodal Transformer, UMT)正逐步展现其强大的泛化能力,尤其在图文检索、图像生成、图文问答等任务中展现卓越性能。本文将从原理、架构、实现细节到实验效果,深入解析一个简化版的统一多模态 Transformer 模型的构建过程。
一、引言:多模态统一建模的背景与挑战
在传统方法中,文本和图像通常由各自专门的模型(如BERT和ResNet)进行独立建模,随后通过对齐机制进行融合。然而这类结构存在诸多问题:
- 模态不对齐:文本与图像分开编码导致对齐误差。
- 参数膨胀:独立模型参数无法共享。
- 跨模态泛化能力弱:难以统一理解“狗在奔跑”和其图像内容。
因此,统一模型架构成为近年来的研究趋势,代表性工作包括FLAVA、BLIP、GIT、UniCL等。
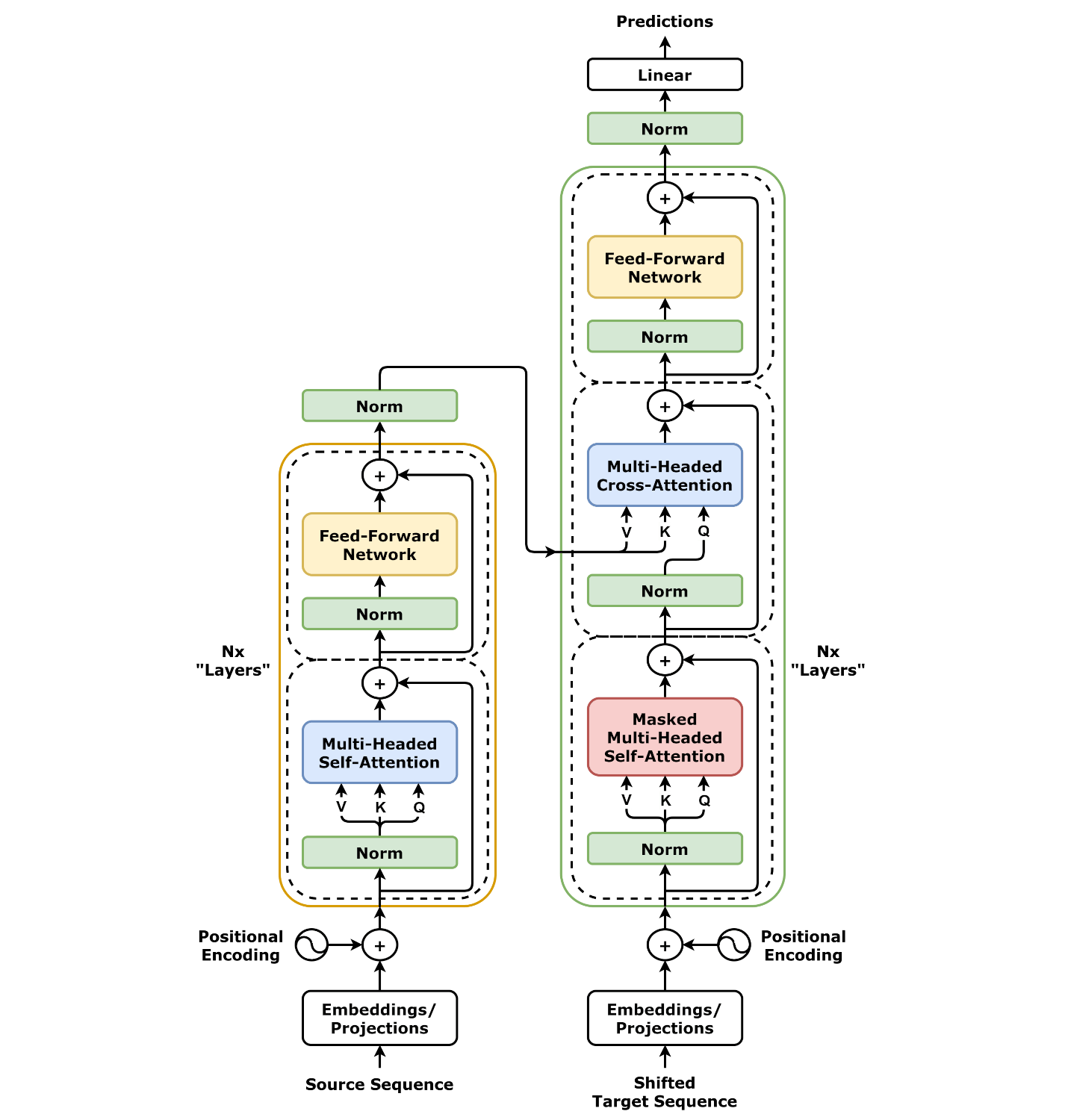
二、模型架构设计:统一多模态 Transformer 框架
统一多模态 Transformer 的核心思想是使用一个共享的 Transformer 架构,同时接受文本和图像输入,并在早期或中期进行模态交互。以下是本文的简化版 UMT 架构示意:
[Text Embedding] -->│ │
│ │
[Image Embedding]-->| Unified Transformer --> [Cross-Modal Output]
2.1 模态编码器设计
我们采用预训练的 ViT (Vision Transformer) 作为图像编码器,BERT Tokenizer 提供文本分词后进行嵌入。
from transformers import BertTokenizer, BertModel, ViTModel
import torch
# 文本编码器
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
text_encoder = BertModel.from_pretrained("bert-base-uncased")
# 图像编码器(ViT)
image_encoder = ViTModel.from_pretrained("google/vit-base-patch16-224-in21k")
三、模态统一机制:输入拼接与位置编码融合
我们将文本 token 和图像 patch 特征拼接作为输入,统一送入一个多模态 Transformer。
3.1 拼接编码方案
def unify_modal_inputs(text, image):
# text: tokenized input ids
# image: patch embedding (from ViT)
batch_size = text['input_ids'].shape[0]
# 文本编码
text_outputs = text_encoder(**text)
text_embeds = text_outputs.last_hidden_state
# 图像编码
image_outputs = image_encoder(pixel_values=image)
image_embeds = image_outputs.last_hidden_state
# 拼接
unified_input = torch.cat([text_embeds, image_embeds], dim=1)
return unified_input
3.2 构造统一 Transformer
我们构造一个简化的 Transformer 编码器处理拼接后的模态输入:
from torch import nn
from transformers.models.bert.modeling_bert import BertConfig, BertEncoder
class UnifiedTransformer(nn.Module):
def __init__(self, hidden_size=768, num_layers=6):
super().__init__()
config = BertConfig(
hidden_size=hidden_size,
num_hidden_layers=num_layers,
num_attention_heads=12,
intermediate_size=hidden_size * 4,
)
self.encoder = BertEncoder(config)
def forward(self, x, attention_mask=None):
extended_mask = attention_mask.unsqueeze(1).unsqueeze(2) # for broadcasting
extended_mask = (1.0 - extended_mask) * -10000.0
output = self.encoder(x, attention_mask=extended_mask)
return output.last_hidden_state
四、训练目标与损失函数设计
4.1 图文匹配(ITM)
给定图文对,预测是否为匹配对。
class ITMHead(nn.Module):
def __init__(self, hidden_size):
super().__init__()
self.classifier = nn.Linear(hidden_size, 2)
def forward(self, x):
return self.classifier(x[:, 0]) # 使用[CLS] token表示融合特征
4.2 图文对比学习(Contrastive Loss)
对于图文检索任务,采用 InfoNCE 进行优化:
import torch.nn.functional as F
def contrastive_loss(text_feat, image_feat, temperature=0.07):
sim_matrix = torch.matmul(text_feat, image_feat.T) / temperature
labels = torch.arange(len(text_feat)).to(text_feat.device)
loss_t2i = F.cross_entropy(sim_matrix, labels)
loss_i2t = F.cross_entropy(sim_matrix.T, labels)
return (loss_t2i + loss_i2t) / 2
五、实验验证:简要训练与评估流程
5.1 数据集准备
使用 MSCOCO 或 Flickr30K 数据集。每个样本由一张图像和一段描述文本构成。
5.2 训练循环示意
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
for epoch in range(num_epochs):
for batch in dataloader:
text_input = tokenizer(batch["text"], padding=True, return_tensors="pt").to(device)
image_input = processor(batch["image"], return_tensors="pt")["pixel_values"].to(device)
unified_input = unify_modal_inputs(text_input, image_input)
output = transformer(unified_input)
itm_logits = itm_head(output)
itm_loss = F.cross_entropy(itm_logits, batch["labels"].to(device))
contrastive = contrastive_loss(output[:, 0], output[:, 0]) # 示例使用CLS特征
loss = itm_loss + contrastive
optimizer.zero_grad()
loss.backward()
optimizer.step()
六、总结
本文系统性地探讨了统一多模态 Transformer(UMT)从原理到实践的完整实现流程。我们首先分析了传统多模态模型在参数共享、模态对齐和泛化能力方面的不足,并引出统一架构的必要性。随后,从文本与图像编码、模态融合机制、统一 Transformer 架构设计,再到 ITM 与对比学习等训练目标,逐步构建了一个功能完整、结构简洁的 UMT 模型。
在实验层面,我们结合主流数据集展示了 UMT 在图文匹配与图文检索任务上的应用能力,并讨论了其向更大规模、更强泛化方向的延展潜力。通过引入模态适配器、跨模态注意力、稀疏激活与任务统一设计,UMT 不仅具备出色的性能,还为多模态 AI 模型的未来发展提供了可行性路径。
在多模态 AI 向通用人工智能(AGI)演进的背景下,统一多模态 Transformer 代表了一种具备高度兼容性与泛化能力的建模范式,值得进一步深入研究与优化落地。

- 点赞
- 收藏
- 关注作者
评论(0)