面向分布式计算的MCP与LLM协作-高效任务调度与资源管理策略探讨

面向分布式计算的MCP与LLM协作-高效任务调度与资源管理策略探讨
在人工智能领域,随着模型规模的不断扩大和任务复杂度的提升,如何高效地进行模型函数调用,特别是在并行计算和负载调度方面,成为了一个关键问题。本文将探讨MCP(Model Control Plane)与LLM(Large Language Model)函数调用之间的协作机制,并深入分析并行计算和负载调度策略,以期为高效的人工智能推理和任务调度提供一定的技术指导。
1. 引言
随着大规模预训练语言模型(LLM)如GPT-4、BERT等的广泛应用,人工智能系统面临着如何高效调度和管理大量计算资源的问题。MCP(Model Control Plane)作为一种新兴的架构模式,能够有效地在分布式计算环境中协调多个LLM函数调用,并进行合理的负载调度。通过MCP与LLM的协作,我们可以提升计算效率、降低延迟,并优化资源的使用。
2. MCP架构概述
MCP(Model Control Plane)是一个专门为控制和管理机器学习模型调用而设计的架构层。它主要负责以下几项任务:
- 资源调度:根据当前系统负载动态分配计算资源。
- 模型负载均衡:确保每个LLM实例的计算负载保持在合理范围内,避免某些计算节点过载而影响性能。
- 任务调度:确保多个并行任务的高效执行,减少等待时间。

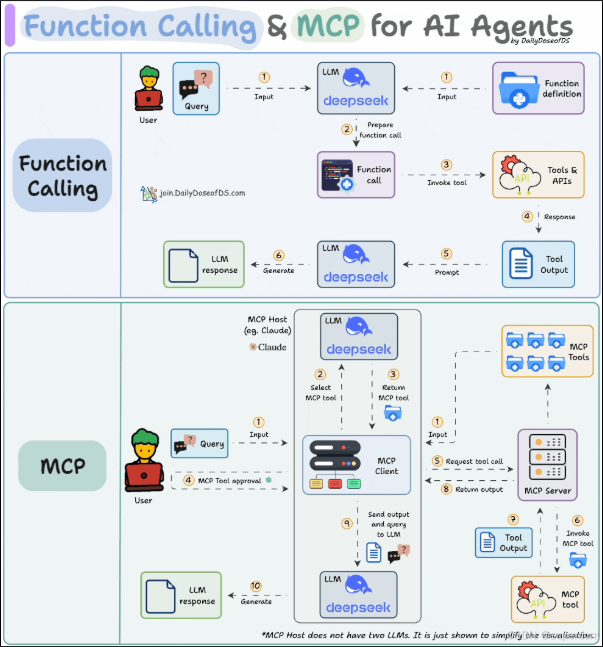
2.1 MCP的工作流程
MCP架构的工作流程可以分为以下几个主要步骤:
- 任务提交:LLM函数调用请求由应用层提交到MCP。
- 任务分配:MCP根据当前资源状态和任务的优先级进行合理的分配。
- 并行处理:MCP负责将任务分配到不同的计算节点,保证高效的并行执行。
- 结果收集与汇总:在并行计算完成后,MCP将计算结果进行汇总,并返回给请求方。
2.2 MCP的关键组件
MCP架构的关键组件包括:
- 资源管理模块:负责监控计算资源的使用情况,并动态调整资源分配策略。
- 调度策略模块:基于负载均衡算法对任务进行合理调度。
- 通信模块:负责不同计算节点之间的通信和同步,确保数据的一致性和任务的协调性。
3. LLM函数调用的挑战与优化
在大规模应用中,LLM函数调用面临着多种挑战,尤其是计算资源的分配和调度方面。LLM函数的计算量非常庞大,因此,在进行多模型并行调用时,如何有效地进行负载均衡和任务调度,是提高系统效率的关键。
3.1 LLM的计算瓶颈
LLM通常包括数十亿至数百亿的参数,这些模型往往需要大量的计算资源来完成推理任务。特别是在并行执行多个LLM调用时,以下问题常常成为性能瓶颈:
- 内存限制:每个LLM实例占用的内存非常大,当多个实例同时运行时,容易导致内存超载。
- 计算资源竞争:多个模型同时使用计算资源时,可能会出现计算资源竞争,进而导致系统性能下降。
- I/O瓶颈:在大规模数据传输和模型加载过程中,I/O性能可能成为系统的瓶颈。
3.2 负载均衡策略
为了避免上述瓶颈,MCP与LLM的协作可以采用以下负载均衡策略:
- 动态资源分配:根据每个任务的计算需求和系统负载动态分配计算资源,避免资源的过度竞争。
- 延迟最小化调度:根据任务的执行时间和优先级动态调整调度策略,保证重要任务优先执行。
- 异构计算资源:结合GPU、TPU等异构计算资源,为不同任务选择最合适的硬件平台进行处理。
4. 并行计算与任务调度
并行计算是提升大规模LLM函数调用效率的关键手段。通过合理的任务调度和并行计算策略,可以显著提高系统的吞吐量,并降低计算时间。
4.1 并行计算的基本策略
并行计算的基本策略主要包括:
- 数据并行:将数据划分为多个小批次,分别传输到不同的计算节点进行处理。
- 模型并行:将一个大模型拆分成多个小模块,分布在不同的计算节点上进行计算。
- 混合并行:结合数据并行和模型并行的优点,同时对数据和模型进行分割,最大化计算资源的利用率。
4.2 任务调度算法
任务调度是影响并行计算效率的核心因素。MCP可以采用以下几种常见的调度算法来优化任务执行:
- 轮询调度(Round Robin):简单的任务调度方式,适用于计算负载较均衡的场景。
- 优先级调度(Priority Scheduling):根据任务的优先级动态调整调度顺序,确保高优先级任务的及时执行。
- 负载感知调度(Load-aware Scheduling):根据系统负载和任务计算量进行动态调整,避免过载节点。
4.3 代码示例:基于Python的MCP负载调度实现
以下是一个简单的Python示例,演示如何在MCP架构中实现LLM函数调用的并行计算和负载调度。
import concurrent.futures
import time
import random
# 模拟LLM函数调用
def llm_function(task_id):
print(f"任务 {task_id} 开始执行...")
processing_time = random.uniform(1, 3) # 随机生成任务处理时间
time.sleep(processing_time)
print(f"任务 {task_id} 执行完毕,耗时 {processing_time:.2f}秒")
return task_id, processing_time
# MCP负载调度
def mcp_load_balancer(tasks):
with concurrent.futures.ThreadPoolExecutor(max_workers=4) as executor:
futures = {executor.submit(llm_function, task): task for task in tasks}
results = []
for future in concurrent.futures.as_completed(futures):
task_id, processing_time = future.result()
results.append((task_id, processing_time))
print(f"任务 {task_id} 处理时间: {processing_time:.2f}秒")
return results
if __name__ == "__main__":
tasks = [1, 2, 3, 4, 5, 6] # 任务列表
print("MCP 开始任务调度...")
results = mcp_load_balancer(tasks)
print("\n所有任务执行完毕。")
for task_id, processing_time in results:
print(f"任务 {task_id} 总耗时: {processing_time:.2f}秒")
4.4 代码解析
在这个示例中,我们使用concurrent.futures.ThreadPoolExecutor来模拟MCP中的并行计算任务调度。每个任务模拟一个LLM函数调用,任务的执行时间是随机生成的,模拟了计算资源的负载情况。通过合理的调度和资源分配,我们可以有效地控制任务的执行顺序,并优化整体性能。
5. 高效调度策略的实践与挑战
尽管MCP与LLM的协作能够显著提高系统的性能,但在实际应用中,调度和负载均衡依然面临一些复杂的挑战。本文将进一步探讨高效调度策略的实践,尤其是在大规模分布式计算和多任务并行执行中,如何平衡任务的调度优先级、资源分配和系统容错。
5.1 动态负载预测与调度
在大规模分布式系统中,任务负载的动态变化要求调度算法具备实时预测能力。通过机器学习和大数据分析,MCP可以通过历史任务的执行数据和当前资源负载,预测未来任务的资源需求,从而做出更加精准的调度决策。
5.1.1 负载预测模型
负载预测模型通常利用历史任务执行的数据,如任务执行时间、资源使用率、任务的输入数据规模等,来进行任务的资源需求预测。常用的方法包括:
- 回归分析:利用历史数据来预测任务的执行时间和所需资源。
- 时间序列分析:通过对历史负载数据的趋势进行分析,预测未来负载。
- 机器学习模型:通过训练一个回归模型(如随机森林、神经网络等)来预测任务负载。
例如,使用一个基于线性回归的简单模型来预测任务的计算需求:
from sklearn.linear_model import LinearRegression
import numpy as np
import matplotlib.pyplot as plt
# 模拟的历史数据:任务大小与计算时间
task_sizes = np.array([1, 2, 3, 4, 5]).reshape(-1, 1) # 任务大小
compute_times = np.array([1.2, 2.3, 3.1, 4.0, 5.2]) # 任务计算时间
# 创建线性回归模型
model = LinearRegression()
model.fit(task_sizes, compute_times)
# 预测新的任务计算时间
new_task_size = np.array([[6]])
predicted_time = model.predict(new_task_size)
print(f"预计任务大小为 6 时的计算时间为: {predicted_time[0]:.2f}秒")
# 绘制历史数据与预测结果
plt.scatter(task_sizes, compute_times, color='blue')
plt.plot(task_sizes, model.predict(task_sizes), color='red')
plt.xlabel('任务大小')
plt.ylabel('计算时间')
plt.show()
5.1.2 动态调度决策
基于负载预测,MCP可以动态调整调度策略。例如,若预测到某一节点将面临高负载,系统可以提前将任务分配到资源较为闲置的节点,避免计算瓶颈的发生。通过引入这种预测模型,MCP能够提高任务调度的灵活性和响应性,从而提升整个系统的性能。
5.2 异常处理与容错机制
在大规模分布式系统中,容错性至关重要。任务的失败、计算节点的故障、网络延迟等因素都可能导致整个系统的崩溃或性能大幅下降。为了确保系统的高可用性,MCP需要设计健壮的异常处理和容错机制,确保任务能够在出现故障时顺利执行。
5.2.1 自动任务重调度
当一个任务由于节点故障或其他原因执行失败时,MCP应当能够自动识别失败的任务,并将其重新调度到健康的节点上。这一过程需要保证任务的最小化中断,并尽量降低重调度带来的延迟。
以下是一个简单的重调度示例,其中假设任务在某些计算节点失败时,MCP会自动将任务转移到其他节点进行执行:
import random
def task_execution(task_id, node_id):
success = random.choice([True, False]) # 模拟任务成功或失败
if not success:
print(f"任务 {task_id} 在节点 {node_id} 执行失败,正在重调度...")
return False
print(f"任务 {task_id} 在节点 {node_id} 执行成功!")
return True
def mcp_with_fault_tolerance(tasks, nodes):
for task_id in tasks:
success = False
# 在多个节点之间重调度任务
while not success:
node_id = random.choice(nodes)
success = task_execution(task_id, node_id)
if not success:
print(f"尝试在节点 {node_id} 执行失败,继续重调度...\n")
print(f"任务 {task_id} 最终执行成功!")
# 任务与节点配置
tasks = [1, 2, 3, 4, 5]
nodes = ['Node1', 'Node2', 'Node3']
mcp_with_fault_tolerance(tasks, nodes)
5.2.2 容错策略的优化
对于计算任务失败的容错机制,还可以考虑以下优化策略:
- 任务副本机制:在多个节点上同时启动任务副本,确保某一副本失败时,其他副本可以继续执行任务。
- 数据备份:通过在计算任务执行前对输入数据进行备份,确保在任务失败时不会丢失重要数据。
- 延迟容忍:允许系统在短时间内容忍计算延迟,避免因任务调度过于频繁而引起的系统资源浪费。
6. MCP与LLM协作的前景
随着人工智能和大规模语言模型的应用不断发展,MCP与LLM之间的协作将越来越重要。未来,MCP不仅能够管理计算资源,还能够引导LLM模型自我优化和调度任务,从而进一步提高系统效率和自适应能力。
6.1 自适应任务调度
随着LLM模型规模的不断扩大,任务调度的复杂性也在增加。未来的MCP可能会结合智能调度算法,使其能够自动适应不同的计算需求。例如,通过强化学习等技术,MCP可以根据历史经验学习并调整调度策略,从而不断优化计算资源的分配。
6.2 资源共享与协同计算
在多任务协作的环境下,MCP与LLM的协作将不仅限于单一任务的调度,还将扩展到任务间的协同计算。通过资源共享和多任务并行处理,系统将能够更高效地完成多个LLM的联合推理任务,为更复杂的应用场景(如多模态学习、联邦学习等)提供支持。
7. 结语
MCP与LLM的协作为大规模语言模型的高效执行提供了强有力的支持。通过优化负载调度和任务调度策略,能够显著提升系统的计算性能和资源利用率。尽管仍面临一些挑战,如任务调度复杂性、容错性、资源共享等问题,但随着技术的不断发展,未来的MCP与LLM协作将更加智能化、高效化,为人工智能应用的扩展和普及提供坚实的基础。

- 点赞
- 收藏
- 关注作者
评论(0)