少样本与零样本学习的新支撑—自监督机制的理论基础与实战

少样本与零样本学习的新支撑—自监督机制的理论基础与实战
深度学习已经从最初的多层感知器(MLP)发展出复杂的神经网络体系,如卷积神经网络(CNN)、循环神经网络(RNN)乃至Transformer架构。但近年来,自监督学习(Self-Supervised Learning, SSL) 正逐渐成为推动深度学习前沿的新范式。本文将系统回顾从基础网络演进到自监督学习的过程,并通过代码实例展示核心思想。
一、从感知器到深度网络:基础构建回顾
1.1 多层感知器的起点
早期的神经网络以MLP为主,适合处理结构简单的数据,如表格和手写数字识别。
import torch
import torch.nn as nn
class SimpleMLP(nn.Module):
def __init__(self):
super(SimpleMLP, self).__init__()
self.fc = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
def forward(self, x):
return self.fc(x.view(-1, 784))
1.2 CNN的崛起与视觉智能
CNN极大地提升了图像识别能力,引入了局部感受野、权重共享和池化层等概念。
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 16, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(16, 32, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.fc = nn.Linear(32 * 7 * 7, 10)
def forward(self, x):
x = self.conv(x)
return self.fc(x.view(x.size(0), -1))
二、迁移学习与预训练:大模型时代的序章
2.1 为什么迁移学习重要
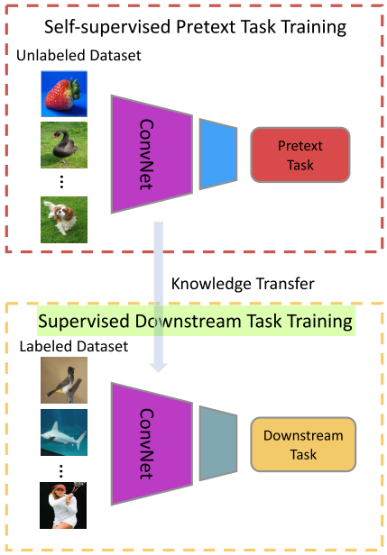
迁移学习让模型在大数据集(如ImageNet)上预训练,再微调到小数据集任务上,大幅降低训练时间和数据需求。
from torchvision import models
model = models.resnet18(pretrained=True)
for param in model.parameters():
param.requires_grad = False
model.fc = nn.Linear(model.fc.in_features, 2) # 假设我们是二分类任务
2.2 预训练模型的演进路径
从ResNet、VGG到Transformer系列,模型规模和复杂度不断上升,但对标注数据的依赖也日益加剧。
三、自监督学习:深度学习的新动力
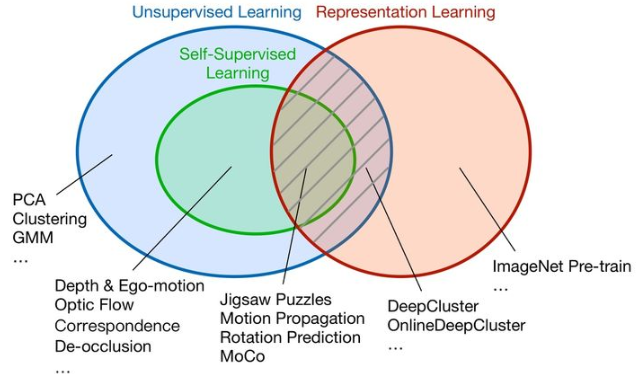
自监督学习是一种“用数据本身生成监督信号”的方式,在不依赖大量人工标注的前提下,学习通用表征。
3.1 自监督的核心思想
- 创建伪任务(pretext task)
- 利用原始数据构造标签(如图像旋转角度、遮挡区域等)
- 最后通过微调进行迁移(fine-tuning)
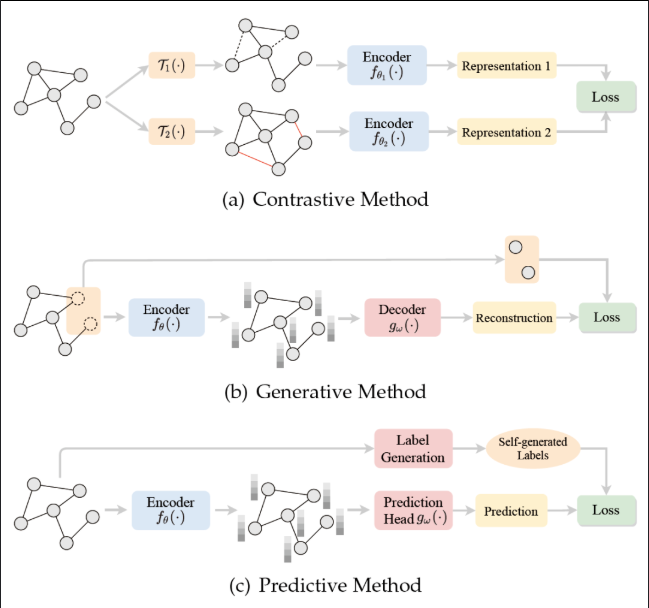
3.2 对比学习:最具代表性的自监督方法
如SimCLR、MoCo通过“拉近正样本,推远负样本”的方式学习语义特征。
import torch.nn.functional as F
def nt_xent_loss(z1, z2, temperature=0.5):
"""
z1, z2: shape (batch_size, dim)
"""
z1 = F.normalize(z1, dim=1)
z2 = F.normalize(z2, dim=1)
representations = torch.cat([z1, z2], dim=0)
similarity_matrix = torch.matmul(representations, representations.T)
# create positive mask
batch_size = z1.size(0)
labels = torch.arange(batch_size).to(z1.device)
labels = torch.cat([labels, labels], dim=0)
# remove self similarity
mask = torch.eye(batch_size * 2, dtype=torch.bool).to(z1.device)
similarity_matrix = similarity_matrix[~mask].view(batch_size * 2, -1)
positives = torch.exp(torch.sum(z1 * z2, dim=-1) / temperature)
numerator = torch.cat([positives, positives], dim=0)
denominator = torch.sum(torch.exp(similarity_matrix / temperature), dim=1)
loss = -torch.log(numerator / denominator)
return loss.mean()
四、典型自监督框架对比:SimCLR vs. MAE
4.1 SimCLR:对比学习的代表
- 基于图像增强
- 两个视角(augmented views)
- 大批量 + 大算力 + 大模型
4.2 MAE(Masked AutoEncoder):视觉BERT类思路
- 隐去图像块,预测原始图像
- 自编码器重建图像特征
- 不依赖负样本,训练更稳定
class MAE(nn.Module):
def __init__(self, encoder, decoder):
super(MAE, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, x, mask):
x_visible = x[~mask]
latent = self.encoder(x_visible)
reconstructed = self.decoder(latent)
return reconstructed
注:完整MAE需要ViT和Patch嵌入模块,示意为简化版本。
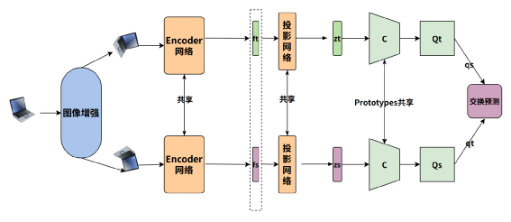
五、自监督学习的未来应用场景
5.1 多模态统一表征
如CLIP、DALL·E系列,结合图文监督,实现通用跨模态推理。
5.2 医疗影像、遥感、金融等低标注领域
自监督可最大化利用无标注数据,提升小样本任务表现。
5.3 模型可持续训练:数据驱动 vs. 标注驱动的转变
未来深度学习模型的训练更多将依赖原始大规模数据本身,而不是昂贵的人工标签。
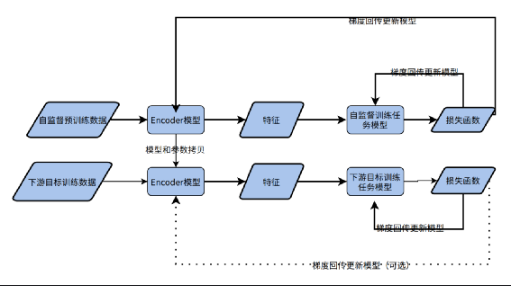
六、从结构主义到自组织智能
传统深度学习依赖人类设计网络结构与监督信号,这是典型的“结构主义”范式。虽然这在图像分类、语音识别等领域取得巨大成功,但其可扩展性和迁移能力受限。而自监督学习的兴起,代表了一种向“自组织智能”迈进的转变:机器通过理解自身所处的数据环境,实现知识的自动获取与泛化。
这种变革不只是一种训练方式的改变,更可能引领下一代人工智能系统的形态:
- 不再依赖庞大的标注集;
- 更容易迁移到多任务、多模态、多语言环境;
- 有潜力在认知科学与人类学习机制的模拟上实现突破。
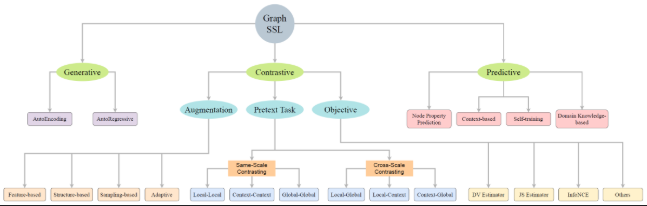
七、自监督学习的技术趋势与挑战
7.1 趋势一:结构轻量化 + 表征强泛化
未来自监督模型将趋于编码器轻量化、解码器任务敏感化,即编码器学习通用语义,解码器适配不同下游任务。
- 示例:SimMIM、BEiT 结合了Transformer编码器与遮挡重建任务。
- 代码思路如下:
# 伪代码结构:Encoder + Lightweight Decoder
class SimpleSelfSupervisedModel(nn.Module):
def __init__(self):
super().__init__()
self.encoder = models.resnet18(pretrained=False)
self.decoder = nn.Sequential(
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 784) # 重建目标,例如28x28图像
)
def forward(self, x):
latent = self.encoder(x)
out = self.decoder(latent)
return out
7.2 趋势二:统一预训练范式(图、语音、图像、文本)
随着多模态融合模型(如CLIP、BLIP、GPT-4V)成功,自监督学习的边界将不再局限于图像,而是走向统一范式:
- 视觉语言统一预训练
- 音频、文本跨模态知识迁移
- 图神经网络中的自监督结构挖掘(Graph SSL)
7.3 挑战:负样本依赖 & 表征坍塌问题
对比学习方法中一个关键问题是:
如何生成足够难、但不干扰语义的“负样本”,且避免表征在无监督训练中陷入“坍塌”状态。
解决方向:
- 使用对比缓冲区(如MoCo);
- 使用无对比架构(如BYOL、SimSiam);
- 引入多任务监督(如Masked Modeling + Contrastive Loss混合)。
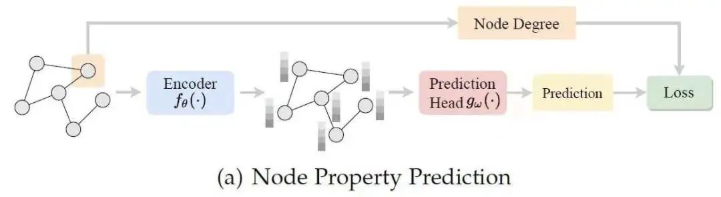
八、自监督学习的未来:预言与展望
8.1 Foundation Models:自监督为王
未来的大模型(如GPT、Gemini、Claude等)本质上都是自监督预训练 + 指令微调的结构。自监督将成为构建“通用人工智能(AGI)”的地基。
- 无监督预训练 → 通用表征
- 微调阶段 → 任务定制能力
- 强化学习 → 决策优化
8.2 少样本学习(Few-shot)与零样本学习(Zero-shot)的进化
自监督模型在构建“语义空间”方面表现出极强的迁移能力,使得模型能通过极少量的任务提示就做出准确预测。
- 如CLIP模型仅需一张图片和一句话描述,就能完成分类任务;
- GPT系列通过提示工程完成复杂任务,无需再训练。
九、结束语:深度学习的下一个十年
从基础网络到迁移学习,从监督训练到自监督演化,深度学习的道路从“人类设定规则”演变为“模型自我进化”。
在未来十年:
- 数据的价值将超过标签;
- 模型的核心在于自我理解与推理;
- AI 将不再依赖有监督规则,而是走向类人智能的路径。
我们正站在一个新纪元的入口,自监督学习不仅仅是一种技术选择,它更是一种认知范式的革新。
推荐阅读与扩展主题:
- 《SimCLR:A Simple Framework for Contrastive Learning of Visual Representations》
- 《MAE:Masked Autoencoders Are Scalable Vision Learners》
- 《BYOL:Bootstrap Your Own Latent》
- 《CLIP:Learning Transferable Visual Models From Natural Language Supervision》

- 点赞
- 收藏
- 关注作者
评论(0)