AutoML

机器学习的难题之一就是建立直觉。建立直觉的意思是采用某种工具来应对问题。 这就需要知道可用的算法、模型、风险权衡以及每一个限制条件。……困难在于机器学习基本上很难进行调试。对于机器学习来说,调试会在两种情况下发生:1)你的算法不起作用了;2)你的算法效用不是很好。…… 算法一开始就起作用的情况很少,因此我们大部分时间都在用来创建算法。
汇总就是:选择算法、超参调整、迭代建模以及模型评价。
自动化机器学的理论基础来源于这个想法:假如我们必须创建海量的机器学习模型、使用大量的算法、使用不同的超参数配置,那么我们就可以使用自动化的方式进行建模。同时也可以比较性能与准确度。
TPOT
TPOT是一种基于遗传算法优化机器学习管道(pipeline)的Python自动机器学习工具。简单来说,就是TPOT可以智能地探索数千个可能的pipeline,为数据集找到最好的pipeline,从而实现机器学习中最乏味的部分。
从下图中我们可以看到,TPOT可以自动地完成特征工作(特征选择,特征预处理,特征构建等),同时也可以进行模型的选择和参数的调优。
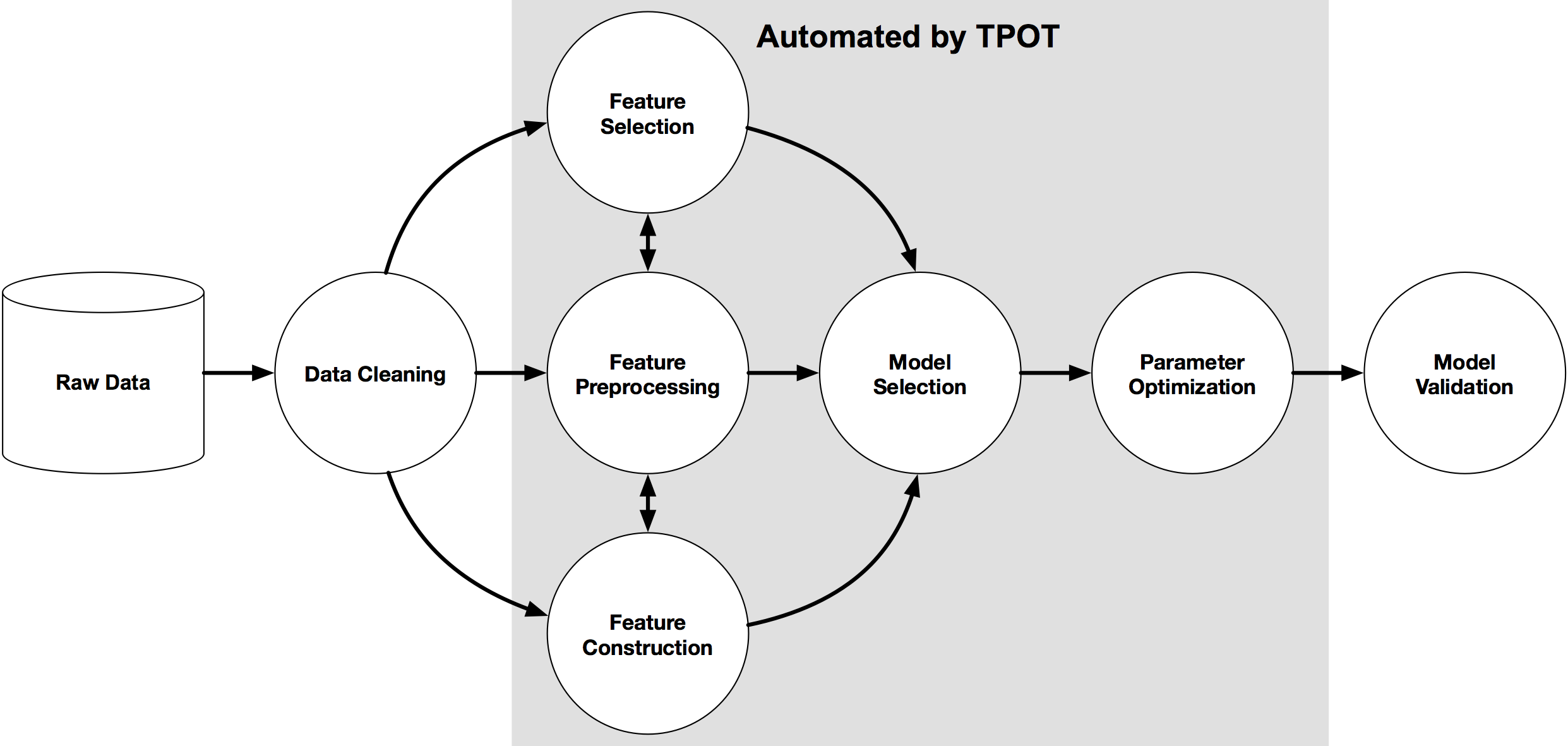
更重要地是,一旦TPOT完成搜索,TPOT同时也提供了Python代码。通过这个代码,我们可以具体地知道TPOT获得最优性能时的具体pipeline的内容,这对于后续修改是十分方便的!
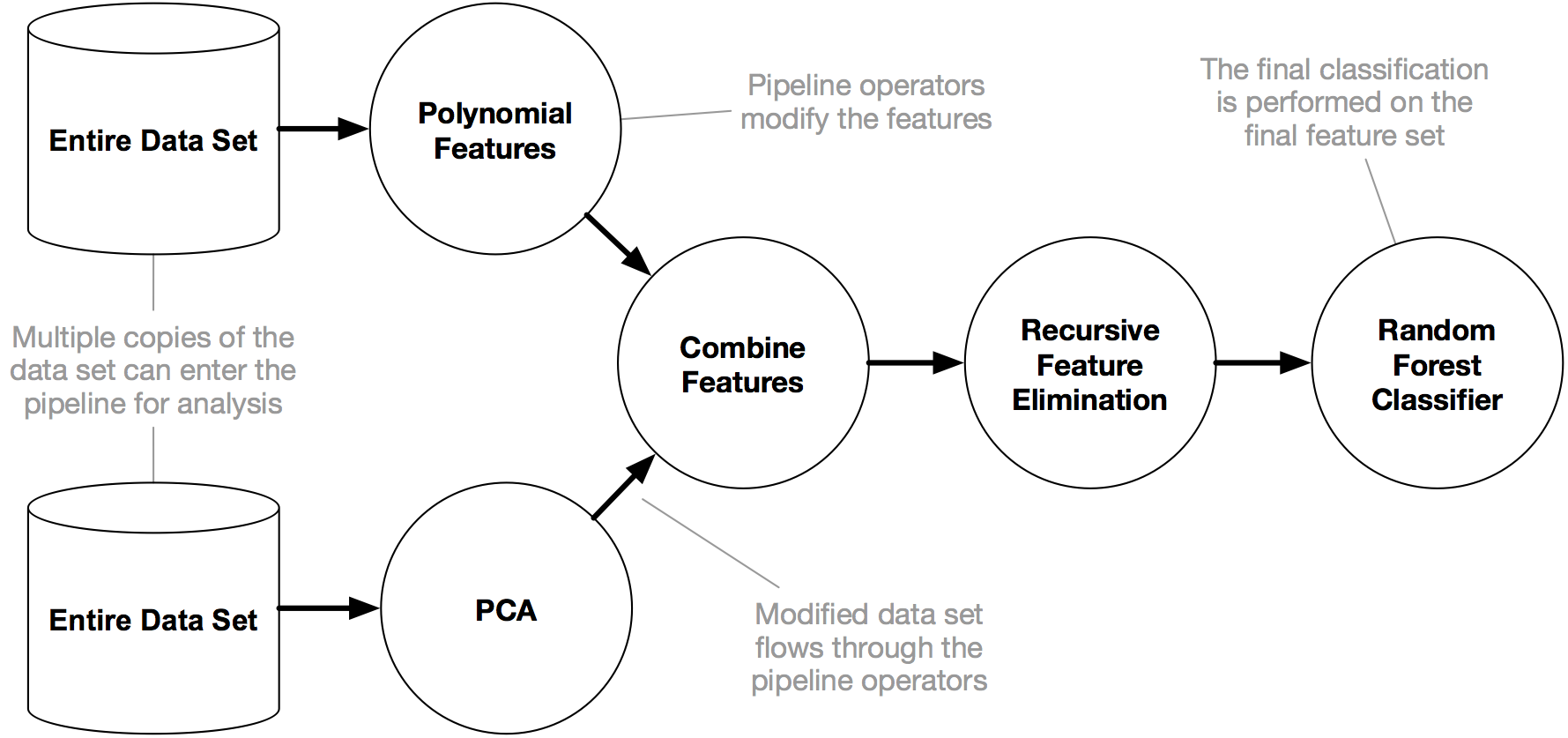
手写体识别示例:
from tpot import TPOTClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target,
train_size=0.75, test_size=0.25, random_state=42)
tpot = TPOTClassifier(generations=5, population_size=50, verbosity=2, random_state=42)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_digits_pipeline.py')
其中,主要的分类器 TPOTClassifier / TPOTRegressor:
class tpot.TPOTClassifier(generations=100, population_size=100,
offspring_size=None, mutation_rate=0.9,
crossover_rate=0.1,
scoring='accuracy', cv=5,
subsample=1.0, n_jobs=1,
max_time_mins=None, max_eval_time_mins=5,
random_state=None, config_dict=None,
template=None,
warm_start=False,
memory=None,
use_dask=False,
periodic_checkpoint_folder=None,
early_stop=None,
verbosity=0,
disable_update_check=False,
log_file=None
)
常用参数解释:
-
generations=5,这是迭代次数,按理说,大一点,效果好,时间长
TPOT will evaluate population_size + generations * offspring_size pipelines in total.
-
population_size=20,每一次的子代数,按理说,同上
-
verbosity
0,TPOT将不打印任何内容,
1,TPOT将打印最少的信息,
2,TPOT将打印更多信息并提供进度条,或者
3,TPOT将打印所有内容并提供进度条。 -
random_state,伪随机数生成器的种子
-
early_stop
-
config_dict,用于定制TPOT在优化过程中搜索的操作符和参数的配置字典
-
n_jobs: integer, optional (default=1),启动的进程数量
- n_jobs=-1: CPUs
- n_jobs=-2: CPUs-1
内置的运算符(算法)和参数
自定义TPOT的运算符(算法)和参数
除了TPOT附带的默认配置之外,在某些情况下,限制TPOT考虑的算法和参数很有用。因此,我们允许用户为TPOT提供其操作员和参数的自定义配置。
定制TPOT配置必须采用嵌套字典格式,其中第一级密钥是运算符的路径和名称(例如sklearn.naive_bayes.MultinomialNB),第二级密钥是该运算符的相应参数名称(例如fit_prior)。第二级键应指向该参数的参数值列表,例如’fit_prior’: [True, False]。
例如:
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target,
train_size=0.75, test_size=0.25)
tpot_config = {
'sklearn.naive_bayes.GaussianNB': {
},
'sklearn.naive_bayes.BernoulliNB': {
'alpha': [1e-3, 1e-2, 1e-1, 1., 10., 100.],
'fit_prior': [True, False]
},
'sklearn.naive_bayes.MultinomialNB': {
'alpha': [1e-3, 1e-2, 1e-1, 1., 10., 100.],
'fit_prior': [True, False]
}
}
tpot = TPOTClassifier(generations=5, population_size=20, verbosity=2,
config_dict=tpot_config)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_digits_pipeline.py')
Neural Networks in TPOT
对神经网络模型和深度学习的支持是新添加到 TPOT 的实验性功能。该tpot.nn模块提供了可用的神经网络架构。与常规sklearn估计器不同的是,这些模型需要手工编写,并且还必须继承其sklearn所有内置模块提供的适当基类。换句话说,他们需要实现诸如.fit()、fit_transform()、get_params()等方法。
Auto-sklearn
基于贝叶斯算法
AutoKeras
AutoKeras采用了退火算法实现了开发和探索,采用了高斯过程回归预估更优秀的网络结构。

- 点赞
- 收藏
- 关注作者
评论(0)