基于PyTorch实现YOLOv11模型的训练和推理

TL;DR
本文章主要介绍YOLOv11目标检测模型的训练和推理。抛弃了集成度较高的ultralytics工具包,用PyTorch实现了YOLOv11的网络结构,以及在COCO数据集上进行训练和测试,便于开发者学习YOLO的原理细节。
- 参考代码:YOLOv11 re-implementation using PyTorch
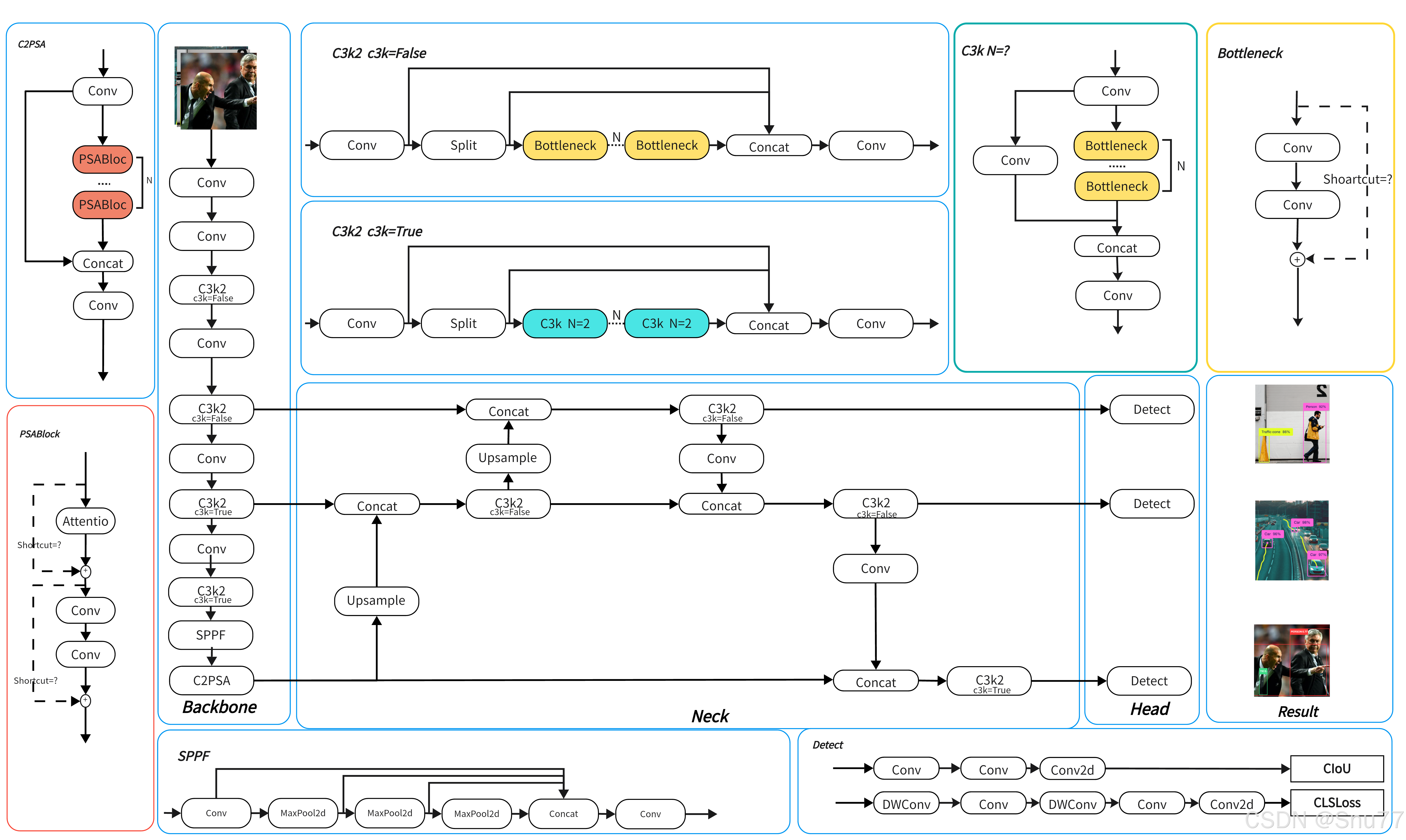
- 相比YOLOv8改进点:①改进backbone和neck的结构,增强特征提取能力,e.g. 将C2f改变为C3k2,在SPPF后面追加C2PSA机制;②分类检测头增加两个DW卷积,降低参数量&提高推理速度;③相比YOLOv8参数量减少22%,同时COCO数据集上实现更高的mAP。
一、准备开发环境
本实验需要“Python3.9+PyTorch2.0”环境,GPU规格P100以上。先注册ModelArts镜像,然后用该镜像创建一个notebook开发环境。
1.1. 注册ModelArts镜像
- 点击进入ModelArts控制台>>资产管理>>镜像管理,进入“镜像管理”页面后,右上角注册镜像:
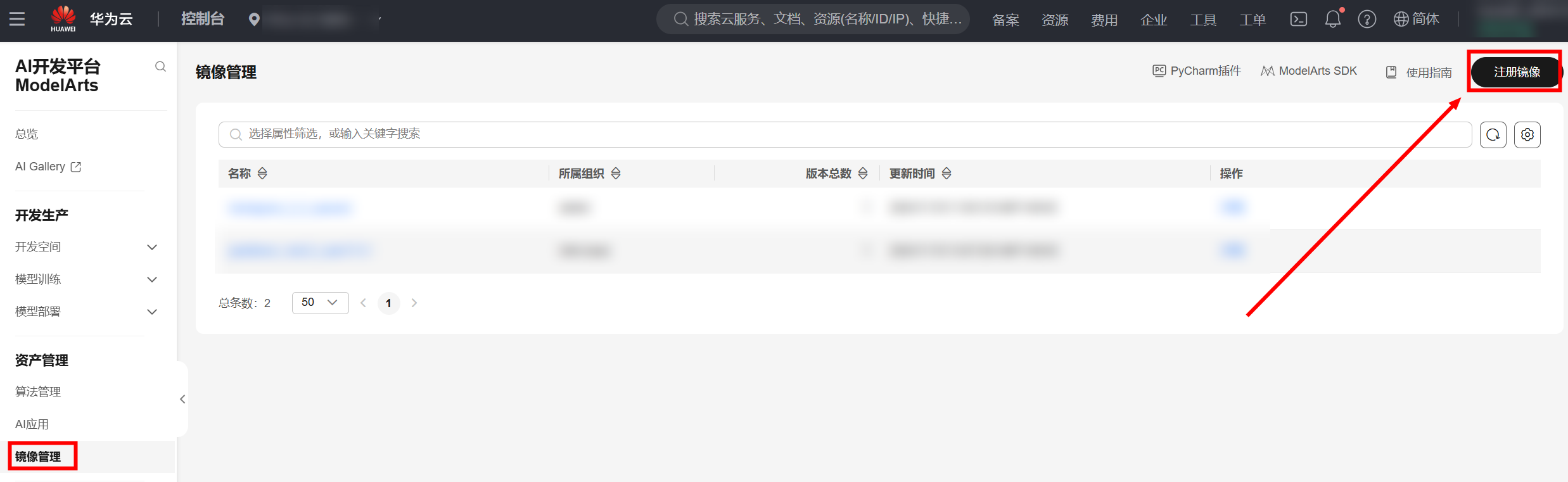
-
在注册镜像页面,按照如下参数进行配置:
镜像源:
swr.cn-north-4.myhuaweicloud.com/atelier/pytorch_2_0:pytorch_2.0.0-cuda_11.7-py_3.9.11-ubuntu_20.04-x86_64-20230727142019-7d74011
架构:x86_64
类型:CPU和GPU
参考下图配置参数:
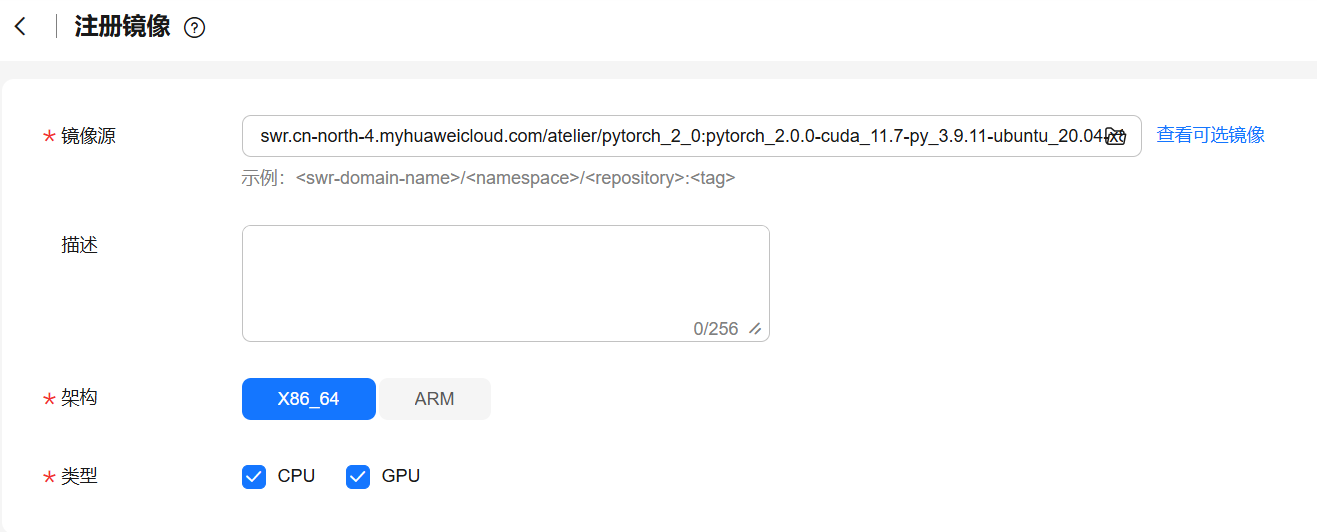
- 点击“立即注册”,等待注册成功后,可使用“自定义镜像”创建notebook。
1.2. 创建notebook
- 点击进入ModelArts的开发环境,右上角创建Notebook:
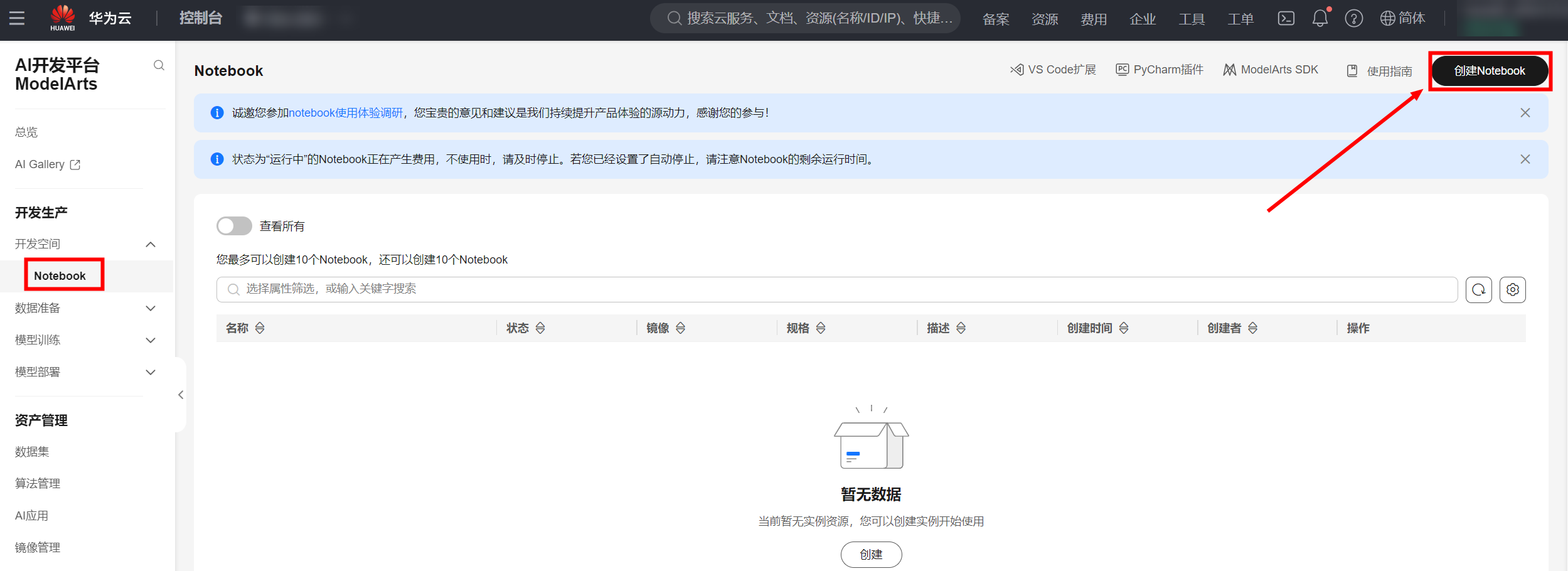
- 在创建Notebook页面,按照如下参数进行配置
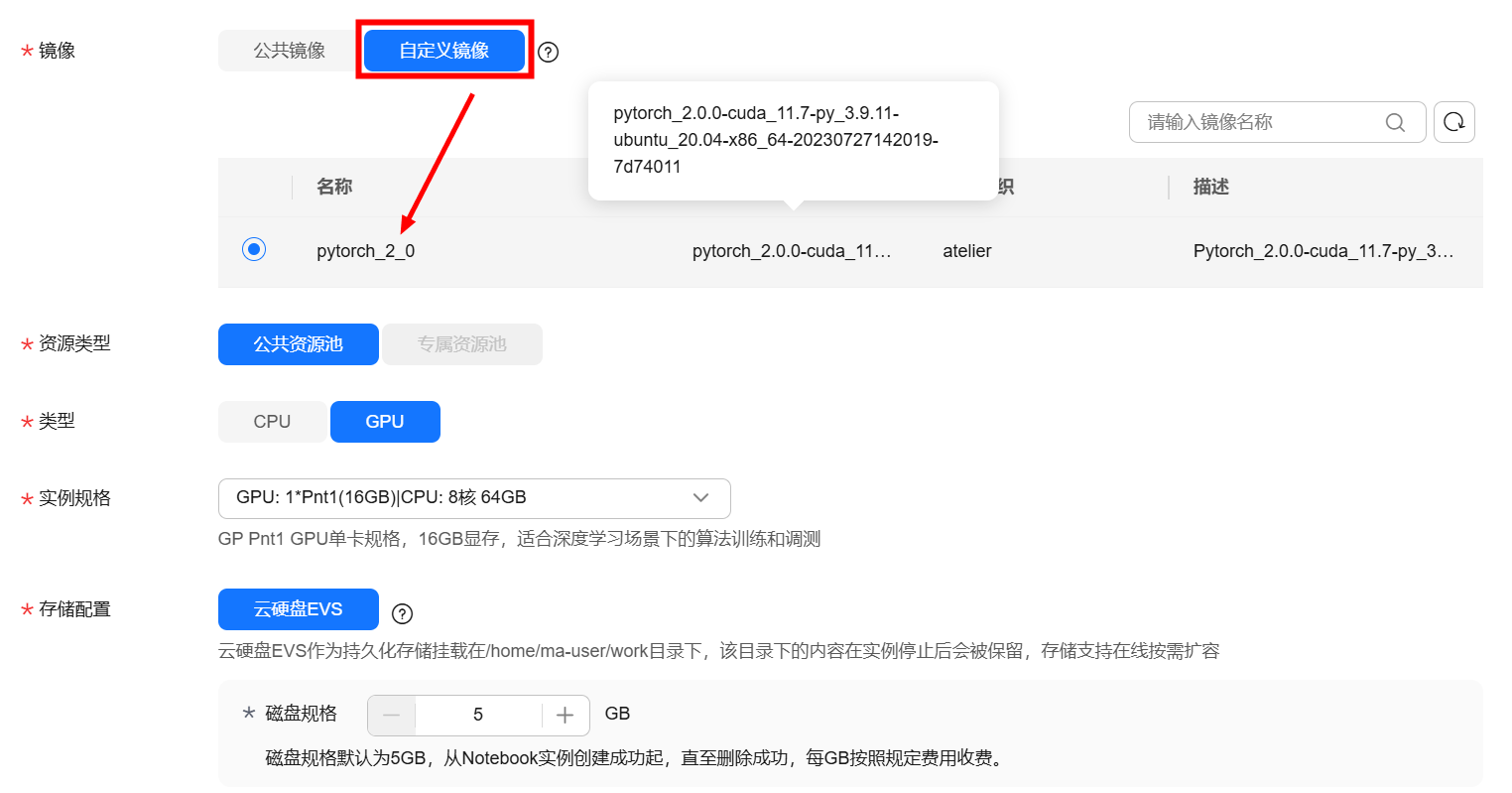
名称:notebook-yolov11(可自定义)
自动停止:开启,1小时
镜像:“自定义镜像”,选择“pytorch_2_0”
资源类型:公共资源池
类型:GPU
规格:GPU: 1*Pnt1(16GB)|CPU: 8核 64GB(可按需选择算力规格)
存储配置:云硬盘EVS,5G(可按需设定合适的磁盘规格)
SSH远程开发:不开启
点击“立即创建”,确认产品规格后点击“提交”,并返回。
注意:Notebook创建完毕后,存储会持续产生少量费用(无论是否运行),代金券使用场景覆盖存储。
注意:可以选择将数据都放在 /cache目录下,这样不会占用EVS空间,但 /cache目录会在每次启动时刷新。如果想要持久化存储,可以对EVS扩容,同时将文件移动至 /home/ma-user/work目录下。
- 等待Notebook创建完成
提交产品规格并返回,此时,notebook正在创建中,创建时长大约1分钟。

待notebook状态变为“运行中”,点击该notebook实例右侧“打开”,即可进入到notebook环境中。

- 打开一个notebook代码开发界面
左上角点击“+”号,点击Notebook进行创建,双击下方新的Untitled.ipynb文件,弹出代码开发界面,如下图:
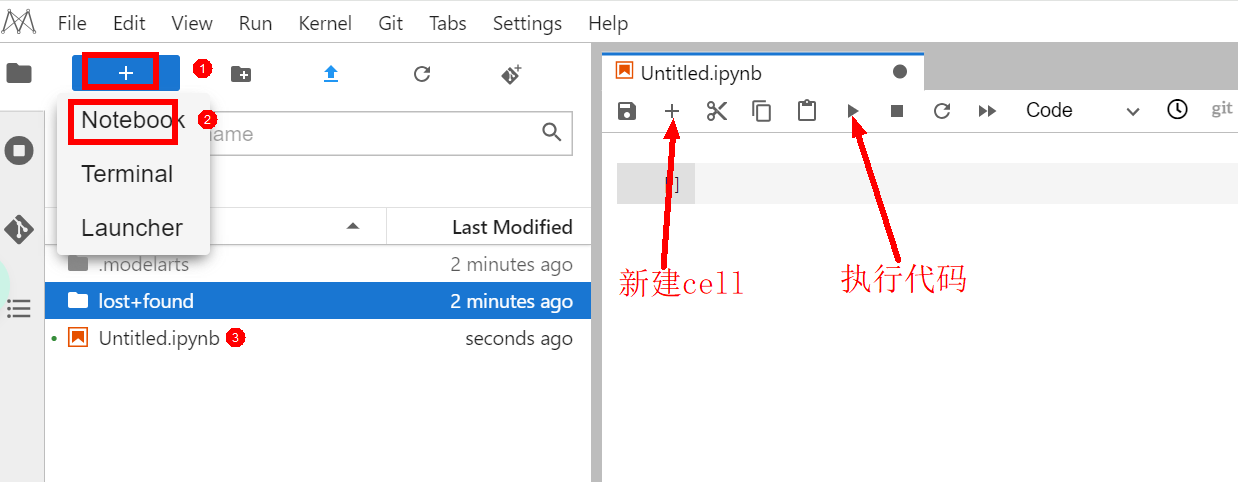
至此,我们已经拥有一个带GPU算力的notebook开发环境。
二、准备数据集
2.1. 下载COCO数据集
- ModelScope数据集:PAI/COCO2017。安装modelscope工具包后,下载至notebook即可。
- COCO8数据集(可简单验证代码):https://github.com/ultralytics/assets/releases/download/v0.0.0/coco8.zip
2.2. 数据集预处理
下载的COCO数据集,需要解压并转换为YOLO格式:
datasets/mini-coco
├── images
│ ├── train2017
│ │ ├── 000000000009.jpg
│ │ ├── 000000000025.jpg
│ ├── val2017
│ ├── 000000000036.jpg
│ ├── 000000000042.jpg
├── labels
│ ├── train2017
│ │ ├── 000000000009.txt
│ │ ├── 000000000025.txt
│ └── val2017
│ ├── 000000000036.txt
│ ├── 000000000042.txt
├── train2017.txt
└── val2017.txt
- 其中,
train2017.txt和val2017.txt分别是训练和验证的图片路径清单。
三、准备核心代码
- 核心代码包括配置文件,数据集加载文件,YOLOv11网络定义文件,以及一些功能函数,其目录结构如下:
/home/ma-user/work/YOLOv11-pt
├── main.py # 主函数
├── nets
│ └── nn.py # YOLOv11网络搭建
├── utils
│ ├── args.yaml # 配置文件
│ ├── dataset.py # 数据集加载
│ └── util.py # 一些功能函数
- 按照上述目录结构,新建nets和utils目录:
!mkdir nets
!mkdir utils
3.1. 配置文件
- 一些训练超参数,以及COCO数据集类别和id的映射。
%%writefile utils/args.yaml
min_lr: 0.000100000000 # initial learning rate
max_lr: 0.010000000000 # maximum learning rate
momentum: 0.9370000000 # SGD momentum/Adam beta1
weight_decay: 0.000500 # optimizer weight decay
warmup_epochs: 3.00000 # warmup epochs
box: 7.500000000000000 # box loss gain
cls: 0.500000000000000 # cls loss gain
dfl: 1.500000000000000 # dfl loss gain
hsv_h: 0.0150000000000 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7000000000000 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4000000000000 # image HSV-Value augmentation (fraction)
degrees: 0.00000000000 # image rotation (+/- deg)
translate: 0.100000000 # image translation (+/- fraction)
scale: 0.5000000000000 # image scale (+/- gain)
shear: 0.0000000000000 # image shear (+/- deg)
flip_ud: 0.00000000000 # image flip up-down (probability)
flip_lr: 0.50000000000 # image flip left-right (probability)
mosaic: 1.000000000000 # image mosaic (probability)
mix_up: 0.000000000000 # image mix-up (probability)
names:
0: person
1: bicycle
2: car
3: motorcycle
4: airplane
5: bus
6: train
7: truck
8: boat
9: traffic light
10: fire hydrant
11: stop sign
12: parking meter
13: bench
14: bird
15: cat
16: dog
17: horse
18: sheep
19: cow
20: elephant
21: bear
22: zebra
23: giraffe
24: backpack
25: umbrella
26: handbag
27: tie
28: suitcase
29: frisbee
30: skis
31: snowboard
32: sports ball
33: kite
34: baseball bat
35: baseball glove
36: skateboard
37: surfboard
38: tennis racket
39: bottle
40: wine glass
41: cup
42: fork
43: knife
44: spoon
45: bowl
46: banana
47: apple
48: sandwich
49: orange
50: broccoli
51: carrot
52: hot dog
53: pizza
54: donut
55: cake
56: chair
57: couch
58: potted plant
59: bed
60: dining table
61: toilet
62: tv
63: laptop
64: mouse
65: remote
66: keyboard
67: cell phone
68: microwave
69: oven
70: toaster
71: sink
72: refrigerator
73: book
74: clock
75: vase
76: scissors
77: teddy bear
78: hair drier
79: toothbrush
3.2. 数据集加载
- 读取YOLO格式的数据,以及训练数据增强函数等。
%%writefile utils/dataset.py
import math
import os
import random
import cv2
import numpy
import torch
from PIL import Image
from torch.utils import data
FORMATS = "bmp", "dng", "jpeg", "jpg", "mpo", "png", "tif", "tiff", "webp"
class Dataset(data.Dataset):
def __init__(self, filenames, input_size, params, augment):
self.params = params
self.mosaic = augment
self.augment = augment
self.input_size = input_size
# Read labels
labels = self.load_label(filenames)
self.labels = list(labels.values())
self.filenames = list(labels.keys()) # update
self.n = len(self.filenames) # number of samples
self.indices = range(self.n)
# Albumentations (optional, only used if package is installed)
self.albumentations = Albumentations()
def __getitem__(self, index):
index = self.indices[index]
if self.mosaic and random.random() < self.params["mosaic"]:
# Load MOSAIC
image, label = self.load_mosaic(index, self.params)
# MixUp augmentation
if random.random() < self.params["mix_up"]:
index = random.choice(self.indices)
mix_image1, mix_label1 = image, label
mix_image2, mix_label2 = self.load_mosaic(index, self.params)
image, label = mix_up(mix_image1, mix_label1, mix_image2, mix_label2)
else:
# Load image
image, shape = self.load_image(index)
h, w = image.shape[:2]
# Resize
image, ratio, pad = resize(image, self.input_size, self.augment)
label = self.labels[index].copy()
if label.size:
label[:, 1:] = wh2xy(label[:, 1:], ratio[0] * w, ratio[1] * h, pad[0], pad[1])
if self.augment:
image, label = random_perspective(image, label, self.params)
nl = len(label) # number of labels
h, w = image.shape[:2]
cls = label[:, 0:1]
box = label[:, 1:5]
box = xy2wh(box, w, h)
if self.augment:
# Albumentations
image, box, cls = self.albumentations(image, box, cls)
nl = len(box) # update after albumentations
# HSV color-space
augment_hsv(image, self.params)
# Flip up-down
if random.random() < self.params["flip_ud"]:
image = numpy.flipud(image)
if nl:
box[:, 1] = 1 - box[:, 1]
# Flip left-right
if random.random() < self.params["flip_lr"]:
image = numpy.fliplr(image)
if nl:
box[:, 0] = 1 - box[:, 0]
target_cls = torch.zeros((nl, 1))
target_box = torch.zeros((nl, 4))
if nl:
target_cls = torch.from_numpy(cls)
target_box = torch.from_numpy(box)
# Convert HWC to CHW, BGR to RGB
sample = image.transpose((2, 0, 1))[::-1]
sample = numpy.ascontiguousarray(sample)
return torch.from_numpy(sample), target_cls, target_box, torch.zeros(nl)
def __len__(self):
return len(self.filenames)
def load_image(self, i):
image = cv2.imread(self.filenames[i])
h, w = image.shape[:2]
r = self.input_size / max(h, w)
if r != 1:
image = cv2.resize(image,
dsize=(int(w * r), int(h * r)),
interpolation=resample() if self.augment else cv2.INTER_LINEAR)
return image, (h, w)
def load_mosaic(self, index, params):
label4 = []
border = [-self.input_size // 2, -self.input_size // 2]
image4 = numpy.full((self.input_size * 2, self.input_size * 2, 3), 0, dtype=numpy.uint8)
y1a, y2a, x1a, x2a, y1b, y2b, x1b, x2b = (None, None, None, None, None, None, None, None)
xc = int(random.uniform(-border[0], 2 * self.input_size + border[1]))
yc = int(random.uniform(-border[0], 2 * self.input_size + border[1]))
indices = [index] + random.choices(self.indices, k=3)
random.shuffle(indices)
for i, index in enumerate(indices):
# Load image
image, _ = self.load_image(index)
shape = image.shape
if i == 0: # top left
x1a = max(xc - shape[1], 0)
y1a = max(yc - shape[0], 0)
x2a = xc
y2a = yc
x1b = shape[1] - (x2a - x1a)
y1b = shape[0] - (y2a - y1a)
x2b = shape[1]
y2b = shape[0]
if i == 1: # top right
x1a = xc
y1a = max(yc - shape[0], 0)
x2a = min(xc + shape[1], self.input_size * 2)
y2a = yc
x1b = 0
y1b = shape[0] - (y2a - y1a)
x2b = min(shape[1], x2a - x1a)
y2b = shape[0]
if i == 2: # bottom left
x1a = max(xc - shape[1], 0)
y1a = yc
x2a = xc
y2a = min(self.input_size * 2, yc + shape[0])
x1b = shape[1] - (x2a - x1a)
y1b = 0
x2b = shape[1]
y2b = min(y2a - y1a, shape[0])
if i == 3: # bottom right
x1a = xc
y1a = yc
x2a = min(xc + shape[1], self.input_size * 2)
y2a = min(self.input_size * 2, yc + shape[0])
x1b = 0
y1b = 0
x2b = min(shape[1], x2a - x1a)
y2b = min(y2a - y1a, shape[0])
pad_w = x1a - x1b
pad_h = y1a - y1b
image4[y1a:y2a, x1a:x2a] = image[y1b:y2b, x1b:x2b]
# Labels
label = self.labels[index].copy()
if len(label):
label[:, 1:] = wh2xy(label[:, 1:], shape[1], shape[0], pad_w, pad_h)
label4.append(label)
# Concat/clip labels
label4 = numpy.concatenate(label4, 0)
for x in label4[:, 1:]:
numpy.clip(x, 0, 2 * self.input_size, out=x)
# Augment
image4, label4 = random_perspective(image4, label4, params, border)
return image4, label4
@staticmethod
def collate_fn(batch):
samples, cls, box, indices = zip(*batch)
cls = torch.cat(cls, dim=0)
box = torch.cat(box, dim=0)
new_indices = list(indices)
for i in range(len(indices)):
new_indices[i] += i
indices = torch.cat(new_indices, dim=0)
targets = {"cls": cls,
"box": box,
"idx": indices}
return torch.stack(samples, dim=0), targets
@staticmethod
def load_label(filenames):
path = f"{os.path.dirname(filenames[0])}.cache"
if os.path.exists(path):
return torch.load(path)
x = {}
for filename in filenames:
try:
# verify images
with open(filename, "rb") as f:
image = Image.open(f)
image.verify() # PIL verify
shape = image.size # image size
assert (shape[0] > 9) & (shape[1] > 9), f"image size {shape} <10 pixels"
assert image.format.lower() in FORMATS, f"invalid image format {image.format}"
# verify labels
a = f"{os.sep}images{os.sep}"
b = f"{os.sep}labels{os.sep}"
if os.path.isfile(b.join(filename.rsplit(a, 1)).rsplit(".", 1)[0] + ".txt"):
with open(b.join(filename.rsplit(a, 1)).rsplit(".", 1)[0] + ".txt") as f:
label = [x.split() for x in f.read().strip().splitlines() if len(x)]
label = numpy.array(label, dtype=numpy.float32)
nl = len(label)
if nl:
assert (label >= 0).all()
assert label.shape[1] == 5
assert (label[:, 1:] <= 1).all()
_, i = numpy.unique(label, axis=0, return_index=True)
if len(i) < nl: # duplicate row check
label = label[i] # remove duplicates
else:
label = numpy.zeros((0, 5), dtype=numpy.float32)
else:
label = numpy.zeros((0, 5), dtype=numpy.float32)
except FileNotFoundError:
label = numpy.zeros((0, 5), dtype=numpy.float32)
except AssertionError:
continue
x[filename] = label
torch.save(x, path)
return x
def wh2xy(x, w=640, h=640, pad_w=0, pad_h=0):
# Convert nx4 boxes
# from [x, y, w, h] normalized to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
y = numpy.copy(x)
y[:, 0] = w * (x[:, 0] - x[:, 2] / 2) + pad_w # top left x
y[:, 1] = h * (x[:, 1] - x[:, 3] / 2) + pad_h # top left y
y[:, 2] = w * (x[:, 0] + x[:, 2] / 2) + pad_w # bottom right x
y[:, 3] = h * (x[:, 1] + x[:, 3] / 2) + pad_h # bottom right y
return y
def xy2wh(x, w, h):
# warning: inplace clip
x[:, [0, 2]] = x[:, [0, 2]].clip(0, w - 1E-3) # x1, x2
x[:, [1, 3]] = x[:, [1, 3]].clip(0, h - 1E-3) # y1, y2
# Convert nx4 boxes
# from [x1, y1, x2, y2] to [x, y, w, h] normalized where xy1=top-left, xy2=bottom-right
y = numpy.copy(x)
y[:, 0] = ((x[:, 0] + x[:, 2]) / 2) / w # x center
y[:, 1] = ((x[:, 1] + x[:, 3]) / 2) / h # y center
y[:, 2] = (x[:, 2] - x[:, 0]) / w # width
y[:, 3] = (x[:, 3] - x[:, 1]) / h # height
return y
def resample():
choices = (cv2.INTER_AREA,
cv2.INTER_CUBIC,
cv2.INTER_LINEAR,
cv2.INTER_NEAREST,
cv2.INTER_LANCZOS4)
return random.choice(seq=choices)
def augment_hsv(image, params):
# HSV color-space augmentation
h = params["hsv_h"]
s = params["hsv_s"]
v = params["hsv_v"]
r = numpy.random.uniform(-1, 1, 3) * [h, s, v] + 1
h, s, v = cv2.split(cv2.cvtColor(image, cv2.COLOR_BGR2HSV))
x = numpy.arange(0, 256, dtype=r.dtype)
lut_h = ((x * r[0]) % 180).astype("uint8")
lut_s = numpy.clip(x * r[1], 0, 255).astype("uint8")
lut_v = numpy.clip(x * r[2], 0, 255).astype("uint8")
hsv = cv2.merge((cv2.LUT(h, lut_h), cv2.LUT(s, lut_s), cv2.LUT(v, lut_v)))
cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR, dst=image) # no return needed
def resize(image, input_size, augment):
# Resize and pad image while meeting stride-multiple constraints
shape = image.shape[:2] # current shape [height, width]
# Scale ratio (new / old)
r = min(input_size / shape[0], input_size / shape[1])
if not augment: # only scale down, do not scale up (for better val mAP)
r = min(r, 1.0)
# Compute padding
pad = int(round(shape[1] * r)), int(round(shape[0] * r))
w = (input_size - pad[0]) / 2
h = (input_size - pad[1]) / 2
if shape[::-1] != pad: # resize
image = cv2.resize(image,
dsize=pad,
interpolation=resample() if augment else cv2.INTER_LINEAR)
top, bottom = int(round(h - 0.1)), int(round(h + 0.1))
left, right = int(round(w - 0.1)), int(round(w + 0.1))
image = cv2.copyMakeBorder(image, top, bottom, left, right, cv2.BORDER_CONSTANT) # add border
return image, (r, r), (w, h)
def candidates(box1, box2):
# box1(4,n), box2(4,n)
w1, h1 = box1[2] - box1[0], box1[3] - box1[1]
w2, h2 = box2[2] - box2[0], box2[3] - box2[1]
aspect_ratio = numpy.maximum(w2 / (h2 + 1e-16), h2 / (w2 + 1e-16)) # aspect ratio
return (w2 > 2) & (h2 > 2) & (w2 * h2 / (w1 * h1 + 1e-16) > 0.1) & (aspect_ratio < 100)
def random_perspective(image, label, params, border=(0, 0)):
h = image.shape[0] + border[0] * 2
w = image.shape[1] + border[1] * 2
# Center
center = numpy.eye(3)
center[0, 2] = -image.shape[1] / 2 # x translation (pixels)
center[1, 2] = -image.shape[0] / 2 # y translation (pixels)
# Perspective
perspective = numpy.eye(3)
# Rotation and Scale
rotate = numpy.eye(3)
a = random.uniform(-params["degrees"], params["degrees"])
s = random.uniform(1 - params["scale"], 1 + params["scale"])
rotate[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
# Shear
shear = numpy.eye(3)
shear[0, 1] = math.tan(random.uniform(-params["shear"], params["shear"]) * math.pi / 180)
shear[1, 0] = math.tan(random.uniform(-params["shear"], params["shear"]) * math.pi / 180)
# Translation
translate = numpy.eye(3)
translate[0, 2] = random.uniform(0.5 - params["translate"], 0.5 + params["translate"]) * w
translate[1, 2] = random.uniform(0.5 - params["translate"], 0.5 + params["translate"]) * h
# Combined rotation matrix, order of operations (right to left) is IMPORTANT
matrix = translate @ shear @ rotate @ perspective @ center
if (border[0] != 0) or (border[1] != 0) or (matrix != numpy.eye(3)).any(): # image changed
image = cv2.warpAffine(image, matrix[:2], dsize=(w, h), borderValue=(0, 0, 0))
# Transform label coordinates
n = len(label)
if n:
xy = numpy.ones((n * 4, 3))
xy[:, :2] = label[:, [1, 2, 3, 4, 1, 4, 3, 2]].reshape(n * 4, 2) # x1y1, x2y2, x1y2, x2y1
xy = xy @ matrix.T # transform
xy = xy[:, :2].reshape(n, 8) # perspective rescale or affine
# create new boxes
x = xy[:, [0, 2, 4, 6]]
y = xy[:, [1, 3, 5, 7]]
box = numpy.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T
# clip
box[:, [0, 2]] = box[:, [0, 2]].clip(0, w)
box[:, [1, 3]] = box[:, [1, 3]].clip(0, h)
# filter candidates
indices = candidates(box1=label[:, 1:5].T * s, box2=box.T)
label = label[indices]
label[:, 1:5] = box[indices]
return image, label
def mix_up(image1, label1, image2, label2):
# Applies MixUp augmentation https://arxiv.org/pdf/1710.09412.pdf
alpha = numpy.random.beta(a=32.0, b=32.0) # mix-up ratio, alpha=beta=32.0
image = (image1 * alpha + image2 * (1 - alpha)).astype(numpy.uint8)
label = numpy.concatenate((label1, label2), 0)
return image, label
class Albumentations:
def __init__(self):
self.transform = None
try:
import albumentations
transforms = [albumentations.Blur(p=0.01),
albumentations.CLAHE(p=0.01),
albumentations.ToGray(p=0.01),
albumentations.MedianBlur(p=0.01)]
self.transform = albumentations.Compose(transforms,
albumentations.BboxParams("yolo", ["class_labels"]))
except ImportError: # package not installed, skip
pass
def __call__(self, image, box, cls):
if self.transform:
x = self.transform(image=image,
bboxes=box,
class_labels=cls)
image = x["image"]
box = numpy.array(x["bboxes"])
cls = numpy.array(x["class_labels"])
return image, box, cls
3.3. YOLOv11模型搭建
- 包括
n, s, m, l, x等五种大小的YOLOv11模型结构定义。
%%writefile nets/nn.py
import math
import torch
from utils.util import make_anchors
def fuse_conv(conv, norm):
fused_conv = torch.nn.Conv2d(conv.in_channels,
conv.out_channels,
kernel_size=conv.kernel_size,
stride=conv.stride,
padding=conv.padding,
groups=conv.groups,
bias=True).requires_grad_(False).to(conv.weight.device)
w_conv = conv.weight.clone().view(conv.out_channels, -1)
w_norm = torch.diag(norm.weight.div(torch.sqrt(norm.eps + norm.running_var)))
fused_conv.weight.copy_(torch.mm(w_norm, w_conv).view(fused_conv.weight.size()))
b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
b_norm = norm.bias - norm.weight.mul(norm.running_mean).div(torch.sqrt(norm.running_var + norm.eps))
fused_conv.bias.copy_(torch.mm(w_norm, b_conv.reshape(-1, 1)).reshape(-1) + b_norm)
return fused_conv
class Conv(torch.nn.Module):
def __init__(self, in_ch, out_ch, activation, k=1, s=1, p=0, g=1):
super().__init__()
self.conv = torch.nn.Conv2d(in_ch, out_ch, k, s, p, groups=g, bias=False)
self.norm = torch.nn.BatchNorm2d(out_ch, eps=0.001, momentum=0.03)
self.relu = activation
def forward(self, x):
return self.relu(self.norm(self.conv(x)))
def fuse_forward(self, x):
return self.relu(self.conv(x))
class Residual(torch.nn.Module):
def __init__(self, ch, e=0.5):
super().__init__()
self.conv1 = Conv(ch, int(ch * e), torch.nn.SiLU(), k=3, p=1)
self.conv2 = Conv(int(ch * e), ch, torch.nn.SiLU(), k=3, p=1)
def forward(self, x):
return x + self.conv2(self.conv1(x))
class CSPModule(torch.nn.Module):
def __init__(self, in_ch, out_ch):
super().__init__()
self.conv1 = Conv(in_ch, out_ch // 2, torch.nn.SiLU())
self.conv2 = Conv(in_ch, out_ch // 2, torch.nn.SiLU())
self.conv3 = Conv(2 * (out_ch // 2), out_ch, torch.nn.SiLU())
self.res_m = torch.nn.Sequential(Residual(out_ch // 2, e=1.0),
Residual(out_ch // 2, e=1.0))
def forward(self, x):
y = self.res_m(self.conv1(x))
return self.conv3(torch.cat((y, self.conv2(x)), dim=1))
class CSP(torch.nn.Module):
def __init__(self, in_ch, out_ch, n, csp, r):
super().__init__()
self.conv1 = Conv(in_ch, 2 * (out_ch // r), torch.nn.SiLU())
self.conv2 = Conv((2 + n) * (out_ch // r), out_ch, torch.nn.SiLU())
if not csp:
self.res_m = torch.nn.ModuleList(Residual(out_ch // r) for _ in range(n))
else:
self.res_m = torch.nn.ModuleList(CSPModule(out_ch // r, out_ch // r) for _ in range(n))
def forward(self, x):
y = list(self.conv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.res_m)
return self.conv2(torch.cat(y, dim=1))
class SPP(torch.nn.Module):
def __init__(self, in_ch, out_ch, k=5):
super().__init__()
self.conv1 = Conv(in_ch, in_ch // 2, torch.nn.SiLU())
self.conv2 = Conv(in_ch * 2, out_ch, torch.nn.SiLU())
self.res_m = torch.nn.MaxPool2d(k, stride=1, padding=k // 2)
def forward(self, x):
x = self.conv1(x)
y1 = self.res_m(x)
y2 = self.res_m(y1)
return self.conv2(torch.cat(tensors=[x, y1, y2, self.res_m(y2)], dim=1))
class Attention(torch.nn.Module):
def __init__(self, ch, num_head):
super().__init__()
self.num_head = num_head
self.dim_head = ch // num_head
self.dim_key = self.dim_head // 2
self.scale = self.dim_key ** -0.5
self.qkv = Conv(ch, ch + self.dim_key * num_head * 2, torch.nn.Identity())
self.conv1 = Conv(ch, ch, torch.nn.Identity(), k=3, p=1, g=ch)
self.conv2 = Conv(ch, ch, torch.nn.Identity())
def forward(self, x):
b, c, h, w = x.shape
qkv = self.qkv(x)
qkv = qkv.view(b, self.num_head, self.dim_key * 2 + self.dim_head, h * w)
q, k, v = qkv.split([self.dim_key, self.dim_key, self.dim_head], dim=2)
attn = (q.transpose(-2, -1) @ k) * self.scale
attn = attn.softmax(dim=-1)
x = (v @ attn.transpose(-2, -1)).view(b, c, h, w) + self.conv1(v.reshape(b, c, h, w))
return self.conv2(x)
class PSABlock(torch.nn.Module):
def __init__(self, ch, num_head):
super().__init__()
self.conv1 = Attention(ch, num_head)
self.conv2 = torch.nn.Sequential(Conv(ch, ch * 2, torch.nn.SiLU()),
Conv(ch * 2, ch, torch.nn.Identity()))
def forward(self, x):
x = x + self.conv1(x)
return x + self.conv2(x)
class PSA(torch.nn.Module):
def __init__(self, ch, n):
super().__init__()
self.conv1 = Conv(ch, 2 * (ch // 2), torch.nn.SiLU())
self.conv2 = Conv(2 * (ch // 2), ch, torch.nn.SiLU())
self.res_m = torch.nn.Sequential(*(PSABlock(ch // 2, ch // 128) for _ in range(n)))
def forward(self, x):
x, y = self.conv1(x).chunk(2, 1)
return self.conv2(torch.cat(tensors=(x, self.res_m(y)), dim=1))
class DarkNet(torch.nn.Module):
def __init__(self, width, depth, csp):
super().__init__()
self.p1 = []
self.p2 = []
self.p3 = []
self.p4 = []
self.p5 = []
# p1/2
self.p1.append(Conv(width[0], width[1], torch.nn.SiLU(), k=3, s=2, p=1))
# p2/4
self.p2.append(Conv(width[1], width[2], torch.nn.SiLU(), k=3, s=2, p=1))
self.p2.append(CSP(width[2], width[3], depth[0], csp[0], r=4))
# p3/8
self.p3.append(Conv(width[3], width[3], torch.nn.SiLU(), k=3, s=2, p=1))
self.p3.append(CSP(width[3], width[4], depth[1], csp[0], r=4))
# p4/16
self.p4.append(Conv(width[4], width[4], torch.nn.SiLU(), k=3, s=2, p=1))
self.p4.append(CSP(width[4], width[4], depth[2], csp[1], r=2))
# p5/32
self.p5.append(Conv(width[4], width[5], torch.nn.SiLU(), k=3, s=2, p=1))
self.p5.append(CSP(width[5], width[5], depth[3], csp[1], r=2))
self.p5.append(SPP(width[5], width[5]))
self.p5.append(PSA(width[5], depth[4]))
self.p1 = torch.nn.Sequential(*self.p1)
self.p2 = torch.nn.Sequential(*self.p2)
self.p3 = torch.nn.Sequential(*self.p3)
self.p4 = torch.nn.Sequential(*self.p4)
self.p5 = torch.nn.Sequential(*self.p5)
def forward(self, x):
p1 = self.p1(x)
p2 = self.p2(p1)
p3 = self.p3(p2)
p4 = self.p4(p3)
p5 = self.p5(p4)
return p3, p4, p5
class DarkFPN(torch.nn.Module):
def __init__(self, width, depth, csp):
super().__init__()
self.up = torch.nn.Upsample(scale_factor=2)
self.h1 = CSP(width[4] + width[5], width[4], depth[5], csp[0], r=2)
self.h2 = CSP(width[4] + width[4], width[3], depth[5], csp[0], r=2)
self.h3 = Conv(width[3], width[3], torch.nn.SiLU(), k=3, s=2, p=1)
self.h4 = CSP(width[3] + width[4], width[4], depth[5], csp[0], r=2)
self.h5 = Conv(width[4], width[4], torch.nn.SiLU(), k=3, s=2, p=1)
self.h6 = CSP(width[4] + width[5], width[5], depth[5], csp[1], r=2)
def forward(self, x):
p3, p4, p5 = x
p4 = self.h1(torch.cat(tensors=[self.up(p5), p4], dim=1))
p3 = self.h2(torch.cat(tensors=[self.up(p4), p3], dim=1))
p4 = self.h4(torch.cat(tensors=[self.h3(p3), p4], dim=1))
p5 = self.h6(torch.cat(tensors=[self.h5(p4), p5], dim=1))
return p3, p4, p5
class DFL(torch.nn.Module):
# Generalized Focal Loss
# https://ieeexplore.ieee.org/document/9792391
def __init__(self, ch=16):
super().__init__()
self.ch = ch
self.conv = torch.nn.Conv2d(ch, out_channels=1, kernel_size=1, bias=False).requires_grad_(False)
x = torch.arange(ch, dtype=torch.float).view(1, ch, 1, 1)
self.conv.weight.data[:] = torch.nn.Parameter(x)
def forward(self, x):
b, c, a = x.shape
x = x.view(b, 4, self.ch, a).transpose(2, 1)
return self.conv(x.softmax(1)).view(b, 4, a)
class Head(torch.nn.Module):
anchors = torch.empty(0)
strides = torch.empty(0)
def __init__(self, nc=80, filters=()):
super().__init__()
self.ch = 16 # DFL channels
self.nc = nc # number of classes
self.nl = len(filters) # number of detection layers
self.no = nc + self.ch * 4 # number of outputs per anchor
self.stride = torch.zeros(self.nl) # strides computed during build
box = max(64, filters[0] // 4)
cls = max(80, filters[0], self.nc)
self.dfl = DFL(self.ch)
self.box = torch.nn.ModuleList(torch.nn.Sequential(Conv(x, box,torch.nn.SiLU(), k=3, p=1),
Conv(box, box,torch.nn.SiLU(), k=3, p=1),
torch.nn.Conv2d(box, out_channels=4 * self.ch,
kernel_size=1)) for x in filters)
self.cls = torch.nn.ModuleList(torch.nn.Sequential(Conv(x, x, torch.nn.SiLU(), k=3, p=1, g=x),
Conv(x, cls, torch.nn.SiLU()),
Conv(cls, cls, torch.nn.SiLU(), k=3, p=1, g=cls),
Conv(cls, cls, torch.nn.SiLU()),
torch.nn.Conv2d(cls, out_channels=self.nc,
kernel_size=1)) for x in filters)
def forward(self, x):
for i, (box, cls) in enumerate(zip(self.box, self.cls)):
x[i] = torch.cat(tensors=(box(x[i]), cls(x[i])), dim=1)
if self.training:
return x
self.anchors, self.strides = (i.transpose(0, 1) for i in make_anchors(x, self.stride))
x = torch.cat([i.view(x[0].shape[0], self.no, -1) for i in x], dim=2)
box, cls = x.split(split_size=(4 * self.ch, self.nc), dim=1)
a, b = self.dfl(box).chunk(2, 1)
a = self.anchors.unsqueeze(0) - a
b = self.anchors.unsqueeze(0) + b
box = torch.cat(tensors=((a + b) / 2, b - a), dim=1)
return torch.cat(tensors=(box * self.strides, cls.sigmoid()), dim=1)
def initialize_biases(self):
# Initialize biases
# WARNING: requires stride availability
for box, cls, s in zip(self.box, self.cls, self.stride):
# box
box[-1].bias.data[:] = 1.0
# cls (.01 objects, 80 classes, 640 image)
cls[-1].bias.data[:self.nc] = math.log(5 / self.nc / (640 / s) ** 2)
class YOLO(torch.nn.Module):
def __init__(self, width, depth, csp, num_classes):
super().__init__()
self.net = DarkNet(width, depth, csp)
self.fpn = DarkFPN(width, depth, csp)
img_dummy = torch.zeros(1, width[0], 256, 256)
self.head = Head(num_classes, (width[3], width[4], width[5]))
self.head.stride = torch.tensor([256 / x.shape[-2] for x in self.forward(img_dummy)])
self.stride = self.head.stride
self.head.initialize_biases()
def forward(self, x):
x = self.net(x)
x = self.fpn(x)
return self.head(list(x))
def fuse(self):
for m in self.modules():
if type(m) is Conv and hasattr(m, "norm"):
m.conv = fuse_conv(m.conv, m.norm)
m.forward = m.fuse_forward
delattr(m, "norm")
return self
def yolo_v11_n(num_classes: int = 80):
csp = [False, True]
depth = [1, 1, 1, 1, 1, 1]
width = [3, 16, 32, 64, 128, 256]
return YOLO(width, depth, csp, num_classes)
def yolo_v11_t(num_classes: int = 80):
csp = [False, True]
depth = [1, 1, 1, 1, 1, 1]
width = [3, 24, 48, 96, 192, 384]
return YOLO(width, depth, csp, num_classes)
def yolo_v11_s(num_classes: int = 80):
csp = [False, True]
depth = [1, 1, 1, 1, 1, 1]
width = [3, 32, 64, 128, 256, 512]
return YOLO(width, depth, csp, num_classes)
def yolo_v11_m(num_classes: int = 80):
csp = [True, True]
depth = [1, 1, 1, 1, 1, 1]
width = [3, 64, 128, 256, 512, 512]
return YOLO(width, depth, csp, num_classes)
def yolo_v11_l(num_classes: int = 80):
csp = [True, True]
depth = [2, 2, 2, 2, 2, 2]
width = [3, 64, 128, 256, 512, 512]
return YOLO(width, depth, csp, num_classes)
def yolo_v11_x(num_classes: int = 80):
csp = [True, True]
depth = [2, 2, 2, 2, 2, 2]
width = [3, 96, 192, 384, 768, 768]
return YOLO(width, depth, csp, num_classes)
3.4. 一些功能函数
%%writefile utils/util.py
import copy
import math
import os
import random
from time import time
import numpy
import torch
import torchvision
from torch.nn.functional import cross_entropy
def setup_seed(seed=0):
"""
Setup random seed.
"""
random.seed(seed)
numpy.random.seed(seed)
torch.manual_seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
def setup_multi_processes():
"""
Setup multi-processing environment variables.
"""
from os import environ
from platform import system
import cv2
# set multiprocess start method as `fork` to speed up the training
if system() != "Windows":
torch.multiprocessing.set_start_method("fork", force=True)
# disable opencv multithreading to avoid system being overloaded
cv2.setNumThreads(0)
# setup OMP threads
if "OMP_NUM_THREADS" not in environ:
environ["OMP_NUM_THREADS"] = "1"
# setup MKL threads
if "MKL_NUM_THREADS" not in environ:
environ["MKL_NUM_THREADS"] = "1"
def wh2xy(x):
y = x.clone() if isinstance(x, torch.Tensor) else numpy.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def make_anchors(x, strides, offset=0.5):
assert x is not None
anchor_tensor, stride_tensor = [], []
dtype, device = x[0].dtype, x[0].device
for i, stride in enumerate(strides):
_, _, h, w = x[i].shape
sx = torch.arange(end=w, device=device, dtype=dtype) + offset # shift x
sy = torch.arange(end=h, device=device, dtype=dtype) + offset # shift y
sy, sx = torch.meshgrid(sy, sx, indexing="ij")
anchor_tensor.append(torch.stack((sx, sy), -1).view(-1, 2))
stride_tensor.append(torch.full((h * w, 1), stride, dtype=dtype, device=device))
return torch.cat(anchor_tensor), torch.cat(stride_tensor)
def compute_metric(output, target, iou_v):
# intersection(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
(a1, a2) = target[:, 1:].unsqueeze(1).chunk(2, 2)
(b1, b2) = output[:, :4].unsqueeze(0).chunk(2, 2)
intersection = (torch.min(a2, b2) - torch.max(a1, b1)).clamp(0).prod(2)
# IoU = intersection / (area1 + area2 - intersection)
iou = intersection / ((a2 - a1).prod(2) + (b2 - b1).prod(2) - intersection + 1e-7)
correct = numpy.zeros((output.shape[0], iou_v.shape[0]))
correct = correct.astype(bool)
for i in range(len(iou_v)):
# IoU > threshold and classes match
x = torch.where((iou >= iou_v[i]) & (target[:, 0:1] == output[:, 5]))
if x[0].shape[0]:
matches = torch.cat((torch.stack(x, 1),
iou[x[0], x[1]][:, None]), 1).cpu().numpy() # [label, detect, iou]
if x[0].shape[0] > 1:
matches = matches[matches[:, 2].argsort()[::-1]]
matches = matches[numpy.unique(matches[:, 1], return_index=True)[1]]
matches = matches[numpy.unique(matches[:, 0], return_index=True)[1]]
correct[matches[:, 1].astype(int), i] = True
return torch.tensor(correct, dtype=torch.bool, device=output.device)
def non_max_suppression(outputs, confidence_threshold=0.001, iou_threshold=0.65):
max_wh = 7680
max_det = 300
max_nms = 30000
bs = outputs.shape[0] # batch size
nc = outputs.shape[1] - 4 # number of classes
xc = outputs[:, 4:4 + nc].amax(1) > confidence_threshold # candidates
# Settings
start = time()
limit = 0.5 + 0.05 * bs # seconds to quit after
output = [torch.zeros((0, 6), device=outputs.device)] * bs
for index, x in enumerate(outputs): # image index, image inference
x = x.transpose(0, -1)[xc[index]] # confidence
# If none remain process next image
if not x.shape[0]:
continue
# matrix nx6 (box, confidence, cls)
box, cls = x.split((4, nc), 1)
box = wh2xy(box) # (cx, cy, w, h) to (x1, y1, x2, y2)
if nc > 1:
i, j = (cls > confidence_threshold).nonzero(as_tuple=False).T
x = torch.cat((box[i], x[i, 4 + j, None], j[:, None].float()), 1)
else: # best class only
conf, j = cls.max(1, keepdim=True)
x = torch.cat((box, conf, j.float()), 1)[conf.view(-1) > confidence_threshold]
# Check shape
n = x.shape[0] # number of boxes
if not n: # no boxes
continue
x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence and remove excess boxes
# Batched NMS
c = x[:, 5:6] * max_wh # classes
boxes, scores = x[:, :4] + c, x[:, 4] # boxes, scores
indices = torchvision.ops.nms(boxes, scores, iou_threshold) # NMS
indices = indices[:max_det] # limit detections
output[index] = x[indices]
if (time() - start) > limit:
break # time limit exceeded
return output
def smooth(y, f=0.1):
# Box filter of fraction f
nf = round(len(y) * f * 2) // 2 + 1 # number of filter elements (must be odd)
p = numpy.ones(nf // 2) # ones padding
yp = numpy.concatenate((p * y[0], y, p * y[-1]), 0) # y padded
return numpy.convolve(yp, numpy.ones(nf) / nf, mode="valid") # y-smoothed
def plot_pr_curve(px, py, ap, names, save_dir):
from matplotlib import pyplot
fig, ax = pyplot.subplots(1, 1, figsize=(9, 6), tight_layout=True)
py = numpy.stack(py, axis=1)
if 0 < len(names) < 21: # display per-class legend if < 21 classes
for i, y in enumerate(py.T):
ax.plot(px, y, linewidth=1, label=f"{names[i]} {ap[i, 0]:.3f}") # plot(recall, precision)
else:
ax.plot(px, py, linewidth=1, color="grey") # plot(recall, precision)
ax.plot(px, py.mean(1), linewidth=3, color="blue", label="all classes %.3f mAP@0.5" % ap[:, 0].mean())
ax.set_xlabel("Recall")
ax.set_ylabel("Precision")
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
ax.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
ax.set_title("Precision-Recall Curve")
fig.savefig(save_dir, dpi=250)
pyplot.close(fig)
def plot_curve(px, py, names, save_dir, x_label="Confidence", y_label="Metric"):
from matplotlib import pyplot
figure, ax = pyplot.subplots(1, 1, figsize=(9, 6), tight_layout=True)
if 0 < len(names) < 21: # display per-class legend if < 21 classes
for i, y in enumerate(py):
ax.plot(px, y, linewidth=1, label=f"{names[i]}") # plot(confidence, metric)
else:
ax.plot(px, py.T, linewidth=1, color="grey") # plot(confidence, metric)
y = smooth(py.mean(0), f=0.05)
ax.plot(px, y, linewidth=3, color="blue", label=f"all classes {y.max():.3f} at {px[y.argmax()]:.3f}")
ax.set_xlabel(x_label)
ax.set_ylabel(y_label)
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
ax.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
ax.set_title(f"{y_label}-Confidence Curve")
figure.savefig(save_dir, dpi=250)
pyplot.close(figure)
def compute_ap(tp, conf, output, target, save_dir, plot=False, names=(), eps=1E-16):
"""
Compute the average precision, given the recall and precision curves.
Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
# Arguments
tp: True positives (nparray, nx1 or nx10).
conf: Object-ness value from 0-1 (nparray).
output: Predicted object classes (nparray).
target: True object classes (nparray).
# Returns
The average precision
"""
# Sort by object-ness
i = numpy.argsort(-conf)
tp, conf, output = tp[i], conf[i], output[i]
# Find unique classes
unique_classes, nt = numpy.unique(target, return_counts=True)
nc = unique_classes.shape[0] # number of classes, number of detections
# Create Precision-Recall curve and compute AP for each class
p = numpy.zeros((nc, 1000))
r = numpy.zeros((nc, 1000))
ap = numpy.zeros((nc, tp.shape[1]))
px, py = numpy.linspace(start=0, stop=1, num=1000), [] # for plotting
for ci, c in enumerate(unique_classes):
i = output == c
nl = nt[ci] # number of labels
no = i.sum() # number of outputs
if no == 0 or nl == 0:
continue
# Accumulate FPs and TPs
fpc = (1 - tp[i]).cumsum(0)
tpc = tp[i].cumsum(0)
# Recall
recall = tpc / (nl + eps) # recall curve
# negative x, xp because xp decreases
r[ci] = numpy.interp(-px, -conf[i], recall[:, 0], left=0)
# Precision
precision = tpc / (tpc + fpc) # precision curve
p[ci] = numpy.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score
# AP from recall-precision curve
for j in range(tp.shape[1]):
m_rec = numpy.concatenate(([0.0], recall[:, j], [1.0]))
m_pre = numpy.concatenate(([1.0], precision[:, j], [0.0]))
# Compute the precision envelope
m_pre = numpy.flip(numpy.maximum.accumulate(numpy.flip(m_pre)))
# Integrate area under curve
x = numpy.linspace(start=0, stop=1, num=101) # 101-point interp (COCO)
ap[ci, j] = numpy.trapz(numpy.interp(x, m_rec, m_pre), x) # integrate
if plot and j == 0:
py.append(numpy.interp(px, m_rec, m_pre)) # precision at mAP@0.5
# Compute F1 (harmonic mean of precision and recall)
f1 = 2 * p * r / (p + r + eps)
if plot:
names = dict(enumerate(names)) # to dict
names = [v for k, v in names.items() if k in unique_classes] # list: only classes that have data
plot_pr_curve(px, py, ap, names, save_dir=f"{save_dir}/PR_curve.png")
plot_curve(px, f1, names, save_dir=f"{save_dir}/F1_curve.png", y_label="F1")
plot_curve(px, p, names, save_dir=f"{save_dir}/P_curve.png", y_label="Precision")
plot_curve(px, r, names, save_dir=f"{save_dir}/R_curve.png", y_label="Recall")
i = smooth(f1.mean(0), 0.1).argmax() # max F1 index
p, r, f1 = p[:, i], r[:, i], f1[:, i]
tp = (r * nt).round() # true positives
fp = (tp / (p + eps) - tp).round() # false positives
ap50, ap = ap[:, 0], ap.mean(1) # AP@0.5, AP@0.5:0.95
m_pre, m_rec = p.mean(), r.mean()
map50, mean_ap = ap50.mean(), ap.mean()
return tp, fp, m_pre, m_rec, map50, mean_ap
def compute_iou(box1, box2, eps=1e-7):
# Returns Intersection over Union (IoU) of box1(1,4) to box2(n,4)
# Get the coordinates of bounding boxes
b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
# Intersection area
inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp(0) * \
(b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp(0)
# Union Area
union = w1 * h1 + w2 * h2 - inter + eps
# IoU
iou = inter / union
cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) width
ch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex height
c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2
# https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
v = (4 / math.pi ** 2) * (torch.atan(w2 / h2) - torch.atan(w1 / h1)).pow(2)
with torch.no_grad():
alpha = v / (v - iou + (1 + eps))
return iou - (rho2 / c2 + v * alpha) # CIoU
def clip_gradients(model, max_norm=10.0):
parameters = model.parameters()
torch.nn.utils.clip_grad_norm_(parameters, max_norm=max_norm)
def set_params(model, decay):
p1 = []
p2 = []
norm = tuple(v for k, v in torch.nn.__dict__.items() if "Norm" in k)
for m in model.modules():
for n, p in m.named_parameters(recurse=0):
if not p.requires_grad:
continue
if n == "bias": # bias (no decay)
p1.append(p)
elif n == "weight" and isinstance(m, norm): # norm-weight (no decay)
p1.append(p)
else:
p2.append(p) # weight (with decay)
return [{"params": p1, "weight_decay": 0.00},
{"params": p2, "weight_decay": decay}]
class CosineLR:
def __init__(self, params, num_epochs, num_steps, lr_scale):
max_lr = params["max_lr"]
min_lr = params["min_lr"]
warmup_steps = int(max(params["warmup_epochs"] * num_steps, 100))
decay_steps = int(num_epochs * num_steps - warmup_steps)
warmup_lr = numpy.linspace(min_lr, max_lr, int(warmup_steps))
decay_lr = []
for step in range(1, decay_steps + 1):
alpha = math.cos(math.pi * step / decay_steps)
decay_lr.append(min_lr + 0.5 * (max_lr - min_lr) * (1 + alpha))
self.total_lr = numpy.concatenate((warmup_lr, decay_lr)) * lr_scale
def step(self, step, optimizer):
for param_group in optimizer.param_groups:
param_group["lr"] = self.total_lr[step]
class LinearLR:
def __init__(self, params, num_epochs, num_steps, lr_scale):
max_lr = params["max_lr"]
min_lr = params["min_lr"]
warmup_steps = int(max(params["warmup_epochs"] * num_steps, 100))
decay_steps = int(num_epochs * num_steps - warmup_steps)
warmup_lr = numpy.linspace(min_lr, max_lr, int(warmup_steps), endpoint=False)
decay_lr = numpy.linspace(max_lr, min_lr, decay_steps)
self.total_lr = numpy.concatenate((warmup_lr, decay_lr)) * lr_scale
def step(self, step, optimizer):
for param_group in optimizer.param_groups:
param_group["lr"] = self.total_lr[step]
class EMA:
"""
Updated Exponential Moving Average (EMA) from https://github.com/rwightman/pytorch-image-models
Keeps a moving average of everything in the model state_dict (parameters and buffers)
For EMA details see https://www.tensorflow.org/api_docs/python/tf/train/ExponentialMovingAverage
"""
def __init__(self, model, decay=0.9999, tau=2000, updates=0):
# Create EMA
self.ema = copy.deepcopy(model).eval() # FP32 EMA
self.updates = updates # number of EMA updates
# decay exponential ramp (to help early epochs)
self.decay = lambda x: decay * (1 - math.exp(-x / tau))
for p in self.ema.parameters():
p.requires_grad_(False)
def update(self, model):
if hasattr(model, "module"):
model = model.module
# Update EMA parameters
with torch.no_grad():
self.updates += 1
d = self.decay(self.updates)
msd = model.state_dict() # model state_dict
for k, v in self.ema.state_dict().items():
if v.dtype.is_floating_point:
v *= d
v += (1 - d) * msd[k].detach()
class AverageMeter:
def __init__(self):
self.num = 0
self.sum = 0
self.avg = 0
def update(self, v, n):
if not math.isnan(float(v)):
self.num = self.num + n
self.sum = self.sum + v * n
self.avg = self.sum / self.num
class Assigner(torch.nn.Module):
def __init__(self, nc=80, top_k=13, alpha=1.0, beta=6.0, eps=1E-9):
super().__init__()
self.top_k = top_k
self.nc = nc
self.alpha = alpha
self.beta = beta
self.eps = eps
@torch.no_grad()
def forward(self, pd_scores, pd_bboxes, anc_points, gt_labels, gt_bboxes, mask_gt):
batch_size = pd_scores.size(0)
num_max_boxes = gt_bboxes.size(1)
if num_max_boxes == 0:
device = gt_bboxes.device
return (torch.zeros_like(pd_bboxes).to(device),
torch.zeros_like(pd_scores).to(device),
torch.zeros_like(pd_scores[..., 0]).to(device))
num_anchors = anc_points.shape[0]
shape = gt_bboxes.shape
lt, rb = gt_bboxes.view(-1, 1, 4).chunk(2, 2)
mask_in_gts = torch.cat((anc_points[None] - lt, rb - anc_points[None]), dim=2)
mask_in_gts = mask_in_gts.view(shape[0], shape[1], num_anchors, -1).amin(3).gt_(self.eps)
na = pd_bboxes.shape[-2]
gt_mask = (mask_in_gts * mask_gt).bool() # b, max_num_obj, h*w
overlaps = torch.zeros([batch_size, num_max_boxes, na], dtype=pd_bboxes.dtype, device=pd_bboxes.device)
bbox_scores = torch.zeros([batch_size, num_max_boxes, na], dtype=pd_scores.dtype, device=pd_scores.device)
ind = torch.zeros([2, batch_size, num_max_boxes], dtype=torch.long) # 2, b, max_num_obj
ind[0] = torch.arange(end=batch_size).view(-1, 1).expand(-1, num_max_boxes) # b, max_num_obj
ind[1] = gt_labels.squeeze(-1) # b, max_num_obj
bbox_scores[gt_mask] = pd_scores[ind[0], :, ind[1]][gt_mask] # b, max_num_obj, h*w
pd_boxes = pd_bboxes.unsqueeze(1).expand(-1, num_max_boxes, -1, -1)[gt_mask]
gt_boxes = gt_bboxes.unsqueeze(2).expand(-1, -1, na, -1)[gt_mask]
overlaps[gt_mask] = compute_iou(gt_boxes, pd_boxes).squeeze(-1).clamp_(0)
align_metric = bbox_scores.pow(self.alpha) * overlaps.pow(self.beta)
top_k_mask = mask_gt.expand(-1, -1, self.top_k).bool()
top_k_metrics, top_k_indices = torch.topk(align_metric, self.top_k, dim=-1, largest=True)
if top_k_mask is None:
top_k_mask = (top_k_metrics.max(-1, keepdim=True)[0] > self.eps).expand_as(top_k_indices)
top_k_indices.masked_fill_(~top_k_mask, 0)
mask_top_k = torch.zeros(align_metric.shape, dtype=torch.int8, device=top_k_indices.device)
ones = torch.ones_like(top_k_indices[:, :, :1], dtype=torch.int8, device=top_k_indices.device)
for k in range(self.top_k):
mask_top_k.scatter_add_(-1, top_k_indices[:, :, k:k + 1], ones)
mask_top_k.masked_fill_(mask_top_k > 1, 0)
mask_top_k = mask_top_k.to(align_metric.dtype)
mask_pos = mask_top_k * mask_in_gts * mask_gt
fg_mask = mask_pos.sum(-2)
if fg_mask.max() > 1:
mask_multi_gts = (fg_mask.unsqueeze(1) > 1).expand(-1, num_max_boxes, -1)
max_overlaps_idx = overlaps.argmax(1)
is_max_overlaps = torch.zeros(mask_pos.shape, dtype=mask_pos.dtype, device=mask_pos.device)
is_max_overlaps.scatter_(1, max_overlaps_idx.unsqueeze(1), 1)
mask_pos = torch.where(mask_multi_gts, is_max_overlaps, mask_pos).float()
fg_mask = mask_pos.sum(-2)
target_gt_idx = mask_pos.argmax(-2)
# Assigned target
index = torch.arange(end=batch_size, dtype=torch.int64, device=gt_labels.device)[..., None]
target_index = target_gt_idx + index * num_max_boxes
target_labels = gt_labels.long().flatten()[target_index]
target_bboxes = gt_bboxes.view(-1, gt_bboxes.shape[-1])[target_index]
# Assigned target scores
target_labels.clamp_(0)
target_scores = torch.zeros((target_labels.shape[0], target_labels.shape[1], self.nc),
dtype=torch.int64,
device=target_labels.device)
target_scores.scatter_(2, target_labels.unsqueeze(-1), 1)
fg_scores_mask = fg_mask[:, :, None].repeat(1, 1, self.nc)
target_scores = torch.where(fg_scores_mask > 0, target_scores, 0)
# Normalize
align_metric *= mask_pos
pos_align_metrics = align_metric.amax(dim=-1, keepdim=True)
pos_overlaps = (overlaps * mask_pos).amax(dim=-1, keepdim=True)
norm_align_metric = (align_metric * pos_overlaps / (pos_align_metrics + self.eps)).amax(-2).unsqueeze(-1)
target_scores = target_scores * norm_align_metric
return target_bboxes, target_scores, fg_mask.bool()
class QFL(torch.nn.Module):
def __init__(self, beta=2.0):
super().__init__()
self.beta = beta
self.bce_loss = torch.nn.BCEWithLogitsLoss(reduction="none")
def forward(self, outputs, targets):
bce_loss = self.bce_loss(outputs, targets)
return torch.pow(torch.abs(targets - outputs.sigmoid()), self.beta) * bce_loss
class VFL(torch.nn.Module):
def __init__(self, alpha=0.75, gamma=2.00, iou_weighted=True):
super().__init__()
assert alpha >= 0.0
self.alpha = alpha
self.gamma = gamma
self.iou_weighted = iou_weighted
self.bce_loss = torch.nn.BCEWithLogitsLoss(reduction="none")
def forward(self, outputs, targets):
assert outputs.size() == targets.size()
targets = targets.type_as(outputs)
if self.iou_weighted:
focal_weight = targets * (targets > 0.0).float() + \
self.alpha * (outputs.sigmoid() - targets).abs().pow(self.gamma) * \
(targets <= 0.0).float()
else:
focal_weight = (targets > 0.0).float() + \
self.alpha * (outputs.sigmoid() - targets).abs().pow(self.gamma) * \
(targets <= 0.0).float()
return self.bce_loss(outputs, targets) * focal_weight
class FocalLoss(torch.nn.Module):
def __init__(self, alpha=0.25, gamma=1.5):
super().__init__()
self.alpha = alpha
self.gamma = gamma
self.bce_loss = torch.nn.BCEWithLogitsLoss(reduction="none")
def forward(self, outputs, targets):
loss = self.bce_loss(outputs, targets)
if self.alpha > 0:
alpha_factor = targets * self.alpha + (1 - targets) * (1 - self.alpha)
loss *= alpha_factor
if self.gamma > 0:
outputs_sigmoid = outputs.sigmoid()
p_t = targets * outputs_sigmoid + (1 - targets) * (1 - outputs_sigmoid)
gamma_factor = (1.0 - p_t) ** self.gamma
loss *= gamma_factor
return loss
class BoxLoss(torch.nn.Module):
def __init__(self, dfl_ch):
super().__init__()
self.dfl_ch = dfl_ch
def forward(self, pred_dist, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask):
# IoU loss
weight = torch.masked_select(target_scores.sum(-1), fg_mask).unsqueeze(-1)
iou = compute_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask])
loss_box = ((1.0 - iou) * weight).sum() / target_scores_sum
# DFL loss
a, b = target_bboxes.chunk(2, -1)
target = torch.cat((anchor_points - a, b - anchor_points), -1)
target = target.clamp(0, self.dfl_ch - 0.01)
loss_dfl = self.df_loss(pred_dist[fg_mask].view(-1, self.dfl_ch + 1), target[fg_mask])
loss_dfl = (loss_dfl * weight).sum() / target_scores_sum
return loss_box, loss_dfl
@staticmethod
def df_loss(pred_dist, target):
# Distribution Focal Loss (DFL)
# https://ieeexplore.ieee.org/document/9792391
tl = target.long() # target left
tr = tl + 1 # target right
wl = tr - target # weight left
wr = 1 - wl # weight right
left_loss = cross_entropy(pred_dist, tl.view(-1), reduction="none").view(tl.shape)
right_loss = cross_entropy(pred_dist, tr.view(-1), reduction="none").view(tl.shape)
return (left_loss * wl + right_loss * wr).mean(-1, keepdim=True)
class ComputeLoss:
def __init__(self, model, params):
if hasattr(model, "module"):
model = model.module
device = next(model.parameters()).device
m = model.head # Head() module
self.params = params
self.stride = m.stride
self.nc = m.nc
self.no = m.no
self.reg_max = m.ch
self.device = device
self.box_loss = BoxLoss(m.ch - 1).to(device)
self.cls_loss = torch.nn.BCEWithLogitsLoss(reduction="none")
self.assigner = Assigner(nc=self.nc, top_k=10, alpha=0.5, beta=6.0)
self.project = torch.arange(m.ch, dtype=torch.float, device=device)
def box_decode(self, anchor_points, pred_dist):
b, a, c = pred_dist.shape
pred_dist = pred_dist.view(b, a, 4, c // 4)
pred_dist = pred_dist.softmax(3)
pred_dist = pred_dist.matmul(self.project.type(pred_dist.dtype))
lt, rb = pred_dist.chunk(2, -1)
x1y1 = anchor_points - lt
x2y2 = anchor_points + rb
return torch.cat(tensors=(x1y1, x2y2), dim=-1)
def __call__(self, outputs, targets):
x = torch.cat([i.view(outputs[0].shape[0], self.no, -1) for i in outputs], dim=2)
pred_distri, pred_scores = x.split(split_size=(self.reg_max * 4, self.nc), dim=1)
pred_scores = pred_scores.permute(0, 2, 1).contiguous()
pred_distri = pred_distri.permute(0, 2, 1).contiguous()
data_type = pred_scores.dtype
batch_size = pred_scores.shape[0]
input_size = torch.tensor(outputs[0].shape[2:], device=self.device, dtype=data_type) * self.stride[0]
anchor_points, stride_tensor = make_anchors(outputs, self.stride, offset=0.5)
idx = targets["idx"].view(-1, 1)
cls = targets["cls"].view(-1, 1)
box = targets["box"]
targets = torch.cat((idx, cls, box), dim=1).to(self.device)
if targets.shape[0] == 0:
gt = torch.zeros(batch_size, 0, 5, device=self.device)
else:
i = targets[:, 0]
_, counts = i.unique(return_counts=True)
counts = counts.to(dtype=torch.int32)
gt = torch.zeros(batch_size, counts.max(), 5, device=self.device)
for j in range(batch_size):
matches = i == j
n = matches.sum()
if n:
gt[j, :n] = targets[matches, 1:]
x = gt[..., 1:5].mul_(input_size[[1, 0, 1, 0]])
y = torch.empty_like(x)
dw = x[..., 2] / 2 # half-width
dh = x[..., 3] / 2 # half-height
y[..., 0] = x[..., 0] - dw # top left x
y[..., 1] = x[..., 1] - dh # top left y
y[..., 2] = x[..., 0] + dw # bottom right x
y[..., 3] = x[..., 1] + dh # bottom right y
gt[..., 1:5] = y
gt_labels, gt_bboxes = gt.split((1, 4), 2)
mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0)
pred_bboxes = self.box_decode(anchor_points, pred_distri)
assigned_targets = self.assigner(pred_scores.detach().sigmoid(),
(pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),
anchor_points * stride_tensor, gt_labels, gt_bboxes, mask_gt)
target_bboxes, target_scores, fg_mask = assigned_targets
target_scores_sum = max(target_scores.sum(), 1)
loss_cls = self.cls_loss(pred_scores, target_scores.to(data_type)).sum() / target_scores_sum # BCE
# Box loss
loss_box = torch.zeros(1, device=self.device)
loss_dfl = torch.zeros(1, device=self.device)
if fg_mask.sum():
target_bboxes /= stride_tensor
loss_box, loss_dfl = self.box_loss(pred_distri,
pred_bboxes,
anchor_points,
target_bboxes,
target_scores,
target_scores_sum, fg_mask)
loss_box *= self.params["box"] # box gain
loss_cls *= self.params["cls"] # cls gain
loss_dfl *= self.params["dfl"] # dfl gain
return loss_box, loss_cls, loss_dfl
四、模型训练+测试
- 介绍如何使用主函数
main.py,进行模型的训练和测试。
4.1. 主函数文件
%%writefile main.py
import copy
import csv
import os
import warnings
from argparse import ArgumentParser
import torch
import tqdm
import yaml
from torch.utils import data
from pprint import pprint
import time
from nets import nn
from utils import util
from utils.dataset import Dataset
warnings.filterwarnings("ignore")
def train(args, params):
# 1. Model
model = nn.yolo_v11_n(len(params["names"]))
start_epoch = 1
if os.path.exists(os.path.join(args.exp_dir, "last.pt")):
state_dict = torch.load(os.path.join(args.exp_dir, "last.pt"))
start_epoch = state_dict["epoch"] + 1
model.load_state_dict(state_dict["model"])
model.cuda()
# 2. Datset+DataLoader
filenames = []
with open(f"{args.data_dir}/train2017.txt") as f:
for filename in f.readlines():
filename = os.path.basename(filename.rstrip())
filenames.append(f"{args.data_dir}/images/train2017/" + filename)
sampler = None
dataset = Dataset(filenames, args.input_size, params, augment=True)
if args.distributed:
sampler = data.distributed.DistributedSampler(dataset)
loader = data.DataLoader(dataset, args.batch_size, sampler is None, sampler,
num_workers=8, pin_memory=True, collate_fn=Dataset.collate_fn)
# 3.1. Optimizer
accumulate = max(round(64 / (args.batch_size * args.world_size)), 1)
params["weight_decay"] *= args.batch_size * args.world_size * accumulate / 64
optimizer = torch.optim.SGD(util.set_params(model, params["weight_decay"]),
params["min_lr"], params["momentum"], nesterov=True)
# 3.2. EMA
ema = util.EMA(model) if args.local_rank == 0 else None
# 3.3. Scheduler
num_steps = len(loader)
lr_scale = (args.batch_size * args.world_size) / 64
scheduler = util.LinearLR(params, args.epochs, num_steps, lr_scale)
# 4.1. syncBN+DDP
if args.distributed:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
model = torch.nn.parallel.DistributedDataParallel(module=model,
device_ids=[args.local_rank],
output_device=args.local_rank)
# 4.2. Scaler+Loss
best = 0
amp_scale = torch.cuda.amp.GradScaler()
criterion = util.ComputeLoss(model, params)
with open(os.path.join(args.exp_dir, "step.csv"), "a+") as log:
if args.local_rank == 0:
logger = csv.DictWriter(log, fieldnames=["epoch",
"box", "cls", "dfl",
"Recall", "Precision", "mAP@50", "mAP"])
logger.writeheader()
for epoch in range(start_epoch, args.epochs):
model.train()
if args.distributed:
sampler.set_epoch(epoch)
if args.epochs - epoch == 10:
loader.dataset.mosaic = False
p_bar = enumerate(loader)
if args.local_rank == 0:
print(("\n" + "%10s" * 6) % ("epoch", "memory", "box", "cls", "dfl", "lr"))
p_bar = tqdm.tqdm(p_bar, total=num_steps)
optimizer.zero_grad()
avg_box_loss = util.AverageMeter()
avg_cls_loss = util.AverageMeter()
avg_dfl_loss = util.AverageMeter()
for i, (samples, targets) in p_bar:
step = i + num_steps * epoch
scheduler.step(step, optimizer)
samples = samples.cuda().float() / 255
# Forward
with torch.cuda.amp.autocast():
outputs = model(samples) # forward
loss_box, loss_cls, loss_dfl = criterion(outputs, targets)
avg_box_loss.update(loss_box.item(), samples.size(0))
avg_cls_loss.update(loss_cls.item(), samples.size(0))
avg_dfl_loss.update(loss_dfl.item(), samples.size(0))
loss_box *= args.batch_size # loss scaled by batch_size
loss_cls *= args.batch_size # loss scaled by batch_size
loss_dfl *= args.batch_size # loss scaled by batch_size
loss_box *= args.world_size # gradient averaged between devices in DDP mode
loss_cls *= args.world_size # gradient averaged between devices in DDP mode
loss_dfl *= args.world_size # gradient averaged between devices in DDP mode
# Backward
amp_scale.scale(loss_box + loss_cls + loss_dfl).backward()
# Optimize
if step % accumulate == 0:
amp_scale.unscale_(optimizer) # unscale gradients
util.clip_gradients(model) # clip gradients
amp_scale.step(optimizer) # optimizer.step
amp_scale.update()
optimizer.zero_grad()
if ema:
ema.update(model)
torch.cuda.synchronize()
# Log
if args.local_rank == 0:
memory = f"{torch.cuda.memory_reserved() / 1E9:.4g}G" # (GB)
s = ("%10s" * 2 + "%10.3g" * 4) % (f"{epoch}/{args.epochs}", memory,
avg_box_loss.avg, avg_cls_loss.avg, avg_dfl_loss.avg, optimizer.param_groups[0]["lr"])
p_bar.set_description(s)
if args.local_rank == 0:
# mAP
last = test(args, params, ema.ema)
logger.writerow({"epoch": str(epoch).zfill(3),
"box": str(f"{avg_box_loss.avg:.3f}"),
"cls": str(f"{avg_cls_loss.avg:.3f}"),
"dfl": str(f"{avg_dfl_loss.avg:.3f}"),
"mAP": str(f"{last[0]:.3f}"),
"mAP@50": str(f"{last[1]:.3f}"),
"Recall": str(f"{last[2]:.3f}"),
"Precision": str(f"{last[3]:.3f}")})
log.flush()
# Update best mAP
if last[0] > best:
best = last[0]
# Save model
save = {"epoch": epoch,
"model": copy.deepcopy(ema.ema.state_dict())}
# Save last, best and delete
torch.save(save, f=os.path.join(args.exp_dir, "last.pt"))
if best == last[0]:
torch.save(save, f=os.path.join(args.exp_dir, "best.pt"))
del save
@torch.no_grad()
def test(args, params, model=None):
# 1. Model
if not model:
model = nn.yolo_v11_n(len(params["names"]))
ckpt_file = args.ckpt_file if args.ckpt_file else os.path.join(args.exp_dir, "best.pt")
state_dict = torch.load(f=ckpt_file, map_location="cpu")
model.load_state_dict(state_dict["model"])
model = model.float().fuse()
device = torch.device(args.device) if torch.cuda.is_available() else torch.device("cpu")
model = model.eval().to(device)
# 2. Datset+DataLoader
filenames = []
with open(f"{args.data_dir}/val2017.txt") as f:
for filename in f.readlines():
filename = os.path.basename(filename.rstrip())
filenames.append(f"{args.data_dir}/images/val2017/" + filename)
dataset = Dataset(filenames, args.input_size, params, augment=False)
loader = data.DataLoader(dataset, batch_size=args.batch_size, shuffle=False, num_workers=4,
pin_memory=True, collate_fn=Dataset.collate_fn)
# 3. Configure
iou_v = torch.linspace(start=0.5, end=0.95, steps=10).to(device) # iou vector for mAP@0.5:0.95
n_iou = iou_v.numel()
m_pre = 0
m_rec = 0
map50 = 0
mean_ap = 0
metrics = []
start_time = time.time()
# 4. Forward Validation Dataset
for samples, targets in tqdm.tqdm(loader, desc="YOLOv11-pt"):
# 4.1. Preprocess
samples = samples.to(device)
samples = samples.float() # uint8 to fp16/32
samples = samples / 255. # 0 - 255 to 0.0 - 1.0
_, _, h, w = samples.shape # batch-size, channels, height, width
scale = torch.tensor((w, h, w, h)).to(device)
# 4.2. Inference
outputs = model(samples)
# 4.3. NMS
outputs = util.non_max_suppression(outputs)
# 4.4. Metrics
for i, output in enumerate(outputs):
idx = targets["idx"] == i
cls = targets["cls"][idx]
box = targets["box"][idx]
cls = cls.to(device)
box = box.to(device)
metric = torch.zeros(output.shape[0], n_iou, dtype=torch.bool).to(device)
if output.shape[0] == 0:
if cls.shape[0]:
metrics.append((metric, *torch.zeros((2, 0)).to(device), cls.squeeze(-1)))
continue
# Evaluate
if cls.shape[0]:
target = torch.cat(tensors=(cls, util.wh2xy(box) * scale), dim=1)
metric = util.compute_metric(output[:, :6], target, iou_v)
metrics.append((metric, output[:, 4], output[:, 5], cls.squeeze(-1)))
# 5. Compute metrics
metrics = [torch.cat(x, dim=0).cpu().numpy() for x in zip(*metrics)] # to numpy
if len(metrics) and metrics[0].any():
tp, fp, m_pre, m_rec, map50, mean_ap = util.compute_ap(
*metrics, args.exp_dir, plot=args.plot, names=params["names"])
print("{:5s}@precision={:.3g}{:10s}@recall={:.3g}".format("", m_pre, "", m_rec))
print("{:5s}@mAP50={:.3g}{:14s}@mAP={:.3g}".format("", map50, "", mean_ap))
print("{:5s}@ConsumTime={:.3g}s".format("", time.time() - start_time))
return mean_ap, map50, m_rec, m_pre
def main():
parser = ArgumentParser()
parser.add_argument("--input-size", default=640, type=int)
parser.add_argument("--batch-size", default=32, type=int)
parser.add_argument("--local-rank", default=0, type=int)
parser.add_argument("--epochs", default=600, type=int)
parser.add_argument("--train", action="store_true")
parser.add_argument("--test", action="store_true")
parser.add_argument("--plot", action="store_true")
parser.add_argument("--device", default="cuda", type=str)
parser.add_argument("--data-dir", default="datasets/coco", type=str)
parser.add_argument("--exp-dir", default="weights", type=str)
parser.add_argument("--ckpt-file", default=None, type=str)
args = parser.parse_args()
args.local_rank = int(os.getenv("LOCAL_RANK", 0))
args.world_size = int(os.getenv("WORLD_SIZE", 1))
args.distributed = int(os.getenv("WORLD_SIZE", 1)) > 1
if args.distributed:
torch.cuda.set_device(device=args.local_rank)
torch.distributed.init_process_group(backend="nccl", init_method="env://")
pprint(vars(args))
if args.local_rank == 0:
os.makedirs(args.exp_dir, exist_ok=True)
with open("utils/args.yaml", errors="ignore") as f:
params = yaml.safe_load(f)
util.setup_seed()
util.setup_multi_processes()
if args.train:
train(args, params)
if args.test:
test(args, params)
# Clean
if args.distributed:
torch.distributed.destroy_process_group()
torch.cuda.empty_cache()
if __name__ == "__main__":
main()
4.2. 模型训练
- 执行如下命令,使用默认参数(bs=32,epoch=600)开启训练:
%cd /home/ma-user/work/YOLOv11-pt
!python main.py --train --data-dir <DATASET-MINI-COCO>
- 训练结束后,模型权重将被保存为“weights/best.pt”
4.3. 模型测试
- 执行如下命令,使用参数(bs=4,指定模型),开启推理测试:
%cd /home/ma-user/work/YOLOv11-pt
!python main.py --test --data-dir <DATASET-MINI-COCO> --batch-size 4 --ckpt-file weights/best.pt
- 输出如下评价指标:
YOLOv11-pt: 100%|███████████████████████████████| 50/50 [00:06<00:00, 8.22it/s]
@precision=0.576 @recall=0.576
@mAP50=0.606 @mAP=0.439
@ConsumTime=6.2s
五、参考资料

- 点赞
- 收藏
- 关注作者
评论(0)