机器学习中的数学 —— 向量篇

数学听起来可能有点复杂,但其实它就像一块拼图,帮助我们解锁世界的奥秘。而向量,就是深度学习这幅拼图的第一块。在这里,我们会用最简单的语言和形象化的方式,带你认识什么是向量,以及它们如何改变深度学习的世界。
向量是什么?
想象一下,你手上有一张藏宝图,图上标着一个箭头,指向宝藏的位置。这个箭头有两个特点:一个是指向的方向,另一个是箭头的长度。这个箭头,就是向量的直观解释。
用数学语言来说,向量是一个有序的数字列表,比如 [1, 2] 或 [3, 4, 5]。每个数字代表一个“坐标”,而整个列表可以描述二维平面或更高维空间中的点。
在深度学习中,向量扮演信息载体的角色。它可以用来表示图像的像素值、文字的意义,甚至是神经网络中每一层的数据传递。向量的灵活性和通用性使它成为深度学习的核心基础之一。
向量的几何视角
1. 向量是“箭头”
在二维平面上,向量可以看成是从原点 (0, 0) 指向某个点的箭头。例如,向量 [3, 4] 对应的箭头就是从 (0, 0) 指向 (3, 4)。这个箭头的长度代表“力量”,方向则表示“指引的方向”。
这种几何视角非常直观,你可以把向量想象成一架纸飞机。纸飞机的方向就是向量的方向,飞行的距离就是向量的长度。
2. 维度是什么?
维度是向量包含的数字个数。比如,向量 [1, 2] 是二维的,而 [1, 2, 3] 是三维的。如果再高一维,那就像你在玩一个复杂的游戏地图,虽然看不到全貌,但数学帮我们描述了它。
想象你在学校操场踢足球,二维的向量可以描述球在地面上的位置。而如果加上高度,就变成了三维向量,描述足球在空中的位置。
向量的长度与方向
1. 长度(模)
长度用来表示向量的“强度”。计算公式是:
||v|| = sqrt(x1^2 + x2^2 + ... + xn^2)
比如,向量 [3, 4] 的长度是:
||[3, 4]|| = sqrt(3^2 + 4^2) = 5.
你可以想象一个跑步的情景:向量的长度就像是你跑过的距离,告诉你跑得有多远。
2. 方向
方向告诉我们向量“指向哪里”。在深度学习中,数据的方向可以帮助我们理解数据的分布趋势,比如判断一组图片属于哪个类别。
想象一个指南针,它的指针永远指向北方。而向量的方向,就像这个指南针一样,为我们提供指引。
3. 归一化
如果你只关心方向而不在意长度,可以通过归一化让向量的长度变为 1:
v^ = v / ||v||.
归一化后的向量叫“单位向量”,它表示同样的方向,但长度被标准化。
举个例子,假如你是地图上的一个旅行者,你不需要知道从一个地点到另一个地点的确切距离,而是只关心应该往哪个方向走。这时,单位向量就派上用场了。
向量的基本运算
向量像乐高积木,可以通过简单的操作组合出更复杂的模型。
1. 向量加法
两个向量相加,就像把两支箭头连接起来,最终得到一个新的箭头:
[1, 2] + [3, 4] = [4, 6].
想象你在滑雪时,从山顶滑到半山腰,再从半山腰滑到山脚。向量加法可以描述你完整的滑行路径。
2. 数乘
向量与一个数字相乘会拉伸或缩短向量的长度:
2 * [1, 2] = [2, 4].
如果你拿着一个弹簧,数乘就像拉伸或压缩弹簧,使它变得更长或更短。
3. 点积(内积)
点积用来衡量两个向量的“相似性”:
v . w = x1*y1 + x2*y2 + ... + xn*yn.
例如:
[1, 2] . [3, 4] = 1*3 + 2*4 = 11.
点积越大,两个向量越“对齐”。
想象两支手电筒的光束,如果光束方向完全一致(相似性大),它们的亮度会更强。
向量在深度学习中的作用
1. 表示数据
- 图像数据:
一张 28×28 的灰度图像可以展开成一个 784 维的向量,每个数字对应一个像素值。 - 文本数据:
单词或句子可以用词嵌入技术(如 Word2Vec)转化为向量,捕捉文字间的语义关系。
想象每个向量是一个小抽屉,抽屉里装着描述图像或文字的“特征”。深度学习的任务就是根据这些特征做出预测或判断。
2. 神经网络中的计算
神经网络的每一层都可以看作一组向量。计算时,向量通过加权求和和激活函数变换:
z = W * x + b.
其中:
x是输入向量,W是权重矩阵,b是偏置向量。
这个过程类似于学生的考试成绩:x 是学生的答题情况,W 是评分标准,b 是老师给的额外分数,最终得到考试总分 z。
3. 比较相似性
在推荐系统中,向量之间的相似性(比如余弦相似度)用来推荐类似的内容:
cosine_similarity = (v . w) / (||v|| * ||w||).
比如,向量 [1, 0, 0] 和 [0.8, 0.2, 0] 的相似度很高,可能代表两首风格相近的歌曲。
案例:图像分类中的向量
假设我们要开发一个应用,能识别一张图片中是否有一只猫。我们会输入一张图片,并希望模型告诉我们结果是“猫”还是“非猫”。
图片的向量化
在计算机中,图像是以像素的形式表示的。例如,一张灰度图像(黑白图像)可以看成由许多小方格(像素)组成,每个像素的亮度用一个数字表示,通常在 0(黑色)到 255(白色)之间。

比如,一张 28 × 28 的灰度图像可以表示为一个 28 × 28 的矩阵:

其中,每个 表示第 (i) 行第 (j) 列像素的亮度值。
为了方便数学运算,我们将图像矩阵“展平”为一个长向量:
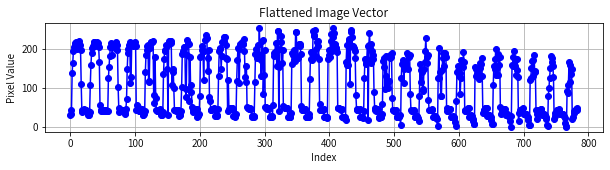
这个向量的维度是 ,即有 784 个元素。
向量在神经网络中的作用
向量是深度学习的核心,因为它将复杂的数据(如图像、声音或文本)转化为机器能理解的数字形式,并让我们能够使用线性代数来处理它们。接下来我们通过两个核心步骤展示向量的作用:
1. 向量与权重的作用:特征提取
在深度学习中,神经网络的每一层会对输入数据进行线性变换。假设我们有一个简单的神经网络,它的第一层只包含 10 个神经元。每个神经元用一个权重向量来表示,用以捕捉输入数据的特定特征。比如:
其中, 是第一个神经元的权重向量,它会与输入向量 做点积运算:
这里, 是偏置项,用于调整结果。
点积的结果 是一个单一的数字,代表这个神经元对输入数据的“反应强度”。每个神经元通过类似的运算提取不同的特征。第一层的输出将是一个 10 维的向量:
这意味着,输入图像通过第一层网络后被转化成一个新的特征向量。
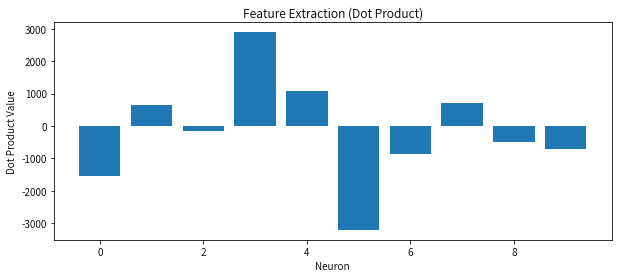
2. 激活函数:非线性变换
在实际问题中,图像的分类通常是非线性的。因此,为了增加网络的表达能力,特征向量会通过一个激活函数(如 ReLU 函数):
ReLU 函数的作用是让输出中的负值变成 0,增强模型的非线性能力。
激活后的向量:
是这一层的最终输出,并作为下一层的输入。
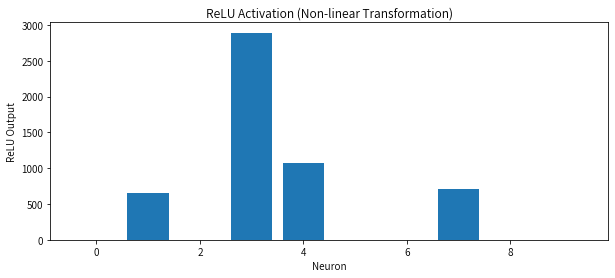
从向量到预测结果
网络的最后一层通常使用一个 Softmax 函数将输出的向量转化为概率分布。例如,假设网络的最后输出是一个 2 维向量:
通过 Softmax 计算每个类别的概率:
最终,模型会将概率最大的类别作为预测结果。
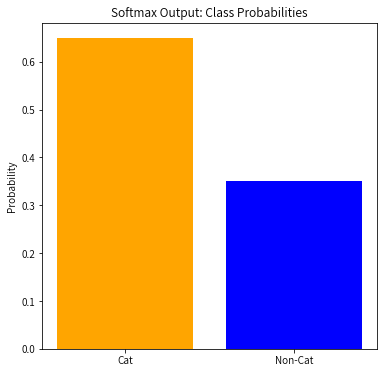
为什么向量重要?
- 数据表示:向量可以将复杂数据(如图像、文本、语音)转化为机器能处理的数值形式。
- 特征提取:向量与权重的点积提取数据的特征,用数学运算模拟人类的感知能力。
- 高效运算:向量化操作(如矩阵乘法)能极大提升计算效率,是深度学习算法高效实现的关键。
- 数学优美:向量让我们能够以简单优雅的数学语言表达复杂的计算过程。
通过这个案例,我们可以清楚看到向量在深度学习中的核心作用:从输入数据的表示到特征提取、再到分类预测,向量贯穿了整个过程。希望这样的讲解能够帮助读者理解深度学习的数学基础及其实际意义!

- 点赞
- 收藏
- 关注作者
评论(0)