MS SQL Server partition by 函数实战 统计与输出

需求
假设有一课程项目,我们需要统计该项目中的课件数量,并提取课程信息,如课程标题名称、排序号等,如果使用 GROUP BY 聚合函数,则只能统计返回课件项目及对应的课件数量一条记录,无法显示明细信息,对于终端想要进行输出的话,此时 partition by 就派上用场了。
输出如下图:
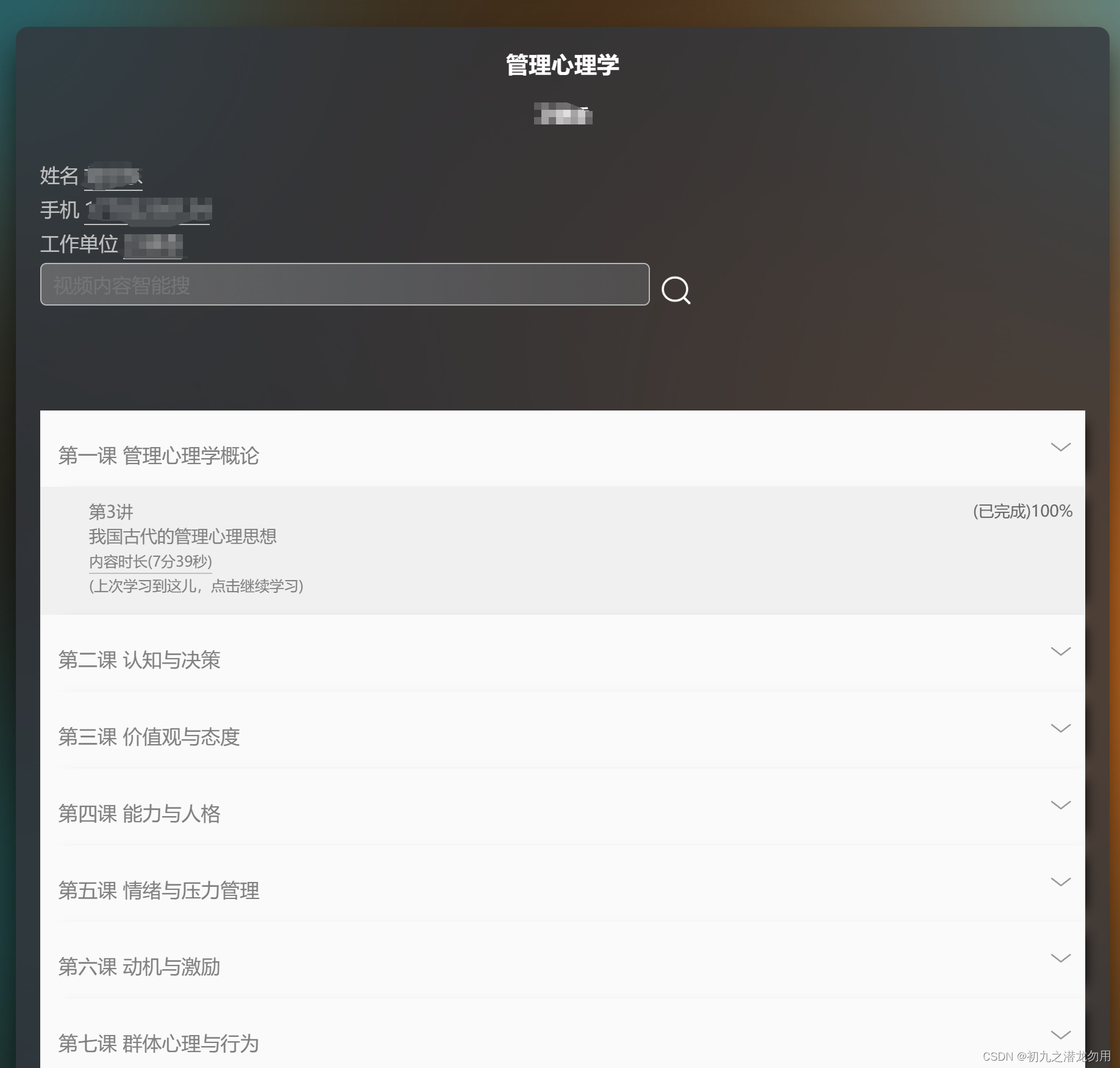
![]()
在管理心理学项目里包括若干课程,我们将根据排序号进行分类输出,显示课程的明细内容并继续其它业务操作。
范例运行环境
操作系统: Windows Server 2019 DataCenter
数据库:Microsoft SQL Server 2016
表及视图样本设计
主表 [ms_project_ep] 项目课程明细表设计如下:
| 序号 | 字段名 | 类型 | 说明 | 备注 |
|---|---|---|---|---|
| 1 | cid | uniqueidentifier | 唯一标识 | |
| 2 | project_cid | uniqueidentifier | 所属项目ID | 对应项目表 |
| 3 | lession_cid | tinyint | 所属课程ID | 对应课程表 |
| 4 | sortid | int | 排序号 | 总排序号 |
查询分析器结果数据显示如下图:

![]()
select cid,project_cid,lession_cid,sortid
from ms_project_ep
order by project_cid,sortid如图我们对项目ID、总排序号进行排序。
数据统计实现
假设统计视图可查询课程项目ID、课程ID、排序号和课程数, 统计表设计如下:
| 序号 | 字段名 | 类型 | 说明 | 备注 |
|---|---|---|---|---|
| 1 | project_cid | uniqueidentifier | 项目ID | |
| 2 | lession_cid | uniqueidentifier | 课程ID | |
| 3 | lcount | int | 课程总数 | 通过项目ID进行分区 |
| 4 | sortid | int | 排序号 | 每分区排序号从1开始 |
查询分析器结果数据显示如下图:
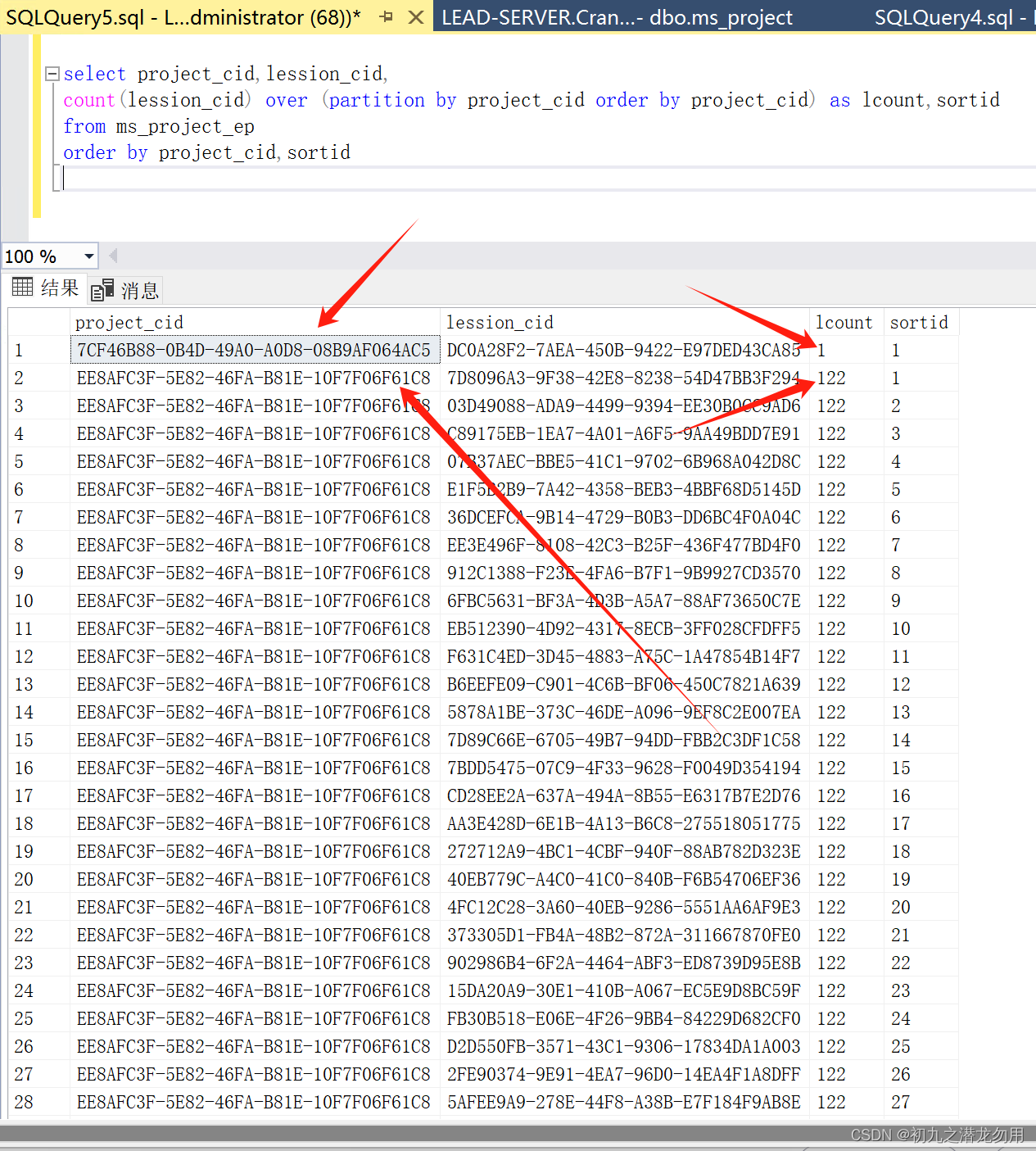
![]()
如图我们看到查询结果按项目ID进行分区,并统计课程数,
如项目ID:7CF46B88-0B4D-49A0-A0D8-08B9AF064AC5,包含了1个课程;
项目ID:EE8AFC3F-5E82-46FA-B81E-10F7F06F61C8,包含了122个课程;
并且每一个分区提取排序号,从1开始。
SQL 语句如下:
select project_cid,lession_cid,
count(lession_cid) over (partition by project_cid order by project_cid) as lcount,
sortid
from ms_project_ep
order by project_cid,sortid关键说明见下表:
| 序号 | 关键语句 | 说明 |
|---|---|---|
| 1 |
count(lession_cid) over (partition by project_cid order by project_cid) as lcount |
partition by project_cid order by project_cid,按项目ID分区并排序; 使用count函数统计课程数; |
小结
partition by 的聚合统计和使用还有很多种,如下表:
| 序号 | 统计项 | 说明 |
|---|---|---|
| 1 | row_number() | 记录总排序号 |
| 2 | rank() | 排序,有并列则按总数递增,如两个第1后是第3 |
| 3 | dense_rank() | 排序,有并列则按上一数值递增,如两个第1后是第2 |
| 4 | count(字段名) | 求个数 |
| 5 | max(字段名) | 求最大值 |
| 6 | min(这段名) | 求最小值 |
| 7 | sum(字段名) | 求和 |
| 8 | avg(字段名) | 求平均值 |
| 9 | first_value(字段名) | 求第一个值 |
| 10 | last_value(字段名) | 求最后一个值 |
| 11 | lag(字段名,[行数]) |
取指定列,将分区列的数据后错n行,行数不是必选项,默认为0,即不错行 |
| 12 | lead(字段名,[行数]) | 取指定列,将分区列的数据前错n行,行数不是必选项,默认为0,即不错行 |
更多学习还请参阅:
至此 partition by 的使用我们就介绍到这里,具体使用中我们还需要灵活掌握。对结果数据的前端输出这里不再详述,需要根据数据的结构以满足我们的设计输出。
感谢您的阅读,希望本文能够对您有所帮助。

- 点赞
- 收藏
- 关注作者
评论(0)