Ascend推理组件MindIE LLM

【摘要】 MindIE LLM是MindIE解决方案下的大语言模型推理组件,基于昇腾硬件提供业界通用大模型推理能力,同时提供多并发请求的调度功能,支持Continuous Batching、PageAttention、FlashDecoding等加速特性,使能用户高性能推理需求。
MindIE LLM是MindIE解决方案下的大语言模型推理组件,基于昇腾硬件提供业界通用大模型推理能力,同时提供多并发请求的调度功能,支持Continuous Batching、PageAttention、FlashDecoding等加速特性,使能用户高性能推理需求。
MindIE LLM主要提供大模型推理Python API和大模型调度C++ API。
1 MindIE LLM架构
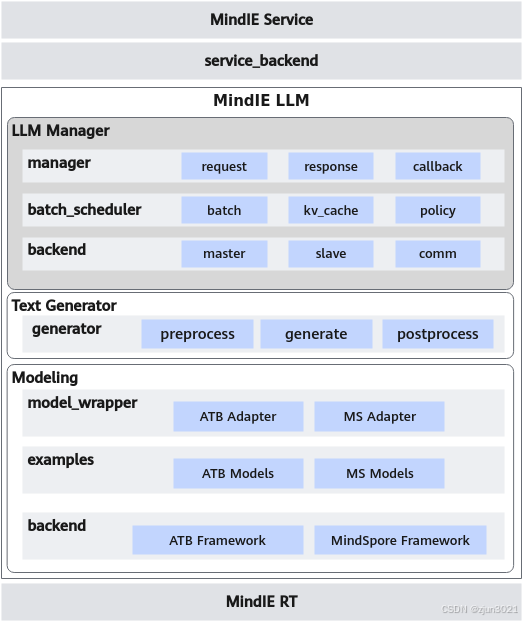
MindIE LLM总体架构分为三层:Modeling和Text Generator、LLM Manager。
1 Modeling
提供深度定制优化的模块和内置模型,支持ATB Models和MindFormers两种框架。
- 内置模块包括Attention、Embedding、ColumnLinear、RowLinear、MLP,支持Weight在线Tensor切分加载。
- 内置模型使用内置模块进行组网拼接,支持Tensor切分与PipeLine切分,支持多种量化方式,用户亦可参照样例通过内置模块组网自定义模型。
- 组网后的模型经过编译优化后,会生成能在昇腾NPU设备上加速推理的可执行图。
2 Text Generator
负责模型配置、初始化、加载、自回归推理流程、后处理等,向LLM Manager提供统一的自回归推理接口,支持并行解码插件化运行。
3 LLM Manager
负责状态管理及任务调度,基于调度策略实现用户请求组batch,统一内存池管理kv缓存,返回推理结果,提供状态监控接口。本层具体介绍及功能后续上线。
2 MindIE LLM接口示意图
MindIE LLM Modeling底层提供三种形式的模型后端(ATB Models、MindFormers合pytorch(开发中)),满足不同用户的使用需求。

术语/缩略语 含义
| 术语/缩略语 | 含义 |
|---|---|
| LLM | Large Language Model,大语言模型。 |
| TGI | Text Generation Inference,文本生成推理。是一个用于部署和服务大型语言模型的工具包。TGI为最流行的开源LLM提供高性能文本生成,包括Llama、Falcon、StarCoder、BLOOM、GPT-NeoX等。 |
| vLLM | vLLM是一个开源的大模型推理加速框架。 |
| Trition | Triton是一个开源的推理服务软件,全称为Triton Inference Server。通过Triton,您可以在基于GPU或CPU的各种基础架构(云、数据中心或边缘)上部署、运行和扩展来自任何框架的AI模型。 |
| ContinuousBatching(CB) | 连续批处理(Continuousbatching),也称为动态批处理或基于迭代级的批处理,是一种针对提升LLM迭代推理性能的优化手段,可以减少调度空泡,提升业务吞吐 |
| PagedAttention(PA) | 自回归过程中缓存的K和V张量非常大,PagedAttention灵感来自于操作系统中虚拟内存和分页的经典思想,它可以允许在非连续空间里存储连续的KV张量 |

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)