SelfAttention在Ascend上的实现

1 SelfAttention是什么?
Self-Attention(自注意力)机制是深度学习领域的一种重要技术,尤其在自然语言处理(NLP)任务中得到广泛应用。它是 Transformer 架构的核心组成部分之一,由 Vaswani 等人在 2017 年提出的论文《Attention is All You Need》中首次介绍。Self-Attention 机制使模型能够在处理序列数据时关注到输入序列的不同部分,从而更好地捕捉上下文关系。
以下介绍来自于知友晚安汤姆布利多的博客,写的非常好,通俗易懂,这里直接引用了。
从零实现Transformer
注意力机制简介
其实注意力机制并不是一个新鲜概念,而且这一概念也不仅仅局限于深度学习领域。以我们人类为例,当我们在通过面相判断一个人的性别时,那么我们人眼的注意力可能就主要放在这个人的脸上,看鼻子、眼睛、耳朵等。当我们通过肢体动作判断运动员所从事的运动时,可能又会关注这个人手脚的肢体动作,而不关注这个人的长相。这一现象在神经网络中也存在(神经网络和人类的感知机理完全不同,仅作类比),如下图图2所示:

上图中,热力图的颜色越深表示网络对这一区域的关注程度越高。可以看到,边牧面部和前胸区域的颜色较深,但是地面、背景的树等的颜色较浅,这说明神经网络可以学到“不同区域的对于当前任务的重要性不同”。
注:热力图(saliency map)的画法多种多样,无固定范式,如有兴趣请自行Google。
值得注意的是,上图所示的热力图是训练完成之后我们采取一些专门为了注意力可视化而设计的方法得到的,比如计算模型输出对于图像输入的每个原始像素点的梯度,然后认为梯度越大的点模型的关注度越高。但是,我们在模型训练的时候却并不一定要求模型直接学习到模型输出和输入之间的注意力,比如CNN中,我们仅仅只是通过反向传播的方式来更新卷积核的权重,但是并没有任何和注意力直接有关的约束。而Transformer,则是直接以注意力机制为主要构成模块的主干网络。
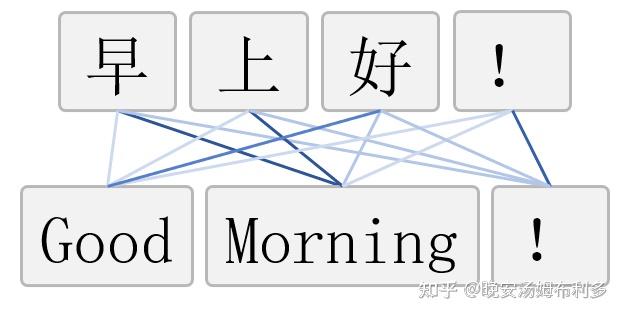
再举一个例子,假如我们想把“早上好!”这句中文翻译成对应的英文“Good Morning!”。我们现在把“早上好!”作为模型输入,“Good Morning!”作为模型输出,那么模型在尝试着拟合输入输出关系的时候,应当可以关注到对于输出的某一部分,输入的不同部分的重要性是不一样的。
具体来讲,“Good”和“好”的关联性最强,和“早上”以及“!”的关联性较弱;“Morning”和“早上”的关联性最强,和“好”以及“!”的关联性较弱;“!”和“!”的关联性最强,和“早上”以及“好”的关联性较弱。如下图所示,其中线条的颜色的颜色深浅表示相连的输入输出字符之间的关联性,颜色越深表示关联性越大。这一“关联性”,其实就是注意力的体现。
好了,说了这么多。那么我们来看Transformer中的注意力机制的实现方式吧!
很形象。。。
Transformer中用的注意力机制包括Query ( Q),Key ( K)和Value ( V )三个组成部分(学习过数据库的同学对这三个名词应该比较熟悉)。可以这样理解,V 是我们手头已经有的所有资料,可以作为一个知识库;Q 是我们待查询的东西,我们希望把V 中和 Q有关的信息都找出来;而 K是 V 这个知识库的钥匙 ,V中每个位置的信息对应于一个 K。对于V 中的每个位置的信息而言,如果 Q和对应钥匙 的匹配程度越高,那么就可以从该条信息中找到和 Q更多的内容。
举个例子,我们现在希望给四不像找妈妈。以四不像作为 Q ,以[鹿 ,牛 ,羊 ,驴,青蛙 ]同时作为V 和K ,然后发现四不像和鹿的相似度为1/3、和牛的相似度为1/6,和羊、驴的相似度均为1/4,和青蛙的相似度为0,那么最终的查询结果就是1/3鹿+1/6牛+1/4羊+1/4驴+0青蛙。
从上面的描述可以看出,计算注意力的流程可以分解为以下两个步骤:
- 计算 Q和 K 的相似度
- 根据计算得到的相似度,取出 V 每条信息中和 Q 有关的内容
Transformer中注意力的计算方法也可以大致分为上面两步。
我们以下面的例子为例。计算过程的简要图如下图所示(美观起见,保留至两位小数),详细分析附后。


1.1 计算Q和K的相似度
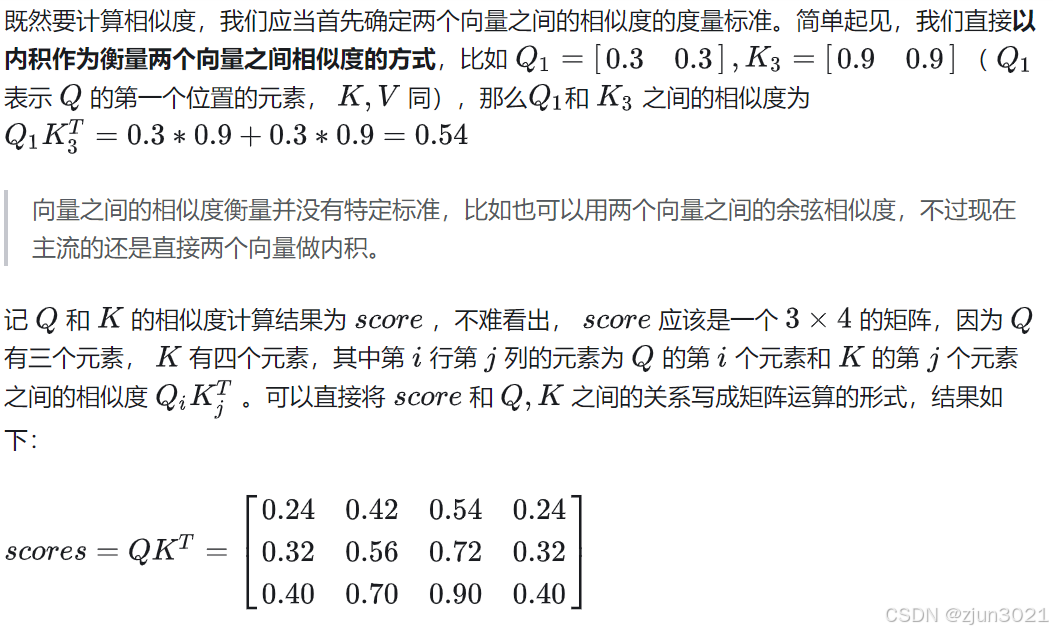
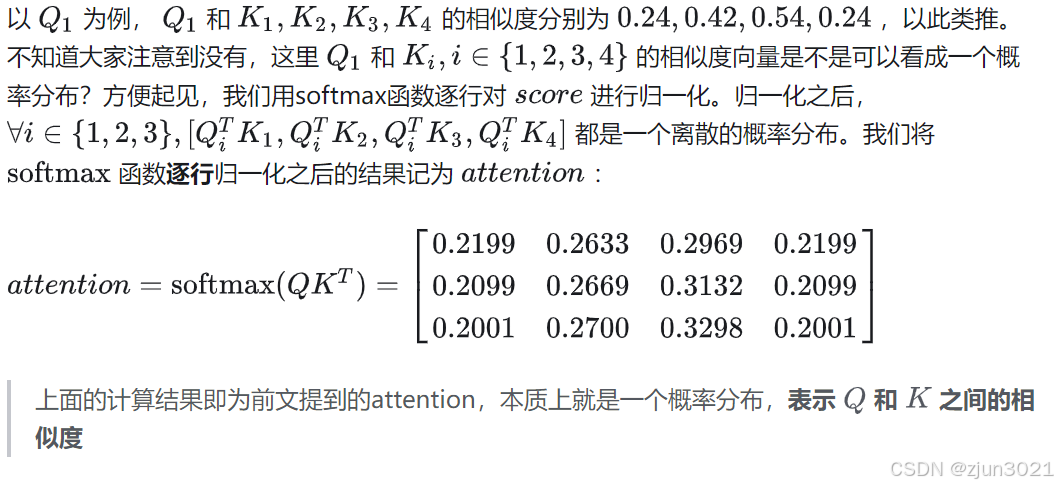
1.2 取出V中每条信息中和Q有关的内容

1.3 注意力机制解释


多头注意力机制的伪代码如下:
q_len, k_len, v_len = ...
batch_size, hdim = ...
head_dim = ...
assert hdim % head_dim = 0
assert k_len == v_len
num_head = hdim // head_dim
q = tensor(batch_size, q_len, hdim)
k = tensor(batch_size, k_len, hdim)
v = tensor(batch_size, v_len, hdim)
def multi_head_split(x):
# x: (batch_size, len, hdim)
b, l, hdim = x.size()
x = x.reshape(b, l, num_head, head_dim).transpose(1, 2) # (b, num_head, l, dim)
return x
def multi_head_merge(x, b):
# x: (batch_ize, num_head, len, head_dim)
b, num_head, l, head_dim = x.size()
x = x.transpose(1, 2).reshape(b, l, num_head * head_dim) #(batch_size, l, hdim)
return x
q, k, v = map(multi_head_split, [q, k, v])
output = MultiHeadAttention(q, k, v) # 该函数的具体实现后文给出
output = multi_head_merge(output, batch_size)
多头注意力机制目前已经是Transformer的标配,通常每个注意力头的维度为64,注意力头的个数为输入维度除以64。
在Transformer原文中,作者并没有对多头注意力机制的motivation做过多的阐述,后来也有研究发现多头并不一定比单头好,参考论文<<Are sixteen heads really better than one?>>[1],不过目前基本都是默认用的多头注意力。
1.4 Scaled Dot-Product Attention

2 SelfAttention概念总结
2.1 自注意力机制的基本概念
Query (Q):查询向量,代表了模型需要关注的部分。
Key (K):键向量,代表了输入序列中各个位置的信息。
Value (V):值向量,包含了实际的信息内容。
自注意力机制的工作流程包括以下几个步骤:
- 线性变换:首先将输入数据通过三个不同的线性变换(即三个权重矩阵)得到 Query、Key 和 Value 向量。
- 计算注意力分数:将 Query 向量与所有 Key 向量进行点积操作,并将结果除以 Key 向量的维度开根号,以获得未归一化的注意力得分(有时称为注意力分数)。
- Softmax 归一化:对注意力得分应用 Softmax 函数,将其转换为概率分布。
- 加权求和:将 Value 向量与经过 Softmax 归一化的注意力得分相乘,得到加权后的值向量,然后对这些加权后的值向量求和,得到最终的输出。
2.2 特点
- 并行计算:自注意力机制可以并行处理序列中的所有位置,这使得模型能够更快地训练。
- 长距离依赖:自注意力机制能够有效捕捉输入序列中的长距离依赖关系。
- 适应性强:自注意力机制可以根据输入数据的不同自动调整其关注的焦点,提高了模型的灵活性。
2.3 多头注意力
在实践中,经常会使用多头注意力(Multi-Head Attention)机制来增强模型的表现力。多头注意力允许模型在同一位置学会关注不同的信息,通过将输入数据分成多个不同的头部(head),每个头部独立进行自注意力计算,最后将所有头部的结果合并起来作为最终的输出。
2.4 与Paged Attention的关系
Self-Attention 和 Paged Attention 都是为了处理序列数据而设计的机制,但它们解决的问题略有不同。Self-Attention 更关注于如何在序列内部建立联系,而 Paged Attention 主要解决的是如何处理超长序列的问题。在某些情况下,Paged Attention 可能会结合 Self-Attention 来实现更高效的长序列处理.
3. Ascend上的Self-Attention实现
SelfAttention在ascend上实现是通过atb算子实现的,如下:
SelfAttentionOperation-atb/infer_op_params.h-Ascend Transformer Boost加速库接口-CANN商用版8.0.RC2.2开发文档-昇腾社区

- 点赞
- 收藏
- 关注作者
评论(0)