Linux 性能优化之CPU 多级缓存

写在前面
- 博文内容为 Linux CPU 多级缓存认知
- 内容涉及:
- 什么是CPU多级缓存认知,CPU 硬件缓存信息,缓存流程写入策略,映射算法认知
- CPU 缓存分析,使用 valgring 和 Perf 分析CPU 缓存命中情况
- 编码方面 CPU 缓存优化,数据指令缓存,多核缓存命中率优化方式
- 理解不足小伙伴帮忙指正 :),生活加油哦
99%的焦虑都来自于虚度时间和没有好好做事,所以唯一的解决办法就是行动起来,认真做完事情,战胜焦虑,战胜那些心里空荡荡的时刻,而不是选择逃避。不要站在原地想象困难,行动永远是改变现状的最佳方式
CPU 多级缓存认知
什么是多级缓存?
在高性能 Linux 服务器中, 高效的数据访问是核心要素之一。为了实现这一目标,计算机采用了分层的内存体系结构。这种体系结构的设计旨在优化 CPU 获取数据的速度当进程启动时,让 CPU 尽快地获取自己需要的数据。

从离CPU近到远依次是:
寄存器文件(Register File):位于 CPU 内核的最核心部分,最快的存储层级,通常在纳秒级别,直接参与指令执行,存储指令、操作数、临时结果和地址。一级缓存(L1 Cache): 紧邻 CPU 内核,通常分为数据缓存(L1D)和指令缓存(L1I),缓存最近和最频繁访问的数据和指令,减少对主内存的访问。二级缓存(L2 Cache,E$): 位于一级缓存之外,但仍在 CPU 芯片内,通常在几百 KB 到几 MB 之间。三级缓存(L3 Cache,LLC 最长延时高速缓存): 通常位于 CPU 芯片之外,但在同一个封装内,通常在几 MB 到几十 MB 之间,为多个 CPU 核心共享,缓存大量数据和指令,减少跨核心的内存访问延迟。主内存(Main Memory): 位于 CPU 外部,通常在主板上,存储程序和数据的长期存储,供 CPU 需要时访问

位于分层内存体系最顶端的 CPU 寄存器。是计算机中最快的存储单元,其处理速度与 CPU 时钟速度保持一致。
CPU时钟:也称为时钟频率或时钟速度或者 CPU 主频,是指中央处理器(CPU)芯片内部时钟的频率,表示处理器每秒钟执行指令的次数。它是衡量CPU性能的重要指标之一,通常以赫兹(Hz)为单位
Windows 查看 CPU 时钟
PS C:\Users\liruilong> wmic cpu get maxclockspeed
MaxClockSpeed
2419
CPU的最大时钟频率是2419MHz,或者说是2.419GHz
有些 CPU 支持睿频加速技术,实际使用中,处理器能够根据负载情况动态提高频率,比如 i7-12700 的性能核基础频率为 2.1GHz,最大睿频实际为 4.9GHz, 支持超频的 i7-12700K 最大可以达到 5.2GHz

下面为 Linux 查看 CPU 时钟
┌──[liruilong@liruilongs.github.io]-[~]
└─$lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 45 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 2
On-line CPU(s) list: 0,1
Vendor ID: GenuineIntel
Model name: 11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40GHz
11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40GHz,即 2.40GHz

寄存器到一级缓存:CPU 在执行指令时,频繁使用的数据和指令会首先被加载到一级缓存中,以便快速访问。
一级缓存到二级缓存:当一级缓存满载或需要更大容量的数据时,数据会被移动到二级缓存。
二级缓存到三级缓存:类似地,二级缓存中的数据在需要时会被提升到三级缓存,尤其是当多个核心需要共享数据时。
三级缓存到主内存:如果所需数据不在任何缓存中,CPU 会从主内存中读取,同时可能会将这部分数据加载到缓存中以备将来使用。
CPU 缓存机制基于两个基本原理:
空间局部性
如果程序访问了某个内存地址的数据,那么在不久的将来,它很可能也会访问相邻的内存地址的数据。这是因为程序通常会按照一定的顺序访问内存,例如循环遍历数组或连续处理数据块。
基于这一原理,当一个数据被加载到cache时,它附近的数据也会被一并加载, 也就是缓存行, Cache Line,同时硬件预取器能够预测接下来可能需要的数据并提前将其加载到缓存中 , 即预取, Prefetching.
时间局部性
如果程序最近访问过某个数据项,那么它在不久的将来很可能再次访问这个数据项。这是因为许多程序都包含有重复的操作或者会反复引用同一组数据。
基于这一原理,当缓存已满且需要加载新的数据时,CPU会使用缓存淘汰算法如 最近最少使用(LRU)算法选择最长时间未被访问的数据项进行替换,同时如果使用缓存回写策略,会回写到内存,同时会触发其他核的缓存探测,下文我们会介绍。
CPU 缓存比主内存要快很多,虽然主内存的访问速度为 8+纳秒, 但是 CPU缓存 的速度是几个 CPU 时钟周期的时间
主内存访问时间:通常表述为“8+纳秒”,这包括了地址译码、等待DRAM行激活、列选择等一系列步骤。CPU缓存访问时间:可能低至几个纳秒甚至更少,具体取决于缓存的级别和当前负载情况。例如,L1缓存访问可能在3-5个时钟周期内完成,如果CPU运行在3GHz,则每个周期大约为0.33纳秒。
时钟周期(Clock Cycle): CPU 工作的基本时间单位,它决定了 CPU 执行指令的速度。时钟周期是 CPU 主频的倒数,即:
时钟周期 = 1 / CPU主频
CPU运行在 3GHz,这意味着每秒钟CPU可以执行3,000,000,000(30亿)个时钟周期。因此,每个时钟周期的时间为:
每个时钟周期的时间 = 1秒 / 3,000,000,000 = 0.33纳秒
是CPU执行指令所需时间的基本单位。在执行一条指令时,CPU可能需要多个时钟周期。例如,L1缓存访问可能在3-5个时钟周期内完成。这意味着,如果CPU运行在3GHz,L1缓存访问时间可能在0.99纳秒到1.65纳秒之间。
CPU 缓存由更快的 SRAM 构成,而内存是由 DRAM 构成的,SRAM 比内存使用的 DRAM 贵很多:
SRAM(静态随机存取存储器)使用六个晶体管来存储每个位(bit),形成一个触发器(flip-flop)结构。它不需要定期刷新数据,因此称为“静态”。DRAM(动态随机存取存储器)使用一个晶体管和一个电容器来存储每个位(bit)。电容器会随着时间流逝逐渐放电,因此需要定期刷新数据以维持信息。
查看CPU 硬件缓存信息
最简单的办法直接查看CPU缓存信息文件
┌──[root@liruilongs.github.io]-[~]
└─$cat /sys/devices/system/cpu/cpu0/cache/index*/size
48K
32K
1280K
8192K
前两个为一级缓存的指令缓存和数据缓存,下面为二级缓存和三级缓存
也可以直接使用 lscpu 的方式查看
┌──[root@liruilongs.github.io]-[~]
└─$lscpu
架构: x86_64
CPU 运行模式: 32-bit, 64-bit
Address sizes: 42 bits physical, 48 bits virtual
字节序: Little Endian
CPU: 4
在线 CPU 列表: 0-3
厂商 ID: GenuineIntel
型号名称: Intel(R) Xeon(R) Gold 6278C CPU @ 2.60GHz
..............
Virtualization features:
超管理器厂商: KVM
虚拟化类型: 完全
Caches (sum of all):
L1d: 64 KiB (2 instances)
L1i: 64 KiB (2 instances)
L2: 2 MiB (2 instances)
L3: 35.8 MiB (1 instance)
..........
使用 lstopo 也可以査看相关缓存信息(需要安装 hwloc-gui 和 hwloc 软件包)。
hwloc 是一个开源软件包,提供了命令行和图形工具,用于收集和展示硬件信息。它可以帮助用户了解系统中的硬件拓扑结构,包括处理器、缓存、内存、PCI设备和网络设备等
lstopo:是 hwloc 的主要命令行工具,用于展示硬件拓扑结构。它会生成一个图形化的拓扑图,显示处理器、缓存、内存和其他设备的层次结构和拓扑关系,如果没有图形环境,Istopo-no-graphics 可以提供命令行文字信息输出
┌──[root@liruilongs.github.io]-[~]
└─$ yum -y install hwloc
┌──[root@liruilongs.github.io]-[~]
└─$ lstopo-no-graphics
Machine (4226MB)
L3 L#0 (4096KB)
Package L#0
L2 L#0 (512KB) + L1d L#0 (32KB) + L1i L#0 (64KB) + Core L#0 + PU L#0 (P#0)
L2 L#1 (512KB) + L1d L#1 (32KB) + L1i L#1 (64KB) + Core L#1 + PU L#1 (P#1)
Package L#1
L2 L#2 (512KB) + L1d L#2 (32KB) + L1i L#2 (64KB) + Core L#2 + PU L#2 (P#2)
L2 L#3 (512KB) + L1d L#3 (32KB) + L1i L#3 (64KB) + Core L#3 + PU L#3 (P#3)
................
根据输出,可以看到以下组件:
- 机器(Machine):总共有
4226MB的内存容量。 - L3 缓存(L3 L#0):具有
4096KB的容量(CPU 共享)。 - 处理器包(Package):存在两个处理器包(Package L#0 和 Package L#1)。
- 每个处理器包中包含以下组件:
- L2 缓存(L2 L#0 和 L2 L#1):每个 L2 缓存具有
512KB的容量。 - L1 数据缓存(L1d L#0 和 L1d L#1):每个 L1 数据缓存具有
32KB的容量。 - L1 指令缓存(L1i L#0 和 L1i L#1):每个 L1 指令缓存具有
64KB的容量。 - 核心(Core L#0、Core L#1、Core L#2 和 Core L#3):每个处理器包中有四个核心。
- 处理单元(PU L#0、PU L#1、PU L#2 和 PU L#3):每个核心有一个处理单元。
- L2 缓存(L2 L#0 和 L2 L#1):每个 L2 缓存具有
- 每个处理器包中包含以下组件:
通过 -v 选项,可以查看更详细的信息
┌──[root@liruilongs.github.io]-[~]
└─$ lstopo-no-graphics -v
Machine (P#0 local=4327132KB total=4327132KB DMIProductName="VMware Virtual Platform" DMIProductVersion=None DMIProductSerial="VMware-56 4d 75 ae f9 4e 9f ad-ba a0 f4 a3 26 c9 6f ae" DMIProductUUID=AE754D56-4EF9-AD9F-BAA0-F4A326C96FAE DMIBoardVendor="Intel Corporation" DMIBoardName="440BX Desktop Reference Platform" DMIBoardVersion=None DMIBoardSerial=None DMIBoardAssetTag= DMIChassisVendor="No Enclosure" DMIChassisType=1 DMIChassisVersion=N/A DMIChassisSerial=None DMIChassisAssetTag="No Asset Tag" DMIBIOSVendor="Phoenix Technologies LTD" DMIBIOSVersion=6.00 DMIBIOSDate=07/22/2020 DMISysVendor="VMware, Inc." Backend=Linux LinuxCgroup=/ OSName=Linux OSRelease=3.10.0-693.el7.x86_64 OSVersion="#1 SMP Tue Aug 22 21:09:27 UTC 2017" HostName=liruilongs.github.io Architecture=x86_64 hwlocVersion=1.11.8 ProcessName=lstopo-no-graphics)
L3Cache L#0 (size=4096KB linesize=64 ways=16 Inclusive=0)
Package L#0 (P#0 CPUVendor=AuthenticAMD CPUFamilyNumber=23 CPUModelNumber=17 CPUModel="AMD Ryzen 7 2700U with Radeon Vega Mobile Gfx" CPUStepping=0)
L2Cache L#0 (size=512KB linesize=64 ways=8 Inclusive=0)
L1dCache L#0 (size=32KB linesize=64 ways=16 Inclusive=0)
L1iCache L#0 (size=64KB linesize=64 ways=4 Inclusive=0)
Core L#0 (P#0)
PU L#0 (P#0)
L2Cache L#1 (size=512KB linesize=64 ways=8 Inclusive=0)
L1dCache L#1 (size=32KB linesize=64 ways=16 Inclusive=0)
L1iCache L#1 (size=64KB linesize=64 ways=4 Inclusive=0)
Core L#1 (P#1)
PU L#1 (P#1)
...................................
┌──[root@liruilongs.github.io]-[~]
└─$
支持通过以下方式来查看硬件拓扑结构信息
lstopo-no-graphics --output-format txt:以文本格式输出硬件拓扑结构。lstopo-no-graphics --output-format xml:以XML格式输出硬件拓扑结构。lstopo-no-graphics --output-format fig:以FIG格式输出硬件拓扑结构。
下面为一个服务器的 CPU 配置
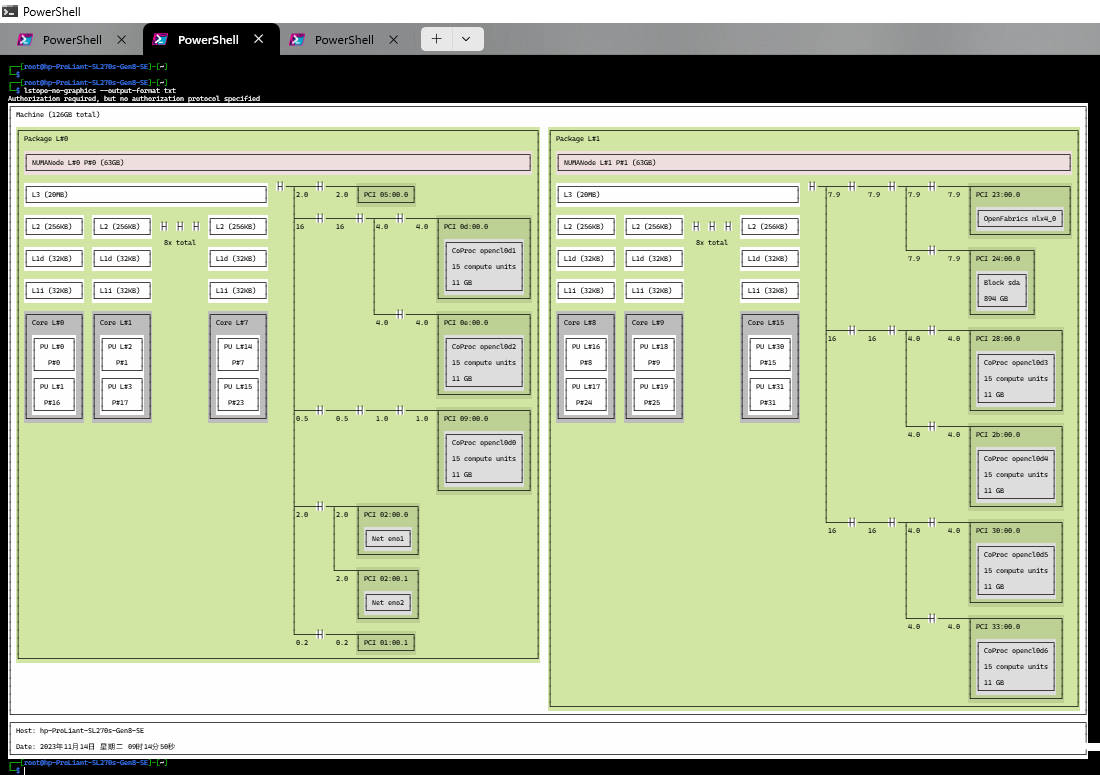
从上面 lstopo 的输出可以看到这个系统的拓扑结构:
- 这是一台双插槽双 处理器(processor) 的服务器,每个 processor 插槽默认安装了一个
AMD EPYC 7002系列的CPU - 每个 CPU 有多个核心,每个核有各级 cache, L1,L2,L3 缓存,L3为共享缓存,L2,L1 为独享缓存
- L3: L3缓存,每个CPU有20MB L3缓存,三级缓存为整个CPU 共享
- L2: L2缓存,每个核有256KB L2缓存
- L1d/L1i: L1数据缓存和指令缓存,每个核32KB
- Core: 物理CPU核
不同级别缓存访问延迟(缓存延迟)
对于 2GHZ 主频的 CPU 来说,一个时钟周期是 0.5 纳秒,可以在 LZMA 的Benchmark https://www.7-cpu.com/ 中找到几种典型 CPU 缓存的访问速度)。
L1缓存访问延迟:
- 数据来自L1缓存的访问延迟为
1纳秒(ns),4~5 个时钟周期 - L1缓存是CPU最接近的高速缓存,通常
集成在CPU芯片内部。 - 因其极短的访问时间,L1缓存对于频繁访问的数据提供了快速的响应。
二级缓存(L2缓存)访问延迟:
- 较大的二级缓存的访问延迟通常是
10纳秒,大约 12 个时钟周期 - L2缓存比L1缓存容量更大,但相应地,其访问速度也稍慢一些。
- 它用于存储那些不常访问但仍需快速访问的数据,作为L1缓存的补充。
主内存访问延迟:
- 主内存(RAM)的访问延迟大约是
60纳秒, 100 个时钟周期以上 - 主内存是计算机的主要存储区域,用于存放程序和数据。
- 相较于缓存,主内存的访问速度明显较慢,但容量更大且成本更低。
不同层级的缓存及主内存具有不同的访问延迟特性,合理利用这些层次结构可以显著提升计算机的性能表现。
缓存流程与写入策略
当处理器引用主存时,高速缓存控制器首先检查请求的地址是否存在于缓存中,以满足处理器的请求。
缓存命中:当处理器请求的数据已经在高速缓存中时,称为缓存命中。这种情况下,处理器可以直接从缓存中获取数据,而不需要访问主内存。

缓存未命中:如果处理器请求的数据不在高速缓存中,则必须从主内存中读取数据。这个过程通常伴随着将数据所在的缓存行(cache line)加载到缓存中,这个过程称为缓存行填充(cache line fill)。
在多处理器系统中,每个处理器都有自己的高速缓存。当一个处理器更新了某个缓存行中的数据时,必须确保其他处理器的高速缓存中的相应数据也被更新或失效,以保持数据的一致性。这个过程称为缓存一致性协议(cache coherence protocol)。

缓存探测(Cache Snooping):是一种缓存一致性协议,其中每个处理器监控(或“窥探”)总线上其他处理器的操作。如果一个处理器检测到另一个处理器更新了某个缓存行,它将根据缓存一致性协议采取适当的行动,比如使自己的缓存行失效或更新它。
缓存一致性的一个副作用是LLC(LastLevelCache)访问延时,即上面的讲的三级缓存访问延时,也叫最后一级访问延时。
- LLC命中但
缓存行未共享,只需要从LLC读取数据,延时约40个CPU周期。 - LLC命中但
缓存行与另一核共享,需要通知其他核,同步缓存内容,延时较长约65个CPU周期。 - LLC命中但
缓存行被另一核修改,需要从内存恢复完整缓存行内容,延时最长约75个CPU周期。
缓存更新数据的方式主要分为直写(Write-Through)和回写(Write-Back)两种。这两种方式各有优缺点,适用于不同的应用场景。
直写(Write-Through)
定义:当缓存中的数据被修改时,这些更改会立即同步到主内存中。

优点:
数据一致性高:由于每次修改都会立即写入主内存,因此缓存和主内存中的数据始终保持一致。不会出现数据丢失的情况:即使在系统崩溃或断电的情况下,由于数据已经写入主内存,因此不会丢失。
缺点:
写入性能较低:每次修改都需要等待数据写入主内存,这会增加写入延迟,降低写入性能。对主内存的磨损较大:频繁的写入操作会增加主内存的磨损,缩短其使用寿命。
回写(Write-Back)
定义:当缓存中的数据被修改时,这些更改首先只保存在缓存中,并不立即写入主内存。只有当缓存中的数据被替换或需要释放空间时,才会将修改后的数据写入主内存。

优点:
写入性能较高:由于修改后的数据首先保存在缓存中,不需要立即写入主内存,因此可以减少写入延迟,提高写入性能。对主内存的磨损较小:由于不是每次修改都写入主内存,因此可以减少主内存的磨损。
缺点:
数据一致性较低:由于修改后的数据可能暂时只保存在缓存中,因此在某些情况下可能会导致缓存和主内存中的数据不一致。存在数据丢失的风险:如果在数据写入主内存之前系统崩溃或断电,那么未写入主内存的数据可能会丢失。
在实际应用中,需要根据具体的需求和场景来选择合适的缓存更新方式。对于需要
高数据一致性和可靠性的应用场景,可以选择直写方式;高性能写入的应用场景,则可以选择回写方式。
缓存映射算法认知
CPU缓存使用不同的绑定算法来存储主内存的数据,每种算法都有其优缺点。CPU缓存经常使用组关联映射方法,这是在全关联映射(开销过大)与直接映射(命中过低)中间找一个平衡点°
通俗的讲,把数据比作很多小盒子(代表主存中的数据),每个小盒子有个编号(主存地址),想把这些小盒子放进一个大柜子(代表缓存)里,但是大柜子里的每个抽屉(缓存被划分为固定大小的块,称为缓存行 cacheline )只能放一个小盒子。
直接映射的方式类似常用的数据类型字典,映射,Map,哈希表全关联映射的方式类似常用的数据类型链表,或者队列组关联映射的方式类似数据类型分组哈希表
缓存行的大小因处理器而异,在 Linux 中可以通过 coherency_line_size 文件查看
┌──[root@liruilongs.github.io]-[~]
└─$cat /sys/devices/system/cpu/cpu0/cache/index1/coherency_line_size
64
index1 缓存中的 coherency_line_size 属性值,这里是64。这通常表示缓存行的大小是64字节。
直接映射缓存(Direct Mapped Cache)
给每个小盒子一个编号(主存地址)。用一个简单的规则(哈希函数)来决定每个小盒子应该放进大柜子的哪个抽屉里。这种方式很简单很快,需要考虑哈希冲突。
原理:
- 每个缓存行只能存储来自主内存中特定地址范围的数据。
- 主内存地址通过一个简单的哈希函数映射到一个特定的缓存行。

优点:
- 实现简单,成本低。
查找速度快,因为每个主内存地址直接对应一个缓存行,不需要在整个缓存中搜索。
缺点:
-缓存命中率较低。当多个不同的主内存地址映射到同一个缓存行时,会发生缓存冲突(cache conflict),导致频繁的缓存行替换。
- 需要额外的逻辑来
处理缓存冲突。
适用场景:
- 对成本和功耗有严格要求的系统。
- 数据访问模式较为简单且重复性高的应用。
全关联缓存(Fully Associative Cache)
大柜子里的每个抽屉都可以放任何一个小盒子。给每个小盒子一个编号(主存地址)。想把一个小盒子放进大柜子的时候,可以选择任何一个空的抽屉放进去。想找一个小盒子的时候,需要打开大柜子的每一个抽屉,一个个地找,直到找到为止。
原理:
- 缓存中的每个缓存行可以存储来自主内存中任何位置的数据。
- 查找数据时需要遍历整个缓存,检查每个缓存行是否包含所需的数据。

优点:
缓存命中率高,因为没有固定的映射关系,减少了缓存冲突的可能性。- 更灵活地利用缓存空间,适合处理不规则的数据访问模式。
缺点:
实现复杂,需要更多的硬件资源和电路设计。查找时间较长,因为需要在所有缓存行中进行搜索。
适用场景:
- 对性能有极高要求的系统。
- 数据访问模式复杂多变的应用。
组关联缓存(Set Associative Cache)
把大柜子分成几个小房间(代表组),每个小房间里有一些抽屉(代表缓存行)。用主存地址的一部分来决定这个小盒子应该放进哪个小房间(组),用另一部分来决定它应该放进小房间里的哪个抽屉(缓存行)。
想找一个小盒子的时候,先看它的编号决定它在哪个小房间里,再去那个小房间里找对应的抽屉就可以了。这种方式比直接映射灵活一些,也比全关联映射快一些,因为它不需要打开每一个抽屉看。
原理:
缓存被分成多个组(set),每个组包含若干个缓存行。- 主内存地址的一部分用于确定数据应该存储在哪个组中,另一部分用于在组内选择具体的缓存行。
- 组关联的程度由“n”决定,即每个组内的缓存行数量,
n通常是2的幂(如2-way、4-way、8-way等)。

优点:
- 结合了直接映射和全关联缓存的优点。
- 相比直接映射,缓存命中率更高,因为同一组内的多个缓存行可以减少冲突。
- 相比全关联,查找时间较短,因为搜索范围限制在一个组内。
缺点:
- 实现复杂度和成本介于直接映射和全关联之间。
- 需要平衡组数和每组的缓存行数以达到最佳性能。
适用场景:
- 大多数现代计算机系统和处理器采用这种模式。
- 适用于各种通用计算任务,能够适应多种数据访问模式。
所以 直接映射缓存 适合简单、低成本的应用场景。全关联缓存: 适合对性能有极致追求且不介意高成本的系统。组关联缓存: 则是折中的方案,广泛用于各种通用和高性能计算环境中。
CPU 缓存分析
通过对 CPU 三级缓存进行分析,进而优化代码,提高执行速度;提起CPU 吞吐。
使用 Valgrind 分析 CPU 缓存
valgrind 实用程序集提供了一组用于内存调试和剖析的工具。
其内的 cachegrind工具允许用户进行缓存仿真,并用缓存缺失的数量对源代码进行注释。
工具安装
sudo apt-get install valgrind # Debian/Ubuntu
sudo yum install valgrind # CentOS/RHEL
在 Rocky Linux 9.4 (Blue Onyx) 下面数据展示不全,Ubuntu 可以正常输出,时间关系我也没找原因,欢迎小伙伴留言讨论 ^_^
┌──[root@liruilongs.github.io]-[~]
└─$hostnamectl
。。。。。。。。。。。。。。。。
Operating System: Rocky Linux 9.4 (Blue Onyx)
CPE OS Name: cpe:/o:rocky:rocky:9::baseos
Kernel: Linux 5.14.0-427.20.1.el9_4.x86_64
Architecture: x86-64
Hardware Vendor: VMware, Inc.
Hardware Model: VMware Virtual Platform
Firmware Version: 6.00
┌──[root@liruilongs.github.io]-[~]
└─$
所以这里使用 ubuntu
┌──[root@liruilongs.github.io]-[~]
└─$hostnamectl
。。。。。。。。
Operating System: Ubuntu 22.04.4 LTS
Kernel: Linux 5.15.0-112-generic
Architecture: x86-64
Hardware Vendor: OpenStack Foundation
Hardware Model: OpenStack Nova
┌──[root@liruilongs.github.io]-[~]
└─$
查看 CPU 缓存信息
┌──[root@liruilongs.github.io]-[~]
└─$cat /sys/devices/system/cpu/cpu0/cache/index*/size
32K
32K
1024K
36608K
分析 hostnamectl 命令的缓存命中情况
┌──[root@liruilongs.github.io]-[~]
└─$valgrind --tool=cachegrind hostnamectl
==2833== Cachegrind, a cache and branch-prediction profiler
==2833== Copyright (C) 2002-2017, and GNU GPL'd, by Nicholas Nethercote et al.
==2833== Using Valgrind-3.18.1 and LibVEX; rerun with -h for copyright info
==2833== Command: hostnamectl
==2833==
--2833-- warning: L3 cache found, using its data for the LL simulation.
--2833-- warning: specified LL cache: line_size 64 assoc 11 total_size 37,486,592
--2833-- warning: simulated LL cache: line_size 64 assoc 18 total_size 37,748,736
Static hostname: liruilongs.github.io
Icon name: computer-vm
Chassis: vm
Machine ID: 42ed7c7740bf4c19a180c6b736d11bbf
Boot ID: 824e0cdaf265442f867746fe1d10c973
Virtualization: kvm
Operating System: Ubuntu 22.04.4 LTS
Kernel: Linux 5.15.0-112-generic
Architecture: x86-64
Hardware Vendor: OpenStack Foundation
Hardware Model: OpenStack Nova
==2833==
==2833== I refs: 3,297,189
==2833== I1 misses: 4,109
==2833== LLi misses: 3,188
==2833== I1 miss rate: 0.12%
==2833== LLi miss rate: 0.10%
==2833==
==2833== D refs: 1,213,021 (855,111 rd + 357,910 wr)
==2833== D1 misses: 43,676 ( 34,627 rd + 9,049 wr)
==2833== LLd misses: 24,966 ( 16,248 rd + 8,718 wr)
==2833== D1 miss rate: 3.6% ( 4.0% + 2.5% )
==2833== LLd miss rate: 2.1% ( 1.9% + 2.4% )
==2833==
==2833== LL refs: 47,785 ( 38,736 rd + 9,049 wr)
==2833== LL misses: 28,154 ( 19,436 rd + 8,718 wr)
==2833== LL miss rate: 0.6% ( 0.5% + 2.4% )
缓存被表示为L1(一级),L2(二级),LL(三级一级)
根据 Valgrind cachegrind 输出,我们可以分析 hostnamectl 命令的缓存命中情况。以下是对输出的详细解析:
- 指令引用:
I refs: 3,297,189,表示在执行hostnamectl命令期间,CPU 指令缓存的总引用次数。可以看出具有非常高的缓存命中率,未命中率仅为0.12%和0.10%,表明指令执行效率高。 - 数据引用:
D refs: 1,213,021 (855,111 rd + 357,910 wr), 表示数据缓存的总引用次数,其中包括读取(rd)和写入(wr)的次数。虽然未命中率较高(3.6%),但仍然在合理范围内
引用次数 = 命中次数 + 未命中次数
指令缓存命中情况
- I1 misses:
4,109,指令缓存(I1)的未命中次数。 - I1 miss rate:
0.12%,指令缓存的未命中率非常低,表明指令缓存的命中情况良好。 - LLi misses:
3,188,这是对低级别指令缓存(LLi)的未命中次数。 - LLi miss rate:
0.10%低级别指令缓存的未命中率同样很低。
数据缓存命中情况
- D1 misses:
43,676,数据缓存(D1)的未命中次数。 - D1 miss rate:
3.6%,数据缓存的未命中率相对较高,表明在数据访问方面,缓存命中率不是特别理想。 - LLd misses:
24,966,低级别数据缓存(LLd)的未命中次数。 - LLd miss rate:
2.1%,低级别数据缓存的未命中率也相对较低。
低级缓存(最后一级,指三级缓存)的引用情况
- LL refs:
47,785 (38,736 rd + 9,049 wr),对低级别缓存的总引用次数,包括读取和写入。 - LL misses:
28,154,低级别缓存的未命中次数。 - LL miss rate:
0.6%,低级别缓存的未命中率相对较低,表明在大多数情况下,低级别缓存能够有效地满足请求。
通过cg_annotate工具对cachegrind.out.2833文件进行注解的结果,它提供了详细的缓存和分支预测分析。
┌──[root@liruilongs.github.io]-[~]
└─$cg_annotate cachegrind.out.2833
--------------------------------------------------------------------------------
I1 cache: 32768 B, 64 B, 8-way associative
D1 cache: 32768 B, 64 B, 8-way associative
LL cache: 37748736 B, 64 B, 18-way associative
Command: hostnamectl
Data file: cachegrind.out.2833
Events recorded: Ir I1mr ILmr Dr D1mr DLmr Dw D1mw DLmw
Events shown: Ir I1mr ILmr Dr D1mr DLmr Dw D1mw DLmw
Event sort order: Ir I1mr ILmr Dr D1mr DLmr Dw D1mw DLmw
Thresholds: 0.1 100 100 100 100 100 100 100 100
Include dirs:
User annotated:
Auto-annotation: on
上面部分为 缓存信息概述
- I1 cache: 指令缓存大小
- 大小: 32 KB
- 行大小: 64 B
- 关联度: 8-way associative(组关联 n 的大小,单个分组的缓存行数据)
- D1 cache: 数据缓存大小
- 大小: 32 KB
- 行大小: 64 B
- 关联度: 8-way associative
- LL cache (低级缓存): 一般是指三级缓存,CPU 共享缓存
- 大小: 37,748,736 B (约 36 MB)
- 行大小: 64 B
- 关联度: 18-way associative
事件记录和显示
- Ir: 指令引用
- I1mr: L1 指令缓存未命中
- ILmr: 低级别指令缓存未命中
- Dr: 数据引用
- D1mr: L1 数据缓存未命中
- DLmr: 低级别数据缓存未命中
- Dw: 数据写入引用
- D1mw: L1 数据缓存写入未命中
- DLmw: 低级别数据缓存写入未命中
接下来的部分是数据统计
--------------------------------------------------------------------------------
Ir I1mr ILmr Dr D1mr DLmr Dw D1mw DLmw
--------------------------------------------------------------------------------
3,297,189 (100.0%) 4,109 (100.0%) 3,188 (100.0%) 855,111 (100.0%) 34,627 (100.0%) 16,248 (100.0%) 357,910 (100.0%) 9,049 (100.0%) 8,718 (100.0%) PROGRAM TOTALS
数据总计
- 指令引用:
3,297,189 - 数据引用:
855,111读取 +357,910写入 - L1 指令缓存未命中:
4,109,未命中率为0.12% - L1 数据缓存未命中:
43,676(34,627 + 9,049),未命中率为3.6%
涉及到的函数的统计
--------------------------------------------------------------------------------
Ir I1mr ILmr Dr D1mr DLmr Dw D1mw DLmw file:function
--------------------------------------------------------------------------------
760,995 (23.08%) 38 ( 0.92%) 18 ( 0.56%) 262,542 (30.70%) 11,342 (32.75%) 976 ( 6.01%) 89,152 (24.91%) 28 ( 0.31%) 3 ( 0.03%) ./elf/./elf/dl-lookup.c:do_lookup_x
391,290 (11.87%) 25 ( 0.61%) 11 ( 0.35%) 86,662 (10.13%) 1,506 ( 4.35%) 943 ( 5.80%) 48,097 (13.44%) 27 ( 0.30%) 1 ( 0.01%) ./elf/./elf/dl-lookup.c:_dl_lookup_symbol_x
370,433 (11.23%) 26 ( 0.63%) 26 ( 0.82%) 91,986 (10.76%) 7,853 (22.68%) 7,493 (46.12%) 42,163 (11.78%) 7,388 (81.64%) 7,318 (83.94%) ./elf/../sysdeps/x86_64/dl-machine.h:_dl_relocate_object
296,478 ( 8.99%) 919 (22.37%) 655 (20.55%) 74,688 ( 8.73%) 204 ( 0.59%) 10 ( 0.06%) 45,590 (12.74%) 15 ( 0.17%) 2 ( 0.02%) ???:???
。。。。。。。。。
54,126 ( 1.64%) 2 ( 0.05%) 2 ( 0.06%) 6,111 ( 0.71%) 3 ( 0.01%) 3 ( 0.02%) 0 0 0 ???:unichar_iswide
46,120 ( 1.40%) 44 ( 1.07%) 28 ( 0.88%) 8,876 ( 1.04%) 0 0 12,842 ( 3.59%) 8 ( 0.09%) 8 ( 0.09%) ???:sd_bus_message_enter_container
43,349 ( 1.31%) 7 ( 0.17%) 3 ( 0.09%) 4,553 ( 0.53%) 0 0 4,189 ( 1.17%) 0 0 ???:utf8_is_valid_n
9,675 ( 0.29%) 2 ( 0.05%) 1 ( 0.03%) 1,935 ( 0.23%) 0 0 0 0 0 ./elf/../sysdeps/generic/ldsodefs.h:do_lookup_x
..................................................
4,417 ( 0.13%) 15 ( 0.37%) 15 ( 0.47%) 883 ( 0.10%) 24 ( 0.07%) 24 ( 0.15%) 768 ( 0.21%) 144 ( 1.59%) 144 ( 1.65%) ./elf/./elf/dl-object.c:_dl_new_object
4,326 ( 0.13%) 3 ( 0.07%) 1 ( 0.03%) 927 ( 0.11%) 0 0 0 0 0 ./malloc/./malloc/malloc.c:malloc_usable_size
3,417 ( 0.10%) 14 ( 0.34%) 8 ( 0.25%) 929 ( 0.11%) 10 ( 0.03%) 7 ( 0.04%) 667 ( 0.19%) 89 ( 0.98%) 89 ( 1.02%) ./string/../sysdeps/x86_64/multiarch/memmove-vec-unaligned-erms.S:memcpy
3,392 ( 0.10%) 17 ( 0.41%) 17 ( 0.53%) 1,142 ( 0.13%) 193 ( 0.56%) 0 484 ( 0.14%) 0 0 ./elf/./elf/dl-reloc.c:_dl_relocate_object
3,334 ( 0.10%) 6 ( 0.15%) 4 ( 0.13%) 654 ( 0.08%) 2 ( 0.01%) 1 ( 0.01%) 653 ( 0.18%) 3 ( 0.03%) 2 ( 0.02%) ./elf/./elf/dl-minimal-malloc.c:__minimal_malloc
具体函数分析
输出的下半部分列出了各个函数的缓存使用情况,包括命中和未命中情况。以下是几个关键函数的分析:
-
do_lookup_x: 数据未命中率最高的函数
- 指令引用: 760,995
- L1 指令未命中: 38 (0.92%)
- 数据引用: 262,542 + 89,152
- L1 数据未命中: 11,342 (32.75%)+ 28 ( 0.31%)
-
_dl_lookup_symbol_x:
- 指令引用: 391,290
- L1 指令未命中: 25 (0.61%)
- 数据引用: 86,662
- L1 数据未命中: 1,506 (4.35%)
-
_dl_relocate_object:
- 指令引用: 370,433
- L1 指令未命中: 26 (0.63%)
- 数据引用: 91,986
- L1 数据未命中: 7,853 (22.68%)
没有找到的源文件
--------------------------------------------------------------------------------
The following files chosen for auto-annotation could not be found:
--------------------------------------------------------------------------------
./elf/../sysdeps/generic/dl-protected.h
./elf/../sysdeps/generic/ldsodefs.h
./elf/../sysdeps/x86_64/dl-machine.h
./elf/./elf/dl-cache.c
。。。。。。。。。。。。。。
./string/../sysdeps/x86_64/strcmp.S
./string/./string/strdup.c
┌──[root@liruilongs.github.io]-[~]
└─$
简单总结
- 命令
hostnamectl的总调用次数为3,297,189次。 - 占用调用次数最多的函数是
do_lookup_x,达760,995次,约占总调用的23.08%。 - 缓存失效率较高的函数有
_do_lookup_x,_dl_relocate_object等,主要集中在数据缓存。
使用 Perf 分析 CPU 缓存
另一个分析内存性能和缓存利用率的工具是 perf。
下面的命令是这云厂商的云电脑上执行的,可以看到全部的事件都不支持,只是输出了命令的总用时,以及在用户态和内核态的执行时间,这里小伙伴可以用手里的机器尝试,通过 perf list 可以获取支持的事件,然后在 -e 后天添加要要跟踪的事件即可。
┌──[root@liruilongs.github.io]-[~]
└─$perf stat -e instructions,cycles,L1-dcache-loads,L1-dcache-load-misses,LLC-load-misses,LLC-loads ./array_test
Starting!
Completed! Time taken: 0.752721 seconds
Performance counter stats for './array_test':
<not supported> instructions
<not supported> cycles
<not supported> L1-dcache-loads
<not supported> L1-dcache-load-misses
<not supported> LLC-load-misses
<not supported> LLC-loads
0.766214055 seconds time elapsed
0.674339000 seconds user
0.091774000 seconds sys
┌──[root@liruilongs.github.io]-[~]
└─$
CPU 缓存优化
优化 CPU 缓存命中率(提升指令缓存和数据缓存命中率)主要依赖于理解缓存与内存之间的数据传输规则和机制,以及通过优化数据结构和算法来增强数据的局部性(空间局部性,时间局部性)。
在这之前,先来看一个常见的 Demo,提升数据缓存命中率,二维数组元素遍历连续读取和非连续读取,大多数的数组都是按照行的方式存放,所以读取的时候,按照行的方式读取要优与列的方式读取。数组存放是在连续的内存中,所以可以利用CPU 缓存行的特性,当数组第一个元素被载入时,可能会把这个元素缓存行其他数据同时载入,这样每次加载多个数据,当读取数组下一个元素,可以直接通过CPU 缓存读取,不需要到内存中。
所以理论上,一个缓存行内,数组元素所占的字节越少,速度越快。
这里我写个简单的 C Demo,对一个二维数组赋值,数据的读取方式为行读取,体会一下CPU数据缓存如何优化
┌──[root@liruilongs.github.io]-[~]
└─$cat array_test.c
#include <stdio.h>
#include <time.h>
#define MAXROW 7000
#define MAXCOL 7000
int main() {
int i, j;
static int x[MAXROW][MAXCOL];
printf("Starting!\n");
clock_t start = clock(); // 记录开始时间
for (i = 0; i < MAXROW; i++) {
for (j = 0; j < MAXCOL; j++) {
x[i][j] = i * j;
}
}
clock_t end = clock(); // 记录结束时间
double time_taken = ((double)(end - start)) / CLOCKS_PER_SEC; // 计算时间
printf("Completed! Time taken: %f seconds\n", time_taken);
return 0;
}
编译之后通过 cachegrind 来分析缓存命中情况
┌──[root@liruilongs.github.io]-[~]
└─$gcc -g -o at array_test.c
这里我们只关注数据缓存
┌──[root@liruilongs.github.io]-[~]
└─$valgrind --tool=cachegrind ./at
..........
==6255==
==6255== D refs: 448,079,176 (384,057,719 rd + 64,021,457 wr)
==6255== D1 misses: 4,002,309 ( 1,650 rd + 4,000,659 wr)
==6255== LLd misses: 4,002,005 ( 1,389 rd + 4,000,616 wr)
==6255== D1 miss rate: 0.9% ( 0.0% + 6.2% )
==6255== LLd miss rate: 0.9% ( 0.0% + 6.2% )
......
┌──[root@liruilongs.github.io]-[~]
└─$
可以看到无论是一级缓存还上是三级缓存,数据缓存的未命中率很低,集中在写缓存未命中 :
==6255== D1 miss rate: 0.9% ( 0.0% + 6.2% )
分析一个生成的注释文件,输出文件很长,这里我们只关注对应的 C 执行文件的数据统计和 对代码的注释
┌──[root@liruilongs.github.io]-[~]
└─$cg_annotate cachegrind.out.6255
--------------------------------------------------------------------------------
................
--------------------------------------------------------------------------------
Ir I1mr ILmr Dr D1mr DLmr Dw D1mw DLmw file:function
--------------------------------------------------------------------------------
896,056,031 (99.98%) 2 ( 0.14%) 2 ( 0.14%) 384,024,007 (99.99%) 2 ( 0.12%) 2 ( 0.14%) 64,008,009 (99.98%) 4,000,000 (99.98%) 4,000,000 (99.98%) /root/array_test.c:main
这些指标表示的是程序执行过程中,不同层次的缓存命中和未命中的情况。下面是每个指标的具体含义:
Ir (Instruction Reads): 指令读取次数。: 896,056,031 (99.98%): 程序执行期间总共读取了将近9亿条指令,占总指令读取次数的99.98%。
I1mr (First-Level Instruction Cache Misses): 第一级指令缓存未命中次数。: 2 (0.14%): 在第一级指令缓存中,只有2次未命中,占总指令读取次数的0.14%。
ILmr (Last-Level Instruction Cache Misses): 最后一级指令缓存未命中次数。: 2 (0.14%): 在最后一级指令缓存中,也只有2次未命中,占总指令读取次数的0.14%。
Dr (Data Reads): 数据读取次数。: 384,024,007 (99.99%): 程序执行期间总共进行了约3.84亿次数据读取操作,占总数据访问次数的99.99%。
D1mr (First-Level Data Cache Misses): 第一级数据缓存未命中次数。: 2 (0.12%): 在第一级数据缓存中,只有2次未命中,占总数据读取次数的0.12%。
DLmr (Last-Level Data Cache Misses): 最后一级数据缓存未命中次数。: 2 (0.14%): 在最后一级数据缓存中,也只有2次未命中,占总数据读取次数的0.14%。
Dw (Data Writes): 数据写入次数。: 64,008,009 (99.98%): 程序执行期间总共进行了约6400万次数据写入操作,占总数据访问次数的99.98%。
D1mw (First-Level Data Cache Misses on Writes): 第一级数据缓存写入未命中次数。: 4,000,000 (99.98%): 在第一级数据缓存中,有将近400万次写入未命中,占总数据写入次数的99.98%。
DLmw (Last-Level Data Cache Misses on Writes): 最后一级数据缓存写入未命中次数。: 4,000,000 (99.98%): 在最后一级数据缓存中,也有将近400万次写入未命中,占总数据写入次数的99.98%。
file:function: 所有这些指标都是针对 /root/array_test.c 文件中的 main 函数的。
这里有两个指标有些看不太懂,为什么在 6400 万次数据写入(Dw)中有 400 万次写入未命中(D1mw),而未命中率达到 99.98%。?
未命中率的计算公式为:
未命中率 = 未命中次数 / 总写入次数 * 100%
代入公式计算未命中率:
4,000,000/64,008,009 X 100% = 6.25%
这正好符合上面的数据: D1 miss rate: 0.9% ( 0.0% + 6.2% )
实际上 99.98% 是指/root/array_test.c 文件中的 main 函数 的 Dw ,D1mr, DLmr 指标和总体的比例。
下面为对 函数栈的注解,横坐标指标值和上面一样,纵坐标为 程序计数器位置
--------------------------------------------------------------------------------
-- Auto-annotated source: /root/array_test.c
--------------------------------------------------------------------------------
Ir I1mr ILmr Dr D1mr DLmr Dw D1mw DLmw
. . . . . . . . . #include <stdio.h>
. . . . . . . . . #include <time.h>
. . . . . . . . .
. . . . . . . . . #define MAXROW 8000
. . . . . . . . . #define MAXCOL 8000
. . . . . . . . .
4 ( 0.00%) 0 0 0 0 0 1 ( 0.00%) 0 0 int main() {
. . . . . . . . . int i, j;
. . . . . . . . . static int x[MAXROW][MAXCOL];
. . . . . . . . .
3 ( 0.00%) 0 0 0 0 0 1 ( 0.00%) 0 0 printf("Starting!\n");
. . . . . . . . .
2 ( 0.00%) 0 0 0 0 0 2 ( 0.00%) 0 0 clock_t start = clock(); // 记录开始时间
. . . . . . . . .
24,004 ( 0.00%) 1 ( 0.07%) 1 ( 0.07%) 16,001 ( 0.00%) 0 0 1 ( 0.00%) 0 0 for (i = 0; i < MAXROW; i++) {
192,032,000 (21.43%) 0 0 128,008,000 (33.33%) 0 0 8,000 ( 0.01%) 0 0 for (j = 0; j < MAXCOL; j++) {
704,000,000 (78.55%) 0 0 256,000,000 (66.66%) 0 0 64,000,000 (99.97%) 4,000,000 (99.98%) 4,000,000 (99.98%) x[i][j] = i * j;
. . . . . . . . . }
. . . . . . . . . }
. . . . . . . . .
2 ( 0.00%) 0 0 0 0 0 2 ( 0.00%) 0 0 clock_t end = clock(); // 记录结束时间
7 ( 0.00%) 0 0 3 ( 0.00%) 1 ( 0.06%) 1 ( 0.07%) 1 ( 0.00%) 0 0 double time_taken = ((double)(end - start)) / CLOCKS_PER_SEC; // 计算时间
6 ( 0.00%) 1 ( 0.07%) 1 ( 0.07%) 1 ( 0.00%) 0 0 1 ( 0.00%) 0 0 printf("Completed! Time taken: %f seconds\n", time_taken);
1 ( 0.00%) 0 0 0 0 0 0 0 0 return 0;
2 ( 0.00%) 0 0 2 ( 0.00%) 1 ( 0.06%) 1 ( 0.07%) 0 0 0 }
--------------------------------------------------------------------------------
Ir I1mr ILmr Dr D1mr DLmr Dw D1mw DLmw
--------------------------------------------------------------------------------
896,056,031 (99.98%) 2 ( 0.14%) 2 ( 0.14%) 384,024,007 (99.99%) 2 ( 0.12%) 2 ( 0.14%) 64,008,009 (99.98%) 4,000,000 (99.98%) 4,000,000 (99.98%) events annotated
┌──[root@liruilongs.github.io]-[~]
└─$
主要关注下面的部分,即未命中主要发生在代码 x[i][j] = i * j;
64,000,000 (99.97%) 4,000,000 (99.98%) 4,000,000 (99.98%) x[i][j] = i * j;
上面为顺序读写,下面修改文件,数组连续读取修改为非连续读取,即列读取
for (i = 0; i < MAXROW; i++) {
for (j = 0; j < MAXCOL; j++) {
x[j][i] = i * j;
}
}
重新编译
┌──[root@liruilongs.github.io]-[~]
└─$gcc -g -o ats array_test.c
┌──[root@liruilongs.github.io]-[~]
└─$
通过 valgrind 分析数据缓存命中情况
┌──[root@liruilongs.github.io]-[~]
└─$valgrind --tool=cachegrind ./ats
。。。。。。。
==6512==
==6512== D refs: 448,079,176 (384,057,719 rd + 64,021,457 wr)
==6512== D1 misses: 64,002,309 ( 1,650 rd + 64,000,659 wr)
==6512== LLd misses: 4,002,005 ( 1,389 rd + 4,000,616 wr)
==6512== D1 miss rate: 14.3% ( 0.0% + 100.0% )
==6512== LLd miss rate: 0.9% ( 0.0% + 6.2% )
。。。。。。。
数据缓存的未命中率相对较高: D1 miss rate: 14.3%相对于上面的 6.2% 缓存未命中 率增加了2倍多。
主要是写缓存,并且 一级数据缓存未命中率为 100%,即这写入数据时没有一个一级缓存被命中。
继续分析一下注解文件
┌──[root@liruilongs.github.io]-[~]
└─$cg_annotate cachegrind.out.6512
--------------------------------------------------------------------------------
.................
--------------------------------------------------------------------------------
Ir I1mr ILmr Dr D1mr DLmr Dw D1mw DLmw file:function
--------------------------------------------------------------------------------
896,056,031 (99.98%) 2 ( 0.14%) 2 ( 0.14%) 384,024,007 (99.99%) 2 ( 0.12%) 2 ( 0.14%) 64,008,009 (99.98%) 64,000,000 (100.0%) 4,000,000 (99.98%) /root/array_test.c:main
--------------------------------------------------------------------------------
-- Auto-annotated source: /root/array_test.c
--------------------------------------------------------------------------------
Ir I1mr ILmr Dr D1mr DLmr Dw D1mw DLmw
. . . . . . . . . #include <stdio.h>
. . . . . . . . . #include <time.h>
. . . . . . . . .
. . . . . . . . . #define MAXROW 8000
. . . . . . . . . #define MAXCOL 8000
. . . . . . . . .
4 ( 0.00%) 0 0 0 0 0 1 ( 0.00%) 0 0 int main() {
. . . . . . . . . int i, j;
. . . . . . . . . static int x[MAXROW][MAXCOL];
. . . . . . . . .
3 ( 0.00%) 0 0 0 0 0 1 ( 0.00%) 0 0 printf("Starting!\n");
. . . . . . . . .
2 ( 0.00%) 0 0 0 0 0 2 ( 0.00%) 0 0 clock_t start = clock(); // 记录开始时间
. . . . . . . . .
24,004 ( 0.00%) 1 ( 0.07%) 1 ( 0.07%) 16,001 ( 0.00%) 0 0 1 ( 0.00%) 0 0 for (i = 0; i < MAXROW; i++) {
192,032,000 (21.43%) 0 0 128,008,000 (33.33%) 0 0 8,000 ( 0.01%) 0 0 for (j = 0; j < MAXCOL; j++) {
704,000,000 (78.55%) 0 0 256,000,000 (66.66%) 0 0 64,000,000 (99.97%) 64,000,000 (100.0%) 4,000,000 (99.98%) x[j][i] = i * j;
. . . . . . . . . }
. . . . . . . . . }
. . . . . . . . .
2 ( 0.00%) 0 0 0 0 0 2 ( 0.00%) 0 0 clock_t end = clock(); // 记录结束时间
7 ( 0.00%) 0 0 3 ( 0.00%) 1 ( 0.06%) 1 ( 0.07%) 1 ( 0.00%) 0 0 double time_taken = ((double)(end - start)) / CLOCKS_PER_SEC; // 计算时间
6 ( 0.00%) 1 ( 0.07%) 1 ( 0.07%) 1 ( 0.00%) 0 0 1 ( 0.00%) 0 0 printf("Completed! Time taken: %f seconds\n", time_taken);
1 ( 0.00%) 0 0 0 0 0 0 0 0 return 0;
2 ( 0.00%) 0 0 2 ( 0.00%) 1 ( 0.06%) 1 ( 0.07%) 0 0 0 }
--------------------------------------------------------------------------------
Ir I1mr ILmr Dr D1mr DLmr Dw D1mw DLmw
--------------------------------------------------------------------------------
896,056,031 (99.98%) 2 ( 0.14%) 2 ( 0.14%) 384,024,007 (99.99%) 2 ( 0.12%) 2 ( 0.14%) 64,008,009 (99.98%) 64,000,000 (100.0%) 4,000,000 (99.98%) events annotated
┌──[root@liruilongs.github.io]-[~]
└─$
主要关注一级数据缓存未命中的情况,可以看到 D1mw 的未命中率占整体的 100%,这里并不是只未命中率为 100%,但是实际上一级缓存未命中率刚好是 100%
64,000,000 (99.97%) 64,000,000 (100.0%) 4,000,000 (99.98%) x[j][i] = i * j;
同时对与当前程序计数器对应的代码,所有的写缓存都没有命中,即可以理解为当需要往 x[j][i] 写入数据时,所有的元素获取都是一级缓存之外拿的,即一级缓存没有任何命中,三级缓存未命中 400 万次,即这 400 万次可能是从内存中,或者二级缓存获取的数据
和上面连续读取做简单的对比
# 连续
64,000,000 (99.97%) 64,000,000 (100.0%) 4,000,000 (99.98%) x[j][i] = i * j;
# 非连续
64,000,000 (99.97%) 4,000,000 (99.98%) 4,000,000 (99.98%) x[i][j] = i * j;
数据缓存优化
数据对齐
数据对齐:即确保数据结构中的元素按照缓存行大小对齐,以减少伪共享(False Sharing)。
伪共享(False Sharing)是一种在多处理器系统中常见的性能问题,尤其在并发编程中。当多个线程或进程在不同的CPU核心访问不同的数据项,但这些数据项恰好位于同一个缓存行(Cache Line)中时,就会发生伪共享。
为了确保所有处理器看到的数据是一致的,每个处理器都有自己的缓存,并且存在一种机制(缓存一致性协议(Cache Coherence Protocol))来同步这些缓存(例如MESI协议)。当一个线程修改了它所在缓存行的数据时,该缓存行在其他处理器的缓存中会变为无效(缓存探测)。这意味着其他处理器必须从主内存中重新加载该缓存行(缓存失效),即使它们只访问了该缓存行中的其他数据项。频繁的缓存行失效和重新加载会导致显著的性能开销,因为处理器访问主内存的速度远慢于访问缓存。
常见的解决办法是使用数据对齐的方式,即避免两个不同的数据项位于一个同一个缓存行
// 使用两个变量,模拟 False Sharing
typedef struct {
int32_t counter1; // 假设每个线程都更新这个变量
} SharedData;
在结构体中添加填充以确保每个变量位于不同的缓存行。int32 为 32 字节,所以一个缓存行理论上可以放两个对象
// 使用两个变量,模拟 False Sharing
typedef struct {
int32_t counter1; // 假设每个线程都更新这个变量
char pad[64]; // 数据填充,
} SharedData;
通过填充一个 64 字节的 字符数组,在任何情况下,不会存在两个对象位于一个缓存行,从而避免了伪共享
连续内存分配
连续内存分配:尽量使用连续的内存块来存储数据,可以提高缓存的利用率。利用缓存行,三级缓存的特性。
使用数组,编程语言的数组一般都是在内存中连续分配的数据结构,因此使用数组来存储数据可以保证数据的局部性。
以Java为Demo
int[][] matrix = new int[rows][cols]; // 二维数组
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
matrix[i][j] = i * j; // 访问方式
}
}
使用一维数组模拟二维数组,使用一维数组并手动计算索引来模拟二维数组,可以确保数据在内存中是连续存放的。
int[] array = new int[rows * cols];
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
array[i * cols + j] = i * j; // 通过一维数组访问
}
}
使用 ArrayList 和 List,虽然 ArrayList 和其他列表在内部使用数组,但它们提供的动态扩展功能在某些情况下可能导致内存不连续,,尽量在创建时指定容量,以减少扩展时的复制操作。同时减少频繁的创建销毁对象,避免内存碎片
List<Integer> list = new ArrayList<>(initialCapacity);
for (int i = 0; i < size; i++) {
list.add(i);
}
避免内存碎片
避免内存碎片:合理管理内存分配和释放,以减少内存碎片化。内存碎片话不利于CPU 空间和时间局部性。
避免频繁的对象创建,频繁创建小对象会导致内存碎片,影响性能。可以考虑对象池技术,重用对象。
class ObjectPool {
private List<MyObject> available = new ArrayList<>();
public MyObject acquire() {
if (available.isEmpty()) {
return new MyObject(); // 创建新对象
}
return available.remove(available.size() - 1); // 重用对象
}
public void release(MyObject obj) {
available.add(obj); // 将对象放回池中
}
}
重复利用变量
重复利用变量:在循环中重复使用相同的变量,而不是每次迭代都创建新变量。在下一次迭代中可以从缓存中直接获取变量,不需要重新申请内存
// 使用一个变量重复利用
for (int i = 0; i < ARRAY_SIZE; i++) {
sum += array[i]; // 直接使用 i 作为索引
}
// 每次迭代创建新的变量(不必要的做法)
for (int j = 0; j < ARRAY_SIZE; j++) {
int temp = array[j]; // 每次都创建一个新的 temp 变量
sum += temp; // 使用 temp 进行计算
}
利用预取指令
软件预取:使用编译器提供的预取指令(如__builtin_prefetch)来提前加载可能需要的数据到缓存中。
#include <stdio.h>
void prefetch_array(int* array, int size) {
for (int i = 0; i < size; ++i) {
// 预取当前元素后面的几个元素
if (i + 8 < size) {
__builtin_prefetch(&array[i + 8], 0, 3);
}
// 处理当前元素
// 这里可以添加实际的处理逻辑
}
}
int main() {
int array[100];
// 初始化数组
for (int i = 0; i < 100; ++i) {
array[i] = i;
}
// 预取数组元素
prefetch_array(array, 100);
return 0;
}
在 prefetch_array 函数中,遍历数组并预取当前元素后面的几个元素。这样可以确保在处理当前元素时,后续需要的数据已经在缓存中。
指令缓存优化
循环展开
循环展开,即指定循环步长,通过减少循环控制的开销和增强 CPU 数据指令缓存命中率来提高程序性能。
for (int i = 0; i < N; i++) {
array[i] += 1; // 访问 array[i]
}
展开的循环中,更新循环计数器的次数减少,降低了 CPU 需要执行的指令数量。同时单个循环进行多次相同指令执行,增强了指令局部性,提高指令缓存的命中率
如果是数组,需要考虑索引越界的问题
for (int i = 0; i < N - (N % 4); i += 4) {
array[i] += 1; // 访问 array[i]
array[i + 1] += 1; // 访问 array[i + 1]
array[i + 2] += 1; // 访问 array[i + 2]
array[i + 3] += 1; // 访问 array[i + 3]
}
// 处理剩余的元素
for (int j = N - (N % 4); j < N; j++) {
array[j] += 1; // 处理未被主循环处理的元素
}
循环展开通常意味着在同一次循环迭代中访问相邻的数据元素。多个相邻的数据访问会增加数据的局部性(缓存行),从而提高缓存命中率。减少了对内存的访问次数。这不仅能提高缓存的利用率,还能降低内存访问的延迟。
需要注意的是代码编译器通常会自动进行循环展开,因此在某些情况下,手动展开可能并不必要。同时循环展开的程度需要根据具体情况来决定。过度展开可能导致代码膨胀,增加指令缓存的压力,反而影响性能。
利用分支预测器(有序)
分支预测器在处理条件语句(如if、switch)时起着关键作用。分支预测器尝试预测程序执行路径,以便CPU可以提前获取和执行预测的分支。当预测正确时,这可以显著提高性能,因为CPU不需要等待从内存中获取指令。
分支预测器通常基于历史执行数据来预测未来的执行路径。有两种主要类型的分支预测器:
静态分支预测器:
基于代码结构进行预测,例如,如果if语句的条件总是为真,则预测器将始终预测if分支。
假设我们有一个函数,用于在数组中查找特定元素:
bool search(int array[], int size, int target) {
for (int i = 0; i < size; ++i) {
if (array[i] == target) {
return true;
}
}
return false;
}
有序数组:如果array是有序的,分支预测器可以很好地预测if语句的执行路径。因为数组是有序的,所以一旦找到目标元素,后续的比较将始终失败,这使得分支预测器可以预测if语句将不会执行。
无序数组:如果array是无序的,分支预测器将无法有效预测if语句的执行路径。每次比较的结果都是独立的,没有可预测的模式。
动态分支预测器:
基于历史执行数据进行预测。它们跟踪每个分支的执行历史,并根据这些历史数据预测未来的执行路径。
for(i = 0; i < N; i++) {
if (array [i] < target){
array[i] = 0;
}
}
对于有序数组,分支预测器基于历史执行数据可以预测接下来要在哪段代码执行(比如 if 还是 else 中的指令),就可以提前把这些指令放在缓存中,需要对应的指令直接从指令缓存中获取,提高了指令缓存命中率
配置CPU亲和性优化多核缓存命中率
在上一篇CPU上下文中我们谈到,通过 CPU 配置亲和性,限制特定进程仅在特定的CPU或内核上运行(也称为CPU绑定或CPU亲和性),可以减少CPU上下文切换,CPU 迁移,
同时 绑定 CPU 核心,从CPU 缓存角度考虑,利用CPU缓存局部性。绑定到某个CPU可以确保这些区域的数据和指令更可能驻留在该CPU的缓存中,从而提高了数据指令缓存命中率,降低了访问延迟(CCL)。
关于 CPU 亲和性配置这里简单说明,小伙伴可以看我之前的文章。
通常有三种方法:
taskset
taskset 是一个在 Linux 系统中用于设置或检索进程 CPU 亲和性(affinity)的命令行工具。通过 taskset,你可以控制进程应该在哪些 CPU 核心或哪些 CPU 集合上运行。这对于性能调优和故障隔离特别有用。
┌──[root@liruilongs.github.io]-[~]
└─$taskset -pc 0 3960506
pid 3960506's current affinity list: 0,1
pid 3960506's new affinity list: 0
┌──[root@liruilongs.github.io]-[~]
└─$
通过 systemd 的 service unit 文件配置
systemd 提供了简单的方法可用实现 CPU 资源的亲和性限制。通过在服务的 unit 文件中[Service]块中,添加CPUAffinity= 即可。
[Service]
CPUAffinity=1-3
CPUAffinity=0-3:允许进程在 CPU 核心 0、1、2 和 3 上运行。CPUAffinity=0,2,3:允许进程在 CPU 核心 0、2 和 3 上运行,但不允许在核心 1 上运行
如果一个 unit 文件中有多行 CPUAffinity= 指令,systemd 确实会合并这些设置,但合并的方式是逻辑 OR,而不是逻辑 AND。这意味着只要在任何一行 CPUAffinity= 中列出的 CPU 核心,进程都有权限运行。
也可以使用 命令行的方式
┌──[root@liruilongs.github.io]-[~]
└─$systemctl set-property <service name> CPUAffinity=<value>
使用 cgroup 的 cpuset 进行 CPU 亲和性限制
这里需要注意 cgroup 版本不同,对应的限制方式也不同,在 v2 版本中不直接支持 cpuset 控制器。cpuset 控制器是 cgroup v1 中的一个功能,它允许管理员为 cgroup 中的进程分配特定的 CPU 核心和内存节点,在 cgroup v2 中,cpuset 功能被整合到了统一的资源管理中,并且不再提供单独的 cpuset 控制器。
这里只放一些核心代码,感兴趣小伙伴可以看我之前的文章 ^_^, 有 CPU 调度策略,亲和性,带宽,权重的详细配置Demo
V1
创建一个 cgroup
┌──[root@vms99.liruilongs.github.io]-[~]
└─$mkdir -p /sys/fs/cgroup/cpuset/cpuset0
配置 cpuset,这里配置 CPU 允许在 0,1 对应的 CPU 上运行
┌──[root@vms99.liruilongs.github.io]-[~]
└─$echo 0-1 > /sys/fs/cgroup/cpuset/cpuset0/cpuset.cpus
┌──[root@vms99.liruilongs.github.io]-[~]
└─$cat /sys/fs/cgroup/cpuset/cpuset0/cpuset.cpus
0-1
V2
──[root@liruilongs.github.io]-[~]
└─$echo "+cpu" >> /sys/fs/cgroup/Example/cgroup.subtree_control
┌──[root@liruilongs.github.io]-[~]
└─$echo "+cpuset" >> /sys/fs/cgroup/Example/cgroup.subtree_control
创建 /sys/fs/cgroup/Example/tasks/ 目录,/sys/fs/cgroup/Example/tasks/ 目录定义了一个子组,以及只与 cpu 和 cpuset 控制器相关的文件。
┌──[root@liruilongs.github.io]-[~]
└─$mkdir /sys/fs/cgroup/Example/tasks/
┌──[root@liruilongs.github.io]-[~]
└─$cat /sys/fs/cgroup/Example/tasks/cgroup.controllers
cpuset cpu
┌──[root@liruilongs.github.io]-[~]
└─$
配置 CPU 亲和性
┌──[root@liruilongs.github.io]-[~]
└─$echo "1" > /sys/fs/cgroup/Example/tasks/cpuset.cpus
┌──[root@liruilongs.github.io]-[~]
└─$
关于 CPU 缓存就和小伙伴们分享到这里,生活加油哦 ^_^
博文部分内容参考
© 文中涉及参考链接内容版权归原作者所有,如有侵权请告知 :)
《性能之颠第二版》
《 Red Hat Performance Tuning 442 》
© 2018-2024 liruilonger@gmail.com, 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)

- 点赞
- 收藏
- 关注作者
评论(0)