YoloV9改进策略:Block改进|改进HCF-Net|附结构图|多种改进方法(独家改进)

摘要
HCF-Net是一种用于红外小物体检测的深度学习网络。它主要包括三个模块:并行化斑块感知注意力(PPA)模块、维度感知选择性整合(DASI)模块和多稀释通道细化器(MDCR)模块。
PPA模块采用多分支特征提取策略,用于捕捉不同尺度和层次的特征信息。DASI模块可实现自适应信道选择和融合,提高模型的检测性能。MDCR模块则通过多个深度分离卷积层捕捉不同感受野范围的空间特征,进一步增强了模型的特征表示能力。
在SIRST红外单帧图像数据集上的实验结果表明,HCF-Net的性能良好,超过了其他传统模型和深度学习模型。
本文改进使用shufflechannel改进MDCR,打造全新的额MDCR_shuffle模块,实现大幅度涨点

论文:《HCF-Net:用于红外小目标检测的分层上下文融合网络》
红外小目标检测是一项重要的计算机视觉任务,涉及在红外图像中识别和定位微小物体,这些物体通常仅包含几个像素。然而,由于物体尺寸极小以及红外图像中通常复杂的背景,这项任务面临困难。在本文中,我们提出了一种深度学习方法 HCF-Net,通过多个实用模块显著提高了红外小目标检测的性能。具体来说,它包括并行补丁感知注意力(PPA)模块、维度感知选择性集成(DASI)模块和多空洞通道细化器(MDCR)模块。PPA 模块使用多分支特征提取策略来捕获不同尺度和级别的特征信息。DASI 模块实现自适应通道选择和融合。MDCR 模块通过多个深度可分离卷积层捕获不同感受野范围的空间特征。在 SIRST 红外单帧图像数据集上的大量实验结果表明,所提出的 HCF-Net 性能良好,优于其他传统和深度学习模型。代码可在 https://github.com/zhengshuchen/HCFNet 获取。
关键词:红外小目标检测,深度学习,多尺度特征。
一、引言
红外小目标检测是一种在红外图像中识别和检测微小物体的关键技术。由于红外传感器能够捕获物体发出的红外辐射,这种技术即使在黑暗或低光环境中也能实现微小物体的精确检测和识别。因此,它在军事、安全、海上救援和火灾监测等多个领域具有显著的应用前景和价值。
然而,红外小目标检测仍然面临以下挑战。首先,深度学习是目前红外小目标检测的主要方法。但是,几乎所有现有的网络都采用经典的下采样方案。由于红外小物体尺寸小,通常伴随着微弱的热信号和模糊的轮廓,在多次下采样过程中存在信息丢失的重大风险。其次,与可见光图像相比,红外图像缺乏物理信息且对比度较低,使得小物体容易淹没在复杂的背景中。
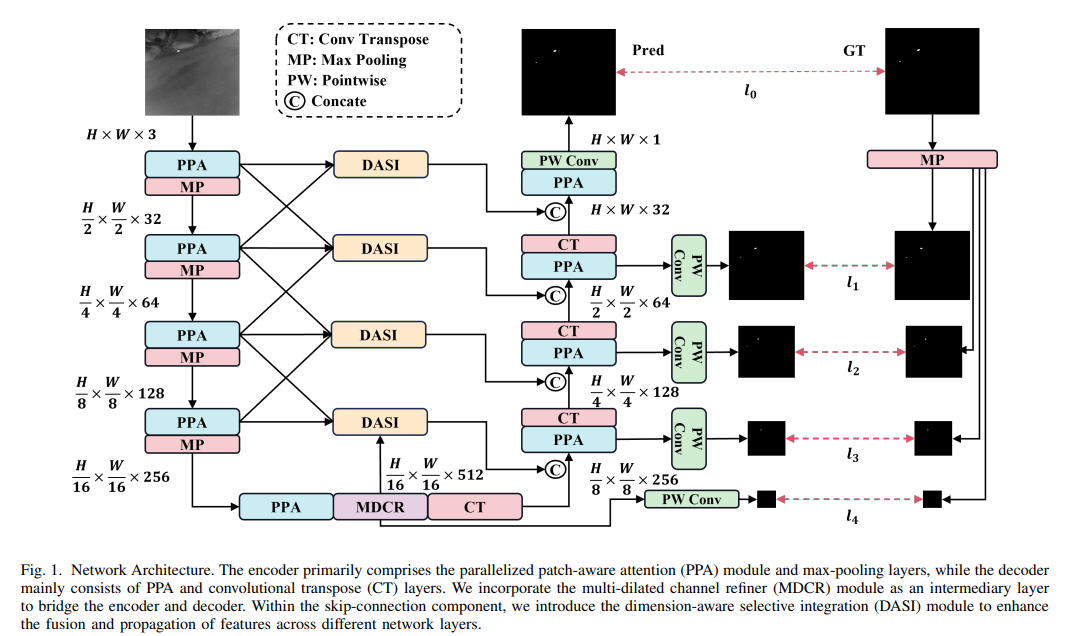
为了应对这些挑战,我们提出了一种名为HCF-Net的红外小目标检测模型。该模型旨在更精确地描述物体的形状和边界,通过将红外小目标检测作为语义分割问题来提高物体定位和分割的准确性。如图1所示,它包含三个关键模块:PPA、DASI和MDCR,这些模块从多个层面解决了上述挑战。
具体来说,作为编码器-解码器的主要组成部分,PPA模块采用层次特征融合和注意力机制来保持和增强小物体的表示,确保在多次下采样步骤中保留关键信息。DASI模块增强了U-Net中的跳跃连接,专注于高维和低维特征的自适应选择和精细融合,以增强小物体的显著性。MDCR模块位于网络的深层,强化了多尺度特征提取和通道信息表示,捕获不同感受野范围的特征。它更精细地建模物体与背景之间的差异,提高了定位小物体的能力。这些模块的有机结合使我们能够更有效地应对小目标检测的挑战,提高检测性能和鲁棒性。
综上所述,本文的主要贡献可以总结如下:
-
我们将红外小目标检测建模为语义分割问题,并提出了HCF-Net,一个可以从头开始训练的逐层上下文融合网络。
-
提出了三个实用模块:并行补丁感知注意力(PPA)模块、维度感知选择性集成(DASI)模块和多空洞通道细化器(MDCR)模块。这些模块有效缓解了红外小目标检测中物体丢失和背景区分度低的问题。
-
我们在公开可用的单帧红外图像数据集SIRST上评估了所提出HCF-Net的检测性能,并证明其相比几种最先进的检测方法具有显著优势。
二、相关工作
A. 传统方法
在红外小目标检测的早期阶段,主要的方法是基于模型的传统方法,通常分为基于滤波器的方法、基于人类视觉系统的方法和低秩方法。基于滤波器的方法通常局限于特定和均匀的场景。例如,TopHat[1]使用各种滤波器估计场景背景,以从复杂背景中分离出物体。基于人类视觉系统的方法适用于具有大物体和强背景区分度的场景,如LCM[2],它通过测量中心点与其周围环境的对比度来实现。低秩方法适用于快速变化和复杂的背景,但在实际应用中缺乏实时性能,通常需要额外的辅助手段,如GPU加速。这些方法包括IPI[3],它使用低秩分解将低秩背景与稀疏形状的物体相结合;PSTNN[4]采用基于张量核范数的非凸方法;RIPT[5]专注于重加权的红外补丁张量;以及NIPPS[6],这是一种高级优化方法,试图将低秩和先验约束结合起来。尽管传统方法在特定场景中有效,但它们容易受到杂波和噪声的干扰。在复杂的现实场景中,物体建模受到模型超参数的影响很大,导致泛化性能较差。
B. 深度学习方法
近年来,随着神经网络的快速发展,深度学习方法在红外小目标检测任务上取得了显著进展。深度学习方法[7]-[14]相比传统方法具有更高的识别准确率,且不依赖于特定场景或设备,表现出更强的鲁棒性和更低的成本,逐渐在该领域占据主导地位。王等人[15]使用在ImageNet大规模视觉识别挑战赛(ILSVRC)数据上训练的模型来完成红外小目标检测任务。梁奎等人[16]结合过采样生成的数据,提出了一种多层网络用于小目标检测。赵等人[17]开发了一种结合红外小目标语义约束信息的编码器-解码器检测方法(TBCNet)。王等人[18]使用生成器和判别器处理两个不同任务:漏检和误报,实现了这两方面的平衡。纳西尔等人[19]提出了一种用于自动目标识别(ATR)的深度卷积神经网络模型。张等人提出了AGPCNet[20],其中引入了注意力引导上下文模块。戴等人引入了非对称上下文调制ACM[21],并发布了第一个真实世界的红外小目标数据集SIRST。吴等人[22]提出了一种“U-Net中的U-Net”框架,以实现目标的多级表示学习。
三、方法
本节将详细讨论HCF-Net。如图1所示,HCF-Net是一个升级版的U-Net架构,由三个关键模块组成:PPA、DASI和MDCR。这些模块使我们的网络更适合检测红外小目标,并有效应对小目标损失和背景特征不明显等挑战。接下来,我们将在第III-A节中简要介绍PPA,然后在第III-B节中概述DASI,最后在第III-C节中介绍MDCR。
A. 并行补丁感知注意力模块
在红外小目标检测任务中,小目标在多次下采样操作中容易丢失关键信息。如图1所示,PPA替代了编码器和解码器基础组件中的传统卷积操作,以更好地应对这一挑战。
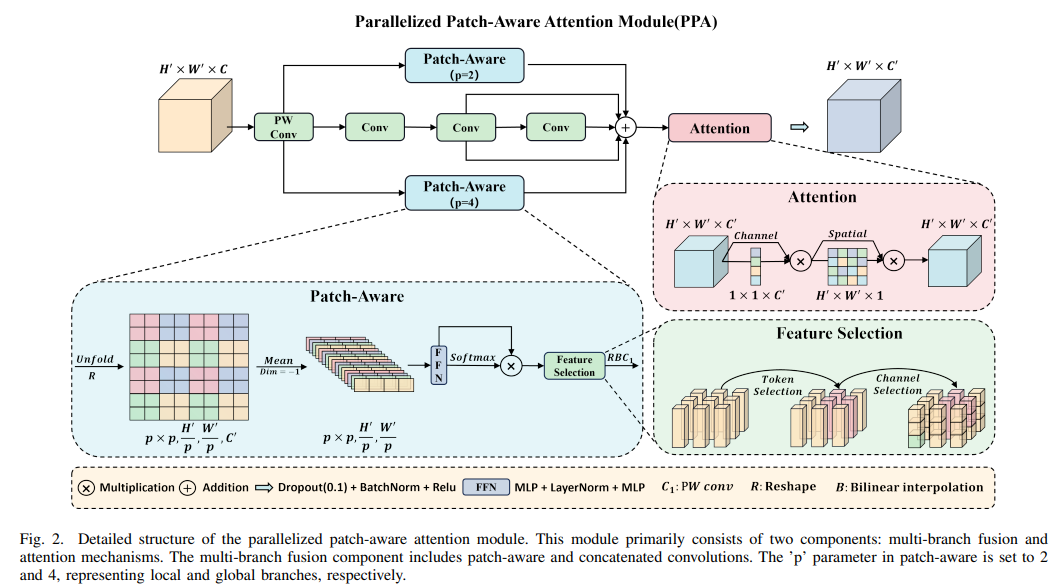
1) 多分支特征提取:PPA的主要优势在于其多分支特征提取策略。如图2所示,PPA采用并行多分支方法,每个分支负责在不同尺度和层次上提取特征。这种多分支策略有助于捕捉目标的多尺度特征,从而提高小目标检测的准确性。具体来说,该策略涉及三个并行分支:局部卷积分支、全局卷积分支和串行卷积分支。给定输入特征张量,它首先通过逐点卷积进行调整,得到。然后,通过这三个分支,可以分别计算出,,以及。最后,将这三个结果相加,得到。
具体来说,局部分支和全局分支之间的区别是通过控制补丁大小参数来建立的,这通过在空间维度上聚合和位移非重叠补丁来实现。此外,我们计算非重叠补丁之间的注意力矩阵,以实现局部和全局特征的提取和交互。
首先,我们使用计算效率高的操作,包括Unfold和reshape,将分割成一组空间上连续的补丁,形状为。接着,我们进行通道平均化操作,得到形状为的结果。然后,我们使用FFN(Feed-Forward Network)进行线性计算。随后,我们应用激活函数,以获得线性计算特征在空间维度上的概率分布,并相应地调整它们的权重。
在加权结果中,我们采用特征选择[24]来从标记和通道中选择与任务相关的特征。具体来说,设,并将加权结果表示为,其中表示第个输出标记。特征选择对每个标记进行操作,输出为,其中和是与任务相关的参数,是范围在之间的余弦相似度函数。这里,作为任务嵌入,指定了哪些标记与任务相关。每个标记都根据其与任务嵌入的相关性(通过余弦相似度衡量)重新加权,有效地模拟了标记选择。随后,我们对每个标记的通道进行线性变换,然后进行重塑和插值操作,最终生成特征和。最后,我们用由三个卷积层组成的串行卷积替代了传统的、和卷积层。这会产生三个不同的输出:,,和。随后,我们将这些输出相加,以得到串行卷积的输出。
2)特征融合与注意力机制:通过多分支特征提取之后,我们利用注意力机制进行自适应特征增强。注意力模块包含一系列高效的通道注意力[25]和空间注意力[26]组件。在这个上下文中, 会依次经过一个一维通道注意力图 和一个二维空间注意力图 的处理。这个过程可以总结如下:
其中, 表示逐元素乘法, 和 分别表示经过通道和空间选择后的特征, 和 分别表示修正线性单元(ReLU)和批量归一化(BN),而 是 PPA(可能指的是某个特定模块或处理的缩写)的最终输出。
B. 维度感知选择性集成模块
在红外小目标检测的多级下采样过程中,高维特征可能会丢失关于小目标的信息,而低维特征可能无法提供足够的上下文信息。为解决这个问题,我们提出了一种新颖的通道划分选择机制(如图3所示),使DASI(维度感知选择性集成模块)能够根据目标的大小和特性自适应地选择适当的特征进行融合。具体来说,DASI首先通过卷积和插值等操作将高维特征 和低维特征 与当前层的特征 进行对齐。

随后,DASI在通道维度上将它们均等地划分为四个部分,得到 , 和 ,其中 、 和 分别表示高维特征、低维特征和当前层特征的第 个划分部分。这些划分部分是根据以下公式计算得到的:
其中, 表示通过激活函数应用于 得到的值, 表示每个分区的选择性聚合结果。在通道维度上合并 后,我们得到 。操作 、 和 分别表示卷积、批量归一化(BN)和修正线性单元(ReLU),最终输出为 。
如果 ,则模型优先考虑细粒度特征;而如果 ,则模型更强调上下文特征。
C. 多扩张通道细化模块
在多扩张通道细化模块(MDCR)中,我们引入了多个具有不同扩张率的深度可分离卷积层,以捕获不同感受野大小的空间特征。这允许我们更详细地建模对象与背景之间的差异,从而增强其识别小对象的能力。
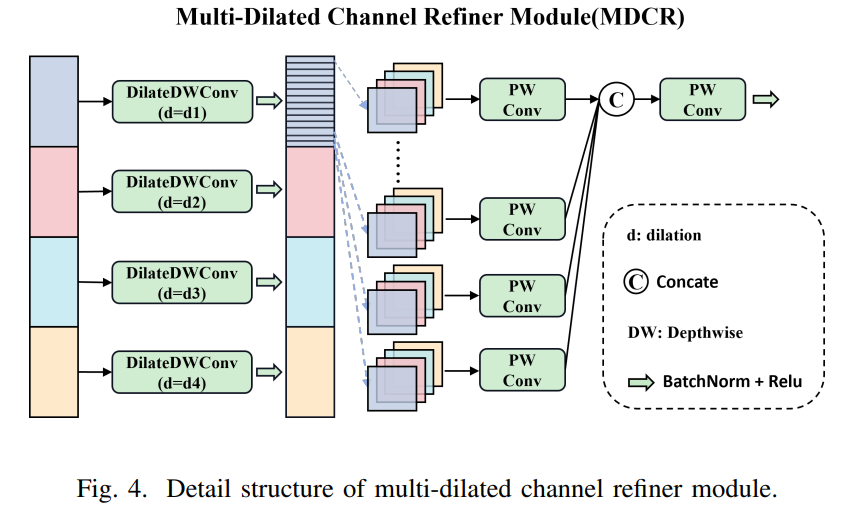
如图4所示,MDCR将输入特征沿通道维度划分为四个不同的头部,生成。然后,每个头部都经过具有不同扩张率的独立深度可分离扩张卷积,得到。我们将卷积扩张率指定为和。
其中,表示通过对第个头部应用深度可分离扩张卷积而获得的特征。操作表示深度可分离扩张卷积,而的取值范围为。
MDCR通过通道分割和重组来增强特征表示。具体来说,我们将分割成单独的通道,以获得每个头部的。接着,我们在各个头部之间交错这些通道,形成,从而增强多尺度特征的多样性。随后,我们使用逐点卷积进行组内和跨组信息融合,得到输出,实现轻量级且高效的聚合效果。
其中,和是逐点卷积中使用的权重矩阵。这里,表示第个头部的第个通道,而表示第组特征。我们有和。函数和分别对应修正线性单元(ReLU)和批量归一化(BN)。
D. 损失设计
如图1所示,我们采用了深度监督策略来进一步解决下采样过程中小对象丢失的问题。每个尺度的损失由二元交叉熵损失(Bce)和交并比损失(Iou)组成,定义如下:
其中,表示多个尺度的损失,是真实掩码,是预测掩码。每个尺度的损失权重定义为。
这种设计允许模型在多个尺度上同时学习,并在训练过程中对不同尺度的特征进行加权。通过给予较低尺度(即较粗糙的尺度)较小的权重,我们能够在不牺牲对小对象检测精度的前提下,平衡模型对不同尺度特征的关注。这有助于模型更好地处理小对象,并在下采样过程中减少信息丢失。通过结合二元交叉熵损失和交并比损失,我们能够同时优化模型的分类和定位能力,从而提高整体性能。
四、实验
A. 数据集与评估指标
我们使用SIRST[21]数据集来评估我们的方法,并采用两个标准指标:交并比(IoU)和归一化交并比(nIoU)[21]。在我们的实验中,SIRST被划分为训练集和测试集,比例为8:2。
B. 实现细节
我们在NVIDIA GeForce GTX 3090 GPU上进行了HCF-Net的实验。对于大小为512×512像素、具有三个颜色通道的输入图像,HCF-Net的计算成本为93.16 GMac(Giga Multiply-Accumulate操作),包含1529万个参数。我们采用Adam优化器进行网络优化,使用批处理大小为4,训练模型300个周期。
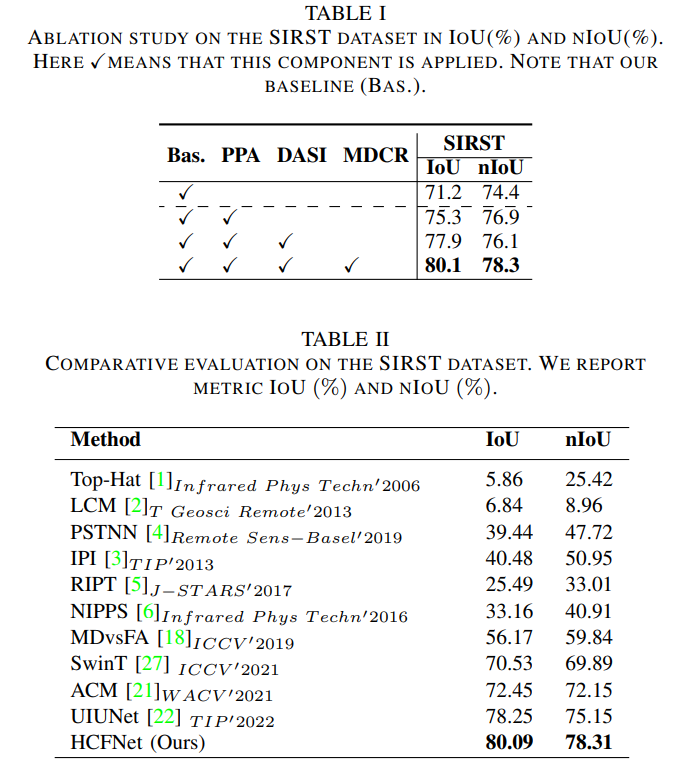
C. 消融实验与对比
本节介绍了在SIRST数据集上进行的消融实验和对比实验。首先,如表I所示,我们使用U-Net作为基线,并系统地引入不同的模块来展示它们的有效性。其次,如表II所示,我们提出的方法在SIRST数据集上取得了出色的性能,IoU和nIoU分数分别为80.09%和78.31%,显著优于其他方法。最后,图5展示了各种方法的可视化结果。在第一行中,可以观察到我们的方法以较低的误报率准确检测到了更多的物体。第二行表明我们的方法在复杂背景下仍然能够精确定位物体。最后,最后一行表明我们的方法提供了更详细的形状和纹理特征描述。

五、结论
本文围绕红外小目标检测中的两个挑战——小目标损失和背景杂波问题进行了深入研究。为应对这些挑战,我们提出了HCF-Net模型,该模型集成了多个实用模块,显著提升了小目标检测的性能。通过大量实验验证,HCF-Net展现出了优越性,在性能上超过了传统的分割方法和深度学习模型。因此,该模型在红外小目标检测领域具有广阔的应用前景和重要的实用价值。
YoloV9官方结果
yolov9-c summary: 580 layers, 60567520 parameters, 0 gradients, 264.3 GFLOPs
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 15/15 00:02
all 230 1412 0.878 0.991 0.989 0.732
c17 230 131 0.92 0.992 0.994 0.797
c5 230 68 0.828 1 0.992 0.807
helicopter 230 43 0.895 0.977 0.969 0.634
c130 230 85 0.955 0.999 0.994 0.684
f16 230 57 0.839 0.965 0.966 0.689
b2 230 2 1 0.978 0.995 0.647
other 230 86 0.91 0.942 0.957 0.525
b52 230 70 0.917 0.971 0.979 0.806
kc10 230 62 0.958 0.984 0.987 0.826
command 230 40 0.964 1 0.995 0.815
f15 230 123 0.939 0.995 0.995 0.702
kc135 230 91 0.949 0.989 0.978 0.691
a10 230 27 0.863 0.963 0.982 0.458
b1 230 20 0.926 1 0.995 0.712
aew 230 25 0.929 1 0.993 0.812
f22 230 17 0.835 1 0.995 0.706
p3 230 105 0.97 1 0.995 0.804
p8 230 1 0.566 1 0.995 0.697
f35 230 32 0.908 1 0.995 0.547
f18 230 125 0.956 0.992 0.993 0.828
v22 230 41 0.921 1 0.995 0.682
su-27 230 31 0.925 1 0.994 0.832
il-38 230 27 0.899 1 0.995 0.816
tu-134 230 1 0.346 1 0.995 0.895
su-33 230 2 0.96 1 0.995 0.747
an-70 230 2 0.718 1 0.995 0.796
tu-22 230 98 0.912 1 0.995 0.804
改进方法
https://jingjing.blog.csdn.net/article/details/138161036
测试结果
yolov9-c summary: 544 layers, 46146640 parameters, 0 gradients, 220.0 GFLOPs
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 15/15 00:19
all 230 1412 0.923 0.986 0.99 0.735
c17 230 131 0.935 0.985 0.994 0.832
c5 230 68 0.912 1 0.989 0.845
helicopter 230 43 0.942 0.977 0.966 0.627
c130 230 85 0.988 1 0.995 0.678
f16 230 57 0.911 0.965 0.974 0.676
b2 230 2 0.791 1 0.995 0.622
other 230 86 0.951 0.965 0.974 0.534
b52 230 70 0.964 0.971 0.982 0.816
kc10 230 62 0.988 0.984 0.989 0.846
command 230 40 0.977 1 0.995 0.819
f15 230 123 0.964 1 0.995 0.662
kc135 230 91 0.981 0.989 0.989 0.708
a10 230 27 1 0.936 0.976 0.463
b1 230 20 0.97 1 0.995 0.724
aew 230 25 0.929 1 0.987 0.781
f22 230 17 0.913 1 0.995 0.731
p3 230 105 0.982 1 0.995 0.814
p8 230 1 0.59 1 0.995 0.796
f35 230 32 0.977 0.969 0.993 0.59
f18 230 125 0.982 0.992 0.988 0.816
v22 230 41 0.984 1 0.995 0.693
su-27 230 31 0.951 1 0.995 0.854
il-38 230 27 0.967 1 0.995 0.822
tu-134 230 1 0.615 1 0.995 0.895
su-33 230 2 1 0.881 0.995 0.624
an-70 230 2 0.762 1 0.995 0.748
tu-22 230 98 0.993 1 0.995 0.823

- 点赞
- 收藏
- 关注作者
评论(0)