昇腾训练适配 -- 精度对齐+性能调优

【摘要】 本文章主要涉及昇腾训练迁移适配过程中的两大问题:精度对齐和性能调优。将介绍精度对齐和性能调优过程中的常用工具用法,以及一些trick。
TL;DR
本文章主要涉及昇腾训练迁移适配过程中的两大问题:精度对齐和性能调优。将介绍精度对齐和性能调优过程中的常用工具用法,以及一些trick。
一、训练迁移适配之精度对齐
1.1. loss曲线差异
- 1.打印日志信息:
- 下面是一个简单示例,将训练损失
Train Loss和训练性能指标Train Steps/Sec打印到指导文件,用于绘制loss曲线以及分析精度差异。
if RANK in {-1, 0}:
import logging
logging.basicConfig(
level=logging.DEBUG,
format='[%(asctime)s] %(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
handlers=[logging.FileHandler("exp/train/log.txt")]
)
logger = logging.getLogger(name="loss_recorder")
start_time = time.time() # for steps_per_sec
nb = len(train_loader)
for epoch in range(1, num_epochs + 1):
if RANK != -1:
train_loader.sampler.set_epoch(epoch)
for i, batch in enumerate(train_loader):
train_steps = i + nb * epoch
#=== Train Code Start ===#
#=== Train Code End ===#
steps_per_sec = 1.0 / (time.time() - start_time)
logger.info("(step=%07d) Train Loss: %.4f, Train Steps/Sec: %.2f",
train_steps, loss, steps_per_sec)
start_time = time.time()
-
2.分析日志文件并绘制loss曲线差异
- 在GPU和NPU环境分别训练,我们将会得到
log_gpu.txt和log_npu.txt两个日志文件 - 使用如下代码,可以读取
loss值绘制loss曲线差异,并给出绝对误差平均值和相对误差百分比平均值
- 在GPU和NPU环境分别训练,我们将会得到
-
注意:一般
相对误差百分比平均值<5%,即为满足精度要求
import matplotlib.pyplot as plt
import re
def get_train_loss_list(loss_file):
train_loss = []
file = open(loss_file)
for line in file:
match = re.search(r'\(step=(\d+)\) Train Loss: ([\d\.]+), Train Steps/Sec: ([\d\.]+)', line)
if match:
loss = float(match.group(2))
train_loss.append(loss)
return train_loss
gpu_log_path = 'log_gpu.txt'
npu_log_path = 'log_npu.txt'
train_loss_gpu = get_train_loss_list(gpu_log_path)
train_loss_npu = get_train_loss_list(npu_log_path)
######################## 绘制loss对比曲线 ########################
#初始化图片
plt.figure(figsize=(12, 6))
#绘制NPU LOSS曲线
plt.plot(train_loss_npu, label='npu_loss', alpha=0.9, color="blue")
#绘制GPU LOSS曲线
plt.plot(train_loss_gpu, label='gpu_loss', alpha=0.9, color="red")
plt.legend(loc='best')
#保存图片
plt.savefig('./compare_loss_curves.png')
if len(train_loss_npu) < len(train_loss_gpu):
len_loss = len(train_loss_npu)
else:
len_loss = len(train_loss_gpu)
#计算LOSS差距
train_diff = []
train_diff_abs = []
train_diff_percent = []
for i in range(0, len_loss):
diff = train_loss_npu[i] - train_loss_gpu[i]
train_diff.append(diff)
train_diff_abs.append(abs(diff))
train_diff_percent.append(abs(diff) / train_loss_gpu[i])
######################## 绘制loss差距曲线 ########################
#初始化图片2
plt.cla()
plt.clf()
plt.figure(figsize=(12, 6))
#绘制图片
plt.plot(train_diff, label='loss_gap')
plt.legend(loc='best')
#保存图片
plt.savefig('./loss_gap_curves.png')
######################## 输出loss绝对误差平均值 ########################
print("------------------------------- Relative abs Loss Gap -------------------------------")
print(sum(train_diff_abs)/len(train_diff_abs))
print("-------------------------------------------------------------------------------------")
######################## 输出相对误差百分比平均值 ########################
print("------------------------------- Loss Gap percent -------------------------------")
print(sum(train_diff_percent)/len(train_diff_percent))
print("-------------------------------------------------------------------------------------")
1.2. ptdbg_ascend工具
- 注意:本文档以
ptdbg_ascend==5.0为例,低版本可能不支持以下语法,若报错可尝试官方指导文档。 dump数据或overflow检查,老版语法(不推荐)
# 导入ptdbg_ascend依赖包
from ptdbg_ascend import register_hook, overflow_check, seed_all, set_dump_path, set_dump_switch, acc_cmp_dump
seed_all(seed=1234, mode=False) # 在 main 函数中固定随机数
set_dump_path("./npu_dump", dump_tag='all') # 设置 dump 文件保存路径
# dump 开启和关闭。在一个 iter 的开始和结束位置设置
register_hook(model, acc_cmp_dump)
set_dump_switch("ON", mode="api_stack", filter_switch="OFF")
# ---------
# iterartion
# ---------
set_dump_switch("OFF", mode="api_stack", filter_switch="OFF")
# dump 开启和关闭。在一个 iter 的开始和结束位置设置
register_hook(model, overflow_check, overflow_nums=3)
set_overflow_check_switch("ON")
# ---------
# iterartion
# ---------
set_overflow_check_switch("OFF")
- 1.精度溢出检测:新版语法(强烈推荐)
from ptdbg_ascend import PrecisionDebugger
debugger = PrecisionDebugger(
dump_path="exp/precision_align/npu_log", hook_name="overflow_check", step=[0],
enable_dataloader=True
)
debugger.configure_hook(overflow_nums=1)
- 2.dump数据用法:新版语法(强烈推荐)
from ptdbg_ascend import PrecisionDebugger
debugger = PrecisionDebugger(
dump_path="exp/precision_align/npu_log", hook_name="dump", step=[0],
enable_dataloader=True
)
debugger.configure_hook(mode="api_stack")
enable_dataloader参数使能,会用装饰器修饰torch.utils.data.dataloader._BaseDataLoaderIter的__next__函数,从而在每个训练迭代自动插入start/stop/step;- 使用
torch提供DataLoader加载数据训练的情况下,强烈建议设置enable_dataloader=True。 - 3.dump数据进阶用法:核心如何dump指定少量数据,而非每次都dump全量数据
# dump数据的configure_hook函数接口
def configure_full_dump(self, mode='api_stack', scope=None, api_list=None, filter_switch=Const.OFF,
input_output_mode=[Const.ALL], acl_config=None, backward_input=None, summary_only=False, summary_mode=None):
...
# dump mode --> ptdbg_ascend.common.utils.Const
ALL = "all"
LIST = "list"
RANGE = "range"
STACK = "stack"
ACL = "acl"
API_LIST = "api_list"
API_STACK = "api_stack"
DUMP_MODE = [ALL, LIST, RANGE, STACK, ACL, API_LIST, API_STACK]
debugger.configure_hook(mode="api_stack", input_output_mode="forward")
debugger.configure_hook(mode="list", scope=["Tensor___truediv___0_forward"]) # scope指定的算子
debugger.configure_hook(mode="range", scope=["Tensor_matmul_0_forward", "Tensor_matmul_0_backward"]) # scope指定的范围
debugger.configure_hook(mode="stack", scope=["Tensor_matmul_0_forward", "Tensor_matmul_0_backward"]) # 只dump堆栈信息
# mode="api_list",支持dump指定api,例如api_list=["relu"]
# mode="acl",支持dump ACL级别的算子数据,此时需要配置acl_config、backward_input
# input_output_mode="all/forward/backward"
# summary_mode="all/summary/md5",只dump统计信息.pkl/计算md5值
1.3. OMS数据迁移服务
- 以北京四OBS数据迁移至贵阳一OBS为例
可以通过如下链接进入OMS管理控制台:https://console.huaweicloud.com/oms/?agencyId=730132108d3d469e92cd6638d76689df®ion=cn-southwest-2&locale=zh-cn#/oms/migrationTaskNew
此外,您也可以在控制台点击左上角“服务列表”,进入搜索框,找到“OMS”服务并点击进入。
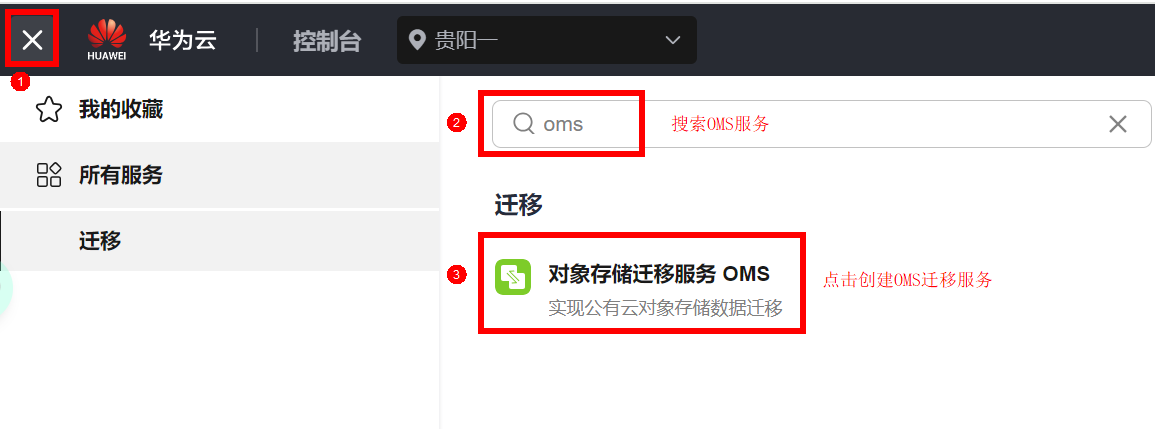
注意:将控制台区域切换为“西南-贵阳一”
进入“OMS”服务后,点击“迁移任务”,然后点击右上角“创建迁移任务”:
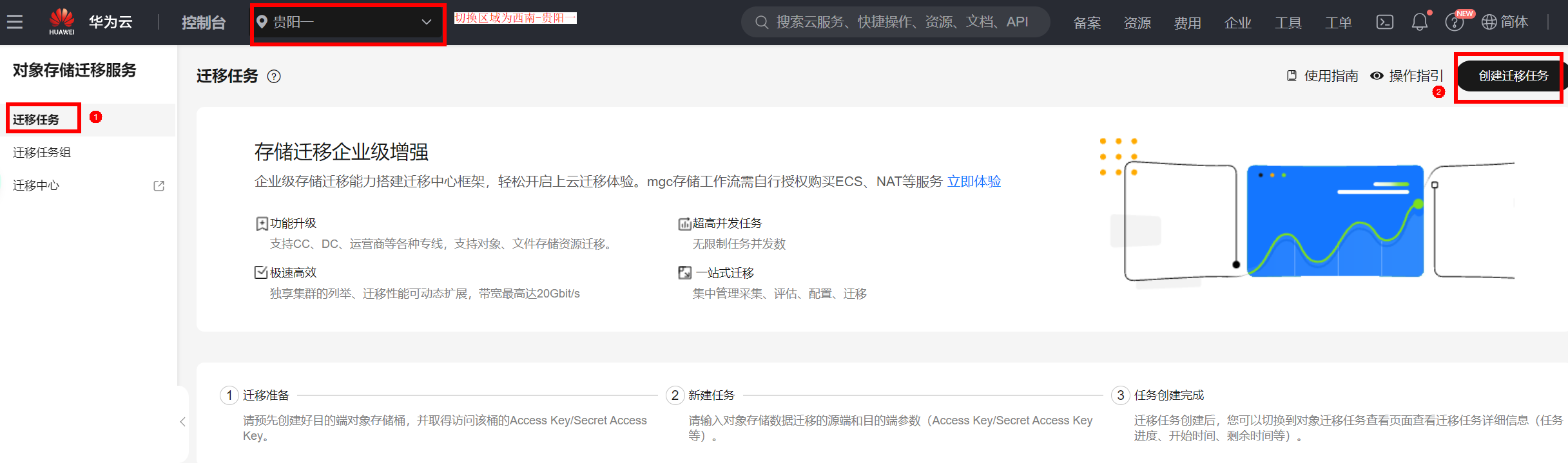
“第1步 迁移前评估”可跳过,主要关注“第2步 选择源端/目的端”,第3-4步默认下一步即可:
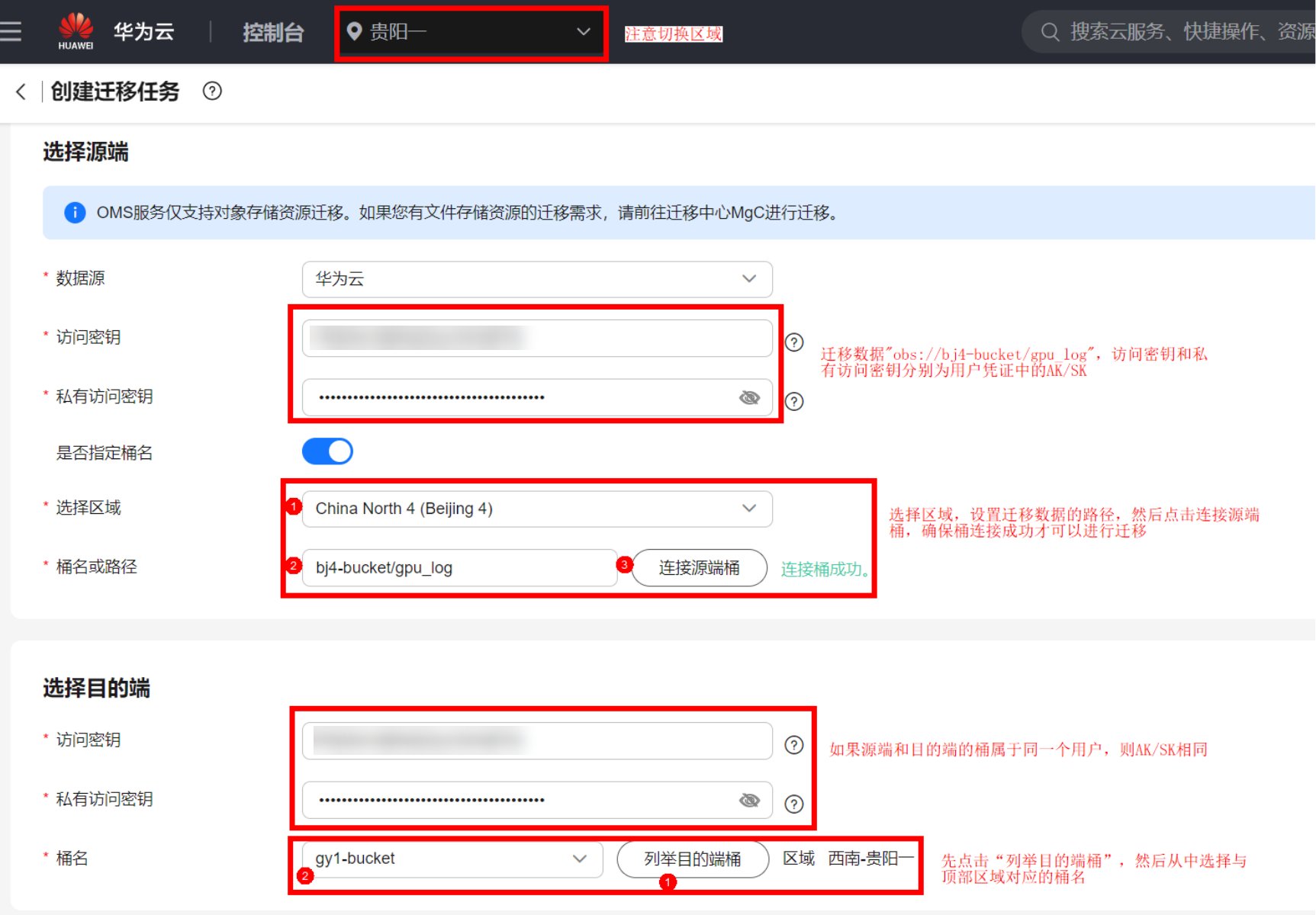
其中,访问密钥(AK/SK)的获取可以参考官方文档:https://support.huaweicloud.com/modelarts_faq/modelarts_05_0004.html
源端和目的端的详细配置参数如下:
数据源:华为云
访问密钥和私有访问密钥:下载的“credentials.csv”文件中查看
指定桶名后:①选择区域为China North4;②填入gpu-dump数据路径;③连接源端桶
目的端:①先列举目的端桶;②然后选择gy1-bucket
注意:OBS桶名称,需要替换为自己创建的桶名称
点击“下一步”之后,完成启动前确认,然后返回任务列表。可见数据正在迁移中:

等待完成数据迁移:

1.4. 分析精度误差来源
- 通过上述步骤后,我们拿到了GPU和NPU的dump数据,下面介绍如何使用ptdbg_ascend工具进行分析
- 1.生成比较结果
import os
from ptdbg_ascend import compare
common_dir = "/home/ma-user/work/yolov8/exp/precision_align"
dump_mode = "api_stack"
npu_pkl_path = os.path.join(common_dir, f"npu_log/ptdbg_dump_v5.0/step0/rank0/{dump_mode}_dump.pkl")
gpu_pkl_path = os.path.join(common_dir, f"gpu_log/ptdbg_dump_v5.0/step0/rank0/{dump_mode}_dump.pkl")
npu_dump_data_dir = os.path.join(common_dir, f"npu_log/ptdbg_dump_v5.0/step0/rank0/{dump_mode}_dump")
gpu_dump_data_dir = os.path.join(common_dir, f"gpu_log/ptdbg_dump_v5.0/step0/rank0/{dump_mode}_dump")
dump_path_param = {
"npu_pkl_path": npu_pkl_path,
"bench_pkl_path": gpu_pkl_path,
"npu_dump_data_dir": npu_dump_data_dir,
"bench_dump_data_dir": gpu_dump_data_dir,
"is_print_compare_log": True
}
compare(dump_path_param, output_path=common_dir, stack_mode=True)
- 如果
npu_dump_data_dir和gpu_dump_data_dir为空,ptdbg_ascend会分析GPU和NPU算子的统计值差异,如果非空会给出compare_results_***.csv - 2.定位误差来源
- 根据
compare_results_***.csv文件,我们可以得到产生误差的第一个算子,记录其算子名称来分析执行堆栈
%%writefile ptdbg_parse.py
import argparse
import ptdbg_ascend
def init_args():
parser = argparse.ArgumentParser()
parser.add_argument('-f', '--file-pkl', type=str, help='pkl_file, e.g. api_stack_dump.pkl')
parser.add_argument('-p', '--prefix', type=str, help='prefix of module name')
args = parser.parse_args()
return args
if __name__ == "__main__":
args = init_args()
ptdbg_ascend.parse(pkl_file=args.file_pkl, module_name_prefix=args.prefix)
# 参考示例
# python ptdbg_parse.py -f exp/precision_align/npu_log/ptdbg_dump_v5.0/step0/rank0/api_stack_dump.pkl -p Tensor_matmul_0_forward
- 根据代码堆栈回溯到问题代码,解决该算子精度问题后,再次dump数据对比,直至精度对齐。
二、训练迁移适配之性能调优
2.1. 量化性能指标
- 下面代码可以读取“任务一:精度对齐”创建的日志文件,并统计训练性能的均值或中位数
import re
import os
import numpy as np
def get_matched_value_list(file: str):
matched_values = []
file = open(file)
for line in file:
match = re.search(r'\(step=(\d+)\) Train Loss: ([\d\.]+), Train Steps/Sec: ([\d\.]+)', line)
if match:
value = float(match.group(3))
matched_values.append(value)
return matched_values
def get_prof_infos(steps_per_second, exclude_first_num: int=0):
steps_per_second = steps_per_second[exclude_first_num:]
assert len(steps_per_second) > 10
steps_per_second = np.array(steps_per_second)
prof_infos = {"mean": np.mean(steps_per_second),
"median": np.median(steps_per_second)
}
# return prof_infos["mean"]
return prof_infos["median"]
if __name__ == "__main__":
train_log_dir = "/home/ma-user/work/yolov8/runs/detect-results"
for log in os.listdir(train_log_dir):
f = os.path.join(train_log_dir, log, "log.txt")
average_prof = get_prof_infos(
get_train_loss_list(f), exclude_first_num=10
)
print("{:s} --> {:.4f}".format(log, average_prof))
2.2. 采集性能数据
- 1.torch_npu采集性能数据
def get_profiler_context(profiler_on: bool=False, profiler_dir: str=""):
if not profiler_on:
from contextlib import nullcontext
class DummyProfilerContext(nullcontext):
def __enter__(self):
return self
def step(self):
pass
return DummyProfilerContext()
import torch_npu
profiler_dir = "./exp/prof_tuning/npu_prof" if not profiler_dir else profiler_dir
experimental_config = torch_npu.profiler._ExperimentalConfig(
aic_metrics=torch_npu.profiler.AiCMetrics.PipeUtilization,
profiler_level=torch_npu.profiler.ProfilerLevel.Level1,
l2_cache=False, data_simplification=False
)
prof_context = torch_npu.profiler.profile(
activities=[
torch_npu.profiler.ProfilerActivity.CPU,
torch_npu.profiler.ProfilerActivity.NPU
],
schedule=torch_npu.profiler.schedule(wait=1, warmup=1, active=2, repeat=1, skip_first=10),
on_trace_ready=torch_npu.profiler.tensorboard_trace_handler(profiler_dir),
record_shapes=True,
profile_memory=True,
with_stack=True,
with_flops=False,
with_modules=False,
experimental_config=experimental_config
)
return prof_context
with get_profiler_context(profiler_on=True) as prof:
for i, batch in enumerate(train_loader):
#=== Train Code Start ===#
#=== Train Code End ===#
prof.step()
- 采集结果目录如下:

- 2.pytorch采集性能数据
def get_profiler_context(profiler_on: bool=False, profiler_dir: str=""):
if not profiler_on:
from contextlib import nullcontext
class DummyProfilerContext(nullcontext):
def __enter__(self):
return self
def step(self):
pass
return DummyProfilerContext()
import torch
profiler_dir = "./exp/prof_tuning/gpu_prof" if not profiler_dir else profiler_dir
prof_context = torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA
],
schedule=torch.profiler.schedule(wait=1, warmup=1, active=2, repeat=1, skip_first=10),
on_trace_ready=torch.profiler.tensorboard_trace_handler(profiler_dir),
record_shapes=True,
profile_memory=True,
with_stack=True,
with_flops=False,
with_modules=False,
)
return prof_context
with get_profiler_context(profiler_on=True) as prof:
for i, batch in enumerate(train_loader):
#=== Train Code Start ===#
#=== Train Code End ===#
prof.step()
- 采集结果保存在
exp/prof_tuning/gpu_prof/devserver-***.trace.json
2.3. ma-advisor专家经验
- 重点使用analyze命令,详细介绍见官网文档https://support.huaweicloud.com/bestpractice-modelarts/modelarts_10_2515.html
- all:同时进行融合算子图调优、亲和API替换调优、AICPU调优、算子调优等分析,并输出相关简略建议到执行终端中,并生成“ma_advisor_**.html”文件可供用户在浏览器中进行预览。
- 使用示例如下:
ma-advisor analyze all --data-dir exp/prof_tuning/npu_prof/devserver-bms-**_ascend_pt
ma-advisor analyze all --data-dir exp/prof_tuning/npu_prof/devserver-bms-**_ascend_pt/ASCEND_PROFILER_OUTPUT
ma-advisor analyze all --data-dir exp/prof_tuning/npu_prof/devserver-bms-**_ascend_pt/ASCEND_PROFILER_OUTPUT --cann-version 8.0.0
- 根据
ma-advisor输出的html文件,参考其专家经验进行性能调优:- NPU融合优化器,e.g. torch_npu.optim.NpuFusedAdamW
- 算子二进制调优,e.g. 动态shape场景jit_compile=False
- 融合算子替换示例,e.g. RotaryMul, RmsNorm, FlashAttentionScore等
- NPU亲和API替换,e.g. npu_confusion_transpose, clip_grad_norm_fused_
- AOE调优,e.g. 固定shape场景时,自动生成调优策略
- 数据处理瓶颈调优,e.g. torch.cuda.Stream实现数据预取
- AICPU算子替换示例,e.g. 数据类型不支持,等价算子替换
- 其他优化操作:fast-gelu调用示例, torch_npu.npu_linear调用示例
2.4. 可视化性能瓶颈
- 主要使用Chrome浏览器功能:打开
chrome://tracing,将NPU或GPU采集到的性能数据track_view.json拖入浏览器页面分析

参考资料

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)