基于ModeArts新版自动学习美食分类

操作前提:登录华为云
进入【实验操作桌面】,打开Chrome浏览器进入华为云登录页面。选择【IAM用户登录】模式,于登录对话框中输入系统为您分配的华为云实验账号和密码登录华为云,如下图所示

注意:账号信息详见实验手册上方,切勿使用您自己的华为云账号登录。

如果出现显示权限不足直接点击“关闭”,没有直接跳过

任务一.准备数据
1.数据集介绍
本次实验,我们使用包含四个类别的美食分类数据集,每个类别10张图片。
该数据集包含的美食及其类别如下图所示:

2.下载训练数据集
回到实验桌面,打开终端,执行以下命令,下载数据集。
wget https://labfiles-singapore.obs.ap-southeast-3.myhuaweicloud.com/ai/ExeML_Food_Recognition.tar.gz
下载后,输入下面指令解压缩:
# decompress file
tar -zxvf ExeML_Food_Recognition.tar.gz
该文件夹包含两个子文件夹。Foods_recognition是训练数据,包含训练集和测试集,foods_recognition_ass是添加的数据。

3.创建桶
登录华为云控制台,鼠标点击菜单栏,输入OBS,选择“对象存储服务”。


点击“创建桶”

目标区域:北京四,
桶名称:自定义,
企业项目:default,
点击“立即创建”

出现提示,点击“确定”,创建成功会有创建桶成功提示,
出现提示,点击“确定”,并等待一会网页跳转,再点击"桶名xxx"。

4.上传数据集
点击“对象”,“新建文件夹”,新建ExeML_Food_Recognition文件夹,点击进入创建foods_recognition和foods_recognition_assi和文件夹,
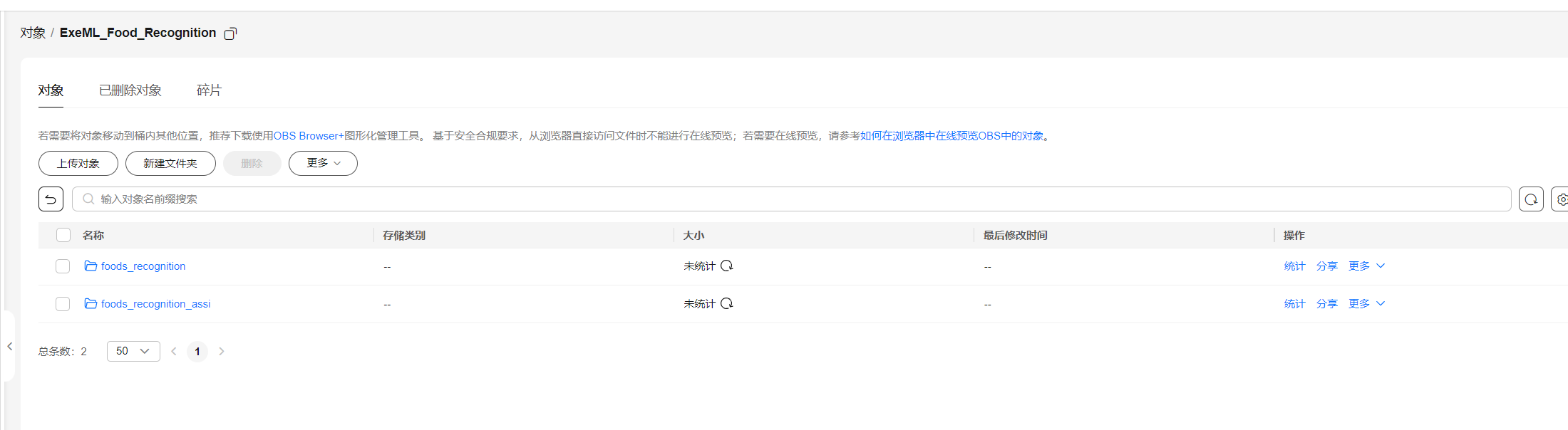
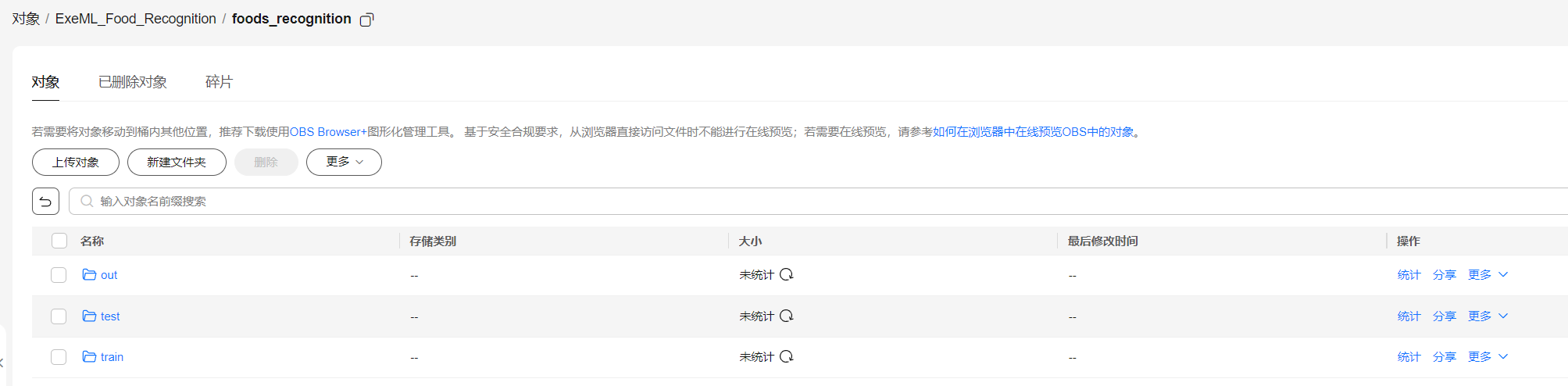
再分别进入创建文件夹“train”,“test”。此处foods_recognition文件夹下面需要多创建一个out文件夹。

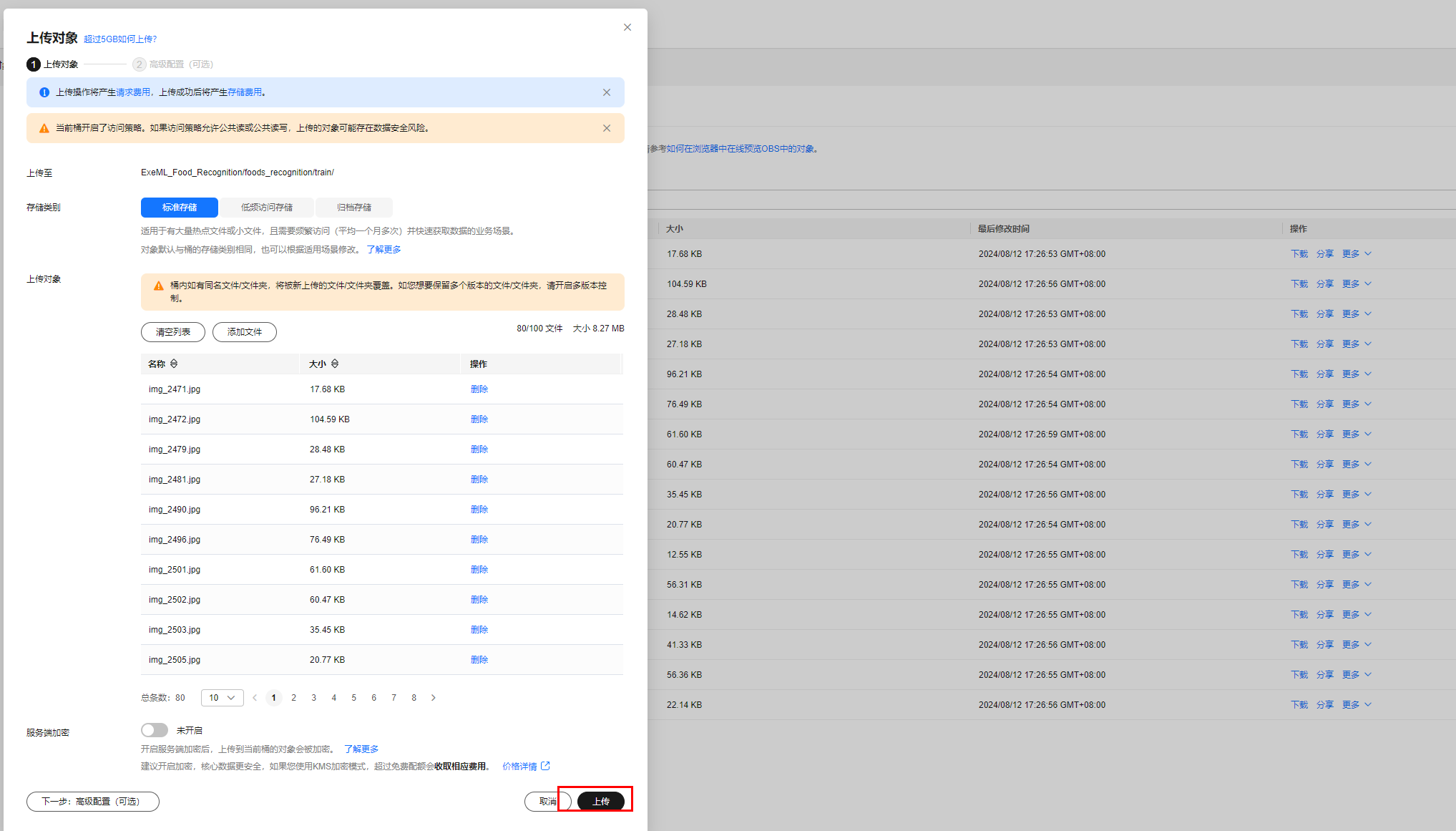
单击“上传对象>添加文件”,选择本地的food_recognition文件夹,将train目录下的图片文件上传到OBS上名为"train"的对象中,本地路径为/home/user/ExeML_Food_Recognition/foods_recognition/train/.按CTRL + A选择所有文件。
5.下载测试数据集图片
打开浏览器 复制链接,直接下载测试集图片,在浏览器左下角
https://sandbox-expriment-files.obs.cn-north-1.myhuaweicloud.com:443/20221019/img_2478.jpg
查看下载的图片:

6.创建数据集
进入ModelArts,点击数据集管理-数据集,点击“创建数据集”,
名称:自定义,其余参数按照图片操作,增加标签:柿子饼,灌汤包,凉皮,肉夹馍,然后点击创建。

任务二.创建图像分类项目
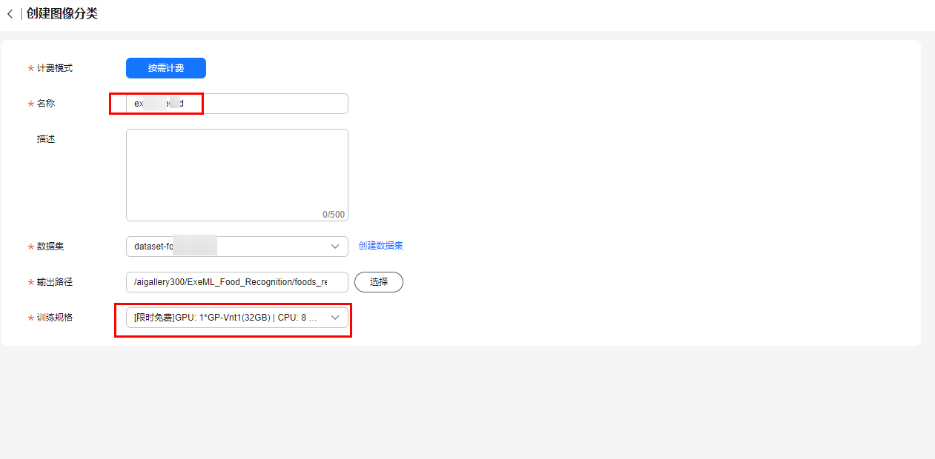
进入ModelArts自动学习界面,然后点击“图像分类”创建项目按钮,

按照如下示例填写参数:
名称:ExeML-d04e
数据集:选择刚才创建的数据集,
输出路径:点击文件夹,选择“桶名/ExeML_Food_Recognition/foods_recognition/out”,
训练规格:[限时免费]GPU:1*GP-Vnt(32GB)|CPU:8核64GB
最后点击“创建项目” 按钮完成图像分类项目创建。
任务三.数据图片标注
进入workflow工作流页面,

双击“数据标注”按钮,点击“实例详情”,进入数据标注页面。

点击进入“未标注”页面。批量选中相同类别的图片,然后添加标签(如果标签已经存在,可以直接选择),最后点击“确定”按钮。如下图所示:

“全部标签”中列举了所有的标签,以及每个标签下的图片数量。
完成所有图片标注后,进入“已标注”页面。在该页面可以校验图片标签,如果标注有误,可以在该页面修改标签。如果发现标签不正确,可以选中图片,重新选择标签。

任务四.数据集版本发布
标注完毕,然后返回自动学习工作流页面,点击继续运行”。
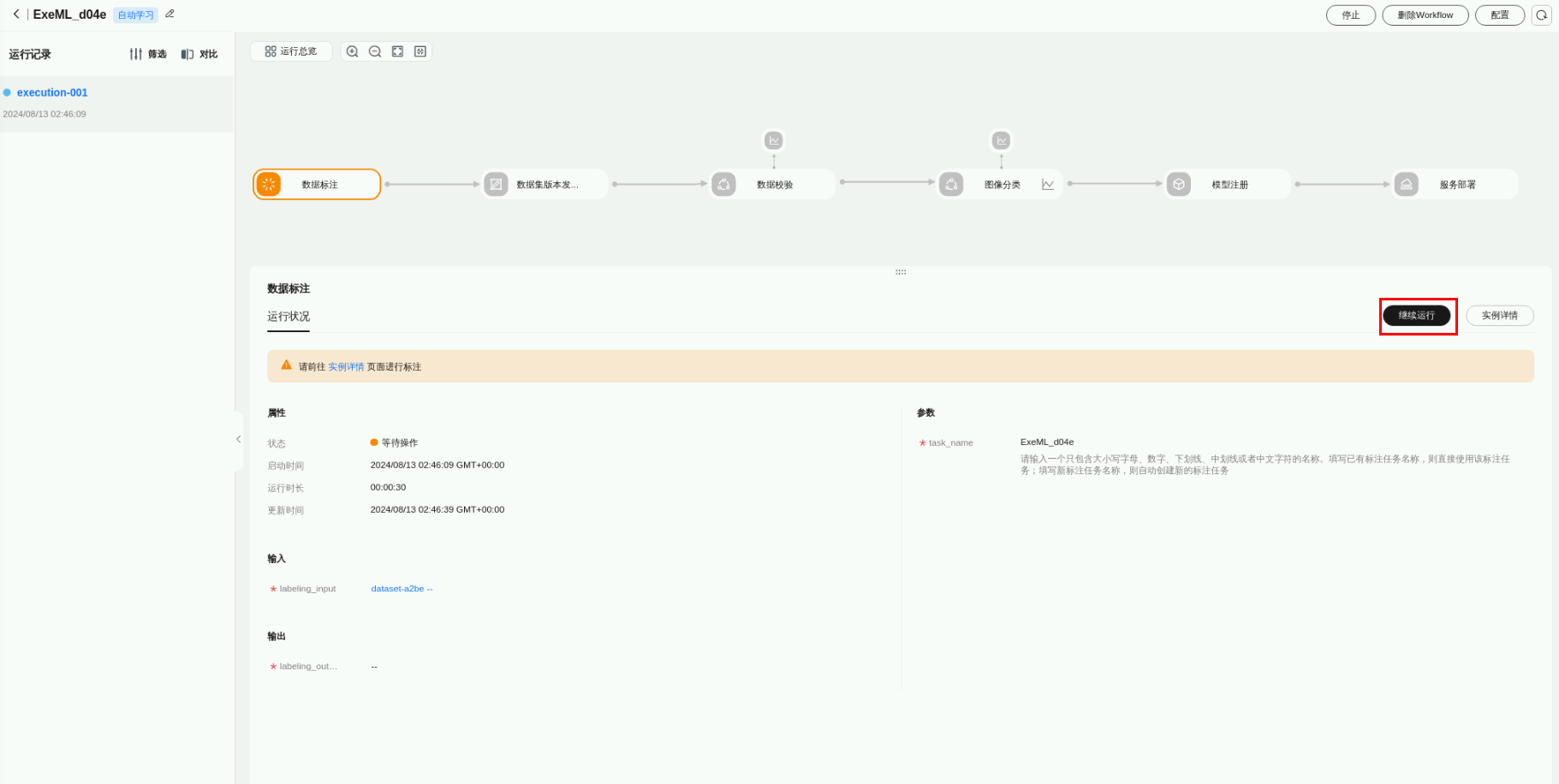
弹出“确认是否继续运行”,点击“确定”,
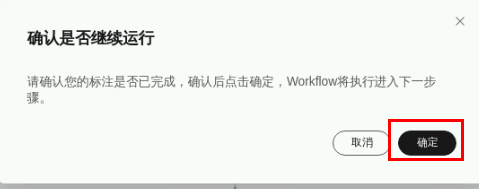
点击数据集版本发布,查看运行状态详情。
点击实例详情查看,
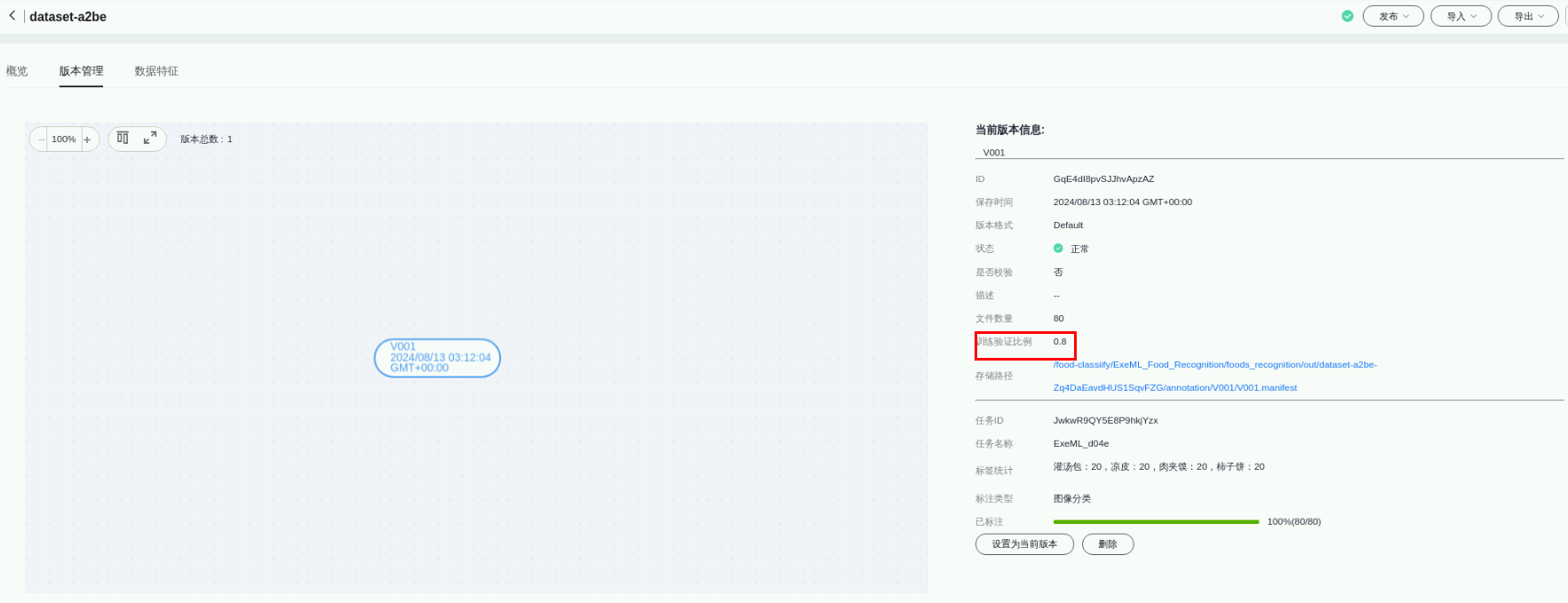
任务五.数据校验
返回自动学习workflow界面,点击数据校验查看详情:

点击“实例详情”查看训练作业详情和运行状态,

点击“重建”,可以查看训练作业的具体参数,

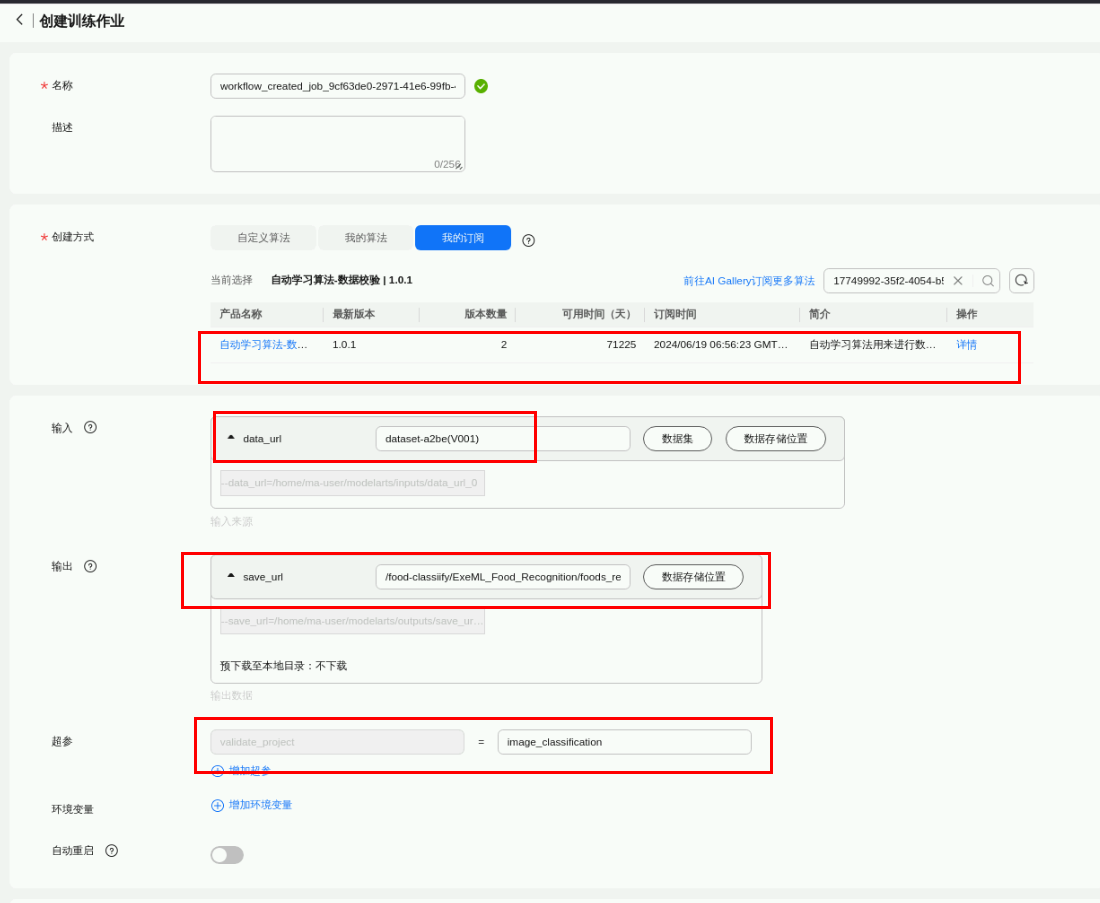
任务六.图像分类
返回自动学习workflow界面,点击图像分类,查看运行状态:
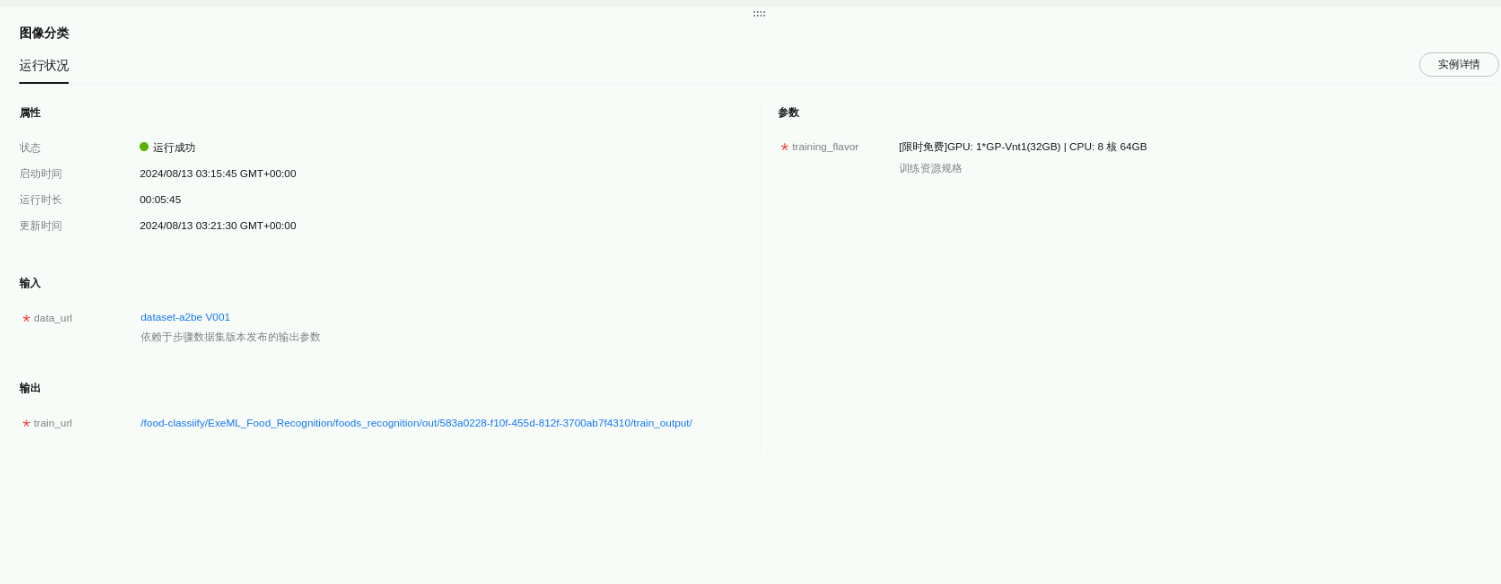
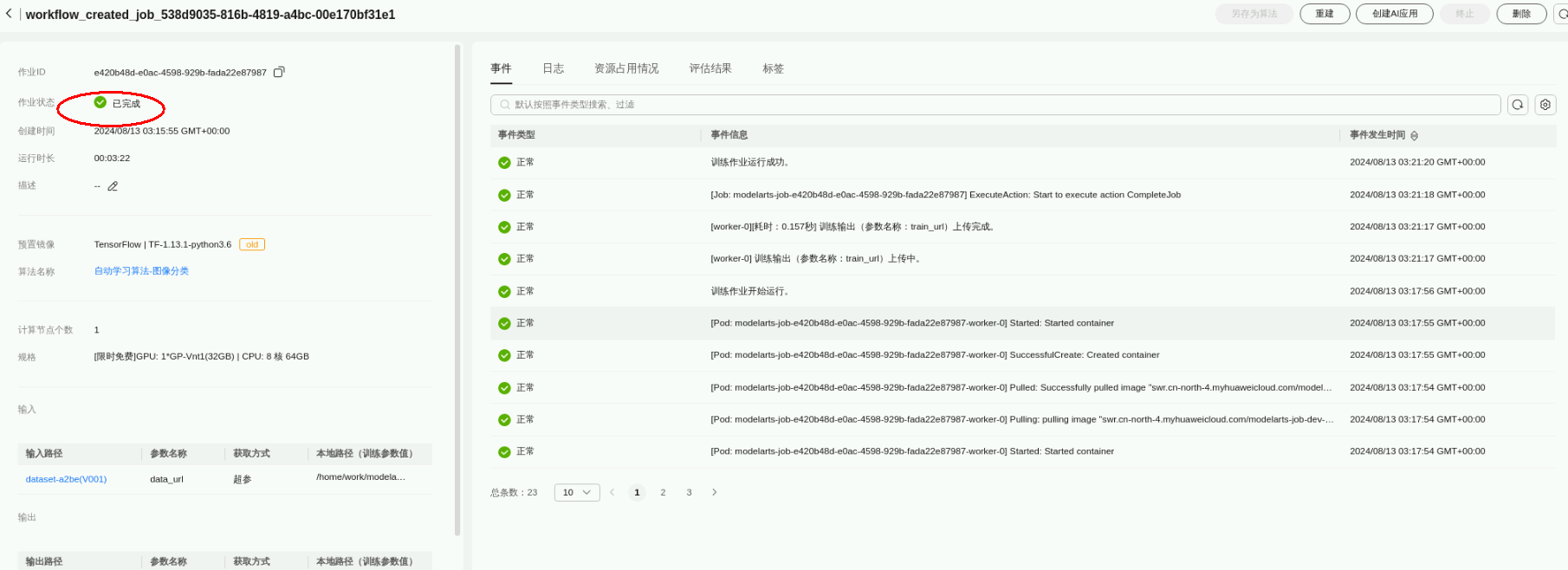
点击“实例详情”,可以看到训练作业显示已完成。
任务七. 模型注册(创建AI应用)
返回自动学习workflow界面,点击模型注册,查看运行状态:
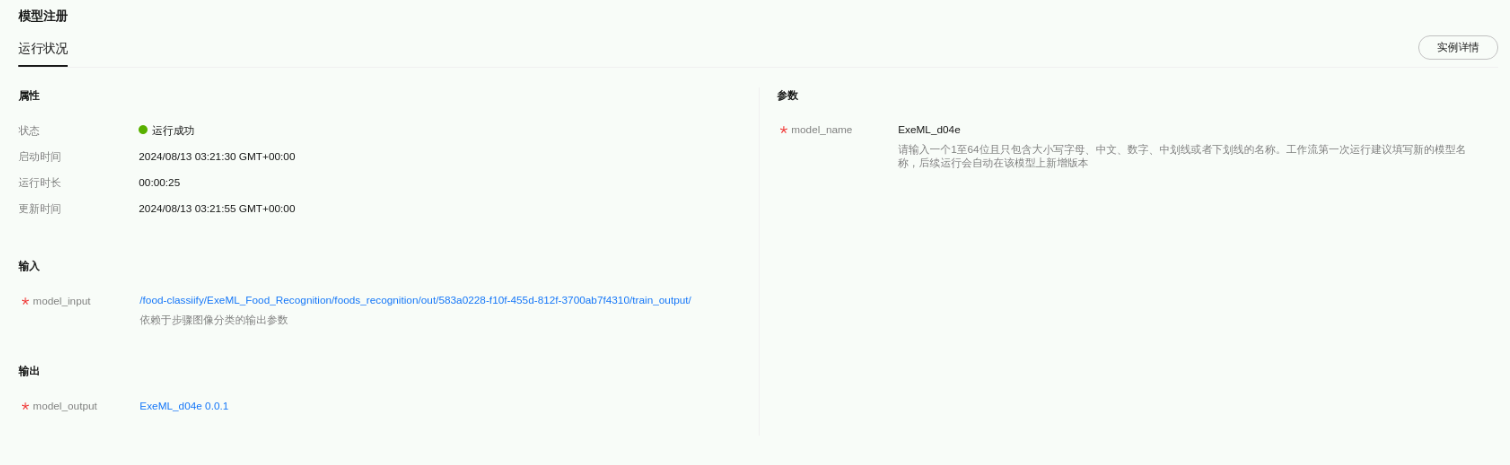
点击“实例详情”,可以看到创建AI应用显示正常。
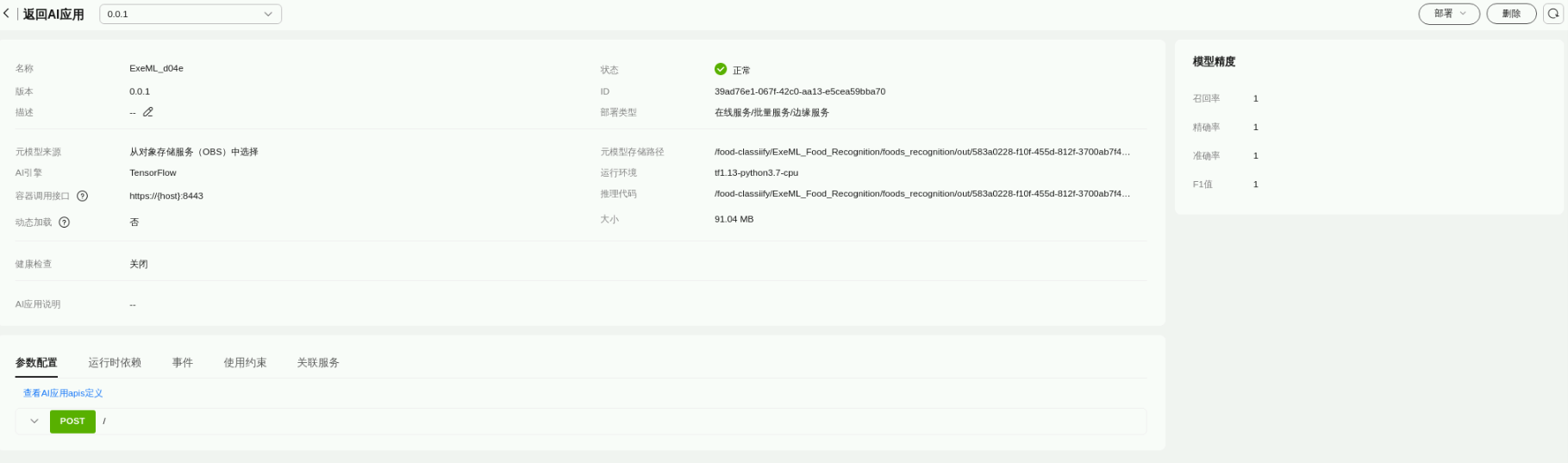
任务八. 服务部署
返回自动学习workflow界面,点击服务部署,公共资源池选择CPU:1核4GB,其他参数默认不变,打开“是否停止”按钮,选择1小时后,点击“继续运行”。
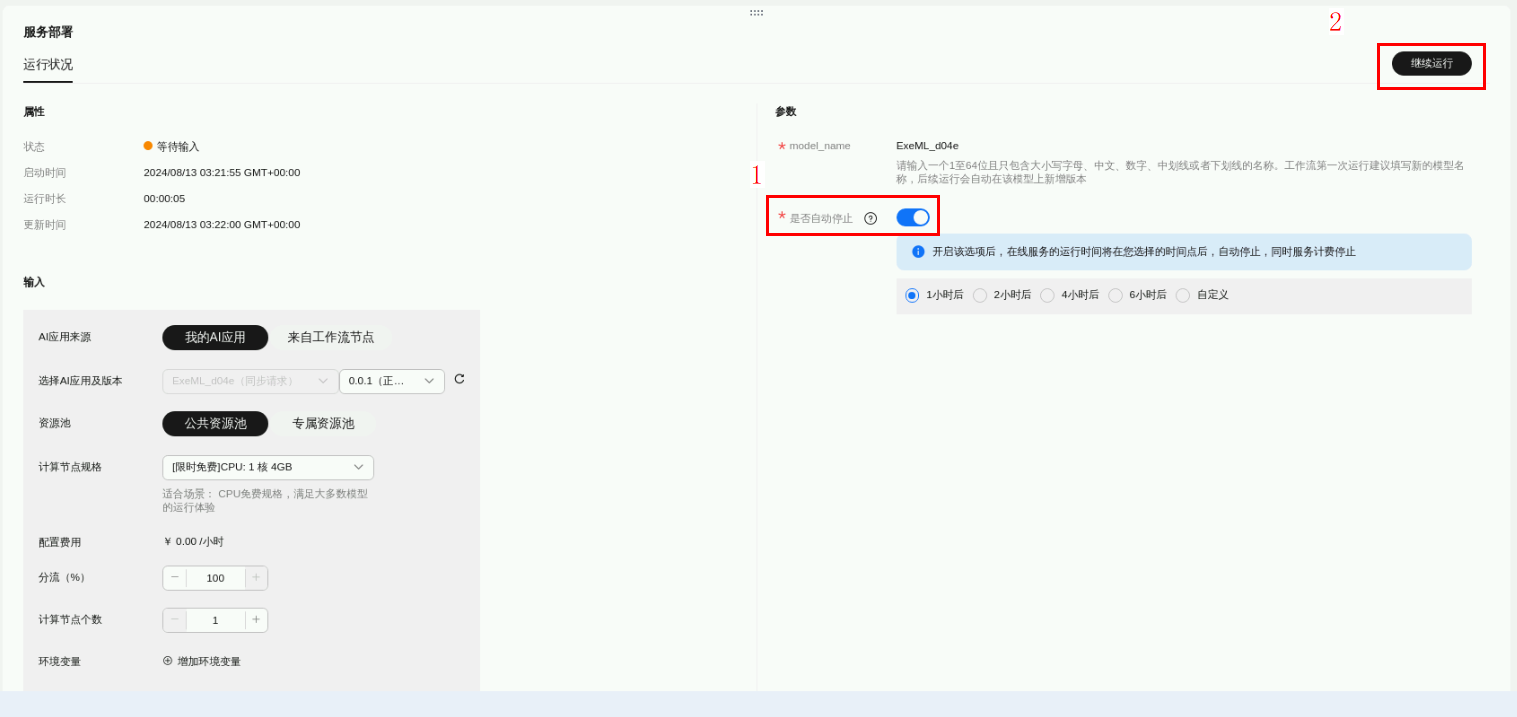
弹出“确认是否继续运行”,点击“确定”。

等待服务部署状态变化,点击实例详情,
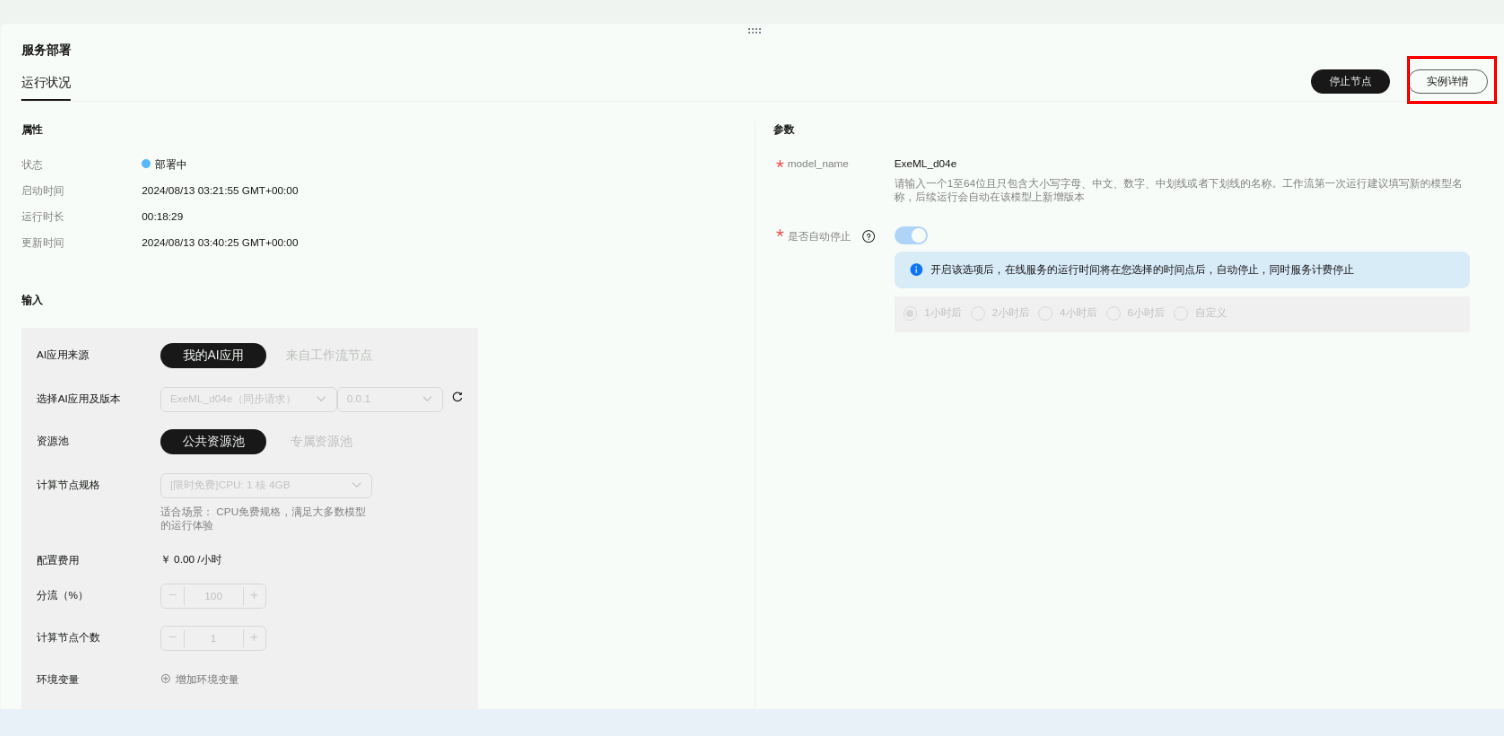
进入部署在线页面,

等待状态由“部署中”变为运行中,即可预测。

点击“预测”,上传/home/user/ExeML_Food_Recognition/foods_recognition——/test目录下的测试图片或者之前下载过的的测试集图片,点“Open”上传,
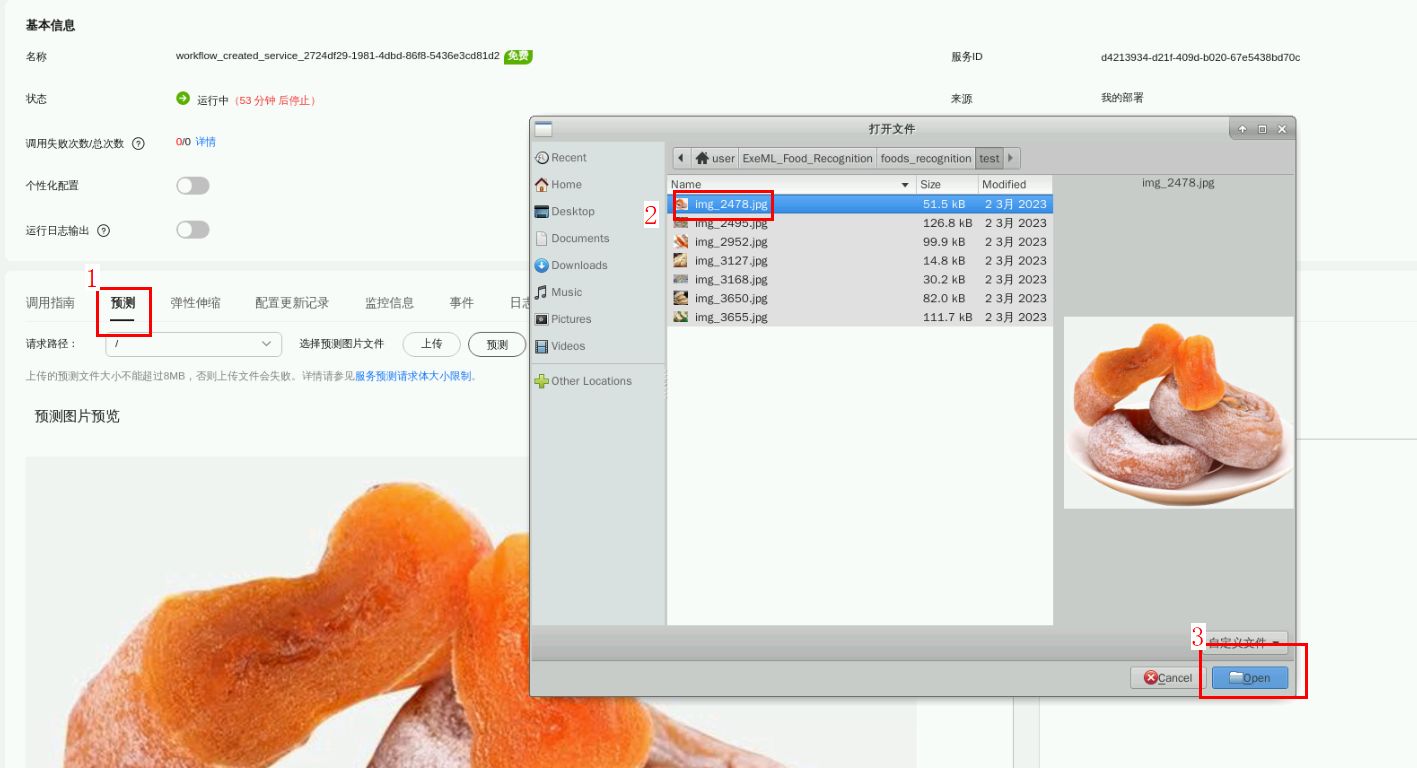
任务九.模型调优
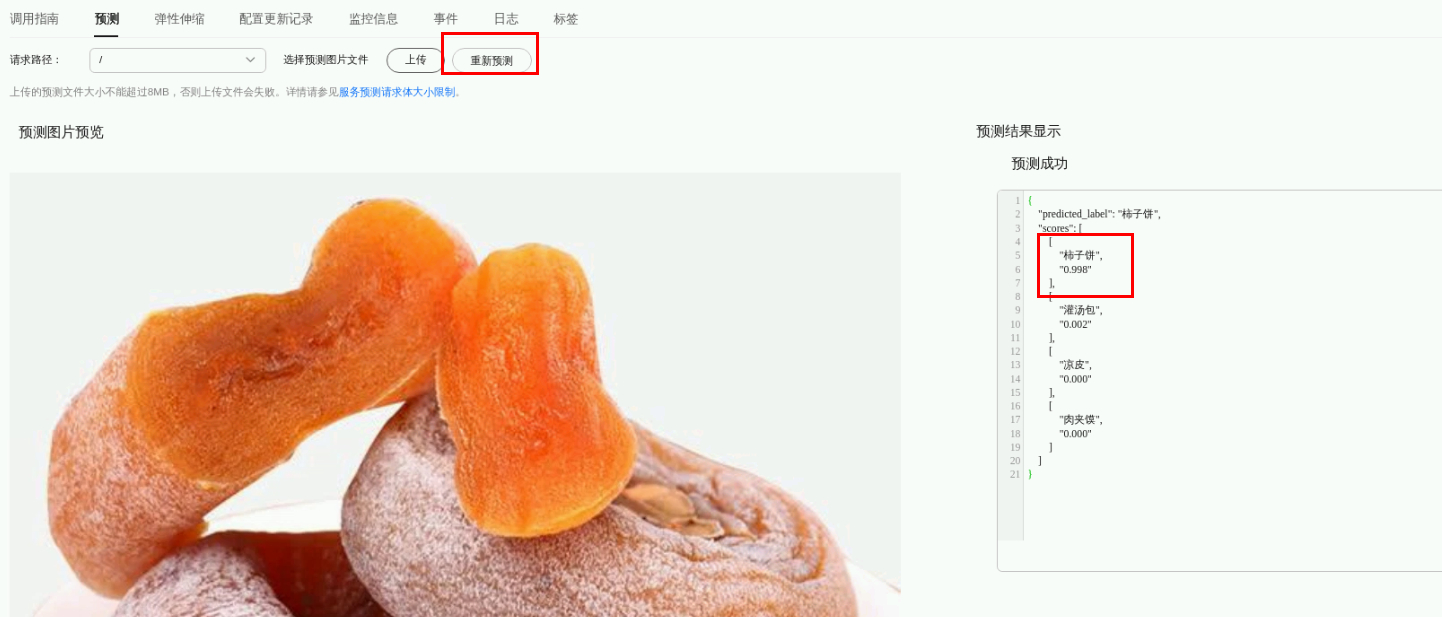
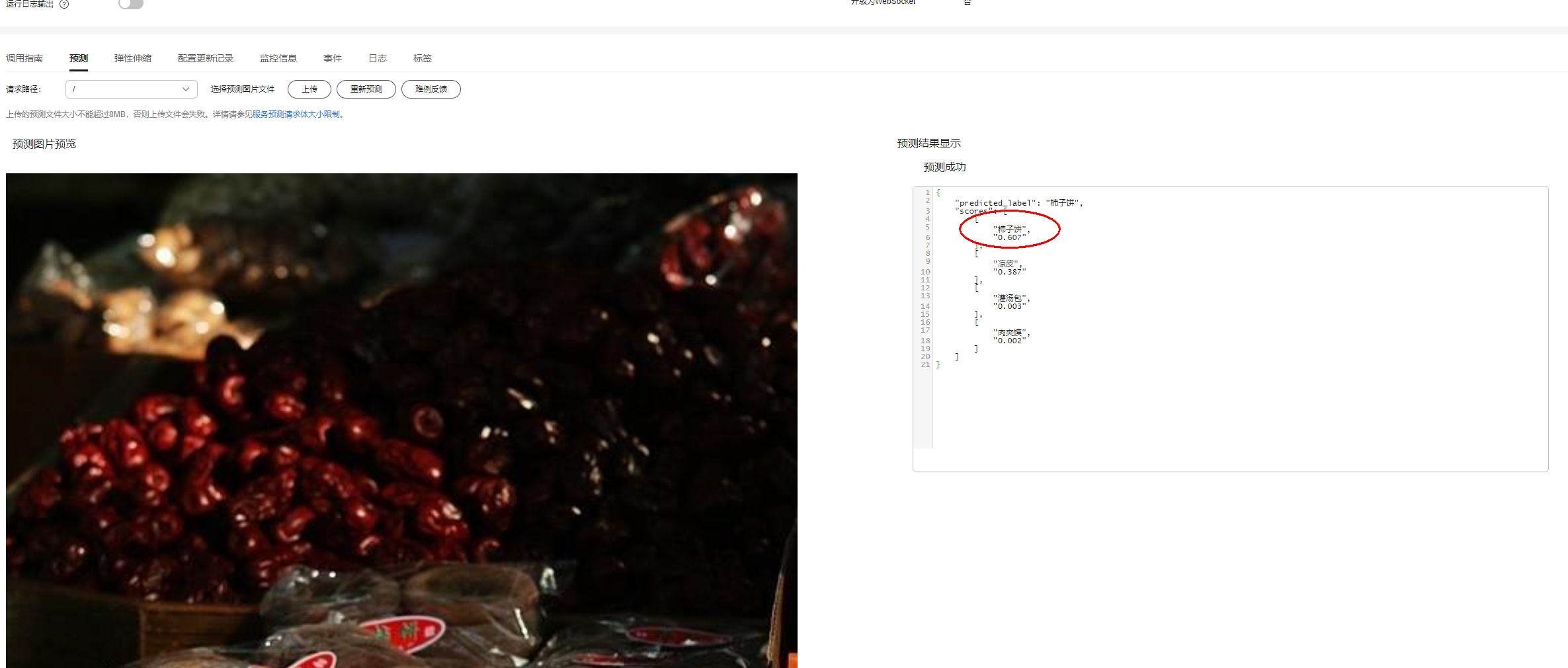
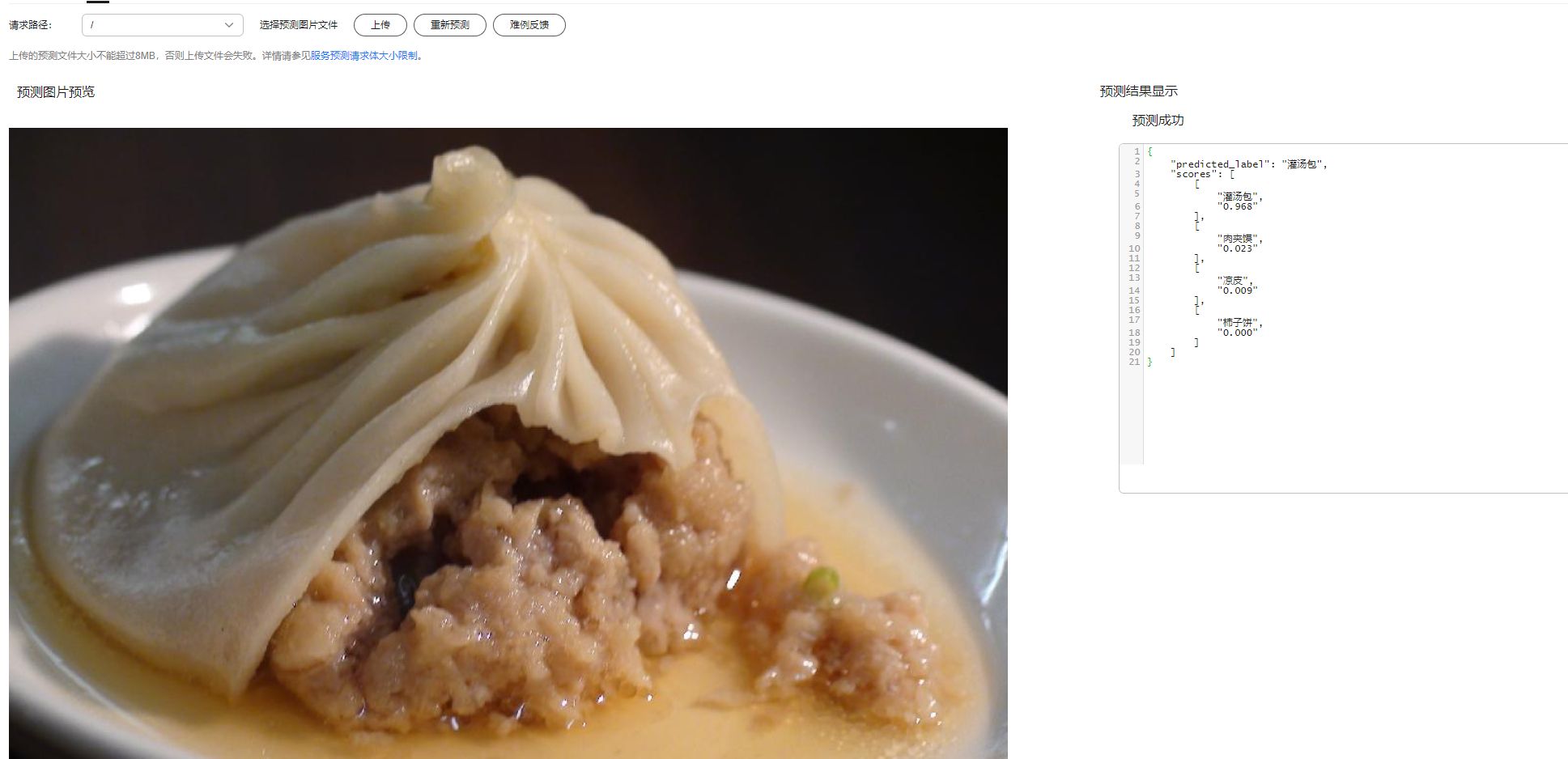
在上面介绍中,你已经使用80张图片训练了一个四分类的美食分类模型,若是没有训练到100%的精度, 在使用其他图片测试时发现有如下预测错误:(注意观察图片内容和右上角红框处的预测结果)
可以上传/home/user/ExeML_Food_Recognition/foods_recognition_assi/test下的目录,预测图片出现预测不精准的情况。
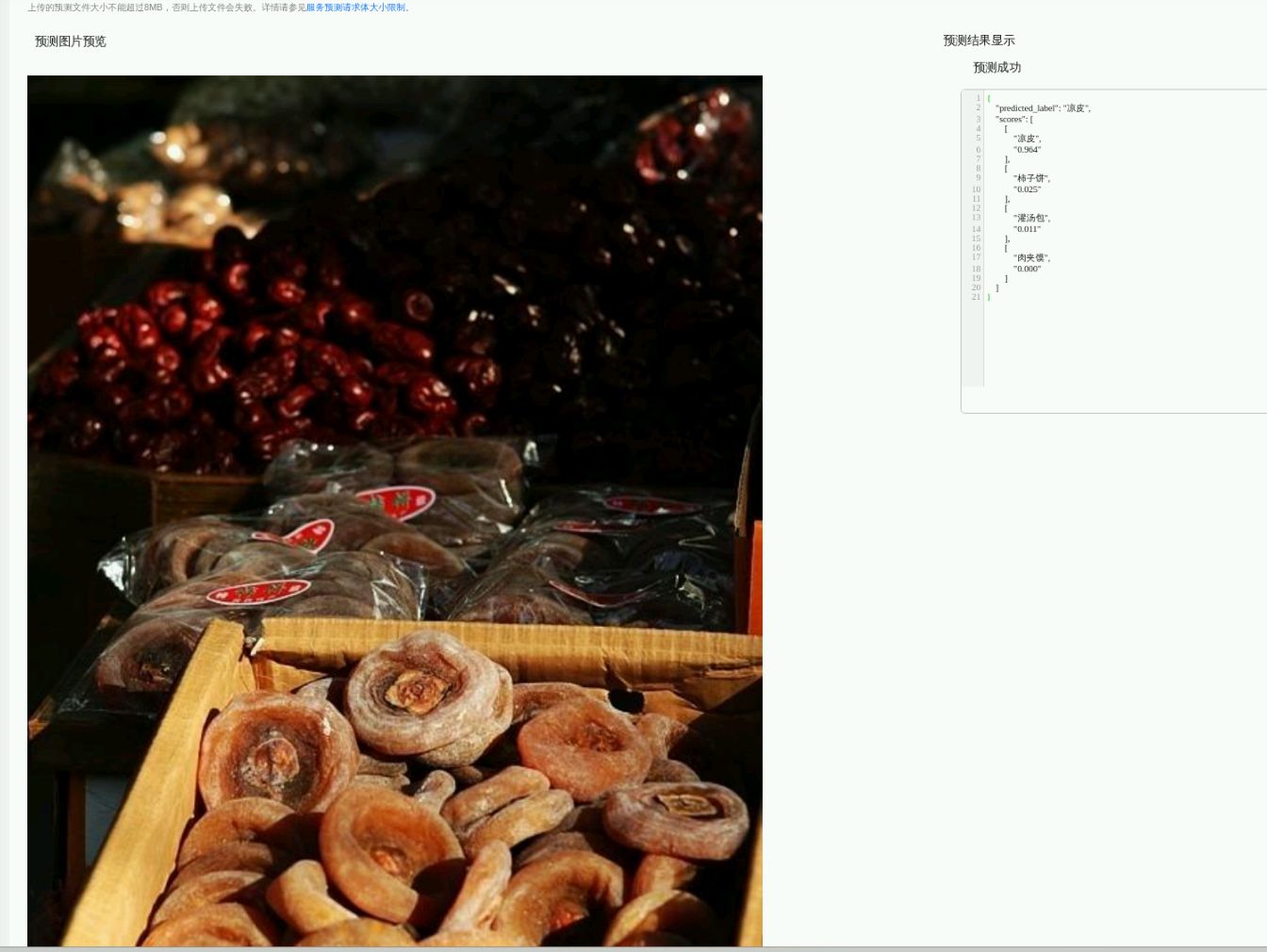

从上面两张图中,可以发现前一张是灌汤包的图,被错识别成肉夹馍,后一张是柿子饼的图,被错识别 成凉皮。 对以上两张预测错误的图片进行分析,可以发现如下规律:
(1)两张预测错误的灌汤包图都是单个包子的近距离拍摄,包子在图片中显得很大,但是查看训练集 可以发现灌汤包的训练图片都是多个包子的图,并没有单个包子的图,如下图所示。训练集中没有出现 单个包子的近景图,所以模型没有学习到预测单个包子的能力;
(2)第一张预测错误的柿子饼图都是很多个柿子饼堆在一起的图,而训练集中的柿子饼图都是少量几个 柿子饼堆在一起,如下图所示。训练集中没有出现很多个柿子饼堆在一起的图,所以模型也就不能预测 这类图。
一句话总结,深度学习模型的能力来自于训练集,在训练集中“见过”的图片,模型才有可能识别,完 全“没见过”、而且差异还有点大的图片,让模型去预测,就容易出错。 既然已经分析清楚了预测出错的原因,那么如何优化模型,才能使得新模型能对上面两张图预测正确呢?
所以需要新增柿子饼和灌汤包的训练集图片。
1.增加训练数据集
返回OBS界面,在XXX/ExeML_Food_Recognition/foods_recognition/train路径下上传本地ExeML_Food_Recognition/foods_recognition_assi/train里面的数据


返回workflow界面,点击“启动”。

进入“实例详情”,进入标注页面,点击“同步数据源”,同步之后可见数据集图片数增加。
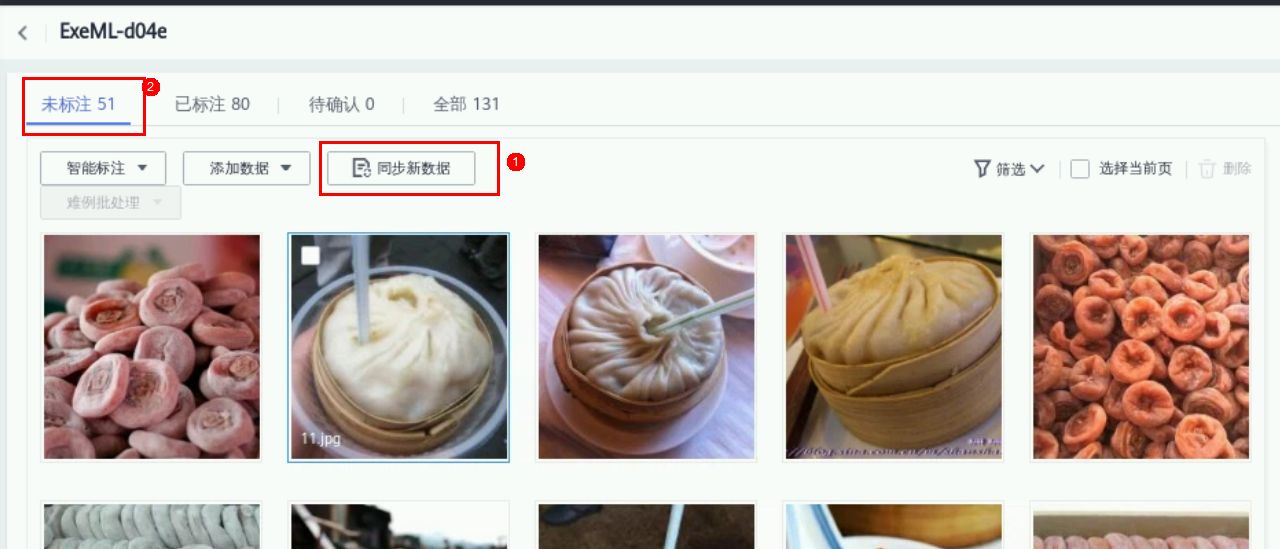
2.数据图片标注
在之前的基础上增加灌汤包和柿子饼的图片,标注完如下图所示:

3.模型部署
在经过“-数据集版本发布-数据校验-图像分类-模型注册”页面等待训练完成,等待几分钟左右,训练完成,可以直接进行部署。
选择“是否自动停止”-“继续运行”

弹出“确认是否就继续运行”,点击“确定”。

等待1分钟后,出现实例详情,点击进入在线部署页面。

4.预测查看结果
点击“预测”,上传上传/home/user/ExeML_Food_Recognition/foods_recognition_assi/test目录下的测试图片或者之前下载过的的测试集图片,点“Open”上传,
可以看到可以正常预测结果。预测后点击“停止”结束资源。
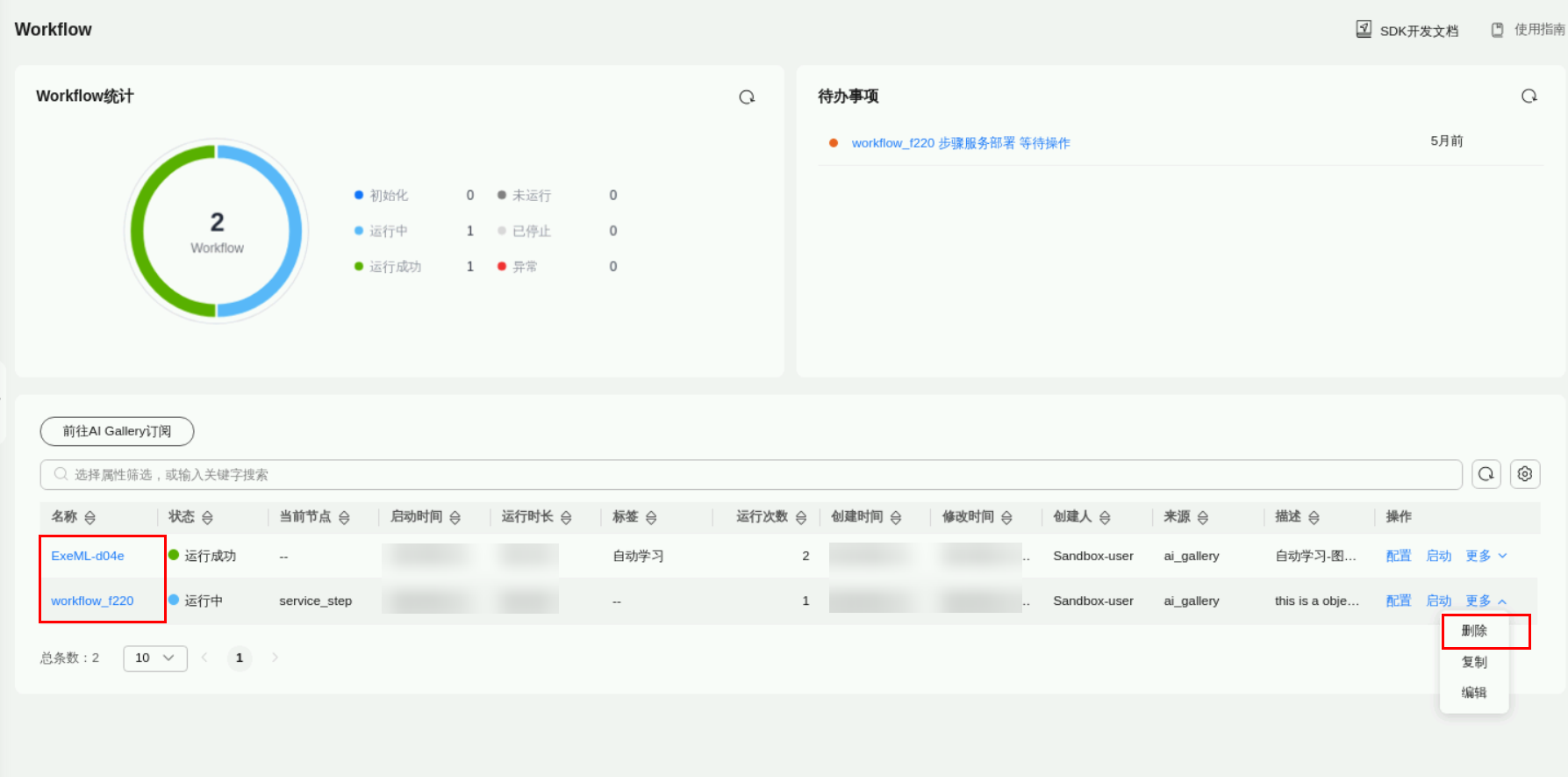
任务十:删除资源
返回ModelArts页面,点击“更多”-“删除”,清理自动学习创建的workflow工作流。否则会持续扣费。
从上面的测试结果可以看出,加入新图片训练得到的模型已经得到了改进,可以正确识别上一个模型识 别错误的图片,且对应类别的score得分都在90%以上。
深度学习模型的训练过程一般都存在随机性,你训练得到的模型可能能正确预测上面2张图中的某些图片,但是对应类别的score得分较低,这是正常现象,你可以自行尝试继续改进模型。
至此,本实验完成anh

- 点赞
- 收藏
- 关注作者
评论(0)