MAE实战:使用MAE提高主干网络的精度(二)

摘要
看完第一篇,大家应该对MAE的训练流程有所了解了。链接:https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/136022910?spm=1001.2014.3001.5501
这篇再讲述一篇案例,我们一起实现吧!
MAE代码
from functools import partial
from typing import Tuple, Optional
import math
import torch
import torch.nn as nn
from .hiera import Hiera, HieraBlock
from .hiera_utils import pretrained_model, undo_windowing, conv_nd
def apply_fusion_head(head: nn.Module, x: torch.Tensor) -> torch.Tensor:
if isinstance(head, nn.Identity):
return x
B, num_mask_units = x.shape[0:2]
# Apply head, e.g [B, #MUs, My, Mx, C] -> head([B * #MUs, C, My, Mx])
permute = [0] + [len(x.shape) - 2] + list(range(1, len(x.shape) - 2))
x = head(x.reshape(B * num_mask_units, *x.shape[2:]).permute(permute))
# Restore original layout, e.g. [B * #MUs, C', My', Mx'] -> [B, #MUs, My', Mx', C']
permute = [0] + list(range(2, len(x.shape))) + [1]
x = x.permute(permute).reshape(B, num_mask_units, *x.shape[2:], x.shape[1])
return x
class MaskedAutoencoderHiera(Hiera):
"""Masked Autoencoder with Hiera backbone"""
def __init__(
self,
in_chans: int = 3,
patch_stride: Tuple[int, ...] = (4, 4),
mlp_ratio: float = 4.0,
decoder_embed_dim: int = 512,
decoder_depth: int = 8,
decoder_num_heads: int = 16,
norm_layer: nn.Module = partial(nn.LayerNorm, eps=1e-6),
**kwdargs,
):
super().__init__(
in_chans=in_chans,
patch_stride=patch_stride,
mlp_ratio=mlp_ratio,
norm_layer=norm_layer,
**kwdargs,
)
del self.norm, self.head
encoder_dim_out = self.blocks[-1].dim_out
self.encoder_norm = norm_layer(encoder_dim_out)
self.mask_unit_spatial_shape_final = [
i // s ** (self.q_pool) for i, s in zip(self.mask_unit_size, self.q_stride)
]
self.tokens_spatial_shape_final = [
i // s ** (self.q_pool)
for i, s in zip(self.tokens_spatial_shape, self.q_stride)
]
# --------------------------------------------------------------------------
# Multi-scale fusion heads
curr_mu_size = self.mask_unit_size
self.multi_scale_fusion_heads = nn.ModuleList()
for i in self.stage_ends[: self.q_pool]: # resolution constant after q_pool
kernel = [
i // s for i, s in zip(curr_mu_size, self.mask_unit_spatial_shape_final)
]
curr_mu_size = [i // s for i, s in zip(curr_mu_size, self.q_stride)]
self.multi_scale_fusion_heads.append(
conv_nd(len(self.q_stride))(
self.blocks[i].dim_out,
encoder_dim_out,
kernel_size=kernel,
stride=kernel,
)
)
self.multi_scale_fusion_heads.append(nn.Identity()) # final stage, no transform
# --------------------------------------------------------------------------
# MAE decoder specifics
self.decoder_embed = nn.Linear(encoder_dim_out, decoder_embed_dim)
self.mask_token = nn.Parameter(torch.zeros(1, 1, decoder_embed_dim))
self.decoder_pos_embed = nn.Parameter(
torch.zeros(
1, math.prod(self.tokens_spatial_shape_final), decoder_embed_dim
)
)
self.decoder_blocks = nn.ModuleList(
[
HieraBlock(
dim=decoder_embed_dim,
dim_out=decoder_embed_dim,
heads=decoder_num_heads,
norm_layer=norm_layer,
mlp_ratio=mlp_ratio,
)
for i in range(decoder_depth)
]
)
self.decoder_norm = norm_layer(decoder_embed_dim)
self.pred_stride = patch_stride[-1] * (
self.q_stride[-1] ** self.q_pool
) # patch stride of prediction
self.decoder_pred = nn.Linear(
decoder_embed_dim,
(self.pred_stride ** min(2, len(self.q_stride))) * in_chans,
) # predictor
# --------------------------------------------------------------------------
self.initialize_weights()
def initialize_weights(self):
nn.init.trunc_normal_(self.mask_token, std=0.02)
nn.init.trunc_normal_(self.decoder_pos_embed, std=0.02)
self.apply(self._mae_init_weights)
# initialize patch_embed like nn.Linear (instead of nn.Conv2d)
w = self.patch_embed.proj.weight.data
nn.init.xavier_uniform_(w.view([w.shape[0], -1]))
def _mae_init_weights(self, m: nn.Module):
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def get_pixel_label_2d(
self, input_img: torch.Tensor, mask: torch.Tensor, norm: bool = True
) -> torch.Tensor:
# mask (boolean tensor): True must correspond to *masked*
input_img = input_img.permute(0, 2, 3, 1)
size = self.pred_stride
label = input_img.unfold(1, size, size).unfold(2, size, size)
label = label.flatten(1, 2).flatten(2)
label = label[mask]
if norm:
mean = label.mean(dim=-1, keepdim=True)
var = label.var(dim=-1, keepdim=True)
label = (label - mean) / (var + 1.0e-6) ** 0.5
return label
def get_pixel_label_3d(
self, input_vid: torch.Tensor, mask: torch.Tensor, norm: bool = True
) -> torch.Tensor:
# mask (boolean tensor): True must correspond to *masked*
# We use time strided loss, only take the first frame from each token
input_vid = input_vid[:, :, ::self.patch_stride[0], :, :]
size = self.pred_stride
label = input_vid.unfold(3, size, size).unfold(4, size, size)
label = label.permute(0, 2, 3, 4, 5, 6, 1) # Different from 2d, mistake during training lol
label = label.flatten(1, 3).flatten(2)
label = label[mask]
if norm:
mean = label.mean(dim=-1, keepdim=True)
var = label.var(dim=-1, keepdim=True)
label = (label - mean) / (var + 1.0e-6) ** 0.5
return label
def forward_encoder(
self, x: torch.Tensor, mask_ratio: float, mask: Optional[torch.Tensor] = None
) -> Tuple[torch.Tensor, torch.Tensor]:
if mask is None:
mask = self.get_random_mask(x, mask_ratio) # [B, #MUs_all]
# Get multi-scale representations from encoder
_, intermediates = super().forward(x, mask, return_intermediates=True)
# Resolution unchanged after q_pool stages, so skip those features
intermediates = intermediates[: self.q_pool] + intermediates[-1:]
# Multi-scale fusion
x = 0.0
for head, interm_x in zip(self.multi_scale_fusion_heads, intermediates):
x += apply_fusion_head(head, interm_x)
x = self.encoder_norm(x)
return x, mask
def forward_decoder(
self, x: torch.Tensor, mask: torch.Tensor
) -> Tuple[torch.Tensor, torch.Tensor]:
# Embed tokens
x = self.decoder_embed(x)
# Combine visible and mask tokens
# x: [B, #MUs, *mask_unit_spatial_shape_final, encoder_dim_out]
# mask: [B, #MUs_all]
x_dec = torch.zeros(*mask.shape, *x.shape[2:], device=x.device, dtype=x.dtype)
mask_tokens = self.mask_token.view(
(1,) * (len(mask.shape) + len(x.shape[2:-1])) + (-1,)
)
mask = mask.reshape(mask.shape + (1,) * len(x.shape[2:]))
mask = mask.expand((-1,) * 2 + x.shape[2:]).bool()
x_dec[mask] = x.flatten()
x_dec = ~mask * mask_tokens + mask * x_dec
# Get back spatial order
x = undo_windowing(
x_dec,
self.tokens_spatial_shape_final,
self.mask_unit_spatial_shape_final,
)
mask = undo_windowing(
mask[..., 0:1],
self.tokens_spatial_shape_final,
self.mask_unit_spatial_shape_final,
)
# Flatten
x = x.reshape(x.shape[0], -1, x.shape[-1])
mask = mask.view(x.shape[0], -1)
# Add pos embed
x = x + self.decoder_pos_embed
# Apply decoder blocks
for blk in self.decoder_blocks:
x = blk(x)
x = self.decoder_norm(x)
# Predictor projection
x = self.decoder_pred(x)
return x, mask
def forward_loss(
self, x: torch.Tensor, pred: torch.Tensor, mask: torch.Tensor
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
"""
Note: in mask, 0 is *visible*, 1 is *masked*
x: e.g. [B, 3, H, W]
pred: [B * num_pred_tokens, num_pixels_in_pred_patch * in_chans]
label: [B * num_pred_tokens, num_pixels_in_pred_patch * in_chans]
"""
if len(self.q_stride) == 2:
label = self.get_pixel_label_2d(x, mask)
elif len(self.q_stride) == 3:
label = self.get_pixel_label_3d(x, mask)
else:
raise NotImplementedError
pred = pred[mask]
loss = (pred - label) ** 2
return loss.mean(), pred, label
def forward(
self,
x: torch.Tensor,
mask_ratio: float = 0.6,
mask: Optional[torch.Tensor] = None,
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
latent, mask = self.forward_encoder(x, mask_ratio, mask=mask)
pred, pred_mask = self.forward_decoder(
latent, mask
) # pred_mask is mask at resolution of *prediction*
# Toggle mask, to generate labels for *masked* tokens
return *self.forward_loss(x, pred, ~pred_mask), mask
接下来,分段解释代码。
初始化
首先看初始化部分,代码如下:
# 定义一个名为MaskedAutoencoderHiera的类,它继承自Hiera类。
# 这是一个使用Hiera作为基础模型的掩码自编码器。
class MaskedAutoencoderHiera(Hiera):
def __init__(
self,
# 输入通道数,默认为3(例如RGB图像)
in_chans: int = 3,
# 图像块的步长,默认为(4, 4),表示在水平和垂直方向上都以4的步长进行划分
patch_stride: Tuple[int, ...] = (4, 4),
# MLP(多层感知器)的扩展比率,默认为4.0。这个比率用于调整MLP层的隐藏层大小。
mlp_ratio: float = 4.0,
# 解码器中嵌入层的维度,默认为512
decoder_embed_dim: int = 512,
# 解码器的深度,默认为8,表示解码器中有8个层
decoder_depth: int = 8,
# 解码器中多头自注意力机制的头数,默认为16
decoder_num_heads: int = 16,
# 归一化层,默认为带有epsilon=1e-6的LayerNorm层
norm_layer: nn.Module = partial(nn.LayerNorm, eps=1e-6),
# 其他关键字参数,用于传递给父类Hiera的初始化方法
**kwdargs,
):
# 调用父类Hiera的初始化方法,并传递相应的参数
super().__init__(
in_chans=in_chans,
patch_stride=patch_stride,
mlp_ratio=mlp_ratio,
norm_layer=norm_layer,
**kwdargs,
)
注释解释:
MaskedAutoencoderHiera类是一个掩码自编码器,它继承自Hiera类,意味着它使用了Hiera类的结构和功能作为基础。- 在初始化方法
__init__中,定义了一些参数来配置这个掩码自编码器。in_chans:输入数据的通道数,例如RGB图像有3个通道。patch_stride:在图像上划分块时的步长,决定了图像被划分成多少个小块。mlp_ratio:用于调整多层感知器(MLP)隐藏层大小的扩展比率。decoder_embed_dim:解码器中嵌入层的维度,决定了解码器内部表示的大小。decoder_depth:解码器的深度,即解码器中有多少层。decoder_num_heads:解码器中多头自注意力机制的头数,用于多头注意力计算。norm_layer:用于归一化的层,这里使用的是带有epsilon=1e-6的LayerNorm层。**kwdargs:其他关键字参数,这些参数会被传递给父类Hiera的初始化方法。
- 最后,使用
super().__init__调用了父类Hiera的初始化方法,并传递了相应的参数。这意味着MaskedAutoencoderHiera类在初始化时会首先执行Hiera类的初始化方法,然后再进行自己的初始化操作(如果有的话)。
编码器
# 删除现有的norm和head属性,可能是为了重新初始化或替换它们。
del self.norm, self.head
# 获取编码器最后一个块的输出维度。
encoder_dim_out = self.blocks[-1].dim_out
# 初始化编码器的新归一化层。
self.encoder_norm = norm_layer(encoder_dim_out)
# 计算mask单元在空间维度上的最终形状,这里考虑了量化池化(q_pool)的影响。
self.mask_unit_spatial_shape_final = [
i // s ** (self.q_pool) for i, s in zip(self.mask_unit_size, self.q_stride)
]
# 计算token在空间维度上的最终形状,同样考虑了量化池化(q_pool)的影响。
self.tokens_spatial_shape_final = [
i // s ** (self.q_pool)
for i, s in zip(self.tokens_spatial_shape, self.q_stride)
]
# --------------------------------------------------------------------------
# 多尺度融合头(Multi-scale fusion heads)
# 初始化一个空的模块列表,用于存放多尺度融合头。
self.multi_scale_fusion_heads = nn.ModuleList()
# 遍历到量化池化(q_pool)之前的每个阶段结束点。
for i in self.stage_ends[: self.q_pool]:
# 根据最终的mask单元空间形状计算卷积核大小。
kernel = [
i // s for i, s in zip(curr_mu_size, self.mask_unit_spatial_shape_final)
]
# 更新当前的mask单元大小,考虑q_stride的影响。
curr_mu_size = [i // s for i, s in zip(curr_mu_size, self.q_stride)]
# 向多尺度融合头列表中添加一个卷积层,该卷积层将当前块的输出维度转换到编码器的输出维度,
# 并且其卷积核大小和步长都设置为上面计算的kernel。
self.multi_scale_fusion_heads.append(
conv_nd(len(self.q_stride))(
self.blocks[i].dim_out,
encoder_dim_out,
kernel_size=kernel,
stride=kernel,
)
)
# 在多尺度融合头列表的末尾添加一个恒等映射(即不做任何变换),这可能是为了处理最后一个阶段或保持某种维度一致性。
self.multi_scale_fusion_heads.append(nn.Identity())
注释解释:
-
del self.norm, self.head:删除当前对象的norm和head属性。这可能是为了重置这些属性,或者是因为它们不再需要。 -
encoder_dim_out:获取编码器最后一个块(self.blocks[-1])的输出维度,这对于后续初始化归一化层和其他层是必要的。 -
self.encoder_norm:使用之前计算的encoder_dim_out维度来初始化一个新的归一化层。norm_layer可能是一个函数,返回特定类型的归一化层(如LayerNorm)。 -
self.mask_unit_spatial_shape_final和self.tokens_spatial_shape_final:计算经过量化池化后的mask单元和token的最终空间形状。这涉及到对原始形状进行一系列除法操作,考虑到q_pool、mask_unit_size和q_stride。 -
self.multi_scale_fusion_heads:这是一个模块列表,用于存放多个多尺度融合头。每个融合头可能是一个卷积层,用于将不同阶段的特征映射到统一的维度。 -
循环内部:对于每个阶段结束点,计算该阶段对应的卷积核大小,并创建一个卷积层来融合特征。这些卷积层将每个阶段的输出转换到编码器的输出维度。
-
nn.Identity():在multi_scale_fusion_heads列表的末尾添加一个恒等映射。这意味着对于列表中的最后一个元素,输入将直接传递到输出,不进行任何变换。这通常用于保持维度一致性或处理最后一个不需要特殊处理的阶段。
解码器部分
这段代码定义了一个MAE(Masked Autoencoder)解码器的具体结构。MAE是一种用于自监督学习的神经网络架构,特别适用于图像和视频数据。现在,我将为您详细解释代码中的每个部分:
- Decoder Embedding Layer:
self.decoder_embed = nn.Linear(encoder_dim_out, decoder_embed_dim)
这一行代码定义了一个线性层,用于将编码器的输出嵌入到解码器的嵌入空间中。encoder_dim_out是编码器输出的维度,而decoder_embed_dim是解码器嵌入的维度。
- Mask Token:
self.mask_token = nn.Parameter(torch.zeros(1, 1, decoder_embed_dim))
这里定义了一个可学习的mask token。在MAE中,一些输入图像块会被掩盖,而这个mask token将作为这些掩盖区域的初始嵌入。
- Decoder Positional Embedding:
self.decoder_pos_embed = nn.Parameter(
torch.zeros(
1, math.prod(self.tokens_spatial_shape_final), decoder_embed_dim
)
)
这是解码器的位置嵌入。与Transformer中的位置嵌入类似,它用于提供图像块在空间中的位置信息。math.prod(self.tokens_spatial_shape_final)计算了所有空间位置的乘积,从而得到位置嵌入的总维度。
- Decoder Blocks:
self.decoder_blocks = nn.ModuleList(
[
HieraBlock(
dim=decoder_embed_dim,
dim_out=decoder_embed_dim,
heads=decoder_num_heads,
norm_layer=norm_layer,
mlp_ratio=mlp_ratio,
)
for i in range(decoder_depth)
]
)
解码器由多个HieraBlock组成,这是一个自定义的块,可能是某种改进的Transformer块。每个块都有特定的维度、头数、归一化层和MLP比率。
- Decoder Normalization:
self.decoder_norm = norm_layer(decoder_embed_dim)
这行代码为解码器定义了一个归一化层,用于在解码过程中稳定嵌入。
- Predictor Layer:
self.decoder_pred = nn.Linear(
decoder_embed_dim,
(self.pred_stride ** min(2, len(self.q_stride))) * in_chans,
)
预测器层是一个线性层,它将解码器的输出转换为原始图像空间。self.pred_stride计算了预测的patch stride,而in_chans是输入图像的通道数。
- Weight Initialization:
self.initialize_weights()
这行代码调用了一个方法,用于初始化网络中的所有权重。虽然代码中没有显示这个方法的具体实现,但它通常会根据某种策略(如Xavier初始化或Kaiming初始化)来设置权重。
总之,这段代码定义了一个MAE解码器,包括嵌入层、位置嵌入、多个解码器块、归一化层和预测器层。这些组件协同工作,以从编码器的输出中重建原始图像。
forward函数
代码:
def forward(
self,
x: torch.Tensor,
mask_ratio: float = 0.6,
mask: Optional[torch.Tensor] = None,
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
# 调用编码器,传入输入张量x、掩码比例mask_ratio和掩码张量mask,得到潜在变量latent和掩码mask
latent, mask = self.forward_encoder(x, mask_ratio, mask=mask)
# 调用解码器,传入潜在变量latent和掩码mask,得到预测值pred和预测掩码pred_mask
pred, pred_mask = self.forward_decoder(
latent, mask
) # pred_mask is mask at resolution of *prediction*
# 计算损失值,调用损失函数,传入输入张量x、预测值pred和预测掩码的补集(即掩码为False的位置)
# 返回预测值、损失值、掩码和预测掩码
return *self.forward_loss(x, pred, ~pred_mask), mask
这段代码是一个名为forward的方法,它接收四个参数:x(一个torch.Tensor类型的输入张量),mask_ratio(一个浮点数,表示掩码比例,默认值为0.6),mask(一个可选的torch.Tensor类型的掩码张量,默认值为None)。该方法返回一个包含四个元素的元组,分别是预测值、损失值、掩码和预测掩码。
方法的主要步骤如下:
- 调用
self.forward_encoder方法,传入输入张量x、掩码比例mask_ratio和掩码张量mask,得到潜在变量latent和掩码mask。 - 调用
self.forward_decoder方法,传入潜在变量latent和掩码mask,得到预测值pred和预测掩码pred_mask。 - 计算损失值,调用
self.forward_loss方法,传入输入张量x、预测值pred和预测掩码的补集(即掩码为False的位置)。 - 返回预测值、损失值、掩码和预测掩码。
forward_encoder函数
def forward_encoder(
self, x: torch.Tensor, mask_ratio: float, mask: Optional[torch.Tensor] = None
) -> Tuple[torch.Tensor, torch.Tensor]:
if mask is None:
mask = self.get_random_mask(x, mask_ratio) # [B, #MUs_all]
# 从编码器获取多尺度表示
_, intermediates = super().forward(x, mask, return_intermediates=True)
# q_pool阶段后分辨率不变,跳过这些特征
intermediates = intermediates[: self.q_pool] + intermediates[-1:]
# 多尺度融合
x = 0.0
for head, interm_x in zip(self.multi_scale_fusion_heads, intermediates):
x += apply_fusion_head(head, interm_x)
x = self.encoder_norm(x)
return x, mask
接收三个参数:x(一个torch.Tensor类型的输入张量),mask_ratio(一个浮点数,表示掩码比例),mask(一个可选的torch.Tensor类型的掩码张量,默认值为None)。该方法返回一个包含两个元素的元组,分别是潜在变量和掩码。
方法的主要步骤如下:
- 如果
mask为None,调用self.get_random_mask方法生成随机掩码。 - 从编码器获取多尺度表示,调用父类的
forward方法,传入输入张量x、掩码mask和return_intermediates=True参数,得到中间结果intermediates。 - 跳过q_pool阶段后分辨率不变的特征,将
intermediates切片为[: self.q_pool] + intermediates[-1:]。 - 进行多尺度融合,初始化
x为0.0,遍历self.multi_scale_fusion_heads和intermediates,将每个头部应用到对应的中间结果上,累加到x中。 - 对
x进行归一化处理,调用self.encoder_norm(x)。 - 返回潜在变量
x和掩码mask。
forward_decoder函数
def forward_decoder(
self, x: torch.Tensor, mask: torch.Tensor
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
解码器的前向传播函数。
参数:
- x: 输入张量,通常是编码器的输出。
- mask: 掩码张量,指示哪些位置被掩盖。
返回:
- pred: 解码器的预测输出。
- pred_mask: 预测输出上的掩码,指示哪些位置是预测的。
"""
# 嵌入标记
x = self.decoder_embed(x) # 对输入x进行嵌入操作
# 结合可见和掩码标记
# 初始化解码器输入张量,大小与mask相同,并填充为0,除了与x对应的可见位置
x_dec = torch.zeros(*mask.shape, *x.shape[2:], device=x.device, dtype=x.dtype)
# 将mask_token调整成与x_dec相匹配的维度
mask_tokens = self.mask_token.view(
(1,) * (len(mask.shape) + len(x.shape[2:-1])) + (-1,)
)
# 调整mask的形状,并扩展它以匹配x_dec的维度
mask = mask.reshape(mask.shape + (1,) * len(x.shape[2:]))
mask = mask.expand((-1,) * 2 + x.shape[2:]).bool()
# 在x_dec的掩码位置填入x的值,其余位置保持为0
x_dec[mask] = x.flatten()
# 使用mask_tokens替换x_dec中的0值(即掩码位置),并保留其他位置的值
x_dec = ~mask * mask_tokens + mask * x_dec
# 恢复空间顺序
# 使用undo_windowing函数调整x_dec和mask的空间顺序
x = undo_windowing(
x_dec,
self.tokens_spatial_shape_final,
self.mask_unit_spatial_shape_final,
)
mask = undo_windowing(
mask[..., 0:1],
self.tokens_spatial_shape_final,
self.mask_unit_spatial_shape_final,
)
# 展平
# 将x展平为[batch_size, sequence_length, feature_dim]的形状
x = x.reshape(x.shape[0], -1, x.shape[-1])
# 将mask展平为[batch_size, sequence_length]的形状
mask = mask.view(x.shape[0], -1)
# 添加位置嵌入
# 将位置嵌入加到x上
x = x + self.decoder_pos_embed
# 应用解码器块
# 遍历解码器块列表,并依次应用它们到x上
for blk in self.decoder_blocks:
x = blk(x)
# 对x进行归一化
x = self.decoder_norm(x)
# 预测器投影
# 将x通过预测器进行投影,得到最终的预测输出
x = self.decoder_pred(x)
return x, mask
接收两个参数:x(一个torch.Tensor类型的输入张量),mask(一个torch.Tensor类型的掩码张量)。该方法返回一个包含两个元素的元组,分别是解码后的张量和掩码。
方法的主要步骤如下:
- 对输入张量
x进行嵌入操作,得到x_dec。 - 将可见的和掩码的tokens组合在一起。
- 将
x_dec恢复到空间顺序。 - 将
x_dec展平。 - 添加位置嵌入。
- 应用解码器块。
- 对解码后的张量进行归一化处理。
- 进行预测投影。
- 返回解码后的张量和掩码。
forward_loss函数
def forward_loss(
self, x: torch.Tensor, pred: torch.Tensor, mask: torch.Tensor
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
"""
计算损失函数值。
参数:
- x: 输入图像张量,形状例如 [B, 3, H, W],其中 B 是批处理大小,3 是通道数(例如 RGB),H 是高度,W 是宽度。
- pred: 模型的预测输出张量,形状例如 [B * num_pred_tokens, num_pixels_in_pred_patch * in_chans]。
这里 B * num_pred_tokens 是预测标记的总数,num_pixels_in_pred_patch * in_chans 是每个预测标记对应的像素数和通道数的乘积。
- mask: 掩码张量,指示哪些位置是可见的(值为0),哪些位置是掩码的(值为1)。
返回:
- loss.mean(): 平均损失值,类型为 torch.Tensor。
- pred: 过滤后的预测输出张量,仅包含被掩码的位置,类型为 torch.Tensor。
- label: 对应的标签张量,仅包含被掩码的位置,类型为 torch.Tensor。
"""
# 根据q_stride的长度决定是获取2D还是3D的标签
if len(self.q_stride) == 2:
# 如果是2D,则调用get_pixel_label_2d方法来获取标签
label = self.get_pixel_label_2d(x, mask)
elif len(self.q_stride) == 3:
# 如果是3D,则调用get_pixel_label_3d方法来获取标签
label = self.get_pixel_label_3d(x, mask)
else:
# 如果q_stride的长度既不是2也不是3,则抛出NotImplementedError异常
raise NotImplementedError
# 使用mask来过滤pred张量,仅保留被掩码的位置
pred = pred[mask]
# 计算pred和label之间的均方误差损失
loss = (pred - label) ** 2
# 返回平均损失值、过滤后的pred和label
return loss.mean(), pred, label
接收三个参数:x(一个torch.Tensor类型的输入张量),pred(一个torch.Tensor类型的预测张量),mask(一个torch.Tensor类型的掩码张量)。函数的返回值是一个包含三个元素的元组,分别是损失值、预测值和标签。
函数首先根据self.q_stride的长度判断是2D还是3D的情况,然后调用相应的get_pixel_label_2d或get_pixel_label_3d方法生成标签。接着,根据掩码对预测值进行筛选,并计算损失值。最后,返回损失值、预测值和标签。
制作数据集
我们整理还的图像分类的数据集结构是这样的
data
├─Black-grass
├─Charlock
├─Cleavers
├─Common Chickweed
├─Common wheat
├─Fat Hen
├─Loose Silky-bent
├─Maize
├─Scentless Mayweed
├─Shepherds Purse
├─Small-flowered Cranesbill
└─Sugar beet
pytorch和keras默认加载方式是ImageNet数据集格式,格式是
├─data
│ ├─val
│ │ ├─Black-grass
│ │ ├─Charlock
│ │ ├─Cleavers
│ │ ├─Common Chickweed
│ │ ├─Common wheat
│ │ ├─Fat Hen
│ │ ├─Loose Silky-bent
│ │ ├─Maize
│ │ ├─Scentless Mayweed
│ │ ├─Shepherds Purse
│ │ ├─Small-flowered Cranesbill
│ │ └─Sugar beet
│ └─train
│ ├─Black-grass
│ ├─Charlock
│ ├─Cleavers
│ ├─Common Chickweed
│ ├─Common wheat
│ ├─Fat Hen
│ ├─Loose Silky-bent
│ ├─Maize
│ ├─Scentless Mayweed
│ ├─Shepherds Purse
│ ├─Small-flowered Cranesbill
│ └─Sugar beet
新增格式转化脚本makedata.py,插入代码:
import glob
import os
import shutil
image_list=glob.glob('data1/*/*.png')
print(image_list)
file_dir='data'
if os.path.exists(file_dir):
print('true')
#os.rmdir(file_dir)
shutil.rmtree(file_dir)#删除再建立
os.makedirs(file_dir)
else:
os.makedirs(file_dir)
from sklearn.model_selection import train_test_split
trainval_files, val_files = train_test_split(image_list, test_size=0.3, random_state=42)
train_dir='train'
val_dir='val'
train_root=os.path.join(file_dir,train_dir)
val_root=os.path.join(file_dir,val_dir)
for file in trainval_files:
file_class=file.replace("\\","/").split('/')[-2]
file_name=file.replace("\\","/").split('/')[-1]
file_class=os.path.join(train_root,file_class)
if not os.path.isdir(file_class):
os.makedirs(file_class)
shutil.copy(file, file_class + '/' + file_name)
for file in val_files:
file_class=file.replace("\\","/").split('/')[-2]
file_name=file.replace("\\","/").split('/')[-1]
file_class=os.path.join(val_root,file_class)
if not os.path.isdir(file_class):
os.makedirs(file_class)
shutil.copy(file, file_class + '/' + file_name)
执行makedata后就可以开启后面的训练和测试了
训练MAE模型
新建train_mea.py,加入下面的代码。代码就比较简单了。
import json
import os
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
from timm.utils import AverageMeter
from hiera.hiera_mae import mae_hiera_tiny_224
from torch.autograd import Variable
from torchvision import datasets
torch.backends.cudnn.benchmark = False
import warnings
warnings.filterwarnings("ignore")
os.environ['CUDA_VISIBLE_DEVICES'] = "0,1"
# 定义训练过程
def train(model, device, train_loader, optimizer, epoch):
model.train()
loss_meter = AverageMeter()
total_num = len(train_loader.dataset)
print(total_num, len(train_loader))
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device, non_blocking=True), Variable(target).to(device, non_blocking=True)
loss, preds, labels, mask = model(data, mask_ratio=0.6)
optimizer.zero_grad()
loss.backward()
optimizer.step()
lr = optimizer.state_dict()['param_groups'][0]['lr']
loss_meter.update(loss.item(), target.size(0))
if (batch_idx + 1) % 10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\tLR:{:.9f}'.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
100. * (batch_idx + 1) / len(train_loader), loss.item(), lr))
ave_loss = loss_meter.avg
print('epoch:{}\tloss:{:.2f}'.format(epoch, ave_loss))
return ave_loss
# 验证过程
@torch.no_grad()
def val(model, device, test_loader):
global Best_LOSS
model.eval()
loss_meter = AverageMeter()
total_num = len(test_loader.dataset)
print(total_num, len(test_loader))
for data, target in test_loader:
data, target = data.to(device, non_blocking=True), target.to(device, non_blocking=True)
loss, preds, labels, mask = model(data, mask_ratio=0.6)
loss_meter.update(loss.item(), target.size(0))
loss = loss_meter.avg
print('\nVal set: Average loss: {:.4f}\n'.format(loss_meter.avg))
if loss < Best_LOSS:
if isinstance(model, torch.nn.DataParallel):
torch.save(model.module, file_dir + '/' + 'best.pth')
else:
torch.save(model, file_dir + '/' + 'best.pth')
Best_LOSS = loss
if isinstance(model, torch.nn.DataParallel):
state = {
'epoch': epoch,
'state_dict': model.module.state_dict(),
'Best_LOSS': Best_LOSS
}
else:
state = {
'epoch': epoch,
'state_dict': model.state_dict(),
'Best_LOSS': Best_LOSS
}
torch.save(state, file_dir + "/" + 'model_' + str(epoch) + '_' + str(round(loss, 3)) + '.pth')
return loss
def seed_everything(seed=42):
os.environ['PYHTONHASHSEED'] = str(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
if __name__ == '__main__':
# 创建保存模型的文件夹
file_dir = 'checkpoints/hiera/'
if os.path.exists(file_dir):
print('true')
os.makedirs(file_dir, exist_ok=True)
else:
os.makedirs(file_dir)
# 设置全局参数
model_lr = 1e-3
BATCH_SIZE = 16
EPOCHS = 600
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
use_dp = True # 是否开启dp方式的多卡训练
classes = 12
Best_LOSS = 1 # 记录最高得分
model_ema_decay = 0.9998
start_epoch = 1
seed = 42
seed_everything(seed)
# 数据预处理7
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933])
])
dataset_train = datasets.ImageFolder('data/train', transform=transform)
dataset_test = datasets.ImageFolder("data/val", transform=transform)
with open('class.txt', 'w') as file:
file.write(str(dataset_train.class_to_idx))
with open('class.json', 'w', encoding='utf-8') as file:
file.write(json.dumps(dataset_train.class_to_idx))
# 导入数据
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)
# 设置模型
model_ft = mae_hiera_tiny_224(pretrained=False)
model_ft.to(DEVICE)
# 选择简单暴力的Adam优化器,学习率调低
optimizer = optim.AdamW(model_ft.parameters(), lr=model_lr)
cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=20, eta_min=1e-6)
if torch.cuda.device_count() > 1 and use_dp:
print("Let's use", torch.cuda.device_count(), "GPUs!")
model_ft = torch.nn.DataParallel(model_ft)
# 训练与验证
is_set_lr = False
log_dir = {}
train_loss_list, val_loss_list, epoch_list = [], [], []
for epoch in range(start_epoch, EPOCHS + 1):
epoch_list.append(epoch)
log_dir['epoch_list'] = epoch_list
train_loss = train(model_ft, DEVICE, train_loader, optimizer, epoch)
train_loss_list.append(train_loss)
log_dir['train_loss'] = train_loss_list
val_loss = val(model_ft, DEVICE, test_loader)
val_loss_list.append(val_loss)
log_dir['val_loss'] = val_loss_list
with open(file_dir + '/result.json', 'w', encoding='utf-8') as file:
file.write(json.dumps(log_dir))
if epoch < 600:
cosine_schedule.step()
else:
if not is_set_lr:
for param_group in optimizer.param_groups:
param_group["lr"] = 1e-6
is_set_lr = True
fig = plt.figure(1)
plt.plot(epoch_list, train_loss_list, 'r-', label=u'Train Loss')
# 显示图例
plt.plot(epoch_list, val_loss_list, 'b-', label=u'Val Loss')
plt.legend(["Train Loss", "Val Loss"], loc="upper right")
plt.xlabel(u'epoch')
plt.ylabel(u'loss')
plt.title('Model Loss ')
plt.savefig(file_dir + "/loss.png")
plt.close(1)
使用MAE模型
训练完成后就可以使用mae模型,如下图:

在hiera.py脚本中,增加调用mae模型的逻辑。将default设置为mae,就会调用mae对应的模型。
还需要修改hiera_utils.py脚本中加载预训练模型的逻辑,如下图:
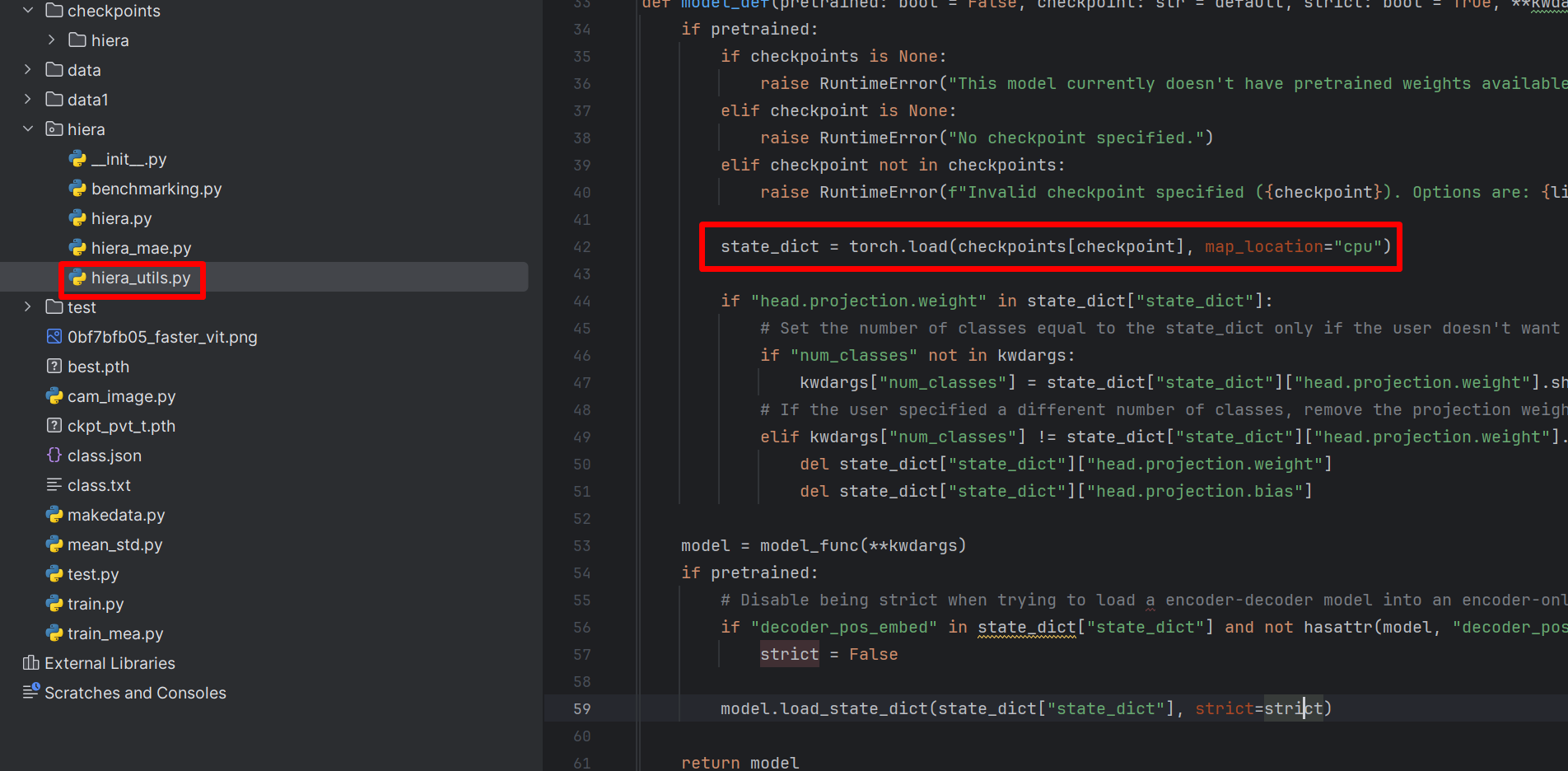
使用state_dict = torch.load(checkpoints[checkpoint], map_location="cpu")替换原来加载超链接的函数
训练
训练部分和平时训练的写法没有区别,这里就不详细解释,代码:
import json
import os
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
from timm.utils import accuracy, AverageMeter, ModelEma
from sklearn.metrics import classification_report
from timm.data.mixup import Mixup
from timm.loss import SoftTargetCrossEntropy
from hiera.hiera import hiera_tiny_224
from torch.autograd import Variable
from torchvision import datasets
torch.backends.cudnn.benchmark = False
import warnings
warnings.filterwarnings("ignore")
os.environ['CUDA_VISIBLE_DEVICES'] = "0,1"
# 定义训练过程
def train(model, device, train_loader, optimizer, epoch,model_ema):
model.train()
loss_meter = AverageMeter()
acc1_meter = AverageMeter()
acc5_meter = AverageMeter()
total_num = len(train_loader.dataset)
print(total_num, len(train_loader))
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device, non_blocking=True), Variable(target).to(device,non_blocking=True)
samples, targets = mixup_fn(data, target)
output = model(samples)
optimizer.zero_grad()
if use_amp:
with torch.cuda.amp.autocast():
loss = torch.nan_to_num(criterion_train(output, targets))
scaler.scale(loss).backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), CLIP_GRAD)
# Unscales gradients and calls
# or skips optimizer.step()
scaler.step(optimizer)
# Updates the scale for next iteration
scaler.update()
else:
loss = criterion_train(output, targets)
loss.backward()
# torch.nn.utils.clip_grad_norm_(models.parameters(), CLIP_GRAD)
optimizer.step()
if model_ema is not None:
model_ema.update(model)
torch.cuda.synchronize()
lr = optimizer.state_dict()['param_groups'][0]['lr']
loss_meter.update(loss.item(), target.size(0))
acc1, acc5 = accuracy(output, target, topk=(1, 5))
loss_meter.update(loss.item(), target.size(0))
acc1_meter.update(acc1.item(), target.size(0))
acc5_meter.update(acc5.item(), target.size(0))
if (batch_idx + 1) % 10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\tLR:{:.9f}'.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
100. * (batch_idx + 1) / len(train_loader), loss.item(), lr))
ave_loss =loss_meter.avg
acc = acc1_meter.avg
print('epoch:{}\tloss:{:.2f}\tacc:{:.2f}'.format(epoch, ave_loss, acc))
return ave_loss, acc
## 验证过程
@torch.no_grad()
def val(model, device, test_loader):
global Best_ACC
model.eval()
loss_meter = AverageMeter()
acc1_meter = AverageMeter()
acc5_meter = AverageMeter()
total_num = len(test_loader.dataset)
print(total_num, len(test_loader))
val_list = []
pred_list = []
for data, target in test_loader:
for t in target:
val_list.append(t.data.item())
data, target = data.to(device, non_blocking=True), target.to(device, non_blocking=True)
output = model(data)
loss = criterion_val(output, target)
_, pred = torch.max(output.data, 1)
for p in pred:
pred_list.append(p.data.item())
acc1, acc5 = accuracy(output, target, topk=(1, 5))
loss_meter.update(loss.item(), target.size(0))
acc1_meter.update(acc1.item(), target.size(0))
acc5_meter.update(acc5.item(), target.size(0))
acc = acc1_meter.avg
print('\nVal set: Average loss: {:.4f}\tAcc1:{:.3f}%\tAcc5:{:.3f}%\n'.format(
loss_meter.avg, acc, acc5_meter.avg))
if acc > Best_ACC:
if isinstance(model, torch.nn.DataParallel):
torch.save(model.module, file_dir + '/' + 'best.pth')
else:
torch.save(model, file_dir + '/' + 'best.pth')
Best_ACC = acc
if isinstance(model, torch.nn.DataParallel):
state = {
'epoch': epoch,
'state_dict': model.module.state_dict(),
'Best_ACC': Best_ACC
}
if use_ema:
state['state_dict_ema'] = model.module.state_dict()
torch.save(state, file_dir + "/" + 'model_' + str(epoch) + '_' + str(round(acc, 3)) + '.pth')
else:
state = {
'epoch': epoch,
'state_dict': model.state_dict(),
'Best_ACC': Best_ACC
}
if use_ema:
state['state_dict_ema'] = model.state_dict()
torch.save(state, file_dir + "/" + 'model_' + str(epoch) + '_' + str(round(acc, 3)) + '.pth')
return val_list, pred_list, loss_meter.avg, acc
def seed_everything(seed=42):
os.environ['PYHTONHASHSEED'] = str(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
if __name__ == '__main__':
# 创建保存模型的文件夹
file_dir = 'checkpoints/hiera/'
if os.path.exists(file_dir):
print('true')
os.makedirs(file_dir, exist_ok=True)
else:
os.makedirs(file_dir)
# 设置全局参数
model_lr = 1e-4
BATCH_SIZE = 64
EPOCHS = 300
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
use_amp = True # 是否使用混合精度
use_dp = True # 是否开启dp方式的多卡训练
classes = 12
resume = None
CLIP_GRAD = 5.0
Best_ACC = 0 # 记录最高得分
use_ema = False
model_ema_decay = 0.9998
start_epoch = 1
seed = 1
seed_everything(seed)
# 数据预处理7
transform = transforms.Compose([
transforms.RandomRotation(10),
transforms.GaussianBlur(kernel_size=(5, 5), sigma=(0.1, 3.0)),
transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5),
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933])
])
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933])
])
mixup_fn = Mixup(
mixup_alpha=0.8, cutmix_alpha=1.0, cutmix_minmax=None,
prob=0.1, switch_prob=0.5, mode='batch',
label_smoothing=0.1, num_classes=classes)
# 读取数据
dataset_train = datasets.ImageFolder('data/train', transform=transform)
dataset_test = datasets.ImageFolder("data/val", transform=transform_test)
with open('class.txt', 'w') as file:
file.write(str(dataset_train.class_to_idx))
with open('class.json', 'w', encoding='utf-8') as file:
file.write(json.dumps(dataset_train.class_to_idx))
# 导入数据
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)
# 实例化模型并且移动到GPU
criterion_train = SoftTargetCrossEntropy()
criterion_val = torch.nn.CrossEntropyLoss()
# 设置模型
model_ft = hiera_tiny_224(pretrained=True)
print(model_ft)
num_fr = model_ft.head.projection.in_features
model_ft.head.projection = nn.Linear(num_fr, classes)
print(model_ft)
if resume:
model = torch.load(resume)
print(model['state_dict'].keys())
model_ft.load_state_dict(model['state_dict'])
Best_ACC = model['Best_ACC']
start_epoch = model['epoch'] + 1
model_ft.to(DEVICE)
# 选择简单暴力的Adam优化器,学习率调低
optimizer = optim.AdamW(model_ft.parameters(), lr=model_lr)
cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=20, eta_min=1e-6)
if use_amp:
scaler = torch.cuda.amp.GradScaler()
if torch.cuda.device_count() > 1 and use_dp:
print("Let's use", torch.cuda.device_count(), "GPUs!")
model_ft = torch.nn.DataParallel(model_ft)
if use_ema:
model_ema = ModelEma(
model_ft,
decay=model_ema_decay,
device=DEVICE,
resume=resume)
else:
model_ema = None
# 训练与验证
is_set_lr = False
log_dir = {}
train_loss_list, val_loss_list, train_acc_list, val_acc_list, epoch_list = [], [], [], [], []
if resume and os.path.isfile(file_dir + "result.json"):
with open(file_dir + 'result.json', 'r', encoding='utf-8') as file:
logs = json.load(file)
train_acc_list = logs['train_acc']
train_loss_list = logs['train_loss']
val_acc_list = logs['val_acc']
val_loss_list = logs['val_loss']
epoch_list = logs['epoch_list']
for epoch in range(start_epoch, EPOCHS + 1):
epoch_list.append(epoch)
log_dir['epoch_list'] = epoch_list
train_loss, train_acc = train(model_ft, DEVICE, train_loader, optimizer, epoch, model_ema)
train_loss_list.append(train_loss)
train_acc_list.append(train_acc)
log_dir['train_acc'] = train_acc_list
log_dir['train_loss'] = train_loss_list
if use_ema:
val_list, pred_list, val_loss, val_acc = val(model_ema.ema, DEVICE, test_loader)
else:
val_list, pred_list, val_loss, val_acc = val(model_ft, DEVICE, test_loader)
val_loss_list.append(val_loss)
val_acc_list.append(val_acc)
log_dir['val_acc'] = val_acc_list
log_dir['val_loss'] = val_loss_list
log_dir['best_acc'] = Best_ACC
with open(file_dir + '/result.json', 'w', encoding='utf-8') as file:
file.write(json.dumps(log_dir))
print(classification_report(val_list, pred_list, target_names=dataset_train.class_to_idx))
if epoch < 600:
cosine_schedule.step()
else:
if not is_set_lr:
for param_group in optimizer.param_groups:
param_group["lr"] = 1e-6
is_set_lr = True
fig = plt.figure(1)
plt.plot(epoch_list, train_loss_list, 'r-', label=u'Train Loss')
# 显示图例
plt.plot(epoch_list, val_loss_list, 'b-', label=u'Val Loss')
plt.legend(["Train Loss", "Val Loss"], loc="upper right")
plt.xlabel(u'epoch')
plt.ylabel(u'loss')
plt.title('Model Loss ')
plt.savefig(file_dir + "/loss.png")
plt.close(1)
fig2 = plt.figure(2)
plt.plot(epoch_list, train_acc_list, 'r-', label=u'Train Acc')
plt.plot(epoch_list, val_acc_list, 'b-', label=u'Val Acc')
plt.legend(["Train Acc", "Val Acc"], loc="lower right")
plt.title("Model Acc")
plt.ylabel("acc")
plt.xlabel("epoch")
plt.savefig(file_dir + "/acc.png")
plt.close(2)
测试
训练完成后就可以测试,代码逻辑也是一样的,代码如下:
import torch.utils.data.distributed
import torchvision.transforms as transforms
from PIL import Image
from torch.autograd import Variable
import os
classes = ('Black-grass', 'Charlock', 'Cleavers', 'Common Chickweed',
'Common wheat', 'Fat Hen', 'Loose Silky-bent',
'Maize', 'Scentless Mayweed', 'Shepherds Purse', 'Small-flowered Cranesbill', 'Sugar beet')
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.51819474, 0.5250407, 0.4945761], std=[0.24228974, 0.24347611, 0.2530049])
])
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model=torch.load('checkpoints/hiera/best.pth')
model.eval()
model.to(DEVICE)
path = 'test/'
testList = os.listdir(path)
for file in testList:
img = Image.open(path + file)
img = transform_test(img)
img.unsqueeze_(0)
img = Variable(img).to(DEVICE)
out = model(img)
# Predict
_, pred = torch.max(out.data, 1)
print('Image Name:{},predict:{}'.format(file, classes[pred.data.item()]))
代码链接:
https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/88910248?spm=1001.2014.3001.5501

- 点赞
- 收藏
- 关注作者
评论(0)