昇腾推理适配+部署 -- PaddleOCR

实验背景
本实验以PaddleOCR的模型推理为例,介绍如何将PaddleOCR模型的推理迁移至ModelArts上,并部署成AI应用和在线服务。
任务一:环境准备
步骤1 进入ModelArts管理控制台
可以通过如下链接进入ModelArts管理控制台:https://console.huaweicloud.com/modelarts/?region=cn-southwest-2&locale=zh-cn#/dashboard。
此外,您也可以在控制台点击左上角“服务列表”,在“人工智能”服务下点击“ModelArts”进入ModelArts管理控制台。
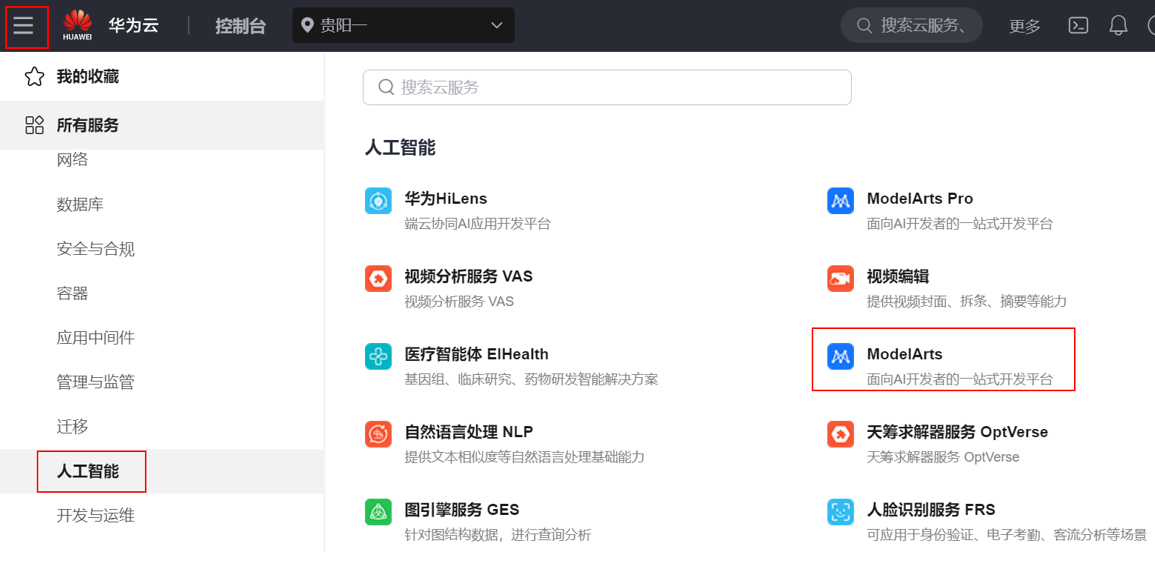
进入到ModelArts管理控制台后,请确认区域是否为“贵阳一”,如果不是,请选择“西南-贵阳一”。
步骤2 创建Notebook
在ModelArts管理控制台左侧导航栏中选择“开发空间 > Notebook”,然后进入“创建Notebook页面”。

可参考下图配置notebook参数:
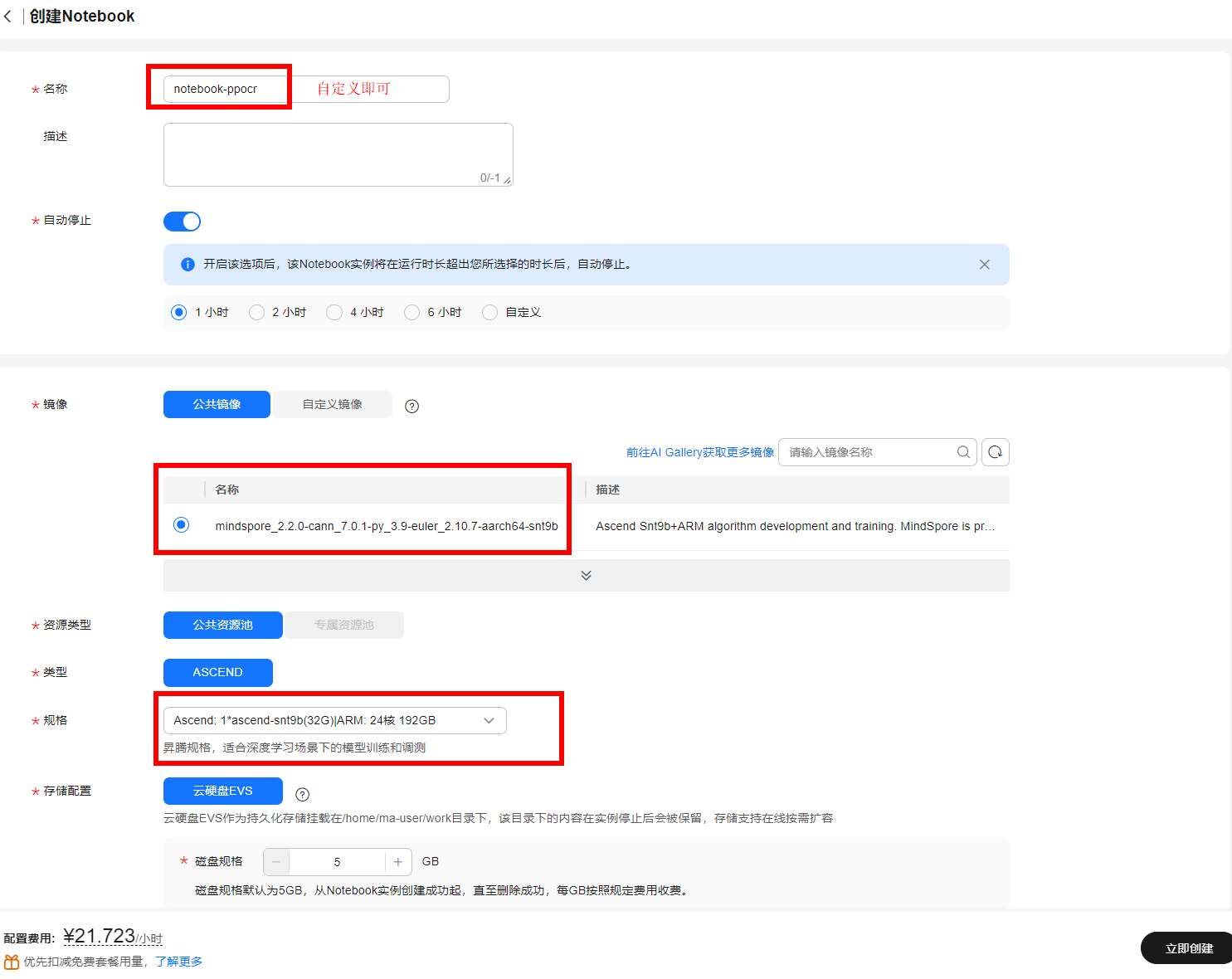
在创建notebook页面,按照如下参数进行配置(均为默认参数无需修改):
名称:notebook-ppocr
自动停止:开启,1小时
镜像:“公共镜像”,选择“mindspore_2.2.0-cann_7.0.1-py_3.9-euler_2.10.7-aarch64-snt9b”
资源类型:公共资源池
类型:ASCEND
规格:Ascend: 1*ascend-snt9b(32G)|ARM: 24核 192GB
存储配置:云硬盘EVS,5G
SSH远程开发:不开启
点击“立即创建”,确认产品规格后点击“提交”,并点击“立即返回”。

此时,notebook正在创建中,创建时长大约1分钟左右。待notebook状态变为“运行中”,点击该notebook实例右侧“打开”,即可进入到jupyterlab环境中。

步骤3 学习Notebook操作
进入Notebook页面后,在打开的notebook页面左上角点击“+”号,点击Notebook进行创建,双击下方新的的Untitled.ipynb文件,弹出代码开发界面,如下图:
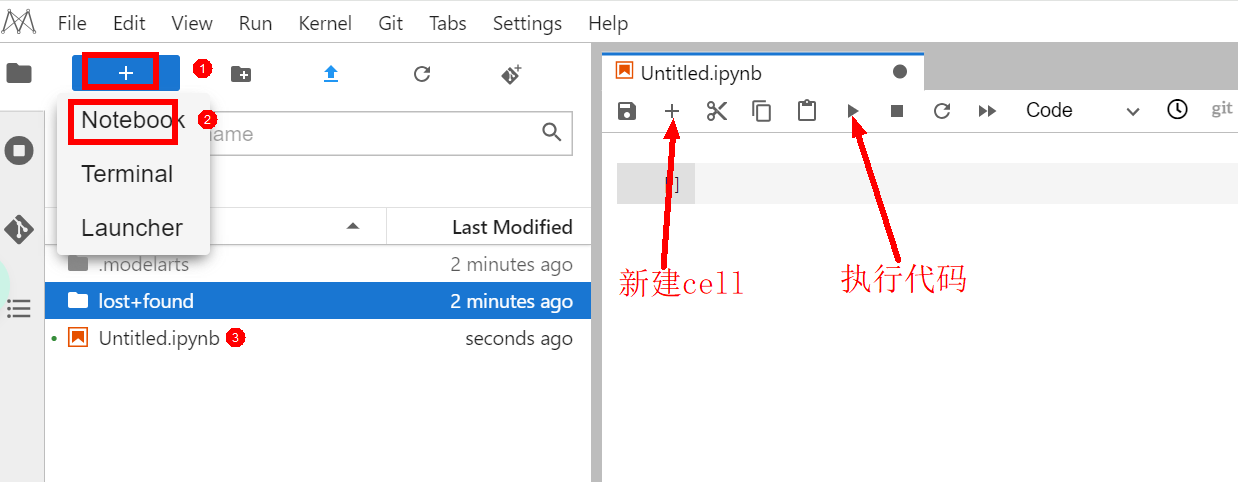
在notebook内的一些基本操作,例如新建文件夹、从本地上传文件、刷新目录、新建terminal等:

任务二:PaddleOCR推理
OCR的推理流程包括:①对输入图片中的文本框进行检测;②对检测到的文本框进行方向分类并纠正;③对纠正过方向的文本框进行文字识别。因此一个完整的OCR pipeline包含了检测模型、分类器和识别模型。本实验中的检测模型使用 ch_PP-OCRv4_server_det,识别模型使用 ch_PP-OCRv4_server_rec,不使用方向分类模型。
步骤1 下载代码并安装依赖
- 在
/home/ma-user/work目录下,新建一个notebook文件,然后可以选择方式一或方式二准备代码 - 方式一:在notebook中执行如下代码,将拉取PaddleOCR的官方代码(大约耗时2分钟)
输入:
!git clone -b main https://gitee.com/paddlepaddle/PaddleOCR.git
%cd /home/ma-user/work/PaddleOCR
# 为确保一致的代码环境,可以切换到指定的commit-id
!git reset --hard 433677182
输出:
Cloning into 'PaddleOCR'...
remote: Enumerating objects: 50663, done.
remote: Counting objects: 100% (1887/1887), done.
remote: Compressing objects: 100% (1173/1173), done.
remote: Total 50663 (delta 826), reused 1668 (delta 673), pack-reused 48776
Receiving objects: 100% (50663/50663), 382.59 MiB | 679.00 KiB/s, done.
Resolving deltas: 100% (35192/35192), done.
Updating files: 100% (2448/2448), done.
/home/ma-user/work/PaddleOCR
HEAD is now at 43367718 fix opencv import error for numpy 2.0 (#13105)
- 方式二(推荐):为避免下文对PaddleOCR的代码修改,也可以选择直接从OBS下载修改后的代码,在notebook中执行如下代码
输入:
import moxing as mox
mox.file.copy_parallel("obs://dtse-model-guiyangyi/course/paddle_ocr/PaddleOCR", "PaddleOCR")
输出:
INFO:root:Using MoXing-v2.2.3.2c7f2141-2c7f2141
INFO:root:Using OBS-Python-SDK-3.20.9.1
INFO:root:Using OBS-C-SDK-2.23.1
INFO:root:An exception occurred in function copy_parallel_c: /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages/moxing/framework/file/csrc/obs/lib/aarch64/libobs_cxx.so: cannot open shared object file: No such file or directory
INFO:root:load shared library failed, retry with copy parallel python
INFO:root:Multiprocessing connection patch for bpo-17560 not applied, not an applicable Python version: 3.9.10 | packaged by conda-forge | (main, Feb 1 2022, 21:53:27)
[GCC 9.4.0]
INFO:root:Listing OBS: 1000
INFO:root:Listing OBS: 2000
INFO:root:List OBS time cost: 4.35 seconds.
INFO:root:1000/1925
INFO:root:Copy parallel total time cost: 8.13 seconds.
- PaddleOCR代码目录说明:
- 主要使用:
tools/infer目录下的OCR推理文件,以及doc目录下测试图片imgs和 字体文件fonts
- 主要使用:
- 在notebook中执行如下命令,将安装第三方依赖
输入:
%cd /home/ma-user/work/PaddleOCR
!pip install -r requirements.txt
!pip install paddlepaddle==2.6.1 paddle2onnx==1.2.4
输出:
/home/ma-user/work/PaddleOCR
Looking in indexes: http://pip.modelarts.private.com:8888/repository/pypi/simple
Requirement already satisfied: shapely in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from -r requirements.txt (line 1)) (2.0.2)
Requirement already satisfied: scikit-image in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from -r requirements.txt (line 2)) (0.21.0)
Requirement already satisfied: imgaug in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from -r requirements.txt (line 3)) (0.4.0)
Collecting pyclipper
Downloading http://pip.modelarts.private.com:8888/repository/pypi/packages/pyclipper/1.3.0.post5/pyclipper-1.3.0.post5-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl (925 kB)
|████████████████████████████████| 925 kB 44.3 MB/s eta 0:00:01
Collecting lmdb
Downloading http://pip.modelarts.private.com:8888/repository/pypi/packages/lmdb/1.5.1/lmdb-1.5.1.tar.gz (881 kB)
|████████████████████████████████| 881 kB 61.6 MB/s eta 0:00:01
Requirement already satisfied: tqdm in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from -r requirements.txt (line 6)) (4.66.1)
Requirement already satisfied: numpy<2.0 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from -r requirements.txt (line 7)) (1.22.0)
Collecting rapidfuzz
Downloading http://pip.modelarts.private.com:8888/repository/pypi/packages/rapidfuzz/3.9.4/rapidfuzz-3.9.4-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl (1.6 MB)
|████████████████████████████████| 1.6 MB 37.8 MB/s eta 0:00:01
Requirement already satisfied: opencv-python in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from -r requirements.txt (line 9)) (4.8.0.76)
Collecting opencv-contrib-python
Downloading http://pip.modelarts.private.com:8888/repository/pypi/packages/opencv-contrib-python/4.10.0.84/opencv_contrib_python-4.10.0.84-cp37-abi3-manylinux_2_17_aarch64.manylinux2014_aarch64.whl (47.4 MB)
|████████████████████████████████| 47.4 MB 56.7 MB/s eta 0:00:01
Requirement already satisfied: cython in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from -r requirements.txt (line 11)) (3.0.2)
Requirement already satisfied: Pillow in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from -r requirements.txt (line 12)) (10.0.1)
Requirement already satisfied: pyyaml in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from -r requirements.txt (line 13)) (6.0.1)
Requirement already satisfied: requests in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from -r requirements.txt (line 14)) (2.27.1)
Requirement already satisfied: imageio in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from imgaug->-r requirements.txt (line 3)) (2.33.1)
Requirement already satisfied: matplotlib in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from imgaug->-r requirements.txt (line 3)) (3.5.1)
Requirement already satisfied: six in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from imgaug->-r requirements.txt (line 3)) (1.16.0)
Requirement already satisfied: scipy in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from imgaug->-r requirements.txt (line 3)) (1.10.1)
Requirement already satisfied: lazy_loader>=0.2 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from scikit-image->-r requirements.txt (line 2)) (0.3)
Requirement already satisfied: networkx>=2.8 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from scikit-image->-r requirements.txt (line 2)) (3.2.1)
Requirement already satisfied: PyWavelets>=1.1.1 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from scikit-image->-r requirements.txt (line 2)) (1.4.1)
Requirement already satisfied: tifffile>=2022.8.12 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from scikit-image->-r requirements.txt (line 2)) (2023.12.9)
Requirement already satisfied: packaging>=21 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from scikit-image->-r requirements.txt (line 2)) (23.2)
Requirement already satisfied: charset-normalizer~=2.0.0 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from requests->-r requirements.txt (line 14)) (2.0.12)
Requirement already satisfied: idna<4,>=2.5 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from requests->-r requirements.txt (line 14)) (2.10)
Requirement already satisfied: certifi>=2017.4.17 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from requests->-r requirements.txt (line 14)) (2023.11.17)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from requests->-r requirements.txt (line 14)) (1.26.7)
Requirement already satisfied: python-dateutil>=2.7 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from matplotlib->imgaug->-r requirements.txt (line 3)) (2.8.2)
Requirement already satisfied: kiwisolver>=1.0.1 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from matplotlib->imgaug->-r requirements.txt (line 3)) (1.4.5)
Requirement already satisfied: cycler>=0.10 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from matplotlib->imgaug->-r requirements.txt (line 3)) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from matplotlib->imgaug->-r requirements.txt (line 3)) (4.47.0)
Requirement already satisfied: pyparsing>=2.2.1 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from matplotlib->imgaug->-r requirements.txt (line 3)) (3.1.1)
Building wheels for collected packages: lmdb
Building wheel for lmdb (setup.py) ... done
Created wheel for lmdb: filename=lmdb-1.5.1-cp39-cp39-linux_aarch64.whl size=119128 sha256=a8131b59f335ee2e8f1d72f88bdf002c82746032dfa458bad76fd8b654760ca9
Stored in directory: /home/ma-user/.cache/pip/wheels/44/25/6a/3b016d67df9564aeec95808128a3230cf8fd8c88f0e94d77f3
Successfully built lmdb
Installing collected packages: rapidfuzz, pyclipper, opencv-contrib-python, lmdb
Successfully installed lmdb-1.5.1 opencv-contrib-python-4.10.0.84 pyclipper-1.3.0.post5 rapidfuzz-3.9.4
WARNING: You are using pip version 21.0.1; however, version 24.1.2 is available.
You should consider upgrading via the '/home/ma-user/anaconda3/envs/MindSpore/bin/python3.9 -m pip install --upgrade pip' command.
Looking in indexes: http://pip.modelarts.private.com:8888/repository/pypi/simple
Collecting paddlepaddle==2.6.1
Downloading http://pip.modelarts.private.com:8888/repository/pypi/packages/paddlepaddle/2.6.1/paddlepaddle-2.6.1-cp39-cp39-manylinux2014_aarch64.whl (74.2 MB)
|████████████████████████████████| 74.2 MB 43.3 MB/s eta 0:00:01 |█▊ | 4.0 MB 43.3 MB/s eta 0:00:02 |████████ | 18.7 MB 43.3 MB/s eta 0:00:02
Collecting paddle2onnx==1.2.4
Downloading http://pip.modelarts.private.com:8888/repository/pypi/packages/paddle2onnx/1.2.4/paddle2onnx-1.2.4-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl (3.6 MB)
|████████████████████████████████| 3.6 MB 34.7 MB/s eta 0:00:01
Requirement already satisfied: onnxruntime>=1.10.0 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from paddle2onnx==1.2.4) (1.15.1)
Collecting opt-einsum==3.3.0
Downloading http://pip.modelarts.private.com:8888/repository/pypi/packages/opt-einsum/3.3.0/opt_einsum-3.3.0-py3-none-any.whl (65 kB)
|████████████████████████████████| 65 kB 44.2 MB/s eta 0:00:01
Requirement already satisfied: decorator in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from paddlepaddle==2.6.1) (4.4.1)
Requirement already satisfied: numpy>=1.13 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from paddlepaddle==2.6.1) (1.22.0)
Collecting astor
Downloading http://pip.modelarts.private.com:8888/repository/pypi/packages/astor/0.8.1/astor-0.8.1-py2.py3-none-any.whl (27 kB)
Requirement already satisfied: Pillow in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from paddlepaddle==2.6.1) (10.0.1)
Requirement already satisfied: httpx in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from paddlepaddle==2.6.1) (0.26.0)
Requirement already satisfied: protobuf>=3.20.2 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from paddlepaddle==2.6.1) (3.20.2)
Requirement already satisfied: flatbuffers in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from onnxruntime>=1.10.0->paddle2onnx==1.2.4) (23.5.26)
Requirement already satisfied: coloredlogs in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from onnxruntime>=1.10.0->paddle2onnx==1.2.4) (15.0.1)
Requirement already satisfied: packaging in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from onnxruntime>=1.10.0->paddle2onnx==1.2.4) (23.2)
Requirement already satisfied: sympy in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from onnxruntime>=1.10.0->paddle2onnx==1.2.4) (1.4)
Requirement already satisfied: humanfriendly>=9.1 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from coloredlogs->onnxruntime>=1.10.0->paddle2onnx==1.2.4) (10.0)
Requirement already satisfied: sniffio in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from httpx->paddlepaddle==2.6.1) (1.3.0)
Requirement already satisfied: idna in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from httpx->paddlepaddle==2.6.1) (2.10)
Requirement already satisfied: httpcore==1.* in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from httpx->paddlepaddle==2.6.1) (1.0.2)
Requirement already satisfied: certifi in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from httpx->paddlepaddle==2.6.1) (2023.11.17)
Requirement already satisfied: anyio in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from httpx->paddlepaddle==2.6.1) (4.2.0)
Requirement already satisfied: h11<0.15,>=0.13 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from httpcore==1.*->httpx->paddlepaddle==2.6.1) (0.14.0)
Requirement already satisfied: typing-extensions>=4.1 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from anyio->httpx->paddlepaddle==2.6.1) (4.9.0)
Requirement already satisfied: exceptiongroup>=1.0.2 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from anyio->httpx->paddlepaddle==2.6.1) (1.2.0)
Requirement already satisfied: mpmath>=0.19 in /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages (from sympy->onnxruntime>=1.10.0->paddle2onnx==1.2.4) (1.3.0)
Installing collected packages: opt-einsum, astor, paddlepaddle, paddle2onnx
Successfully installed astor-0.8.1 opt-einsum-3.3.0 paddle2onnx-1.2.4 paddlepaddle-2.6.1
WARNING: You are using pip version 21.0.1; however, version 24.1.2 is available.
You should consider upgrading via the '/home/ma-user/anaconda3/envs/MindSpore/bin/python3.9 -m pip install --upgrade pip' command.
步骤2 准备推理模型
本步骤将下载原始的 *.pdmodel模型文件,首先将其转换为 onnx推理格式,然后再转换为昇腾云自己的 mindir推理格式 。
下载paddle模型
- 在notebook中新建一个cell,然后执行如下命令,将下载
*.pdmodel模型至~/work/inference目录下
输入:
!mkdir /home/ma-user/work/inference
%cd /home/ma-user/work/inference
!echo "Stage1 -- Downloading Inference Models ..."
!wget -nc https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_det_server_infer.tar
!tar -xf ch_PP-OCRv4_det_server_infer.tar
!wget -nc https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_rec_server_infer.tar
!tar -xf ch_PP-OCRv4_rec_server_infer.tar
输出:
/home/ma-user/work/inference
Stage1 -- Downloading Inference Models ...
--2024-07-29 17:40:26-- https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_det_server_infer.tar
Resolving proxy-notebook.modelarts.com (proxy-notebook.modelarts.com)... 192.168.0.33
Connecting to proxy-notebook.modelarts.com (proxy-notebook.modelarts.com)|192.168.0.33|:8083... connected.
Proxy request sent, awaiting response... 200 OK
Length: 113479680 (108M) [application/x-tar]
Saving to: ‘ch_PP-OCRv4_det_server_infer.tar’
ch_PP-OCRv4_det_ser 100%[===================>] 108.22M 9.41MB/s in 11s
2024-07-29 17:40:38 (9.66 MB/s) - ‘ch_PP-OCRv4_det_server_infer.tar’ saved [113479680/113479680]
--2024-07-29 17:40:39-- https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_rec_server_infer.tar
Resolving proxy-notebook.modelarts.com (proxy-notebook.modelarts.com)... 192.168.0.33
Connecting to proxy-notebook.modelarts.com (proxy-notebook.modelarts.com)|192.168.0.33|:8083... connected.
Proxy request sent, awaiting response... 200 OK
Length: 92385280 (88M) [application/x-tar]
Saving to: ‘ch_PP-OCRv4_rec_server_infer.tar’
ch_PP-OCRv4_rec_ser 100%[===================>] 88.11M 9.00MB/s in 11s
2024-07-29 17:40:50 (8.18 MB/s) - ‘ch_PP-OCRv4_rec_server_infer.tar’ saved [92385280/92385280]
paddle2onnx
参考:PaddleOCR/deploy/paddle2onnx/readme.md
- 在notebook中执行如下命令,将检测和识别的模型均转换为onnx模型,并保存在
~/work/inference目录下
输入:
%cd /home/ma-user/work
!echo "Stage2 -- Convert Models to ONNX by \`paddle2onnx\`"
!paddle2onnx --model_dir inference/ch_PP-OCRv4_det_server_infer \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--save_file inference/det/model.onnx \
--opset_version 11 \
--enable_onnx_checker True
!paddle2onnx --model_dir inference/ch_PP-OCRv4_rec_server_infer \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--save_file inference/rec/model.onnx \
--opset_version 11 \
--enable_onnx_checker True
输出:
/home/ma-user/work
Stage2 -- Convert Models to ONNX by `paddle2onnx`
[Paddle2ONNX] Start to parse PaddlePaddle model...
[Paddle2ONNX] Model file path: inference/ch_PP-OCRv4_det_server_infer/inference.pdmodel
[Paddle2ONNX] Parameters file path: inference/ch_PP-OCRv4_det_server_infer/inference.pdiparams
[Paddle2ONNX] Start to parsing Paddle model...
[Paddle2ONNX] Use opset_version = 11 for ONNX export.
[Paddle2ONNX] PaddlePaddle model is exported as ONNX format now.
[Paddle2ONNX] Start to parse PaddlePaddle model...
[Paddle2ONNX] Model file path: inference/ch_PP-OCRv4_rec_server_infer/inference.pdmodel
[Paddle2ONNX] Parameters file path: inference/ch_PP-OCRv4_rec_server_infer/inference.pdiparams
[Paddle2ONNX] Start to parsing Paddle model...
[Paddle2ONNX] Use opset_version = 11 for ONNX export.
[Paddle2ONNX] PaddlePaddle model is exported as ONNX format now.
-
注意:这里
paddle2onnx命令转换的模型,默认输入为动态shape- 例如,检测模型输入为
x:[-1,3,-1,-1],识别模型输入为x:[-1,3,48,-1],表示输入名称为x且同时支持动态batch和动态分辨率 - 如何重新指定模型的动态shape:①可以通过
paddle2onnx.optimize的--input_shape_dict指定,②也可以在onnx2mindir阶段,使用配置文件中input_shape_range参数指定,见示例
- 例如,检测模型输入为
-
示例①:
paddle2onnx指定模型的动态shape(仅供参考无需运行)
python3 -m paddle2onnx.optimize \
--input_model inference/det/model.onnx \
--output_model inference/det/model_demo.onnx \
--input_shape_dict "{'x': [1,3,640,-1]}"
onnx2mindir
本节主要使用 converter_lite工具将onnx推理模型转换为 mindir格式,它可以针对NPU或GPU做专门的优化从而提升推理性能。
参考官网文档:https://www.mindspore.cn/lite/docs/zh-CN/r2.3.0rc2/use/cloud_infer/converter_tool.html
- 在notebook中执行如下命令,将使用
converter_lite工具将检测和识别模型分别转换为mindir格式(大约耗时10分钟)
输入:
%cd /home/ma-user/work
!echo "Stage3 -- Convert Models to MINDIR by \`converter_lite\`"
!converter_lite --fmk=ONNX \
--saveType=MINDIR \
--optimize=ascend_oriented \
--modelFile=inference/det/model.onnx \
--outputFile=inference/det/model
!converter_lite --fmk=ONNX \
--saveType=MINDIR \
--optimize=ascend_oriented \
--modelFile=inference/rec/model.onnx \
--outputFile=inference/rec/model
输出:
/home/ma-user/work
Stage3 -- Convert Models to MINDIR by `converter_lite`
[WARNING] LITE(23190,ffffab316010,converter_lite):2024-07-29-17:42:48.077.738 [mindspore/lite/build/tools/converter/parser/onnx/onnx_op_parser.cc:1409] GetConvChannel] not find node: conv2d_0.w_0
[WARNING] LITE(23190,ffffab316010,converter_lite):2024-07-29-17:42:48.077.927 [mindspore/lite/build/tools/converter/parser/onnx/onnx_op_parser.cc:1409] GetConvChannel] not find node: conv2d_1.w_0
...
[WARNING] LITE(23190,ffffab316010,converter_lite):2024-07-29-17:42:48.087.483 [mindspore/lite/build/tools/converter/parser/onnx/onnx_op_parser.cc:1409] GetConvChannel] not find node: conv2d_105.w_0
[WARNING] LITE(23190,ffffab316010,converter_lite):2024-07-29-17:42:48.087.589 [mindspore/lite/build/tools/converter/parser/onnx/onnx_op_parser.cc:1660] Parse] parsing of channelIn/Out is delayed.
[WARNING] LITE(23190,ffffab316010,converter_lite):2024-07-29-17:42:48.087.698 [mindspore/lite/build/tools/converter/parser/onnx/onnx_op_parser.cc:1660] Parse] parsing of channelIn/Out is delayed.
[WARNING] LITE(23190,ffffab316010,converter_lite):2024-07-29-17:42:48.087.821 [mindspore/lite/build/tools/converter/parser/onnx/onnx_op_parser.cc:1409] GetConvChannel] not find node: conv2d_107.w_0
[WARNING] LITE(23190,ffffab316010,converter_lite):2024-07-29-17:42:48.087.918 [mindspore/lite/build/tools/converter/parser/onnx/onnx_op_parser.cc:1409] GetConvChannel] not find node: conv2d_108.w_0
[WARNING] LITE(23190,ffffab316010,converter_lite):2024-07-29-17:42:49.243.821 [mindspore/lite/tools/converter/adapter/acl/mapper/primitive_mapper.cc:66] AttrAdjust] GlobalAveragePool has no attr kernel_size
...
/usr/local/Ascend/ascend-toolkit/latest/python/site-packages/tbe/dsl/unify_schedule/extract_image_patches_without_cbuf_schedule.py:317: SyntaxWarning: "is not" with a literal. Did you mean "!="?
if _ is not 1:
...
/usr/local/Ascend/ascend-toolkit/latest/python/site-packages/tbe/dsl/unify_schedule/extract_image_patches_without_cbuf_schedule.py:317: SyntaxWarning: "is not" with a literal. Did you mean "!="?
if _ is not 1:
CONVERT RESULT SUCCESS:0
[WARNING] LITE(35984,ffff81bca010,converter_lite):2024-07-29-17:45:47.372.823 [mindspore/lite/build/tools/converter/parser/onnx/onnx_op_parser.cc:1409] GetConvChannel] not find node: conv2d_0.w_0
[WARNING] LITE(35984,ffff81bca010,converter_lite):2024-07-29-17:45:47.373.004 [mindspore/lite/build/tools/converter/parser/onnx/onnx_op_parser.cc:1409] GetConvChannel] not find node: conv2d_1.w_0
...
[WARNING] LITE(35984,ffff81bca010,converter_lite):2024-07-29-17:45:48.347.334 [mindspore/lite/tools/converter/adapter/acl/mapper/primitive_mapper.cc:66] AttrAdjust] GlobalAveragePool has no attr kernel_size
[WARNING] LITE(35984,ffff81bca010,converter_lite):2024-07-29-17:45:48.348.056 [mindspore/lite/tools/converter/adapter/acl/mapper/primitive_mapper.cc:66] AttrAdjust] GlobalAveragePool has no attr kernel_size
...
/usr/local/Ascend/ascend-toolkit/latest/python/site-packages/tbe/dsl/unify_schedule/extract_image_patches_without_cbuf_schedule.py:317: SyntaxWarning: "is not" with a literal. Did you mean "!="?
if _ is not 1:
...
/usr/local/Ascend/ascend-toolkit/latest/python/site-packages/tbe/dsl/unify_schedule/extract_image_patches_without_cbuf_schedule.py:317: SyntaxWarning: "is not" with a literal. Did you mean "!="?
if _ is not 1:
Warning: set_tiling_params does not take effect because get_op_mode is dynamic
Warning: set_tiling_params does not take effect because get_op_mode is dynamic
Warning: set_tiling_params does not take effect because get_op_mode is dynamic
Warning: set_tiling_params does not take effect because get_op_mode is dynamic
CONVERT RESULT SUCCESS:0
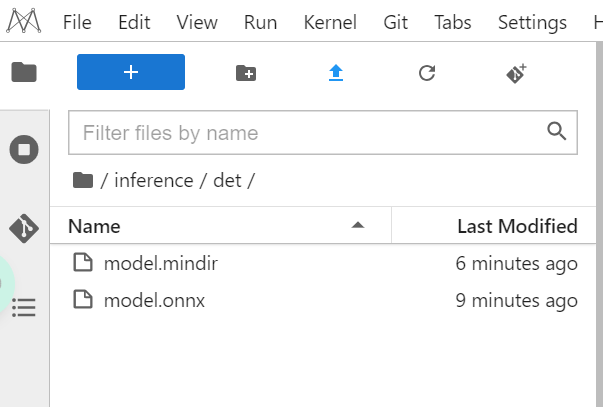
- 出现
CONVERT RESULT SUCCESS:0,表示转换成功。转换之后的模型如下:
- 示例②:
onnx2mindir指定模型的动态shape(仅供参考无需运行)
CONFIG_FILE=config_demo.conf
echo "[acl_build_options]" > $CONFIG_FILE
echo "input_format=NCHW" >> $CONFIG_FILE
echo "input_shape_range=x:[1,3,640,-1]" >> $CONFIG_FILE
converter_lite --fmk=ONNX --saveType=MINDIR \
--optimize=ascend_oriented \
--modelFile=inference/det/model.onnx \
--outputFile=inference/det/model_demo \
--configFile=$CONFIG_FILE
步骤3 适配推理代码
PaddleOCR原始代码不支持使用 mindir模型格式进行推理,本实验的推理适配复用了PaddleOCR的前处理和后处理逻辑,主要涉及 PaddleOCR/tools/infer目录下4个代码文件的修改:
注意:如果步骤1选择直接从OBS下载适配好的PaddleOCR代码,则跳过此步骤即可。
utility.py
- 在
init_args函数,新增--use_mindir,用于指示开启mindir推理

parser.add_argument("--use_mindir", type=str2bool, default=False)
- 在
create_perdictor函数中,大约214行的位置,新增mindir模型的初始化逻辑,这部分代码检测/识别/分类共用
if args.use_onnx:
...
elif args.use_mindir: # for ascend inference
import mindspore_lite as mslite
model_file_path = model_dir
if not os.path.exists(model_file_path):
raise ValueError("not find model file path {}".format(model_file_path))
# init context, and set target is ascend.
context = mslite.Context()
context.target = ["ascend"] # cpu/gpu/ascend
context.ascend.device_id = args.gpu_id # default to 0
# context.ascend.provider = "ge"
model = mslite.Model()
model.build_from_file(model_file_path, mslite.ModelType.MINDIR, context)
return model, model.get_inputs(), None, None
else:
...
predict_det.py
- 在
__init__函数中,保存args.use_mindir的值,即:
self.use_mindir = args.use_mindir
- 在
TextDetector -- predict函数中,大约254行的位置,新增使用mindir模型推理的逻辑
if self.use_onnx:
...
elif self.use_mindir: # for ascend inference
self.predictor.resize(self.input_tensor, [img.shape]) # dynamic shape
inputs = self.predictor.get_inputs()
inputs[0].set_data_from_numpy(img)
# execute inference
outputs = self.predictor.predict(inputs)
outputs = [o.get_data_to_numpy() for o in outputs]
else:
self.input_tensor.copy_from_cpu(img)
...
predict_rec.py
- 在
__init__函数中,保存args.use_mindir的值 - 在
TextRecognizer -- __call__函数中,大约676行的位置,新增使用mindir模型推理的逻辑
if self.use_onnx:
...
elif self.use_mindir: # for ascend inference
self.predictor.resize(self.input_tensor, [norm_img_batch.shape])
inputs = self.predictor.get_inputs()
inputs[0].set_data_from_numpy(norm_img_batch)
outputs = self.predictor.predict(inputs)
outputs = [o.get_data_to_numpy() for o in outputs]
preds = outputs[0]
else:
self.input_tensor.copy_from_cpu(norm_img_batch)
...
predict_cls.py
- 在
__init__函数中,保存args.use_mindir的值 - 在
TextClassifier -- __call__函数中,大约112行的位置,新增使用mindir模型推理的逻辑
if self.use_onnx:
...
elif self.use_mindir: # for ascend inference
self.predictor.resize(self.input_tensor, [norm_img_batch.shape])
inputs = self.predictor.get_inputs()
inputs[0].set_data_from_numpy(norm_img_batch)
outputs = self.predictor.predict(inputs)
outputs = [o.get_data_to_numpy() for o in outputs]
prob_out = outputs[0]
else:
self.input_tensor.copy_from_cpu(norm_img_batch)
...
步骤4 测试推理pipeline
- 在notebook中执行如下命令,将对
PaddleOCR/doc/imags/11.jpg图片执行检测和识别,并将结果保存在inference_results中
注意:--image_dir支持输入目录,对目录下的所有图片做OCR推理
输入:
%cd /home/ma-user/work
!python PaddleOCR/tools/infer/predict_system.py \
--use_mindir True --gpu_id 0 \
--image_dir PaddleOCR/doc/imgs/11.jpg \
--det_model_dir inference/det/model.mindir \
--rec_model_dir inference/rec/model.mindir \
--rec_char_dict_path PaddleOCR/ppocr/utils/ppocr_keys_v1.txt \
--use_angle_cls False \
--vis_font_path PaddleOCR/doc/fonts/simfang.ttf
输出:
/home/ma-user/work
[2024-07-29 17:52:18,673] [ WARNING] model.py:109 - mslite ascendc custom kernel path not found
[2024-07-29 17:52:25,511] [ WARNING] model.py:109 - mslite ascendc custom kernel path not found
[2024/07/29 17:52:29] ppocr INFO: In PP-OCRv3, rec_image_shape parameter defaults to '3, 48, 320', if you are using recognition model with PP-OCRv2 or an older version, please set --rec_image_shape='3,32,320
[WARNING] ME(51741,ffff9f6470b0,python):2024-07-29-17:52:29.030.425 [mindspore/lite/src/extendrt/kernel/ascend/src/custom_ascend_kernel.cc:168] Resize] Invalid inputs or output shapes.
[2024/07/29 17:52:29] ppocr DEBUG: dt_boxes num : 16, elapsed : 0.06305480003356934
[WARNING] ME(51741,ffff9f6470b0,python):2024-07-29-17:52:29.082.780 [mindspore/lite/src/extendrt/kernel/ascend/src/custom_ascend_kernel.cc:168] Resize] Invalid inputs or output shapes.
[2024/07/29 17:52:29] ppocr DEBUG: rec_res num : 16, elapsed : 0.23969674110412598
[2024/07/29 17:52:29] ppocr DEBUG: 0 Predict time of PaddleOCR/doc/imgs/11.jpg: 0.310s
[2024/07/29 17:52:29] ppocr DEBUG: 纯臻营养护发素, 0.995
[2024/07/29 17:52:29] ppocr DEBUG: 产品信息/参数, 0.993
[2024/07/29 17:52:29] ppocr DEBUG: (45元/每公斤,100公斤起订), 0.964
[2024/07/29 17:52:29] ppocr DEBUG: 每瓶22元,1000瓶起订), 0.996
[2024/07/29 17:52:29] ppocr DEBUG: 【品牌】:代加工方式/OEMODM, 0.985
[2024/07/29 17:52:29] ppocr DEBUG: 【品名】:纯臻营养护发素, 0.998
[2024/07/29 17:52:29] ppocr DEBUG: 【产品编号】:YM-X-3011, 0.989
[2024/07/29 17:52:29] ppocr DEBUG: ODMOEM, 0.995
[2024/07/29 17:52:29] ppocr DEBUG: 【净含量】:220ml, 0.991
[2024/07/29 17:52:29] ppocr DEBUG: 【适用人群】:适合所有肤质, 0.989
[2024/07/29 17:52:29] ppocr DEBUG: 【主要成分】:鲸蜡硬脂醇、燕麦β-葡聚, 0.977
[2024/07/29 17:52:29] ppocr DEBUG: 糖、椰油酰胺丙基甜菜碱、泛醒, 0.983
[2024/07/29 17:52:29] ppocr DEBUG: (成品包材), 0.998
[2024/07/29 17:52:29] ppocr DEBUG: 【主要功能】:可紧致头发磷层,从而达到, 0.996
[2024/07/29 17:52:29] ppocr DEBUG: 即时持久改善头发光泽的效果,给干燥的头, 0.989
[2024/07/29 17:52:29] ppocr DEBUG: 发足够的滋养, 0.998
[2024/07/29 17:52:29] ppocr DEBUG: The visualized image saved in ./inference_results/11.jpg
[2024/07/29 17:52:29] ppocr INFO: The predict total time is 0.41288328170776367
识别效果如下图:

任务三:推理性能调优–固定/多档
任务二中的OCR推理模型默认为动态shape,此时的识别效果最优,但与此同时推理速度最慢。为了进一步提升OCR的推理性能,本任务中我们将探讨动态shape、固定shape和多档shape三种情况下,推理性能和识别效果的差异。
步骤0 背景知识及实验设置
实验背景
动态shape:OCR管线的输入图片可以是各种大小,推理模型为了支持任意大小的输入,在推理前需要根据输入shape进行resize,然而这势必会增加推理延时。
固定shape:是指在前处理阶段就把输入图片缩放到指定大小,尽管这样可以获得固定shape优化后的速度提升,但缩放会导致文本等信息畸变从而降低OCR的识别效果。如何平衡OCR管线的性能和延时呢?
多档shape:MindIR推理格式支持最多100档的输入shape,并同时保持了固定shape的推理速度。如果我们可以按照一定策略,能够在尽可能减少文本畸变的前提下,将输入图片的大小限定在100种之内,那么我们就可以较好地平衡OCR管线的性能和延时。
如官网文档所述:在某些推理场景,如检测出目标后再执行目标识别网络,由于目标个数不固定导致目标识别网络输入BatchSize不固定。如果每次推理都按照最大的BatchSize或最大分辨率进行计算,会造成计算资源浪费。因此,推理需要支持动态BatchSize和动态分辨率的场景,MindSpore-Lite在Ascend上推理支持动态BatchSize和动态分辨率场景,在convert阶段通过congFile配置[ascend_context]中dynamic_dims动态参数,推理时使用model的Resize功能,改变输入shape。
注意:这里所提及的【动态BatchSize和动态分辨率】,也可以理解为【多档shape】。
参考官方文档:https://www.mindspore.cn/lite/docs/zh-CN/r2.0/use/cloud_infer/converter_tool_ascend.html
实验设置
为衡量并对比上述三种模型的性能和延时,我们从ICDAR 2017 RCTW数据集中选择四条样本来评估。对于检测模型来说,我们用预测的文本框四元组和真实标签四元组,计算 P/R指标和 Hmean指标来评估。对于识别模型来说,我们将真实标签四元组获得的文本框图片送入识别模型,并利用预测的文本和真实标注文本,计算 ACC和 编辑距离等指标来评估。
表1 不同模型的输入shape一览
| batch-size | channel | height | width | |
|---|---|---|---|---|
| dynamic-det | -1 | 3 | -1 | -1 |
| dynamic-rec | -1 | 3 | 48 | -1 |
| frozen-det | 1 | 3 | 640 | 640 |
| frozen-rec | 6 | 3 | 48 | 320 |
| multi-gear-det | 1 | 3 | 640 | -1 |
| multi-gear-rec | 6 | 3 | 48 | -1 |
任务二转换的模型默认支持动态shape,此处不再赘述。对于固定shape的模型,我们将输入缩放到指定 HW做推理,并对识别模型的输入进行 batch-size的填充,以此增加推理速度。对于多档shape的模型,我们认定输入图片的宽高比是在一定范围内,例如检测模型的输入范围为 [0.5, 2],识别模型的输入范围为 [0.5, 20]。除此之外,我们先对输入图片的 H做约束,然后根据真实高宽比并按照 32的步长间隔,来计算输入图片的 W。
由此,我们可以获得三种shape策略下的模型,并能够得到检测/识别模型在小数据集上的效果以及耗时情况。
步骤1 下载数据集
- 在notebook中执行如下命令,将下载用于评估识别准确率的数据集,并将图片和标注文件分别放在
data/rctw_images和data/rctw_gts目录下:
输入:
%cd /home/ma-user/work
import moxing as mox
mox.file.copy_parallel("obs://dtse-model-guiyangyi/course/paddle_ocr/data", "data")
输出:
INFO:root:An exception occurred in function copy_parallel_c: /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages/moxing/framework/file/csrc/obs/lib/aarch64/libobs_cxx.so: cannot open shared object file: No such file or directory
INFO:root:load shared library failed, retry with copy parallel python
INFO:root:Multiprocessing connection patch for bpo-17560 not applied, not an applicable Python version: 3.9.10 | packaged by conda-forge | (main, Feb 1 2022, 21:53:27)
[GCC 9.4.0]
INFO:root:List OBS time cost: 0.37 seconds.
INFO:root:Copy parallel total time cost: 0.59 seconds.
- 我们选择从ICDAR 2017 RCTW的训练集中挑选4个样本用于简单评估性能,样例如下:

步骤2 准备评估代码
为了评估OCR推理的识别性能,这里我们利用RCTW2017的数据集,分别评估检测模型和识别模型的性能。其中,检测模型使用 hmean指标评估,而识别模型则使用 acc和编辑距离指标评估。需要注意的是,识别模型使用了标注的 boxes去推理,而非检测模型输出的 boxes。
除新建评估代码 evaluate.py文件外,还需要额外修改 PaddleOCR/tools/infer目录下的推理文件,来支持固定shape和分档shape的推理,修改细节如下:
注意:如果“任务二步骤1”选择直接从OBS下载适配好的PaddleOCR代码,则只需要新建 evaluate.py文件,其他代码修改可跳过。
evaluate.py
在 /home/ma-user/work目录下,新建 evaluate.py文件,并输入如下内容:
import argparse
import copy
import glob
import json
import os
from typing import Dict, List, Tuple
import cv2
import numpy as np
from numpy import ndarray
os.sys.path.append(os.path.join(os.path.dirname(__file__), "PaddleOCR"))
from tools.infer.predict_det import TextDetector
from tools.infer.predict_rec import TextRecognizer
from tools.infer.predict_system import sorted_boxes
from tools.infer.utility import get_minarea_rect_crop, get_rotate_crop_image
from tools.infer.utility import init_args as ppocr_init_args
from ppocr.metrics.det_metric import DetMetric
from ppocr.metrics.rec_metric import RecMetric
class OCRTestDataset(object):
def __init__(self, image_dir: str, annotation_dir: str) -> None:
super(OCRTestDataset, self).__init__()
self.image_dir = image_dir
self.annotation_dir = annotation_dir
self.data_list = glob.glob(os.path.join(image_dir, "*.jpg"))
self.data_list.sort()
self.label_list = []
for image_file in self.data_list:
f = os.path.basename(image_file)
f = f.removesuffix(".jpg") + ".txt"
self.label_list.append(os.path.join(annotation_dir, f))
@classmethod
def annotation2boxes(self, annotation: List[str]) -> ndarray:
assert len(annotation) == 8, "[annotation] error boxes"
try:
flatten_boxes = list(map(float, annotation))
except ValueError:
print(annotation)
exit(1)
boxes = np.array(flatten_boxes).astype(np.float32).reshape(4, 2)
return boxes
def __getitem__(self, index: int) -> Tuple[str, Dict[str, List]]:
image_file = self.data_list[index]
annotation = {"gt_boxes": [], "gt_texts": [], "ignore_tags": []}
with open(self.label_list[index], "r", encoding="utf8") as fout:
lines = fout.readlines()
for line in lines:
elements = line.strip().split(",")
boxes = self.annotation2boxes(elements[:8])
diffculty = int(elements[8])
text = elements[-1].replace("\"", "")
ignore = "###" in text
annotation["gt_boxes"].append(boxes)
annotation["gt_texts"].append([text, None]) # text, score
annotation["ignore_tags"].append(ignore)
return image_file, annotation
def __len__(self) -> int:
return len(self.data_list)
class InferTextSystem:
def __init__(self, det_model: str, rec_model: str, infer_type: str, **kwargs) -> None:
args, unknown = ppocr_init_args().parse_known_args()
args.use_mindir = True
if infer_type in ["frozen_shape", "multi_gear"]:
args.mindir_frozen_shape = (infer_type == "frozen_shape")
args.mindir_multi_gear = not args.mindir_frozen_shape
if args.mindir_multi_gear:
args.rec_image_shape="3,48,-1" # use the actual `max_wh_ratio`
args.det_model_dir = det_model
args.rec_model_dir = rec_model
paddle_ocr_project_path = os.path.join(os.path.dirname(__file__), 'PaddleOCR')
args.rec_char_dict_path = os.path.join(paddle_ocr_project_path, 'ppocr/utils/ppocr_keys_v1.txt')
args.vis_font_path = os.path.join(paddle_ocr_project_path, 'doc/fonts/simfang.ttf')
self.paddle_ocr_project_path = paddle_ocr_project_path
self.text_detector = TextDetector(args)
self.text_recognizer = TextRecognizer(args)
self.det_box_type = args.det_box_type
self.drop_score = args.drop_score
def detect(self, image: ndarray) -> ndarray:
dt_boxes, elapse = self.text_detector(image)
dt_boxes = sorted_boxes(dt_boxes)
return dt_boxes, elapse
def recognize(self, image: ndarray, dt_boxes: ndarray) -> List[str]:
img_crop_list = []
for bno in range(len(dt_boxes)):
tmp_box = copy.deepcopy(dt_boxes[bno])
if self.det_box_type == "quad":
img_crop = get_rotate_crop_image(image, tmp_box)
else:
img_crop = get_minarea_rect_crop(image, tmp_box)
img_crop_list.append(img_crop)
rec_res, elapse = self.text_recognizer(img_crop_list)
return rec_res, elapse
def __call__(self, image_file: str):
image = cv2.imread(image_file)
dt_boxes, dt_elapse = self.detect(image)
rec_res, rec_elapse = self.recognize(image, dt_boxes)
print(dt_elapse, rec_elapse)
filter_boxes, filter_rec_res = [], []
for box, rec_result in zip(dt_boxes, rec_res):
text, score = rec_result[0], rec_result[1]
if score >= self.drop_score:
filter_boxes.append(box)
filter_rec_res.append(rec_result)
return filter_boxes, filter_rec_res
class Evaluator:
def __init__(self):
self.det_metric = DetMetric()
self.rec_metric = RecMetric()
def evaluate(self, dt_boxes: List[ndarray],
gt_boxes: List[ndarray],
ignore_tags: List[bool],
rec_texts: List[str],
gt_texts: List[str], **kwargs
) -> Dict[str, float]:
metrics = {}
# box_num = len(ignore_tags)
# gt_boxes = [gt_boxes[i] for i in range(box_num) if not ignore_tags[i]]
points = np.stack(dt_boxes) if dt_boxes else np.zeros((0, 4, 2), dtype=np.float32)
self.det_metric(preds=[{"points": points}],
batch=[None, None,
np.expand_dims(np.stack(gt_boxes), axis=0),
np.expand_dims(np.stack(ignore_tags), axis=0)]
)
det_metric_results_backup = self.det_metric.results
self.det_metric.results = [det_metric_results_backup[-1]]
out = self.det_metric.get_metric()
self.det_metric.results = det_metric_results_backup
metrics.update(out)
box_num = len(ignore_tags)
pred_texts = [rec_texts[i] for i in range(box_num) if not ignore_tags[i]]
label_texts = [gt_texts[i] for i in range(box_num) if not ignore_tags[i]]
metrics.update(
self.rec_metric([pred_texts, label_texts])
)
return metrics
def get(self) -> Dict[str, float]:
metrics = {}
metrics.update(self.det_metric.get_metric())
metrics.update(self.rec_metric.get_metric())
return metrics
def init_args():
parser = argparse.ArgumentParser()
parser.add_argument("--dset_image_dir", type=str, default="data/rctw_images")
parser.add_argument("--dset_annotation_dir", type=str, default="data/rctw_gts")
parser.add_argument("--det_model", type=str, default="inference/det/model.mindir")
parser.add_argument("--rec_model", type=str, default="inference/rec/model.mindir")
parser.add_argument("--infer_type", type=str, default="dynamic_shape",
choices=["dynamic_shape", "frozen_shape", "multi_gear"])
args = parser.parse_args()
return args
if __name__ == "__main__":
args = init_args()
testset = OCRTestDataset(args.dset_image_dir, args.dset_annotation_dir)
infer_text_system = InferTextSystem(**vars(args))
# infer_text_system("PaddleOCR/doc/imgs/00018069.jpg")
evaluator = Evaluator()
results = {}
total_det_elapse = 0
total_rec_elapse = 0
for i in range(len(testset)):
image_file, labels = testset[i]
image = cv2.imread(image_file)
dt_boxes, dt_elapse = infer_text_system.detect(image)
rec_texts, rec_elapse = infer_text_system.recognize(image, labels["gt_boxes"])
metrics = evaluator.evaluate(dt_boxes=dt_boxes, rec_texts=rec_texts, **labels)
metrics.update({"det_elapse": dt_elapse, "rec_elapse": rec_elapse})
total_det_elapse += dt_elapse
total_rec_elapse += rec_elapse
results[os.path.basename(image_file)] = metrics
results["total"] = {**evaluator.get(),
"det_elapse": total_det_elapse / len(testset),
"rec_elapse": total_rec_elapse / len(testset),
}
print(json.dumps(results, indent=2))
utility.py
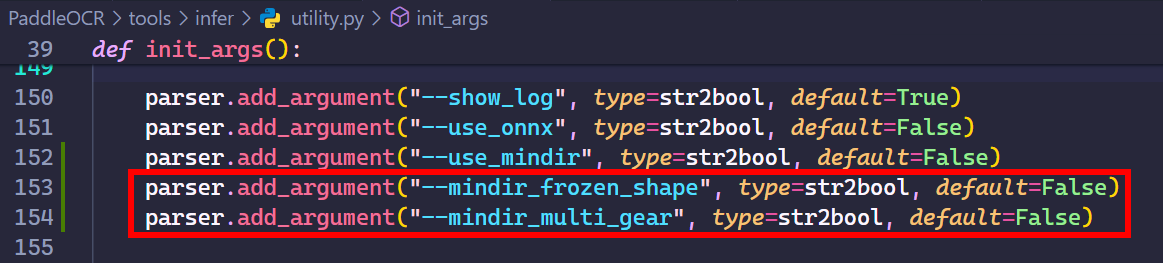
- 在
init_args函数,新增--mindir_frozen_shape用于指示开启固定shape推理;新增--mindir_multi_gear用于指示开启多档shape推理
parser.add_argument("--mindir_frozen_shape", type=str2bool, default=False)
parser.add_argument("--mindir_multi_gear", type=str2bool, default=False)
predict_det.py
- 在
__init__函数中,保存args.mindir_frozen_shape和args.mindir_multi_gear的值
self.mindir_frozen_shape = args.mindir_frozen_shape
self.mindir_multi_gear = args.mindir_multi_gear
try:
assert not (self.mindir_frozen_shape and self.mindir_multi_gear)
except AssertionError:
logger.warn("`mindir_frozen_shape` and `mindir_multi_gear` are both enabled, \
defaultly, set `mindir_frozen_shape=False` to prevent errors.")
self.mindir_frozen_shape = False
- 在
__init__函数中,新增前处理初始化逻辑,分别针对固定shape和多档shape,示例如下:
if self.use_onnx:
img_h, img_w = self.input_tensor.shape[2:]
...
elif self.use_mindir and self.mindir_frozen_shape:
img_h, img_w = self.input_tensor[0].shape[2:]
assert isinstance(img_h, int) and img_h > 0, "[mindir] error frozen shape -- img_h"
assert isinstance(img_w, int) and img_w > 0, "[mindir] error frozen shape -- img_w"
pre_process_list[0] = {
"DetResizeForTest": {"image_shape": [img_h, img_w]}
}
elif self.use_mindir and self.mindir_multi_gear:
# img_h: 320, 480, 640
# img_w: (wh_ratios, 0.5 -> 2.0)
pre_process_list[0] = {
"DetResizeForTest": {"image_shape": [640, -1],
"keep_ratio": True}
}
self.preprocess_op = create_operators(pre_process_list)
...
- 在
TextDetector -- predict函数中,修改mindir模型的resize逻辑,最小示例如下:
if self.use_onnx:
...
elif self.use_mindir: # for ascend inference
if not self.mindir_frozen_shape: # dynamic-shape or multi-gear
self.predictor.resize(self.input_tensor, [img.shape])
inputs = self.predictor.get_inputs()
inputs[0].set_data_from_numpy(img)
# execute inference
outputs = self.predictor.predict(inputs)
outputs = [o.get_data_to_numpy() for o in outputs]
else:
self.input_tensor.copy_from_cpu(img)
...
predict_rec.py
- 在
__init__函数中,保存args.mindir_frozen_shape和args.mindir_multi_gear的值
self.mindir_frozen_shape = args.mindir_frozen_shape
self.mindir_multi_gear = args.mindir_multi_gear
try:
assert not (self.mindir_frozen_shape and self.mindir_multi_gear)
except AssertionError:
logger.warn("`mindir_frozen_shape` and `mindir_multi_gear` are both enabled, \
defaultly, set `mindir_frozen_shape=False` to prevent errors.")
self.mindir_frozen_shape = False
- 在
TextDetector -- resize_norm_img函数中,新增前处理初始化逻辑,分别针对固定shape和多档shape,示例如下:
if self.use_onnx:
w = self.input_tensor.shape[3:][0]
...
elif self.use_mindir and self.mindir_frozen_shape:
w = self.input_tensor[0].shape[3]
assert isinstance(w, int) and w > 0, "[mindir] error fronzen shape -- w"
imgW = w
elif self.use_mindir and self.mindir_multi_gear:
# img_h=48, img_w: 32, ..., 960
imgW = math.ceil(imgH * max_wh_ratio / 32) * 32
h, w = img.shape[:2]
...
- 在
TextRecognizer -- __call__函数中,大约579行的位置,新增填充batch-size的逻辑
norm_img_batch = np.concatenate(norm_img_batch)
norm_img_batch = norm_img_batch.copy()
# padding batch-size ===> start
if self.mindir_frozen_shape or self.mindir_multi_gear:
padding_img_batch_size = self.rec_batch_num - len(norm_img_batch)
padding_img_shape = norm_img_batch.shape[1:]
paddign_img_batch = np.zeros((padding_img_batch_size, *padding_img_shape),
dtype=np.float32)
norm_img_batch = np.concatenate([norm_img_batch, paddign_img_batch], axis=0)
# padding batch-size ===> end
if self.benchmark:
self.autolog.times.stamp()
- 在
TextRecognizer -- __call__函数中,大约700行的位置,修改mindir模型的resize逻辑,最小示例如下:
if self.use_onnx:
...
elif self.use_mindir: # for ascend inference
if not self.mindir_frozen_shape: # dynamic-shape or multi-gear
self.predictor.resize(self.input_tensor, [norm_img_batch.shape])
inputs = self.predictor.get_inputs()
inputs[0].set_data_from_numpy(norm_img_batch)
outputs = self.predictor.predict(inputs)
outputs = [o.get_data_to_numpy() for o in outputs]
preds = outputs[0]
# drop results of dummy-data
if self.mindir_frozen_shape or self.mindir_multi_gear:
vaild_img_batch_size = self.rec_batch_num - padding_img_batch_size
preds = preds[:vaild_img_batch_size]
else:
self.input_tensor.copy_from_cpu(norm_img_batch)
...
步骤3 动态shape评估
- 支持动态shape的模型已在任务一中生成:
inference/det/model.mindir和inference/rec/model.mindir - 在notebook中执行如下命令,将评估动态shape下模型的识别性能和推理耗时:
输入:
%cd /home/ma-user/work/
!python evaluate.py --det_model inference/det/model.mindir \
--rec_model inference/rec/model.mindir \
--infer_type dynamic_shape
输出:
/home/ma-user/work
[2024-07-29 18:11:14,197] [ WARNING] model.py:109 - mslite ascendc custom kernel path not found
[2024-07-29 18:11:21,208] [ WARNING] model.py:109 - mslite ascendc custom kernel path not found
[WARNING] ME(75276,ffff833360b0,python):2024-07-29-18:11:25.078.141 [mindspore/lite/src/extendrt/kernel/ascend/src/custom_ascend_kernel.cc:168] Resize] Invalid inputs or output shapes.
[WARNING] ME(75276,ffff833360b0,python):2024-07-29-18:11:25.134.488 [mindspore/lite/src/extendrt/kernel/ascend/src/custom_ascend_kernel.cc:168] Resize] Invalid inputs or output shapes.
{
"image_0.jpg": {
"precision": 1.0,
"recall": 0.7777777777777778,
"hmean": 0.8750000000000001,
"acc": 0.7777769135812072,
"norm_edit_dis": 0.9444445061727709,
"det_elapse": 0.08648085594177246,
"rec_elapse": 0.17359185218811035
},
"image_1.jpg": {
"precision": 1.0,
"recall": 1.0,
"hmean": 1.0,
"acc": 0.9999985714306123,
"norm_edit_dis": 1.0,
"det_elapse": 0.07720947265625,
"rec_elapse": 0.050136566162109375
},
"image_1013.jpg": {
"precision": 1.0,
"recall": 1.0,
"hmean": 1.0,
"acc": 0.9999950000249999,
"norm_edit_dis": 1.0,
"det_elapse": 0.047595977783203125,
"rec_elapse": 0.01030421257019043
},
"image_1016.jpg": {
"precision": 1.0,
"recall": 1.0,
"hmean": 1.0,
"acc": 0.9999950000249999,
"norm_edit_dis": 1.0,
"det_elapse": 0.0553433895111084,
"rec_elapse": 0.010103225708007812
},
"total": {
"precision": 1.0,
"recall": 0.9,
"hmean": 0.9473684210526316,
"acc": 0.899999550000225,
"norm_edit_dis": 0.9750000124999938,
"det_elapse": 0.0666574239730835,
"rec_elapse": 0.06103396415710449
}
}
步骤4 固定shape评估
- 首先使用
converter_lite工具,将onnx模型转换为支持固定shape的mindir模型,输出CONVERT RESULT SUCCESS:0即表示转换成功
%cd /home/ma-user/work/
!converter_lite --fmk=ONNX \
--saveType=MINDIR \
--optimize=ascend_oriented \
--modelFile=inference/det/model.onnx \
--outputFile=inference/det/model_frozen_shape \
--inputShape=x:1,3,640,640
!converter_lite --fmk=ONNX \
--saveType=MINDIR \
--optimize=ascend_oriented \
--modelFile=inference/rec/model.onnx \
--outputFile=inference/rec/model_frozen_shape \
--inputShape=x:6,3,48,320
- 然后在notebook中执行如下命令,将评估固定shape下模型的识别性能和推理耗时:
输入:
%cd /home/ma-user/work/
!python evaluate.py --det_model inference/det/model_frozen_shape.mindir \
--rec_model inference/rec/model_frozen_shape.mindir \
--infer_type frozen_shape
输出:
/home/ma-user/work
[2024-07-29 18:15:53,058] [ WARNING] model.py:109 - mslite ascendc custom kernel path not found
[2024-07-29 18:15:54,389] [ WARNING] model.py:109 - mslite ascendc custom kernel path not found
{
"image_0.jpg": {
"precision": 0.75,
"recall": 0.6666666666666666,
"hmean": 0.7058823529411765,
"acc": 0.7777769135812072,
"norm_edit_dis": 0.9500000555554938,
"det_elapse": 0.054441213607788086,
"rec_elapse": 0.05269813537597656
},
"image_1.jpg": {
"precision": 0.8571428571428571,
"recall": 0.8571428571428571,
"hmean": 0.8571428571428571,
"acc": 0.9999985714306123,
"norm_edit_dis": 1.0,
"det_elapse": 0.04184436798095703,
"rec_elapse": 0.03612112998962402
},
"image_1013.jpg": {
"precision": 1.0,
"recall": 1.0,
"hmean": 1.0,
"acc": 0.9999950000249999,
"norm_edit_dis": 1.0,
"det_elapse": 0.034049034118652344,
"rec_elapse": 0.01288747787475586
},
"image_1016.jpg": {
"precision": 1.0,
"recall": 1.0,
"hmean": 1.0,
"acc": 0.9999950000249999,
"norm_edit_dis": 1.0,
"det_elapse": 0.03696155548095703,
"rec_elapse": 0.013694524765014648
},
"total": {
"precision": 0.8421052631578947,
"recall": 0.8,
"hmean": 0.8205128205128205,
"acc": 0.899999550000225,
"norm_edit_dis": 0.9775000112499944,
"det_elapse": 0.04182404279708862,
"rec_elapse": 0.028850317001342773
}
}
步骤5 多档shape评估
- 首先在
inference目录下,新建两个配置文件config_det.conf和config_rec.conf,并填入如下内容:
// inference/config_det.conf
[ascend_context]
input_format=NCHW
input_shape=x:[1,3,-1,-1]
dynamic_dims=[640,480],[640,640],[640,992]
// inference/config_rec.conf
[ascend_context]
input_format=NCHW
input_shape=x:[6,3,-1,-1]
dynamic_dims=[48,160],[48,288],[48,320],[48,352],[48,416],[48,512],[48,800]
- 注意:这里的dynamic_dims参数可以指定模型输入的shape,最高支持100档。对于检测模型,我们先固定height=640,假定宽高比范围为[0.5, 2],然后在保持宽高比的情况下,将width缩放为最接近32的倍数。对于识别模型,我们固定batch-size=6,假定宽高比范围为[0.5, 20],以32的步长设置输入图片的宽。
- 然后使用
converter_lite工具,将onnx模型转换为支持多档shape的mindir模型,输出CONVERT RESULT SUCCESS:0即表示转换成功
%cd /home/ma-user/work/
!converter_lite --fmk=ONNX \
--saveType=MINDIR \
--optimize=ascend_oriented \
--modelFile=inference/det/model.onnx \
--outputFile=inference/det/model_multi_gear \
--configFile=inference/config_det.conf
!converter_lite --fmk=ONNX \
--saveType=MINDIR \
--optimize=ascend_oriented \
--modelFile=inference/rec/model.onnx \
--outputFile=inference/rec/model_multi_gear \
--configFile=inference/config_rec.conf
- 最后在notebook中执行如下命令,评估多档shape下模型的识别性能和推理耗时:
输入:
%cd /home/ma-user/work/
!python evaluate.py --det_model inference/det/model_multi_gear.mindir \
--rec_model inference/rec/model_multi_gear.mindir \
--infer_type multi_gear
输出:
/home/ma-user/work
[2024-07-29 18:31:22,812] [ WARNING] model.py:109 - mslite ascendc custom kernel path not found
[2024-07-29 18:31:24,821] [ WARNING] model.py:109 - mslite ascendc custom kernel path not found
{
"image_0.jpg": {
"precision": 1.0,
"recall": 0.6666666666666666,
"hmean": 0.8,
"acc": 0.7777769135812072,
"norm_edit_dis": 0.9444445061727709,
"det_elapse": 0.04750823974609375,
"rec_elapse": 0.04743814468383789
},
"image_1.jpg": {
"precision": 0.8571428571428571,
"recall": 0.8571428571428571,
"hmean": 0.8571428571428571,
"acc": 0.9999985714306123,
"norm_edit_dis": 1.0,
"det_elapse": 0.042635202407836914,
"rec_elapse": 0.05770230293273926
},
"image_1013.jpg": {
"precision": 1.0,
"recall": 1.0,
"hmean": 1.0,
"acc": 0.9999950000249999,
"norm_edit_dis": 1.0,
"det_elapse": 0.05117201805114746,
"rec_elapse": 0.011896610260009766
},
"image_1016.jpg": {
"precision": 1.0,
"recall": 1.0,
"hmean": 1.0,
"acc": 0.9999950000249999,
"norm_edit_dis": 1.0,
"det_elapse": 0.030267953872680664,
"rec_elapse": 0.013908863067626953
},
"total": {
"precision": 0.9411764705882353,
"recall": 0.8,
"hmean": 0.8648648648648648,
"acc": 0.899999550000225,
"norm_edit_dis": 0.9750000124999938,
"det_elapse": 0.0428958535194397,
"rec_elapse": 0.03273648023605347
}
}
步骤6 结果总览
| hmean | acc | norm_edit_dis | det_elapse | rec_elapse | |
|---|---|---|---|---|---|
| 动态shape | 0.9473 | 90% | 0.9750 | 66.7ms | 61.0ms |
| 固定shape | 0.8205 | 90% | 0.9775 | 41.8ms | 28.9ms |
| 多档shape | 0.8649 | 90% | 0.9750 | 42.9ms | 32.7ms |
由评估结果可知,动态shape性能最好而推理耗时最高,多档shape能够在维持固定shape推理速度的同时,提高识别性能。
任务四:PaddleOCR模型部署准备
在跑通“任务二 PaddleOCR推理”后,在ModelArts服务中可以将OCR推理管线创建为AI应用,然后将AI应用快速部署为在线推理服务,流程图如下所示:
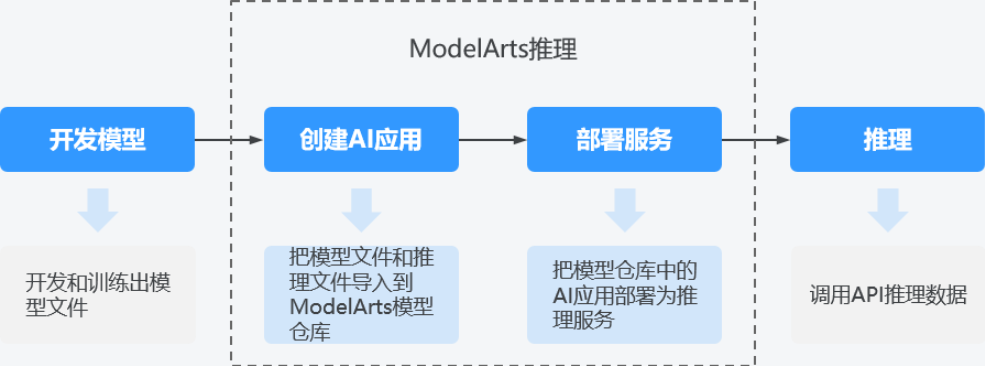
◉ 开发模型:模型开发可以在ModelArts服务中进行,也可以在您的本地开发环境进行。
◉ 创建AI应用:把模型文件、配置文件和推理文件导入到ModelArts的模型仓库中,进行版本化管理,并构建为可运行的AI应用。
◉ 部署服务:把AI应用在资源池中部署为容器实例,注册外部可访问的推理API。
◉ 推理:在您的应用中增加对推理API的调用,在业务流程中集成AI推理能力。
步骤1 编写推理代码
本步骤主要是准备 customize_service.py推理文件,分为以下五部分:①导入推理依赖包;②重写__init__函数;③重写_preprocess函数;④重写_inference函数;⑤重写_postprocess函数。下面将分别详细介绍:
在 /home/ma-user/work目录下,新建 customize_service.py文件
- 1.插入如下代码,导入推理所需的依赖包
import cv2
import numpy as np
from PIL import Image
import os
from model_service.model_service import SingleNodeService # mindspore
os.sys.path.append(os.path.join(
os.path.dirname(os.path.abspath(__file__)), "PaddleOCR"
))
from typing import List, Dict, Any
import tools.infer.utility as utility
from tools.infer.predict_system import TextSystem
-
注意:不同框架需要导入的依赖不同
- MindSpore框架,需要导入
SingleNodeService父类,来创建推理服务 - TensorFlow和PyTorch框架,需要导入的父类见官方文档
- MindSpore框架,需要导入
-
导入依赖包之后,创建
CustomizeService类,其框架如下:
class CustomizeService(SingleNodeService):
def __init__(self, model_name: str, model_path: str):
# 初始化Mindir模型
...
def _preprocess(self, data: Dict[str, Dict[str, Any]]) -> Dict[str, np.ndarray]:
# 前处理:读取字节流/图片文件
...
def _inference(self, data: Dict[str, np.ndarray]) -> Dict[str, Dict[str, List]]:
# 推理:将图片进行OCR推理
...
def _postprocess(self, data: Dict[str, Dict[str, List]]) -> Dict[str, Dict[str, Any]]:
# 后处理:规整OCR推理结果
...
- 2.初始化函数
__init__,主要由两部分组成:加载PaddleOCR的默认参数并指定推理所需的参数;然后根据默认参数,创建TextSystem用于推理
def __init__(self, model_name: str, model_path: str):
super(CustomizeService, self).__init__(model_name, model_path)
self.model_name = model_name # serve
self.model_path = model_path # `/home/ma-user/infer/run.sh`: $INFER_DIR/model/1/
args, unknown = utility.init_args().parse_known_args() # !!! IMPORTANT FOR `modelarts-server`
args.use_mindir = True
args.det_model_dir = os.path.join(model_path, 'inference/det/model.mindir')
args.rec_model_dir = os.path.join(model_path, 'inference/rec/model.mindir')
paddle_ocr_project_path = os.path.join(model_path, 'PaddleOCR')
args.rec_char_dict_path = os.path.join(paddle_ocr_project_path, 'ppocr/utils/ppocr_keys_v1.txt')
args.vis_font_path = os.path.join(paddle_ocr_project_path, 'doc/fonts/simfang.ttf')
self.paddle_ocr_project_path = paddle_ocr_project_path
self.visualize = False
self.text_sys = TextSystem(args)
if args.warmup:
img = np.random.uniform(0, 255, [640, 640, 3]).astype(np.uint8)
for _ in range(10):
self.text_sys(img)
- 3.前处理函数
_preprocess:将modelarts推理传入的图片字节流,即file_content,转为PaddleOCR输入要求的BGR格式。
def _preprocess(self, data: Dict[str, Dict[str, Any]]) -> Dict[str, np.ndarray]:
"""
curl -X POST <modelarts-inference-endpoint> \
-F image1=@cat.jpg \
-F image2=@horse.jpg
data:
[{
"image1":{"cat.jpg":"<cat.jpg file io>"}
},
{
"image2":{"horse.jpg":"<horse.jpg file io>"}
}]
"""
preprocessed_data = {}
for k, v in data.items():
file_name, file_content = next(iter(v.items())) # only-support single image
image = np.array(Image.open(file_content))
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
preprocessed_data[k] = image
return preprocessed_data
- 4.推理函数
_inference,复用PaddleOCR接口,识别目标图像,获得检测文本框位置及其对应的识别结果
def _inference(self, data: Dict[str, np.ndarray]) -> Dict[str, Dict[str, List]]:
"""
result-item -> {
"dt_boxes": [quadruplet-box1, ...],
"rec_res": [(text, score), (...)]
}
"""
result = {}
for k, v in data.items():
dt_boxes, rec_res, time_dict = self.text_sys(v)
result[k] = {"dt_boxes": dt_boxes,
"rec_res": rec_res}
return result
- 5.后处理函数
_postprocess,将识别结果按照,“transcription“、”confidence”和”position”组织,分别表示检测到文本框的识别结果、置信度和用四元组表示的位置
def _postprocess(self, data: Dict[str, Dict[str, List]]) -> Dict[str, Dict[str, Any]]:
"""
result-item -> [
{"transcription": <text>,
"confidence": <score>,
"position": <box>},
{...}
]
"""
result = {}
for k, v in data.items():
dt_boxes = v['dt_boxes']
rec_res = v['rec_res']
ocr_results_single_image = []
for (text, score), box in zip(rec_res, dt_boxes):
box_result = {"transcription": text,
"confidence": score,
"position": box.tolist()}
ocr_results_single_image.append(box_result)
result[k] = ocr_results_single_image
return result
步骤2 本地测试
本步骤主要是在notebook中测试推理服务,启动脚本见 /home/ma-user/infer/run.sh
- 1.拷贝项目文件:在notebook中执行如下命令,将PaddleOCR推理所必须的文件:
PaddleOCR、inference、customize_service.py,拷贝到/home/ma-user/infer/model/1目录下
%cd /home/ma-user/work
!cp -r inference PaddleOCR customize_service.py /home/ma-user/infer/model/1
- 2.拉起推理服务:由于本镜像的推理不支持https服务,即
MODELARTS_SSL_ENABLE=false,建立推理服务之前,需要先修改启动脚本run.sh然后再运行

新建terminal,执行如下命令将拉起PaddleOCR推理服务
输入:
bash /home/ma-user/infer/run.sh
输出:
The environment has been set
__ __ _ _ _
| \/ | | | | | /\ | |
| \ / | ___ __| | ___ | | / \ _ __ | |_ ___
| |\/| | / _ \ / _ | / _ \ | | / /\ \ | __| | __ | / __|
| | | | | (_) | | (_| | | __/ | | / ____ \ | | | |_ \__ \
|_| |_| \___/ \__ _| \___| |_| /_/ \_\ |_| \__| |___/
Using user ma-user
EulerOS 2.0 (SP10), CANN-7.0.RC1 [V100R001C29],[V100R001C30],[V100R001C13],[V100R003C10],[V100R003C11]
Tips:
1) Navigate to the target conda environment. For details, see /home/ma-user/README.
2) Copy (Ctrl+C) and paste (Ctrl+V) on the jupyter terminal.
3) Store your data in /home/ma-user/work, to which a persistent volume is mounted.
start. . .
[2024-08-26 10:49:53 +0800] [20736] [INFO] Starting gunicorn 21.2.0
[2024-08-26 10:49:53 +0800] [20736] [INFO] Listening at: http://127.0.0.1:8443 (20736)
[2024-08-26 10:49:53 +0800] [20736] [INFO] Using worker: gthread
[2024-08-26 10:49:53 +0800] [20752] [INFO] Booting worker with pid: 20752
2024-08-26 10:49:54 CST [MainThread ] - /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages/model_service/app.py[line:50] - INFO: args: Namespace(model_path='/home/ma-user/infer/model/1', model_name='serve', tf_server_name='127.0.0.1', service_file='/home/ma-user/infer/model/1/customize_service.py') []
model_path=/home/ma-user/infer/model/1
model_name=serve
model_service_file=/home/ma-user/infer/model/1/customize_service.py
tf_server_name=127.0.0.1
[2024-08-26 10:49:58,882] [ WARNING] model.py:109 - mslite ascendc custom kernel path not found
[2024-08-26 10:50:05,772] [ WARNING] model.py:109 - mslite ascendc custom kernel path not found
此时推理服务已建立,监听端口号为 8443
- 3.请求测试:在终端用
curl命令测试推理服务是否成功调用
新建一个terminal,执行如下命令将使用 PaddleOCR/doc/imgs/11.jpg图片文件进行测试,并输出列表形式的结果。其中,列表的每个元素包含“transcription“、”confidence”和”position”,分别表示检测到文本框的识别结果、置信度和用四元组表示的位置
输入:
curl -kv -F 'images=@/home/ma-user/infer/model/1/PaddleOCR/doc/imgs/11.jpg' -X POST http://127.0.0.1:8443
输出:
Note: Unnecessary use of -X or --request, POST is already inferred.
* Uses proxy env variable no_proxy == '127.0.0.1,localhost,172.16.*,obs.cn-southwest-2.myhuaweicloud.com,iam.cn-southwest-2.huaweicloud.com,pip.modelarts.private.com,.myhuaweicloud.com'
* Trying 127.0.0.1:8443...
* Connected to 127.0.0.1 (127.0.0.1) port 8443 (#0)
> POST / HTTP/1.1
> Host: 127.0.0.1:8443
> User-Agent: curl/7.71.1
> Accept: */*
> Content-Length: 48866
> Content-Type: multipart/form-data; boundary=------------------------1e4ccec8cb7a7587
>
* We are completely uploaded and fine
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Server: gunicorn
< Date: Mon, 26 Aug 2024 02:52:29 GMT
< Connection: keep-alive
< Content-Type: application/json
< Content-Length: 2639
<
{"images": [{"transcription": "纯臻营养护发素", "confidence": 0.99462890625, "position": [[26.0, 37.0], [304.0, 37.0], [304.0, 73.0], [26.0, 73.0]]}, {"transcription": "产品信息/参数", "confidence": 0.9929547905921936, "position": [[26.0, 81.0], [171.0, 81.0], [171.0, 102.0], [26.0, 102.0]]}, {"transcription": "(45元/每公斤,100公斤起订)", "confidence": 0.9635224938392639, "position": [[26.0, 111.0], [332.0, 111.0], [332.0, 134.0], [26.0, 134.0]]}, {"transcription": "每瓶22元,1000瓶起订)", "confidence": 0.9955008625984192, "position": [[25.0, 143.0], [282.0, 143.0], [282.0, 165.0], [25.0, 165.0]]}, {"transcription": "【品牌】:代加工方式/OEMODM", "confidence": 0.9853228330612183, "position": [[25.0, 179.0], [299.0, 179.0], [299.0, 195.0], [25.0, 195.0]]}, {"transcription": "【品名】:纯臻营养护发素", "confidence": 0.99755859375, "position": [[24.0, 208.0], [234.0, 208.0], [234.0, 228.0], [24.0, 228.0]]}, {"transcription": "【产品编号】:YM-X-3011", "confidence": 0.98883056640625, "position": [[24.0, 239.0], [242.0, 239.0], [242.0, 259.0], [24.0, 259.0]]}, {"transcription": "ODMOEM", "confidence": 0.9950358271598816, "position": [[414.0, 234.0], [428.0, 234.0], [428.0, 302.0], [414.0, 302.0]]}, {"transcription": "【净含量】:220ml", "confidence": 0.9907670617103577, "position": [[24.0, 271.0], [180.0, 271.0], [180.0, 290.0], [24.0, 290.0]]}, {"transcription": "【适用人群】:适合所有肤质", "confidence": 0.9890324473381042, "position": [[26.0, 304.0], [252.0, 304.0], [252.0, 320.0], [26.0, 320.0]]}, {"transcription": "【主要成分】:鲸蜡硬脂醇、燕麦β-葡聚", "confidence": 0.9773334860801697, "position": [[25.0, 334.0], [342.0, 334.0], [342.0, 351.0], [25.0, 351.0]]}, {"transcription": "糖、椰油酰胺丙基甜菜碱、泛醒", "confidence": 0.98291015625, "position": [[27.0, 366.0], [280.0, 366.0], [280.0, 383.0], [27.0, 383.0]]}, {"transcription": "(成品包材)", "confidence": 0.997802734375, "position": [[3* Connection #0 to host 127.0.0.1 left intact
67.0, 368.0], [475.0, 368.0], [475.0, 388.0], [367.0, 388.0]]}, {"transcription": "【主要功能】:可紧致头发磷层,从而达到", "confidence": 0.9955026507377625, "position": [[25.0, 397.0], [360.0, 397.0], [360.0, 414.0], [25.0, 414.0]]}, {"transcription": "即时持久改善头发光泽的效果,给干燥的头", "confidence": 0.9889751076698303, "position": [[28.0, 429.0], [371.0, 429.0], [371.0, 445.0], [28.0, 445.0]]}, {"transcription": "发足够的滋养", "confidence": 0.998291015625, "position": [[26.0, 458.0], [136.0, 458.0], [136.0, 478.0], [26.0, 478.0]]}]}
- 注意:本地测试结束后,需要将host_ip的值恢复,
host_ip=$(hostname -i)
任务五:创建AI应用并部署在线服务
ModelArts提供三种创建AI应用的方式:从训练作业、从容器镜像、从OBS创建。因此,可以选择方式1或方式2创建AI应用。
方式1 从容器镜像创建AI应用
notebook保存镜像
这里我们选择“从容器镜像创建ai应用”,因此需要先保存任务二创建的notebook镜像
进入“开发空间 > notebook”页面,选择“更多 > 保存镜像”

等待快照结束后,再进入下一步(大约10分钟左右)

注意:如果提示没有镜像组织,则需要新建一个
创建AI应用
进入“资产管理 > AI应用”,开始创建AI应用

- 元模型来源
- 选择从容器镜像创建
- 容器镜像所在路径:选择刚才保存的notebook镜像
- 容器调用接口:选择HTTP,端口为8443
其他参数配置见下图

启动命令设置:sh /home/ma-user/infer/run.sh
apis定义如下:
[{
"url": "/",
"method": "post",
"request": {
"Content-type": "multipart/form-data",
"data": {
"type": "object",
"properties": {
"images": {
"type": "file"
}
}
}
},
"response": {
"Content-type": "multipart/form-data",
"data": {
"type": "object",
"properties": {
"ocr_results": {
"type": "list",
"items": [{
"type": "object",
"properties": {
"transcription": {
"type": "string"
},
"confidence": {
"type": "number"
},
"position": {
"type": "list",
"minItems": 4,
"maxItems": 4,
"items": [{
"type": "number"
}]
}
}
}]
}
}
}
}
}]
方式2 从OBS桶创建AI应用
准备推理模型和代码
这里我们选择“从OBS创建ai应用”,因此需要按照部署规范,将推理模型和代码放在OBS桶中
注意:没有OBS桶则新建一个,区域选择“西南贵阳一”,数据冗余存储策略选择“单AZ存储”即可
- 1.首先从OBS拉取代码和权重文件,并删除
PaddleOCR/.git和PaddleOCR/delpoy/docker目录,防止镜像构建失败
%cd /home/ma-user/work
mox.file.copy_parallel("obs://dtse-model-guiyangyi/course/paddle_ocr", "model")
!rm -rf model/PaddleOCR/.git
!rm -rf model/PaddleOCR/deploy/docker
- 2.按照任务四准备推理代码
customize_service.py,按照下文内容准备config.json文件,并将其放在model文件夹下。
最终 model目录内容如下图:

config.json文件内容如下:
{
"model_type": "MindSpore",
"model_algorithm": "OCR",
"runtime": "mindspore_2.2.0-cann_7.0.1-py_3.9-euler_2.10.7-aarch64-snt9b",
"apis": [{
"url": "/",
"method": "post",
"request": {
"Content-type": "multipart/form-data",
"data": {
"type": "object",
"properties": {
"images": {
"type": "file"
}
}
}
},
"response": {
"Content-type": "multipart/form-data",
"data": {
"type": "object",
"properties": {
"ocr_results": {
"type": "list",
"items": [{
"type": "object",
"properties": {
"transcription": {
"type": "string"
},
"confidence": {
"type": "number"
},
"position": {
"type": "list",
"minItems": 4,
"maxItems": 4,
"items": [{
"type": "number"
}]
}
}
}]
}
}
}
}
}],
"dependencies": [{
"installer": "pip",
"packages": [
{
"package_name": "shapely"
},
{
"package_name": "scikit-image"
},
{
"package_name": "imgaug"
},
{
"package_name": "pyclipper"
},
{
"package_name": "lmdb"
},
{
"package_name": "tqdm"
},
{
"package_name": "rapidfuzz"
},
{
"package_name": "opencv-python"
},
{
"package_name": "opencv-contrib-python"
},
{
"package_name": "cython"
},
{
"package_name": "Pillow"
},
{
"package_name": "pyyaml"
},
{
"package_name": "requests"
},
{
"package_name": "numpy",
"package_version": "1.22.0",
"restraint": "EXACT"
},
{
"package_name": "paddlepaddle",
"package_version": "2.6.1",
"restraint": "EXACT"
},
{
"package_name": "paddle2onnx",
"package_version": "1.2.4",
"restraint": "EXACT"
}
]
}]
}
- 3.将准备好的
model目录上传到自己的OBS桶内,注意替换自己的桶名称
输入:
%cd /home/ma-user/work
import moxing as mox
mox.file.make_dirs("obs://gy1-bucket-xc/paddleocr/model")
mox.file.copy_parallel("model", "obs://gy1-bucket-xc/paddleocr/model")
输出:
INFO:root:Using MoXing-v2.2.3.2c7f2141-2c7f2141
INFO:root:Using OBS-Python-SDK-3.20.9.1
INFO:root:Using OBS-C-SDK-2.23.1
WARNING:root:[MOX_PROFILE] PID 2041: Exists called 1143 times, cache hit rate 0.0% (threshold 10.0%), metadata cache hit rate 0.0% (threshold 10.0%), log interval 300s.
INFO:root:List OBS time cost: 34.41 seconds.
INFO:root:1000/1955
INFO:root:Copy parallel total time cost: 43.94 seconds.
创建AI应用
进入“资产管理 > AI应用”,开始创建AI应用

- 元模型来源
- 选择从对象服务存储服务OBS创建
- 元模型存储路径为:
model目录的上一级,即paddleocr - 由于我们编写的
config.json文件中包含了启动镜像、推理依赖及apis定义,因此其他参数会自动读取并填入

启动命令设置:sh /home/ma-user/infer/run.sh
步骤3 部署在线服务
进入“资产管理 > AI应用”,选中刚才创建的AI应用,点击“部署 > 在线服务”,开始配置部署的参数

- 名称:自定义即可
- 资源池:没有专属资源池,即选择公共资源池
- AI应用及版本,选择上一步创建的AI应用
点击“下一步 > 提交”,等待在线服务部署完成,如下图所示,可以查看在线服务的启动日志:

步骤4 在线服务预测
进入“开发空间 > 模型部署 > 在线服务”,进入之后,可以选中刚才部署的在线服务,进行预测测试:

点击预测后,会出现相关日志信息

参考资料
converter_lite工具使用:https://www.mindspore.cn/lite/docs/zh-CN/r2.3.0rc2/use/cloud_infer/converter_tool.html
动态batch和动态分辨率:https://www.mindspore.cn/lite/docs/zh-CN/r2.0/use/cloud_infer/converter_tool_ascend.html
推理规范-配置文件编写说明:https://support.huaweicloud.com/inference-modelarts/inference-modelarts-0056.html

- 点赞
- 收藏
- 关注作者
评论(0)