解密Java中的Map:如何高效地操作键值对?有两下子!


🏆本文收录于「滚雪球学Java」专栏中,这个专栏专为有志于提升Java技能的你打造,覆盖Java编程的方方面面,助你从零基础到掌握Java开发的精髓。赶紧关注,收藏,学习吧!
环境说明:Windows 10 + IntelliJ IDEA 2021.3.2 + Jdk 1.8
前言
在Java开发中,Map 是一种非常重要的数据结构。它以键值对的形式存储数据,并为我们提供了高效的查找、插入和删除操作。在各种应用场景中,Map 被广泛用于存储和处理关联数据。理解和掌握如何高效地操作Map,不仅能够提升代码的性能,还能提高程序的可维护性。本文将深入探讨Java中的Map,分析其核心实现,并展示如何在实际开发中充分发挥Map的优势。
摘要
本文系统地介绍了Java中Map的使用与优化策略,涵盖了HashMap、TreeMap、LinkedHashMap等常见实现。我们将深入解析Map的底层源码,揭示其性能特性,并通过实际案例展示Map在不同场景中的应用效果。本文还将提供代码示例和测试用例,帮助读者理解如何高效地操作键值对。最后,文章将总结Map的优缺点,并提供最佳实践建议,助力开发者在Java开发中更加游刃有余。
简介
Map 是Java集合框架中的一个重要接口,用于存储键值对映射。它不同于List或Set,因为Map允许我们通过键来快速访问对应的值,而不是按顺序存储元素。Java中提供了多个Map接口的实现,如HashMap、TreeMap、LinkedHashMap 等,它们各自有不同的性能特性和适用场景。
什么是Map?
- 键值对(Key-Value Pair):
Map通过键值对的形式存储数据,每个键都唯一地对应一个值。 - 键的唯一性:在
Map中,键必须是唯一的,重复的键会覆盖之前的值。 - 快速查找:
Map提供了高效的查找操作,可以通过键快速找到对应的值。
为什么使用Map?
在实际开发中,Map广泛应用于各种需要快速查找和存储关联数据的场景,如缓存、配置管理、索引数据等。通过使用Map,我们可以避免手动遍历集合进行查找,从而大大提高程序的执行效率。
概述
Java中实现Map接口的类主要包括:
HashMap:基于哈希表实现的Map,提供快速的查找和插入操作,但无序。TreeMap:基于红黑树实现的Map,提供键的有序存储,适用于需要按顺序访问键值对的场景。LinkedHashMap:基于HashMap和双向链表实现,维护插入顺序或访问顺序,适用于需要记录元素插入顺序的场景。
核心源码解读
1. HashMap 的实现原理
HashMap 是Java中最常用的Map实现之一。它基于哈希表实现,通过计算键的哈希值来确定键值对的存储位置。以下是HashMap的部分源码解析:
HashMap的put() 方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
- 哈希值计算:
hash(key)方法用于计算键的哈希值,决定键值对的存储位置。 - 冲突解决:当多个键的哈希值相同时,
HashMap采用链表或红黑树解决冲突。 - 扩容机制:当
HashMap中的元素数量超过一定阈值时,会自动扩容以保持性能。
2. TreeMap 的实现原理
TreeMap 基于红黑树实现,支持按键的自然顺序或自定义顺序存储键值对。以下是TreeMap的部分源码解析:
TreeMap的put() 方法
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
- 红黑树:
TreeMap通过红黑树结构存储键值对,保证数据的有序性和查找的高效性。 - 排序:
TreeMap可以按照键的自然顺序或自定义比较器进行排序,适用于需要顺序访问的场景。
3. LinkedHashMap 的实现原理
LinkedHashMap 继承自 HashMap,并通过双向链表维护元素的插入顺序或访问顺序。
LinkedHashMap的put() 方法
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
- 插入顺序:默认情况下,
LinkedHashMap按插入顺序存储键值对。 - 访问顺序:通过设置
accessOrder参数,可以让LinkedHashMap按访问顺序存储键值对,适用于实现LRU缓存。
案例分析
案例:选择合适的Map实现
假设你需要在一个应用程序中
存储用户的访问日志,并希望能够快速查询某个用户的最后访问时间,同时需要按访问顺序清理最早的访问记录。在这种场景下,选择合适的Map实现非常关键。
使用LinkedHashMap 实现LRU缓存
LinkedHashMap 提供了按访问顺序存储键值对的能力,非常适合实现LRU(Least Recently Used)缓存。以下是实现LRU缓存的代码示例:
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int capacity;
public LRUCache(int capacity) {
super(capacity, 0.75f, true);
this.capacity = capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > capacity;
}
public static void main(String[] args) {
LRUCache<Integer, String> cache = new LRUCache<>(3);
cache.put(1, "One");
cache.put(2, "Two");
cache.put(3, "Three");
cache.get(1); // 访问1
cache.put(4, "Four"); // 插入4,2被移除
System.out.println("Cache: " + cache);
}
}
代码分析
- 按访问顺序排序:在
LinkedHashMap中设置accessOrder为true,使得缓存按访问顺序排序。 - 容量控制:重写
removeEldestEntry()方法,在超过容量时移除最早访问的键值对,实现LRU缓存。
应用场景演示
Map在Java开发中有广泛的应用场景,以下是一些常见的例子:
- 缓存机制:
HashMap和LinkedHashMap常用于实现缓存机制,其中LinkedHashMap通过设置访问顺序可以轻松实现LRU缓存。 - 配置管理:在存储和管理应用程序配置时,
TreeMap可以通过键的有序性保证配置项的顺序输出。 - 索引数据:在数据分析和处理过程中,
Map可以用于建立索引,加速数据的查询和处理。
优缺点分析
优点
- 高效查找:
Map通过键值对的存储方式,提供了O(1)或O(log n)的查找效率,适用于大规模数据的快速查询。 - 多样性实现:Java提供了多种
Map的实现,满足了不同场景下的需求,如快速查找的HashMap、有序存储的TreeMap、顺序敏感的LinkedHashMap等。 - 扩展性强:
Map接口的实现类可以通过继承和重写来实现特定的功能,如自定义的缓存机制。
缺点
- 线程不安全:
HashMap等默认实现是线程不安全的,在多线程环境中需要使用ConcurrentHashMap等线程安全的实现。 - 内存开销大:
Map在存储大量键值对时,会占用较多的内存,尤其是LinkedHashMap由于维护链表结构,内存开销更大。 - 复杂度增加:在使用
TreeMap等实现时,由于需要维护键的有序性,插入和删除操作的复杂度会增加。
类代码方法介绍及演示
使用TreeMap 实现排序
以下代码演示了如何使用TreeMap来实现按键的自然顺序排序:
public class TreeMapExample {
public static void main(String[] args) {
TreeMap<String, Integer> map = new TreeMap<>();
map.put("Apple", 10);
map.put("Banana", 20);
map.put("Orange", 15);
System.out.println("TreeMap: " + map);
}
}
方法解析
- 自然顺序排序:
TreeMap会根据键的自然顺序进行排序,输出时按字母顺序排列键值对。 - Comparator支持:
TreeMap支持自定义比较器,可以实现更复杂的排序逻辑。
测试用例
为了验证Map的各种操作效果,以下是一个简单的测试用例:
测试代码
public class MapTest {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("A", 1);
map.put("B", 2);
map.put("C", 3);
System.out.println("Map contains A: " + map.containsKey("A"));
System.out.println("Value of B: " + map.get("B"));
map.remove("C");
System.out.println("Map after removing C: " + map);
}
}
测试结果预期
在运行测试代码后,我们应该看到以下输出:
Map contains A: true
Value of B: 2
Map after removing C: {A=1, B=2}
这表明Map能够正确执行基本的插入、查找和删除操作。
案例执行结果
根据如上的测试用例,作者在本地进行测试结果如下,仅供参考,你们也可以自行修改测试用例或者添加其他的测试数据或测试方法,以便于进行熟练学习以此加深知识点的理解。
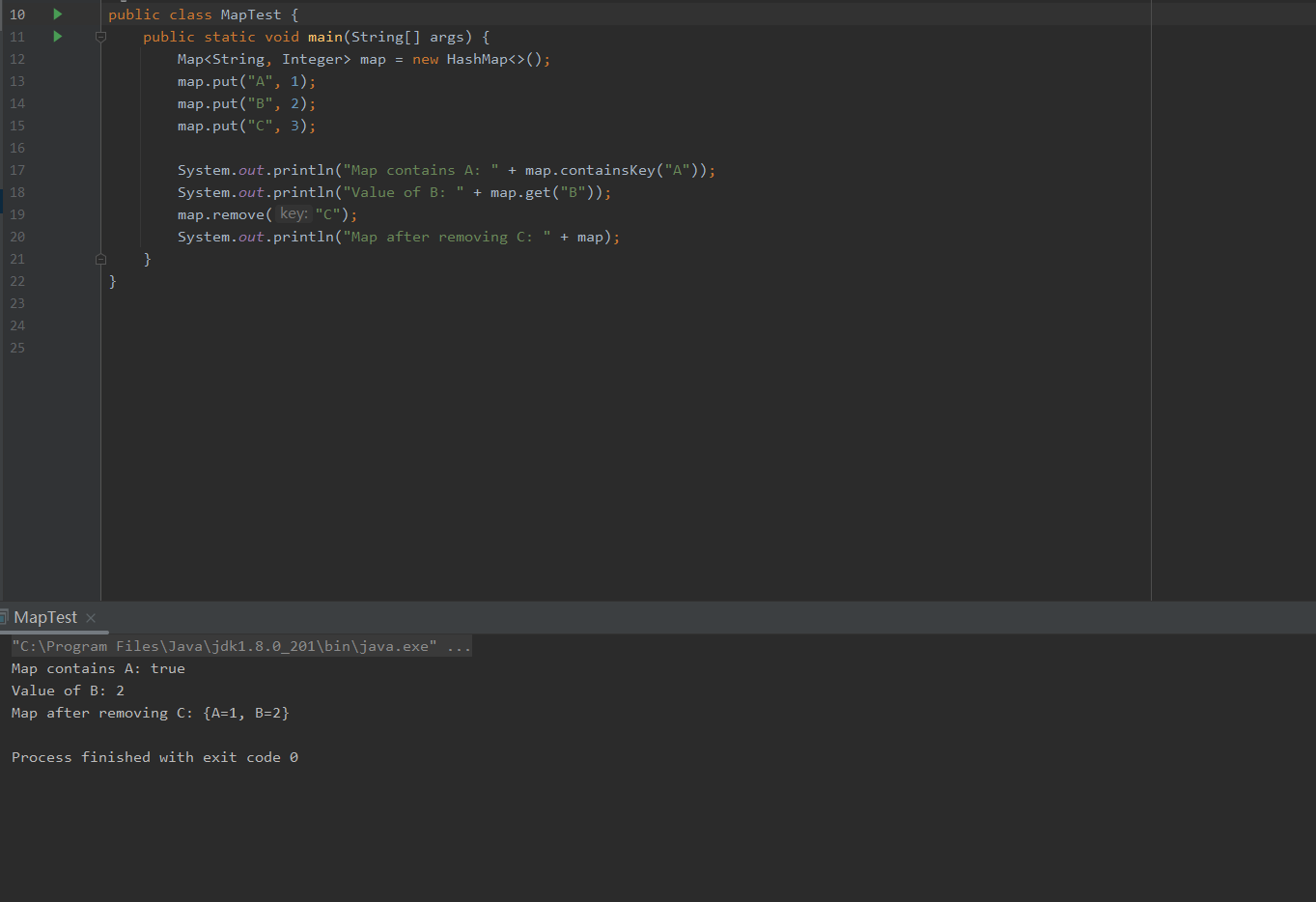
测试代码分析
通过这个测试,我们验证了Map的核心操作功能,证明其在键值对操作上的高效性和可靠性。
小结
本文通过对Java中Map的深入解析,帮助读者理解了如何高效地操作键值对。我们探讨了HashMap、TreeMap和LinkedHashMap的实现原理及其适用场景,并通过实际案例展示了这些实现的性能特点。通过本文的学习,读者应能够在实际开发中选择合适的Map实现,并优化代码性能。
总结
Map 是Java开发中必不可少的数据结构,其高效的键值对存储和查找功能广泛应用于各种场景。通过掌握Map的实现原理和最佳实践,开发者可以大大提升程序的性能和可维护性。在选择Map实现时,应根据具体需求,考虑性能、排序需求和内存开销,做出最佳选择。希望本文的内容能够为你的Java开发之路提供有益的参考和指导。
寄语
在编程的世界里,每一个数据结构都有其独特的用途和优化空间。通过不断学习和实践,掌握Map的操作技巧,你将能够编写出更高效、更健壮的Java程序。愿你在Java开发的道路上不断进步,成为一名卓越的开发者!
📣关于我
我是bug菌,CSDN | 掘金 | InfoQ | 51CTO | 华为云 | 阿里云 | 腾讯云 等社区博客专家,C站博客之星Top30,华为云2023年度十佳博主,掘金多年度人气作者Top40,掘金等各大社区平台签约作者,51CTO年度博主Top12,掘金/InfoQ/51CTO等社区优质创作者;全网粉丝合计 30w+;硬核微信公众号「猿圈奇妙屋」,欢迎你的加入!免费白嫖最新BAT互联网公司面试真题、4000G PDF电子书籍、简历模板等海量资料,你想要的我都有,关键是你不来拿哇。


- 点赞
- 收藏
- 关注作者
评论(0)