grep与Select-String用法对比

Visit me at CSDN: https://jclee95.blog.csdn.net
My WebSite:http://thispage.tech/
Email: 291148484@163.com.
Shenzhen China
Address of this article:https://blog.csdn.net/qq_28550263/article/details/139253970
HuaWei:https://bbs.huaweicloud.com/blogs/428150
【介绍】:grep用于在 Linux 和其他类 Unix 系统中搜索文本。Select-String 是 PowerShell 中用于搜索和匹配文本的cmdlet。它提供了类似于 grep 的功能。现在将两者放在一起做个总结。

在文本搜索方面,Linux 和 PowerShell 提供了各自强大的工具。grep 是 Linux 中用于搜索文本的命令行工具,而 Select-String 是 PowerShell 中用于搜索文本的 cmdlet,功能类似于 grep。
grep(Global Regular Expression Print)用于在 Linux 和其他类 Unix 系统中搜索文本。它可以在一个或多个文件中查找包含指定模式的行,并将匹配的行输出到标准输出。grep 支持正则表达式,提供了多种选项来控制搜索行为和输出格式。
grep 命令的基本格式如下:
grep [OPTIONS] PATTERN [FILE...]
其中,OPTIONS 表示可选的命令行选项,PATTERN 表示要搜索的模式(可以是普通字符串或正则表达式),FILE 表示要搜索的一个或多个文件。如果未指定文件,grep 将从标准输入读取文本。
Select-String 是 PowerShell 中用于搜索和匹配文本的 cmdlet。它提供了类似于 grep 的功能,可以在文件、字符串或管道输入中查找指定的模式。Select-String 支持正则表达式和通配符,并提供了各种参数来控制搜索行为和输出格式。
Select-String 命令的基本格式如下:
Select-String [-Path] <string[]> [-Pattern] <string[]> [-AllMatches] [-CaseSensitive] [-Context <Int32[]>] [-Encoding <string>] [-Exclude <string[]>] [-Include <string[]>] [-List] [-NotMatch] [-Quiet] [-SimpleMatch] [<CommonParameters>]
Select-String -InputObject <psobject> [-Pattern] <string[]> [-AllMatches] [-CaseSensitive] [-Context <Int32[]>] [-Encoding <string>] [-Exclude <string[]>] [-Include <string[]>] [-List] [-NotMatch] [-Quiet] [-SimpleMatch] [<CommonParameters>]
其中:
-Pattern参数指定要搜索的模式(可以是普通字符串或正则表达式);-Path参数指定要搜索的一个或多个文件。
Select-String 还提供了其他参数,如 -SimpleMatch(简单字符串匹配)、-CaseSensitive(区分大小写)、-Quiet(仅返回布尔值)等,用于控制搜索行为和输出格式。
在Linux上,grep命令用于在每个文件中搜索指定的模式。其基本使用格式为:
grep [选项]... 模式 [文件]...
grep命令会在指定的文件中查找匹配的模式,并输出包含该模式的行。如果未指定文件,grep会从标准输入读取数据。
例如,下面的命令在menu.h和main.c文件中搜索不区分大小写的字符串“hello world”:
grep -i 'hello world' menu.h main.c
在这个例子中:
-i选项表示忽略大小写,因此Hello,HELLO,或hello都能匹配模式hello world。'hello world'是要搜索的模式。menu.h和main.c是要搜索的文件。
这条命令会输出包含“hello world”的所有行,无论这些行中的“hello world”是大写、小写还是混合大小写。
其中,模式可以包含多个由换行符分隔的模式。模式选择及其解释如下:
-E, --extended-regexp 模式为扩展正则表达式
-F, --fixed-strings 模式为字符串
-G, --basic-regexp 模式为基本正则表达式
-P, --perl-regexp 模式为Perl正则表达式
-e, --regexp=模式 使用指定的模式进行匹配
-f, --file=文件 从文件中获取模式
-i, --ignore-case 忽略模式和数据中的大小写区别
--no-ignore-case 不忽略大小写区别(默认)
-w, --word-regexp 仅匹配整个单词
-x, --line-regexp 仅匹配整个行
-z, --null-data 数据行以0字节结束,而不是换行符
杂项:
-s, --no-messages 抑制错误消息
-v, --invert-match 选择不匹配的行
-V, --version 显示版本信息并退出
--help 显示此帮助文本并退出
【注】:在接下来的示例中,输出结果中的颜色是由
grep命令自动添加的,用于突出显示匹配的部分。这是grep的一个特性,称为 “颜色输出”。
当在终端中运行grep命令时,它会自动检测是否支持颜色输出,并相应地着色。
可以参考2.4.3小节。
使用-E选项,可以使用扩展正则表达式。
例如,以下命令会在file.txt中搜索匹配任意一个字母后跟一个数字的字符串:
grep -E '[a-zA-Z][0-9]' file.txt
再如,搜索包含一个到三个’a’字符的模式。
echo "aaa abbb aaaa" | grep -E 'a{1,3}'
输出为: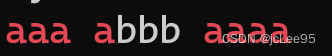
在输出结果 “aaa abbb aaaa” 中:
-
第一部分 “aaa” 匹配正则表达式,因为它包含连续的三个 ‘a’ 字符,所以显示为红色;
-
第二部分 “abbb” 不匹配正则表达式,因为 ‘a’ 后面没有连续的 ‘a’ 字符,所以显示为白色。
-
第三部分 “aaaa” 匹配正则表达式,因为它包含连续的四个 ‘a’ 字符,前三个 ‘a’ 匹配,所以前三个 ‘a’ 显示为红色,剩下的 ‘a’ 显示为白色。
搜索包含确切字符串’a*b’的行。
echo "a*b a b" | grep -F 'a*b'
结果为:
echo "hello" > patterns.txt
echo "world" >> patterns.txt
echo "hello world" | grep -f patterns.txt
echo "Hello WORLD" | grep -i 'hello'
结果为:

echo "hello world
hello universe
goodbye world
hello hello" | grep -v 'hello'
在这个例子中,我们使用 echo 命令生成了一个包含多行文本的字符串,每行文本之间用换行符 \n 分隔。然后,我们使用管道将这个多行文本传递给 grep -v 'hello' 命令。
-v 选项表示 “反转匹配”,即选择不包含指定模式的行。在这里,grep -v 'hello' 会输出所有不包含 “hello” 的行。
输出结果为:
goodbye world
-x 选项用于匹配整行,即只有当整行完全匹配指定的模式时才会被选中。例如:
echo "hello
hello world
world
hello hello" | grep -x 'hello'
输出结果为:
hello
在这个例子中,我们使用 echo 命令生成了一个包含多行文本的字符串,每行文本之间用换行符 \n 分隔。然后,我们使用管道将这个多行文本传递给 grep -x 'hello' 命令。
-x 选项表示 “匹配整行”,即只有当一行文本完全匹配指定的模式时才会被选中。在这里,grep -x 'hello' 会输出完全匹配 “hello” 的行。
其中,只有第 1 行完全匹配 “hello”,所以被选中并输出。其他行虽然包含 “hello”,但并不是完全匹配,所以被过滤掉了。
grep命令中也可以通过下面的选项对输出内容进行控制:
-m, --max-count=NUM 在选择NUM行后停止
-b, --byte-offset 打印输出行的字节偏移量
-n, --line-number 打印输出行的行号
--line-buffered 在每行后刷新输出
-H, --with-filename 打印输出行的文件名
-h, --no-filename 输出时不显示文件名前缀
--label=LABEL 使用LABEL作为标准输入文件名前缀
-o, --only-matching 仅显示匹配的非空部分
-q, --quiet, --silent 抑制所有正常输出
--binary-files=TYPE 假定二进制文件为TYPE;
TYPE可以是'binary'(二进制)、'text'(文本)或'without-match'(无匹配)
-a, --text 等同于--binary-files=text
-I 等同于--binary-files=without-match
-d, --directories=ACTION 如何处理目录;
ACTION可以是'read'(读取)、'recurse'(递归)或'skip'(跳过)
-D, --devices=ACTION 如何处理设备、FIFO和套接字;
ACTION可以是'read'(读取)或'skip'(跳过)
-r, --recursive 等同于--directories=recurse
-R, --dereference-recursive 同样,但跟随所有符号链接
--include=GLOB 仅搜索匹配GLOB(文件模式)的文件
--exclude=GLOB 跳过匹配GLOB的文件
--exclude-from=FILE 跳过匹配FILE中的任何文件模式的文件
--exclude-dir=GLOB 跳过匹配GLOB的目录
-L, --files-without-match 仅打印没有选中行的文件名
-l, --files-with-matches 仅打印有选中行的文件名
-c, --count 每个文件仅打印选中行的计数
-T, --initial-tab 对齐制表符(如有需要)
-Z, --null 在文件名后打印0字节
seq 10 | grep -m 3 -E '[0-9]'
输出结果为:
1
2
3
在这个例子中,我们使用seq命令生成1到10的整数序列,然后通过管道传递给grep -m 3 -E '[0-9]'命令。
-m 3选项表示最多输出匹配的前3行. -E '[0-9]'使用正则表达式匹配所有包含数字的行。
echo "hello world" | grep -b 'world'
输出结果为:
hello world

-b选项会在输出的每一行前面显示该行在原始输入中的字节偏移量。在这个例子中,"world"在输入字符串中的起始字节位置为6。
seq 10 | grep -n -E '[24680]$'
-n选项会在输出的每一行前面显示该行在原始输入中的行号. 在这个例子中,我们匹配所有以偶数结尾的行。输出结果为:
2:2
4:4
6:6
8:8
10:10

上下文控制是指在输出匹配行的同时,也输出匹配行前后的一些行作为上下文,以便更好地理解匹配行在原始文本中的位置和含义。grep提供了一些选项来控制输出的上下文行数和格式。
-B, --before-context=NUM 打印匹配前NUM行的上下文
-A, --after-context=NUM 打印匹配后NUM行的上下文
-C, --context=NUM 打印匹配前后各NUM行的上下文
-NUM 等同于--context=NUM
--group-separator=SEP 在带有上下文的匹配行之间打印分隔符SEP
--no-group-separator 不打印带有上下文的匹配行的分隔符
--color[=WHEN],
--colour[=WHEN] 使用标记突出显示匹配的字符串;
WHEN可以是'always'(总是)、'never'(从不)或'auto'(自动)
-U, --binary 不去除行尾的CR字符(MSDOS/Windows)
seq 10 | grep -A 2 -B 2 '5'
-A 2选项表示输出匹配行后的2行作为上下文;-B 2选项表示输出匹配行前的2行作为上下文;
因此,这个命令会输出匹配行'5'以及它前后各2行。输出结果为:
3
4
5
6
7

seq 10 | grep -C 1 '5'
-C 1选项等同于-A 1 -B 1,表示输出匹配行前后各1行作为上下文。出结果为:
4
5
6

--color=always选项会使用标记突出显示匹配的字符串,以便更容易识别匹配的位置。例如:
echo "Hello World" | grep --color=always 'World'
你可以尝试在终端中运行这个命令,看看’World’是否被高亮显示:

Select-String 是 PowerShell 中用于搜索和匹配文本的cmdlet。它提供了类似于 grep 的功能,可以在文件、字符串或管道输入中查找指定的模式。Select-String 支持正则表达式和通配符,并提供了各种参数来控制搜索行为和输出格式。
Select-String的基本格式如下:
Select-String [-Path] <string[]> [-Pattern] <string[]> [-AllMatches] [-CaseSensitive] [-Context <Int32[]>] [-Encoding <string>] [-Exclude <string[]>] [-Include <string[]>] [-List] [-NotMatch] [-Quiet] [-SimpleMatch] [<CommonParameters>]
Select-String -InputObject <psobject> [-Pattern] <string[]> [-AllMatches] [-CaseSensitive] [-Context <Int32[]>] [-Encoding <string>] [-Exclude <string[]>] [-Include <string[]>] [-List] [-NotMatch] [-Quiet] [-SimpleMatch] [<CommonParameters>]
Select-String -Pattern 'hello' -Path 'file.txt'
在 file.txt 文件中搜索包含 “hello” 的行。
"hello world", "hello universe", "goodbye world" | Select-String -Pattern 'hello'
在给定的字符串数组中搜索包含 “hello” 的行。输出结果为:
通过 -CaseSensitive 选项可以指定是否区分大小写。默认情况下,Select-String 不区分大小写,这意味着它会匹配模式的任何大小写组合。使用 -CaseSensitive 选项可以强制 Select-String 进行区分大小写的匹配。
"Hello world", "hello universe" | Select-String -Pattern 'hello' -CaseSensitive

"hello*world", "hello world" | Select-String -Pattern 'hello*world' -SimpleMatch
通过 -SimpleMatch 选项可以指定 Select-String 进行简单字符串匹配,而不是使用正则表达式。默认情况下,Select-String 会将模式解释为正则表达式。如果你希望进行简单的字符串匹配,可以使用 -SimpleMatch 选项。例如:
"hello*world", "hello world" | Select-String -Pattern 'hello*world' -SimpleMatch
输出结果为:
hello*world
在这个例子中,我们有一个包含两行文本的字符串数组:
-
“hello*world”
-
“hello world”
我们使用管道将这个字符串数组传递给 Select-String 命令,并指定 -Pattern 'hello*world' 和 -SimpleMatch 选项。
-
-Pattern 'hello*world'指定要搜索的模式是 “hello*world”。 -
-SimpleMatch选项指示Select-String进行简单字符串匹配,而不是将模式解释为正则表达式。
由于 -SimpleMatch 选项的作用,Select-String 会将模式 “helloworld" 作为一个普通字符串进行匹配。因此,只有第一行 "helloworld” 会被匹配并输出,因为它完全包含了字符串 “hello*world”。第二行 “hello world” 不会被匹配,因为它不包含星号 *。
通过 -Context 选项可以指定在输出中显示匹配行的前后上下文行。这在需要查看匹配行周围的内容时非常有用。
"line1", "line2 hello", "line3", "line4 hello", "line5" | Select-String -Pattern 'hello' -Context 1,1
输出结果为:
line1
> line2 hello
line3
> line4 hello
line5

在这个例子中,我们有一个包含多行文本的字符串数组:
- “line1”
- “line2 hello”
- “line3”
- “line4 hello”
- “line5”
我们使用管道将这个字符串数组传递给 Select-String 命令,并指定 -Pattern ‘hello’ 和 -Context 1,1 选项。
-Pattern ‘hello’ 指定要搜索的模式是 “hello”。
-Context 1,1 选项指示 Select-String 显示每个匹配行的前一行和后一行。
由于 -Context 1,1 选项的作用,Select-String 会输出包含 “hello” 的行以及每个匹配行的前一行和后一行。
通过 -Pattern 选项可以指定多个模式进行搜索。Select-String 会匹配任意一个指定的模式。
"hello world", "goodbye world" | Select-String -Pattern 'hello', 'goodbye'
搜索结果为:
hello world
goodbye world

在这个例子中,我们有一个包含两行文本的字符串数组: "hello world"和 “goodbye world”。
我们使用管道将这个字符串数组传递给 Select-String 命令,并指定 -Pattern 'hello', 'goodbye' 选项。
-Pattern 'hello', 'goodbye'指定要搜索的模式是 “hello” 或 “goodbye”。
由于 -Pattern 选项的作用,Select-String 会输出包含 “hello” 或 “goodbye” 的行。
通过 -List 选项可以指定 Select-String 只返回每个输入中的第一个匹配项。这在你只关心第一个匹配结果时非常有用。
假设我们有两个文件 file1.txt 和 file2.txt,它们的内容如下:
file1.txt:
hello world
hello universe
file2.txt:
goodbye world
hello again
我们可以使用以下命令来搜索这两个文件,并只返回每个文件中的第一个匹配项:
Select-String -Pattern 'hello' -Path 'file1.txt', 'file2.txt' -List
输出结果为:
file1.txt:1:hello world
file2.txt:2:hello again

在这个例子中,Select-String 搜索 file1.txt 和 file2.txt 中包含 “hello” 的行,并使用 -List 选项只返回每个文件中的第一个匹配项。
Select-String -Pattern 'hello' -Path 'file.txt' -Encoding UTF8
在这个例子中,我们在名为 file.txt 的文件中搜索包含 “hello” 的行,并指定文件的编码为 UTF8。
-
-Pattern 'hello'指定要搜索的模式是 “hello”。 -
-Path 'file.txt'指定要搜索的文件是 file.txt。 -
-Encoding UTF8选项指示 Select-String 使用 UTF8 编码来读取文件。
假设 file.txt 的内容如下:
hello world
goodbye world
运行上述命令的输出结果为:
file.txt:1:hello world

这个例子展示了如何使用 -Encoding 选项来在指定编码的文件中搜索。在处理不同编码的文件时,这可以确保 Select-String 正确读取文件内容并进行搜索。

- 点赞
- 收藏
- 关注作者
评论(0)