Linux 虚拟网络隧道技术 VXLAN 认知

写在前面
-
博文内容为 Linux 网络隧道技术 VXLAN认知,内容涉及: -
vxlan协议介绍 -
vxlan基本配置命令 -
基于命名空间的组网实践 -
自维护 VTEP组介绍 -
篇幅较长,小伙伴可直接跳到第三部分看实验 -
基于 《 Kubernetes 网络权威指南:基础、原理与实践》vxlan部分整理 -
理解不足小伙伴帮忙指正
不必太纠结于当下,也不必太忧虑未来,当你经历过一些事情的时候,眼前的风景已经和从前不一样了。——村上春树
vxlan 协议介绍
当我们在构建网络时,有时候需要将多个物理网络连接在一起,形成一个虚拟的网络。但是,物理网络之间的连接受到一些限制,比如距离、设备数量等。这时候,我们可以使用一种叫做 VXLAN 的技术。
VXLAN :虚拟扩展局域网(Virtual Extensible LAN)是一种虚拟化隧道通信技术,它可以帮助我们在不同的物理网络间构建一个虚拟的网络。它的实现方式是通过在原有的数据包上添加一些额外的信息,将数据包封装起来,然后在不同的物理网络之间传输。
具体来说,VXLAN 在原始数据包的上层添加了一个特殊的头部,其中包含一个标识虚拟网络的编号。这个编号叫做 VNI(Virtual Network Identifier),可以将不同的虚拟网络区分开来。当一个数据包从源物理网络传输到目标物理网络时,VXLAN 头部会被保留,这样目标网络就知道这个数据包属于哪个虚拟网络,并将其正确地传递给目标设备。
通过使用 VXLAN,我们可以在底层的物理网络之上创建出一个虚拟的网络,就好像它们连接在同一个局域网上一样。这样,我们就可以更方便地管理和扩展网络,而不需要受到物理网络的限制。
VXLAN 是一种overlay(覆盖网络)技术,即在三层的网络搭建虚拟的二层网络。RFC7348中是这样介绍 VXLAN 的:
A framework for overlaying virtualized layer 2 networks over lay 3 networks.
VXLAN 是在底层物理网络(underlay)之上使用隧道技术,依托UDP层(3 层)构建的 overlay 的逻辑网络,使逻辑网络与物理网络解耦,实现灵活的组网需求。不仅能适配虚拟机环境,还能用于容器环境。
VXLAN这类隧道网络的一个特点是对原有的网络架构影响小,不需要对原网络做任何改动,就可在原网络的基础上架设一层新的网络。
不同于其他隧道协议,VXLAN是一个一对多的网络,并不仅是一对一的隧道协议。
一个VXLAN设备能通过像网桥一样的学习方式学习到其他对端的IP地址,也可以直接配置 静态转发表。
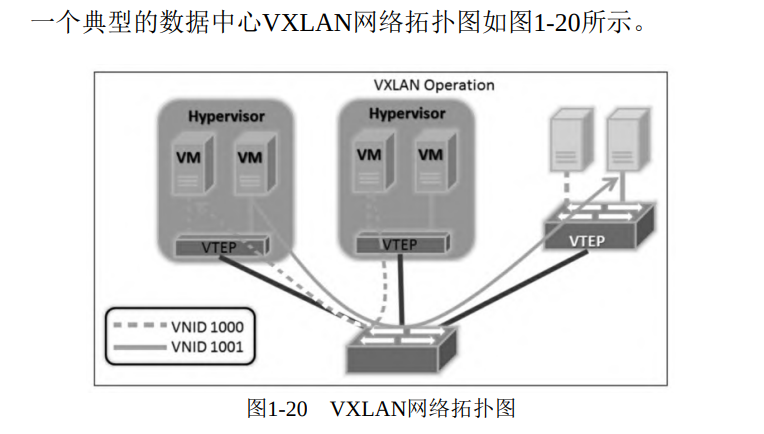
VM指的是虚拟机,Hypervisor指的是节点的虚拟机管理器。VXLAN不仅能用在基于虚拟机的虚拟化系统中,还被广泛应用于容器集群。
为什么需要 VXLAN
VLAN技术的缺陷是VLAN Header预留的长度只有12 bit,限制了 VLAN 的子网划分数量,故最多只能支持 2 的 12 次方(4096)子网的划分,无法满足云计算场景下主机数量日益增长的需求。
VXLAN 能突破 VLAN 的最多 4096 个子网的数量限制,以满足大规模云计算数据中心的需求。具体来说,VXLAN 技术解决以下几个问题:
-
当前 VXLAN的报文 Header 内有24 bit,可以支持2的24次方个子网,并通过VNI(Virtual Network Identifier)区分不同的子网,相当于VLAN中的LAN ID; -
多租户网络隔离 -
虚拟机可能会大规模迁移, 并保证网络一直可用,也就是大二层的概念
VXLAN 协议原理简介
VXLAN 隧道网络方案相比改造传统的二层或三层网络,对原有的网络架构影响小。隧道网络不需要原来的网络做任何改动,可直接在原来的网络基础上架设一层新的网络。
VXLAN 的工作模型,它创建在原来的 IP 网络(三层)上,只要是三层可达(能够通过 IP 互相通信)的网络就能部署 VXLAN。
在 VXLAN 网络的每个端点都有一个 VTEP 设备,负责 VXLAN 协议报文的封包和解包,也就是在虚拟报文上封装VTEP 通信的报文头部。
物理网络上可以创建多个 VXLAN 网络,可以将这些 VXLAN 网络看作一个隧道,不同节点上的虚拟机/容器能够通过隧道直连。通过VNI标识不同的VXLAN网络,使得不同的VXLAN可以相互隔离。
VXLAN的几个重要概念如下:
VTEP(VXLAN Tunnel Endpoints):VXLAN 网络的边缘设备,用来进行VXLAN报文的处理(封包和解包)。VTEP可以是网络设备(例如交换机),也可以是一台机器(例如虚拟化集群中的宿主机);
VNI(VXLAN Network Identifier):VNI 是每个 VXLAN 的标识,是个 24 位整数,因此最大值是 2^24=16777216。如果一个VNI对应一个租户,那么理论上 VXLAN 可以支撑千万级别的租户。
tunnel:隧道是一个逻辑上的概念,在 VXLAN 模型中并没有具体的物理实体相对应。隧道可以看作一种虚拟通道,VXLAN 通信双方(图中的虚拟机)都认为自己在直接通信,并不知道底层网络的存在。从整体看,每个 VXLAN 网络像是为通信的虚拟机搭建了一个单独的通信通道,也就是隧道。

VXLAN其实是在三层网络上构建出来的一个二层网络的隧道。**VNI 相同的机器逻辑上处于同一个二层网络中**。VXLAN 封包格式如图
+----------------------------------------------------+
| Ethernet Frame |
+----------------------------------------------------+
| Destination MAC Address |
| Source MAC Address |
| Ethernet Type (IPv4/IPv6) |
+----------------------------------------------------+
| IP Packet Header |
+----------------------------------------------------+
| Version | IHL | DSCP | ECN |
| Total Length |
| Identification |
| Flags | Fragment Offset |
| Time to Live (TTL) |
| Protocol |
| Header Checksum |
| Source IP Address |
| Destination IP Address |
+----------------------------------------------------+
| UDP Header |
+----------------------------------------------------+
| Source Port |
| Destination Port |
| Length |
| Checksum |
+----------------------------------------------------+
| VXLAN Header |
+----------------------------------------------------+
| Flags | Reserved | VNI |
+----------------------------------------------------+
| |
| Original Ethernet Frame |
| |
+----------------------------------------------------+
VXLAN的报文就是MAC in UDP,即在三层网络的基础上构建一个虚拟的二层网络。
VXLAN 的报文封装过程如下:
原始二层以太网帧:VXLAN 的封包格式显示把原始二层以太网帧(目标 MAC 地址、源 MAC 地址、以太网类型(如 IPv4 或 IPv6)以及数据负载)封装在 VXLAN 头部中
VXLAN封装: VXLAN 头部包含以下字段:
-
VNI(Virtual Network Identifier):用于标识虚拟二层网络的唯一标识符,通常是一个 24 位的标识符。 -
Reserved:保留字段,设置为 0。 -
VXLAN标志:指示是否启用 VXLAN 特性,通常设置为 1。
将原始二层以太网帧放置在VXLAN头部之后,形成VXLAN封装的报文
UDP封装:将 VXLAN 封装的报文再次封装在 UDP 数据报中。UDP头部包含以下字段:
-
源端口号:用于标识发送方的端口号。 -
目标端口号:用于标识接收方的端口号。 -
长度:指示 UDP 数据报的长度。 -
校验和:用于验证 UDP 数据报的完整性。
将 VXLAN 封装的报文放置在 UDP 数据报的数据部分。
IP封装:最后,将 UDP 封装的报文再次封装在 IP 数据报中。IP 头部包含以下字段:
-
源 IP 地址:标识发送方的 IP 地址。 -
目标 IP 地址:标识接收方的 IP 地址。 -
协议:指示上层协议为 UDP。 -
长度:指示 IP 数据报的长度。 -
校验和:用于验证 IP 数据报的完整性。
将 UDP 封装的报文放置在 IP 数据报的数据部分。
网络传输:最终,将 IP 封装的报文通过底层网络进行传输。底层网络可以是物理网络、虚拟网络或云服务提供商的网络基础设施。
报文的封装过程是将
原始的二层以太网帧放置在VXLAN头部内,然后将VXLAN封装的报文再次封装在UDP数据报中,最后再放置在IP数据报中进行传输。接收方在接收到报文后,按照相反的顺序进行解封装,将报文逐层还原为原始的二层以太网帧。
VXLAN 报文比原始报文多出了 50 个字节,包括
-
8个字节的 VXLAN 协议相关的部分, -
8个字节的 UDP 头部 -
20个字节的 IP 头部 -
14个字节的 MAC 头部
UDP目的端口是接收方VTEP设备使用的端口, IANA(Internet Assigned Numbers Authority,互联网号码分配局)分配了 4789 作为 VXLAN 的目的 UDP 端口。
VXLAN 的配置管理使用iproute2包,这个工具是和 VXLAN 一起合入内核的,我们常用的 ip 命令就是 iproute2 的客户端工具。
VXLAN 要求 Linux 内核版本在3.7以上,最好为3.9以上,所以在一些旧版本的 Linux 上无法使用基于 VXLAN 的封包技术。
VXLAN 组网必要信息
VXLAN 报文的转发过程:
发送方封装:原始报文经过VTEP,被Linux内核添加上VXLAN包头及外层的UDP头部,形成完整的 vxlan 报文,再发送出去。
接收方接收:对端 VTEP 接收到 VXLAN 报文后拆除外层 UDP头部,并根据VXLAN头部的VNI把原始报文发送到目的服务器。
解析VNI:在解封装后,接收方从 VXLAN 头部中读取 VNI(Virtual Network Identifier)。VNI 用于标识虚拟二层网络,指示报文应该被转发到哪个虚拟二层网络中的目标。
根据VNI进行转发:接收方使用 VNI 作为关键信息,通过查找本地的VXLAN转发表或VXLAN控制平面,确定报文应该转发到哪个虚拟二层网络中的目标主机。
封装为原始二层以太网帧:接收方根据目标主机的 MAC 地址和 VXLAN 报文的内容,将报文封装为原始的二层以太网帧。
目标主机交付:接收方将封装的原始二层以太网帧交付给目标主机上的网络栈,进一步处理或交给目标容器或应用程序进行处理。
上面通信的前提是通信双方已经知道所有通信信息
-
哪些 VTEP需要加到一个相同的VNI组?VTEP通常由网络管理员进行配置 -
发送方如何知道对方的 MAC地址? -
VXLAN网络的通信双方如何感知彼此并选择正确的路径传输报文?
完整的 VXLAN 报文需要哪些信息
内层报文:通信双方的 IP 地址已经明确,需要VXLAN填充的是对方的MAC地址,VXLAN 需要一个机制来实现ARP的功能;
VXLAN 头部:只需要知道VNI。它一般是直接配置在VTEP上的,即要么是提前规划的,要么是根据内部报文自动生成的;
UDP 头部:最重要的是源地址和目的地址的端口,源地址端口是由系统生成并管理的,目的端口一般固定为IANA分配的4789端口
IP 头部:IP 头部关心的是对端 VTEP 的 IP 地址,源地址可以用很简单的方式确定,目的地址是虚拟机所在地址宿主机 VTEP 的 IP 地址,需要由某种方式来确定;
MAC 头部:确定了 VTEP 的 IP 地址,MAC 地址可以通过经典的 ARP 方式获取,毕竟 VTEP 在同一个三层网络内
一个VXLAN报文需要确定两个地址信息:
-
内层报文(对应目的虚拟机/容器)的 MAC地址 -
外层报文(对应目的虚拟机/容器所在宿主机上的 VTEP) IP地址。
如果VNI也是动态感知的,那么VXLAN一共需要知道三个信息:内部MAC、VTEP IP和VNI。
一般有两种方式获得以上VXLAN网络的必要信息:
-
多播:同一个VXLAN网络的VTEP加入同一个多播网络 -
控制中心:某个集中式的地方保存所有虚拟机的上述信息,自动告知VTEP它需要的信息即可
VXLAN 基本配置命令
VXLAN 接口的基本管理
创建 VXLAN 接口
liruilonger@cloudshell:~$ sudo ip link add vxlan0 type vxlan id 42 group 239.1.1.1 dev eth0 dstport 4789
liruilonger@cloudshell:~$ ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 26:e2:b4:04:7f:71 brd ff:ff:ff:ff:ff:ff link-netnsid 0
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 02:42:ea:90:45:48 brd ff:ff:ff:ff:ff:ff
4: vxlan0: <BROADCAST,MULTICAST> mtu 1450 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 96:cc:e1:a9:24:94 brd ff:ff:ff:ff:ff:ff
-
ip link add vxlan0 type vxlan id 42: 这部分命令用于创建一个名为vxlan0的VXLAN接口,并分配一个 ID 为 42 的 VXLAN 网络标识符。 -
group 239.1.1.1: 这部分命令指定了VXLAN组播组的 IP 地址,也就是用于广播 VXLAN 数据包的组播地址。 -
dev eth0: 这部分命令指定了底层网络接口,也就是将 VXLAN 流量封装在其中的物理网络接口,这里是eth0。 -
dstport 4789: 这部分命令指定了VXLAN流量使用的目标端口号,通常使用 UDP 端口4789。
删除 vxlan 接口
liruilonger@cloudshell:~$ sudo ip link delete vxlan0
liruilonger@cloudshell:~$ ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 26:e2:b4:04:7f:71 brd ff:ff:ff:ff:ff:ff link-netnsid 0
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 02:42:ea:90:45:48 brd ff:ff:ff:ff:ff:ff
在VXLAN中,一般将 VXLAN 接口(在我们的例子中即vxlan0)叫作VTEP(VXLAN tunnel endpoint),VXLAN 子网的报文需要从 VTEP 出去。
多播组主要通过 ARP 洪泛来学习 MAC 地址,即在 VXLAN 子网内广播 ARP 请求
查看 VXLAN 接口信息
liruilonger@cloudshell:~$ sudo ip link add vxlan0 type vxlan id 42 group 239.1.1.1 dev eth0 dstport 4789
liruilonger@cloudshell:~$ ip -d link show vxlan0
5: vxlan0: <BROADCAST,MULTICAST> mtu 1450 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 42:3f:2f:d0:4c:7a brd ff:ff:ff:ff:ff:ff promiscuity 0 minmtu 68 maxmtu 65535
vxlan id 42 group 239.1.1.1 dev eth0 srcport 0 0 dstport 4789 ttl auto ageing 300 udpcsum noudp6zerocsumtx noudp6zerocsumrx addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
VXLAN 转发表,可以使用 bridge 命令创建、删除或查看 VXLAN 接口的转发表 fdb。
liruilonger@cloudshell:~$ sudo bridge fdb add to 02:42:ea:90:45:48 dst 192.168.0.2 dev vxlan0
02:42:ea:90:45:48 即对端 VTEP 的 MAC 地址,192.19.0.2 即对端 VTEP 的 IP 地址。
liruilonger@cloudshell:~$ sudo bridge fdb delete 02:42:ea:90:45:48 dev vxlan0
删除一条转发表项
liruilonger@cloudshell:~$ sudo bridge fdb add to 02:42:ea:90:45:48 dst 192.168.0.2 dev vxlan0
查看 VXLAN 接口的转发表:
liruilonger@cloudshell:~$ bridge fdb show dev vxlan0
00:00:00:00:00:00 dst 239.1.1.1 via eth0 self permanent
02:42:ea:90:45:48 dst 192.168.0.2 self permanent
liruilonger@cloudshell:~$
FDB 表是什么?
网络设备都以 MAC 地址唯一地标识自己,而交换机要实现设备之间的通信就必须知道自己的哪个端口连接着哪台设备,因此就需要一张 MAC 地址与端口号一一对应的表,以便在交换机内部实现二层数据转发。这张二层转发表就是 FDB 表,它主要由 MAC 地址、VLAN 号、端口号和一些标志域等信息组成。如果收到数据帧的目的 MAC 地址不在 FDB 地址表中,那么该数据将被广播给除源端口外,该数据包所属 VLAN 中的其他所有端口。把数据发给其他所有端口的行为称为洪泛。
VXLAN 网络实践
点对点的 VXLAN
从最简单的点对点的 VXLAN 网络说起。点对点 VXLAN 即两台机器构成一个 VXLAN 网络,每台机器上有一个 VTEP,VTEP 之间通过它们的 IP 地址进行通信。点对点 VXLAN 网络拓扑如图
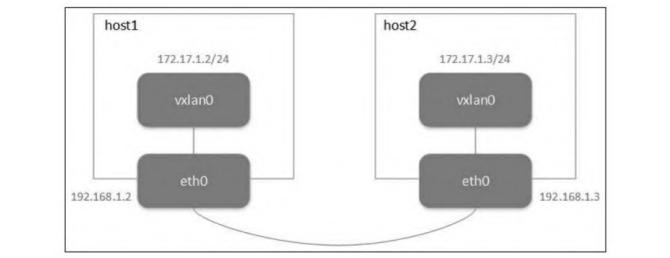 在这里插入图片描述
在这里插入图片描述
只有一个机器,这里我们使用两个 Linux netowrk namespace node1,node2 来模拟
liruilonger@cloudshell:~$ sudo ip netns add node1
liruilonger@cloudshell:~$ sudo ip netns add node2
liruilonger@cloudshell:~$ ip netns list
node2
node1
创建两个 网络命名空间,使用 veth pair 来建立通信,配置 IP ,两个命名空间都开启 ipv4 转发,ping 测试
liruilonger@cloudshell:~$ sudo ip link add veth1 netns node1 type veth peer name veth2 netns node2
liruilonger@cloudshell:~$ sudo ip netns exec node1 ip addr add 192.168.1.2/24 dev veth1
liruilonger@cloudshell:~$ sudo ip netns exec node2 ip addr add 192.168.1.3/24 dev veth2
liruilonger@cloudshell:~$ sudo ip netns exec node1 ip link set dev veth1 up
liruilonger@cloudshell:~$ sudo ip netns exec node2 ip link set dev veth2 up
liruilonger@cloudshell:~$ sudo ip netns exec node1 sysctl -w net.ipv4.ip_forward=1
net.ipv4.ip_forward = 1
liruilonger@cloudshell:~$ sudo ip netns exec node2 sysctl -w net.ipv4.ip_forward=1
net.ipv4.ip_forward = 1
liruilonger@cloudshell:~$ sudo ip netns exec node1 ping -c 3 192.168.1.3
PING 192.168.1.3 (192.168.1.3) 56(84) bytes of data.
64 bytes from 192.168.1.3: icmp_seq=1 ttl=64 time=0.066 ms
64 bytes from 192.168.1.3: icmp_seq=2 ttl=64 time=0.047 ms
64 bytes from 192.168.1.3: icmp_seq=3 ttl=64 time=0.038 ms
--- 192.168.1.3 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2088ms
rtt min/avg/max/mdev = 0.038/0.050/0.066/0.011 ms
liruilonger@cloudshell:~$
模拟好了环境,在 node1 命名空间 使用ip link命令创建VXLAN接口
liruilonger@cloudshell:~$ sudo ip netns exec node1 ip link add vxlan0 type vxlan id 42 dstport 4789 remote 192.168.1.3 local 192.168.1.2 dev veth1
liruilonger@cloudshell:~$ sudo ip netns exec node1 ip -d link show dev veth1
2: veth1@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether ea:d1:4d:8c:c0:9a brd ff:ff:ff:ff:ff:ff link-netns node2 promiscuity 0 minmtu 68 maxmtu 65535
veth addrgenmode eui64 numtxqueues 2 numrxqueues 2 gso_max_size 65536 gso_max_segs 65535
在名为 node1 的网络命名空间中创建了一个名为 vxlan0 的 VXLAN 接口。
-
它使用 VXLAN 标识 VID 42, -
目标端口号为 4789, -
并设置了远程端点的 IP 地址为 192.168.1.3 -
本地端点的 IP 地址为 192.168.1.2 -
该 VXLAN 接口使用 veth1作为底层网络接口
查看它的详细信息
liruilonger@cloudshell:~$ sudo ip netns exec node1 ip -d link show dev vxlan0
3: vxlan0: <BROADCAST,MULTICAST> mtu 1450 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether c6:b1:87:67:d9:e4 brd ff:ff:ff:ff:ff:ff promiscuity 0 minmtu 68 maxmtu 65535
vxlan id 42 remote 192.168.1.3 local 192.168.1.2 dev veth1 srcport 0 0 dstport 4789 ttl auto ageing 300 udpcsum noudp6zerocsumtx noudp6zerocsumrx addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
为刚创建的VXLAN网卡配置IP地址并启用它
liruilonger@cloudshell:~$ sudo ip netns exec node1 ip addr add 172.17.1.2/24 dev vxlan0
liruilonger@cloudshell:~$ sudo ip netns exec node1 ip link set vxlan0 up
执行成功后会发现路由表项多了下面的内容,所有目的地址是 172.17.1.0/24 网段的包要通过 vxlan0 转发
liruilonger@cloudshell:~$ sudo ip netns exec node1 ip route
172.17.1.0/24 dev vxlan0 proto kernel scope link src 172.17.1.2
192.168.1.0/24 dev veth1 proto kernel scope link src 192.168.1.2
vxlan0 的 FDB 表项中的内容如下
liruilonger@cloudshell:~$ sudo ip netns exec node1 bridge fdb
33:33:00:00:00:01 dev veth1 self permanent
01:00:5e:00:00:01 dev veth1 self permanent
33:33:ff:8c:c0:9a dev veth1 self permanent
00:00:00:00:00:00 dev vxlan0 dst 192.168.1.3 via veth1 self permanent
默认的VTEP对端地址为192.168.1.3。换句话说,原始报文经过vxlan0后会被内核添加上VXLAN头部,而外部UDP头的目的 IP 地址会被冠上192.168.1.3。这里的IP地址即为我们上面的配置的 远程端点 的 IP
在另一个命名空间也进行相同的配置,配置项这里不做说明
liruilonger@cloudshell:~$ sudo ip netns exec node2 bash
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link add vxlan0 type vxlan id 42 dstport 4789 remote 192.168.1.2 local 192.168.1.3 dev veth2
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip -d link show dev vxlan0
3: vxlan0: <BROADCAST,MULTICAST> mtu 1450 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 5a:46:75:cd:ce:9e brd ff:ff:ff:ff:ff:ff promiscuity 0 minmtu 68 maxmtu 65535
vxlan id 42 remote 192.168.1.2 local 192.168.1.3 dev veth2 srcport 0 0 dstport 4789 ttl auto ageing 300 udpcsum noudp6zerocsumtx noudp6zerocsumrx addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip addr add 172.17.1.3/24 dev vxlan0
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link set vxlan0 up
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip route
172.17.1.0/24 dev vxlan0 proto kernel scope link src 172.17.1.3
192.168.1.0/24 dev veth2 proto kernel scope link src 192.168.1.3
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# bridge fdb
33:33:00:00:00:01 dev veth2 self permanent
01:00:5e:00:00:01 dev veth2 self permanent
33:33:ff:6d:21:bb dev veth2 self permanent
00:00:00:00:00:00 dev vxlan0 dst 192.168.1.2 via veth2 self permanent
测试两个命名空间中 veth 对应的 VTEP 内的 vxlan 设备的连通性
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ping -c 3 172.17.1.2
PING 172.17.1.2 (172.17.1.2) 56(84) bytes of data.
64 bytes from 172.17.1.2: icmp_seq=1 ttl=64 time=0.088 ms
64 bytes from 172.17.1.2: icmp_seq=2 ttl=64 time=0.062 ms
64 bytes from 172.17.1.2: icmp_seq=3 ttl=64 time=0.063 ms
--- 172.17.1.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2035ms
rtt min/avg/max/mdev = 0.062/0.071/0.088/0.012 ms
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger#
上面即为点对点组网模型 VXLAN 网络
抓包测试:
node1 上发起 ping
liruilonger@cloudshell:~$ sudo ip netns exec node1 bash
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ping -c 5 172.17.1.3
PING 172.17.1.3 (172.17.1.3) 56(84) bytes of data.
64 bytes from 172.17.1.3: icmp_seq=1 ttl=64 time=0.053 ms
64 bytes from 172.17.1.3: icmp_seq=2 ttl=64 time=0.058 ms
64 bytes from 172.17.1.3: icmp_seq=3 ttl=64 time=0.059 ms
64 bytes from 172.17.1.3: icmp_seq=4 ttl=64 time=0.064 ms
64 bytes from 172.17.1.3: icmp_seq=5 ttl=64 time=0.065 ms
--- 172.17.1.3 ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4115ms
rtt min/avg/max/mdev = 0.053/0.059/0.065/0.004 ms
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger#
查看 node2 上配置的 vxlan 设备信息
liruilonger@cloudshell:~$ sudo ip netns exec node2 bash
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: veth2@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 46:26:8c:6d:21:bb brd ff:ff:ff:ff:ff:ff link-netns node1
inet 192.168.1.3/24 scope global veth2
valid_lft forever preferred_lft forever
inet6 fe80::4426:8cff:fe6d:21bb/64 scope link
valid_lft forever preferred_lft forever
3: vxlan0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether 5a:46:75:cd:ce:9e brd ff:ff:ff:ff:ff:ff
inet 172.17.1.3/24 scope global vxlan0
valid_lft forever preferred_lft forever
inet6 fe80::5846:75ff:fecd:ce9e/64 scope link
valid_lft forever preferred_lft forever
指定对应的设备信息抓包
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# tcpdump -i vxlan0
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on vxlan0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
^C07:40:51.689496 IP6 fe80::5846:75ff:fecd:ce9e > ff02::2: ICMP6, router solicitation, length 16
07:40:56.278116 IP 172.17.1.2 > 172.17.1.3: ICMP echo request, id 7030, seq 1, length 64
07:40:56.278143 IP 172.17.1.3 > 172.17.1.2: ICMP echo reply, id 7030, seq 1, length 64
07:40:57.321585 IP 172.17.1.2 > 172.17.1.3: ICMP echo request, id 7030, seq 2, length 64
07:40:57.321610 IP 172.17.1.3 > 172.17.1.2: ICMP echo reply, id 7030, seq 2, length 64
07:40:58.345557 IP 172.17.1.2 > 172.17.1.3: ICMP echo request, id 7030, seq 3, length 64
07:40:58.345582 IP 172.17.1.3 > 172.17.1.2: ICMP echo reply, id 7030, seq 3, length 64
07:40:59.369546 IP 172.17.1.2 > 172.17.1.3: ICMP echo request, id 7030, seq 4, length 64
07:40:59.369575 IP 172.17.1.3 > 172.17.1.2: ICMP echo reply, id 7030, seq 4, length 64
07:41:00.393571 IP 172.17.1.2 > 172.17.1.3: ICMP echo request, id 7030, seq 5, length 64
07:41:00.393600 IP 172.17.1.3 > 172.17.1.2: ICMP echo reply, id 7030, seq 5, length 64
07:41:01.417503 ARP, Request who-has 172.17.1.2 tell 172.17.1.3, length 28
07:41:01.417543 ARP, Request who-has 172.17.1.3 tell 172.17.1.2, length 28
07:41:01.417599 ARP, Reply 172.17.1.3 is-at 5a:46:75:cd:ce:9e (oui Unknown), length 28
07:41:01.417594 ARP, Reply 172.17.1.2 is-at c6:b1:87:67:d9:e4 (oui Unknown), length 28
15 packets captured
15 packets received by filter
0 packets dropped by kernel
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger#
通过 VXLAN 隧道,成功地在 node1 和 node2 网络命名空间之间建立了通信,并且可以通过 vxlan0 接口进行数据传输。(这里发现一个问题,但是没有找到原因,APR 请求在 ICMP 之后,正常应该先ARP 然后在 ICMP)
多播的情况
要组成同一个VXLAN网络,VTEP必须能感知到彼此的存在。多播组本来的功能就是把网络中的某些节点组成一个虚拟的组,所以 VXLAN最初想到用多播来实现是很自然的事情
这时候我们创建 vxlan1 ,任然在上一个实验的两个网络命名空间中
liruilonger@cloudshell:~$ sudo ip netns exec node1 bash
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link add vxlan1 type vxlan id 43 dstport 4789 local 192.168.1.2 group 224.1.1.1 dev veth1
-
type vxlan:指定创建的接口类型为VXLAN。 -
id 43:设置 VXLAN 网络标识符(VNI)为 43,用于标识 VXLAN 网络中的特定子网。 -
dstport 4789:指定 VXLAN 数据包在传输时使用的目标端口号。 -
local 192.168.1.2:设置本地端点的 IP 地址为 192.168.1.2,表示该主机是 VXLAN 的一部分。 -
group 224.1.1.1:指定多播组地址,用于 VXLAN 的数据包传输。 -
dev veth1:指定 VXLAN 接口的底层物理接口为 veth1。
主机之间不是点对点的连接,而是通过多播组成一个虚拟的整体。group 224.1.1.1,它表示将 VTEP 加入一个多播组,多播地址是 224.1.1.1。
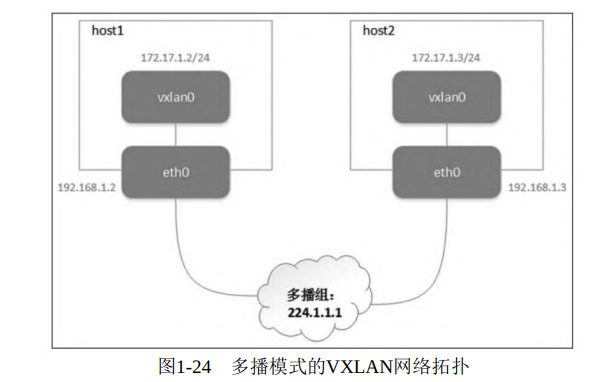 在这里插入图片描述
在这里插入图片描述
和点对点模型相比就多了 group 参数,刚创建的 VXLAN 网卡配置 IP 地址并启用它
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip addr add 172.17.2.2/24 dev vxlan1
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link set vxlan1 up
一样添加了 vxlan1 的路由信息
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip route
172.17.1.0/24 dev vxlan0 proto kernel scope link src 172.17.1.2
172.17.2.0/24 dev vxlan1 proto kernel scope link src 172.17.2.2
192.168.1.0/24 dev veth1 proto kernel scope link src 192.168.1.2
不同的是 FDB 表项的内容
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# bridge fdb
33:33:00:00:00:01 dev veth1 self permanent
01:00:5e:00:00:01 dev veth1 self permanent
33:33:ff:8c:c0:9a dev veth1 self permanent
01:00:5e:01:01:01 dev veth1 self permanent
00:00:00:00:00:00 dev vxlan0 dst 192.168.1.3 via veth1 self permanent
00:00:00:00:00:00 dev vxlan1 dst 224.1.1.1 via veth1 self permanent
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger#
dst字段的值变成了多播地址224.1.1.1,而不是之前对方的VTEP地址,意思是原始报文经过vxlan1后被内核添加上 VXLAN 头部,其外部 UDP 头的目的 IP 地址会被冠上多播地址224.1.1.1。
另一个命名空间做相同的配置
liruilonger@cloudshell:~$ sudo ip netns exec node2 bash
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link add vxlan1 type vxlan id 43 dstport 4789 local 192.168.1.3 group 224.1.1.1 dev veth2
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip addr add 172.17.2.3/24 dev vxlan1
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link set vxlan1 up
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip route
172.17.1.0/24 dev vxlan0 proto kernel scope link src 172.17.1.3
172.17.2.0/24 dev vxlan1 proto kernel scope link src 172.17.2.3
192.168.1.0/24 dev veth2 proto kernel scope link src 192.168.1.3
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# bridge fdb
33:33:00:00:00:01 dev veth2 self permanent
01:00:5e:00:00:01 dev veth2 self permanent
33:33:ff:6d:21:bb dev veth2 self permanent
01:00:5e:01:01:01 dev veth2 self permanent
00:00:00:00:00:00 dev vxlan0 dst 192.168.1.2 via veth2 self permanent
00:00:00:00:00:00 dev vxlan1 dst 224.1.1.1 via veth2 self permanent
对 vxlan1 对应的 ip 做 ping 测试
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ping -c 3 172.17.2.2
PING 172.17.2.2 (172.17.2.2) 56(84) bytes of data.
64 bytes from 172.17.2.2: icmp_seq=1 ttl=64 time=0.080 ms
64 bytes from 172.17.2.2: icmp_seq=2 ttl=64 time=0.058 ms
64 bytes from 172.17.2.2: icmp_seq=3 ttl=64 time=0.059 ms
--- 172.17.2.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2035ms
rtt min/avg/max/mdev = 0.058/0.065/0.080/0.010 ms
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger#
抓包测试
node2 命名空间发起 ping 测
liruilonger@cloudshell:~$ sudo ip netns exec node2 bash
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: veth2@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 46:26:8c:6d:21:bb brd ff:ff:ff:ff:ff:ff link-netns node1
inet 192.168.1.3/24 scope global veth2
valid_lft forever preferred_lft forever
inet6 fe80::4426:8cff:fe6d:21bb/64 scope link
valid_lft forever preferred_lft forever
3: vxlan0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether 5a:46:75:cd:ce:9e brd ff:ff:ff:ff:ff:ff
inet 172.17.1.3/24 scope global vxlan0
valid_lft forever preferred_lft forever
inet6 fe80::5846:75ff:fecd:ce9e/64 scope link
valid_lft forever preferred_lft forever
4: vxlan1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether 0a:5f:67:a1:21:c0 brd ff:ff:ff:ff:ff:ff
inet 172.17.2.3/24 scope global vxlan1
valid_lft forever preferred_lft forever
inet6 fe80::85f:67ff:fea1:21c0/64 scope link
valid_lft forever preferred_lft forever
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ping -c 5 172.17.2.2
PING 172.17.2.2 (172.17.2.2) 56(84) bytes of data.
64 bytes from 172.17.2.2: icmp_seq=1 ttl=64 time=0.084 ms
64 bytes from 172.17.2.2: icmp_seq=2 ttl=64 time=0.063 ms
64 bytes from 172.17.2.2: icmp_seq=3 ttl=64 time=0.064 ms
64 bytes from 172.17.2.2: icmp_seq=4 ttl=64 time=0.061 ms
64 bytes from 172.17.2.2: icmp_seq=5 ttl=64 time=0.061 ms
--- 172.17.2.2 ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4101ms
rtt min/avg/max/mdev = 0.061/0.066/0.084/0.008 ms
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger#
在 node1 上面抓包
liruilonger@cloudshell:~$ sudo ip netns exec node1 bash
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: veth1@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether ea:d1:4d:8c:c0:9a brd ff:ff:ff:ff:ff:ff link-netns node2
inet 192.168.1.2/24 scope global veth1
valid_lft forever preferred_lft forever
inet6 fe80::e8d1:4dff:fe8c:c09a/64 scope link
valid_lft forever preferred_lft forever
3: vxlan0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether c6:b1:87:67:d9:e4 brd ff:ff:ff:ff:ff:ff
inet 172.17.1.2/24 scope global vxlan0
valid_lft forever preferred_lft forever
inet6 fe80::c4b1:87ff:fe67:d9e4/64 scope link
valid_lft forever preferred_lft forever
4: vxlan1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether 4e:fa:e8:b9:51:3a brd ff:ff:ff:ff:ff:ff
inet 172.17.2.2/24 scope global vxlan1
valid_lft forever preferred_lft forever
inet6 fe80::4cfa:e8ff:feb9:513a/64 scope link
valid_lft forever preferred_lft forever
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# tcpdump -i vxlan1
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on vxlan1, link-type EN10MB (Ethernet), snapshot length 262144 bytes
^C07:58:03.620275 IP 172.17.2.3 > 172.17.2.2: ICMP echo request, id 13998, seq 1, length 64
07:58:03.620315 IP 172.17.2.2 > 172.17.2.3: ICMP echo reply, id 13998, seq 1, length 64
07:58:04.649543 IP 172.17.2.3 > 172.17.2.2: ICMP echo request, id 13998, seq 2, length 64
07:58:04.649571 IP 172.17.2.2 > 172.17.2.3: ICMP echo reply, id 13998, seq 2, length 64
07:58:05.673573 IP 172.17.2.3 > 172.17.2.2: ICMP echo request, id 13998, seq 3, length 64
07:58:05.673600 IP 172.17.2.2 > 172.17.2.3: ICMP echo reply, id 13998, seq 3, length 64
07:58:06.697562 IP 172.17.2.3 > 172.17.2.2: ICMP echo request, id 13998, seq 4, length 64
07:58:06.697588 IP 172.17.2.2 > 172.17.2.3: ICMP echo reply, id 13998, seq 4, length 64
07:58:07.721560 IP 172.17.2.3 > 172.17.2.2: ICMP echo request, id 13998, seq 5, length 64
07:58:07.721587 IP 172.17.2.2 > 172.17.2.3: ICMP echo reply, id 13998, seq 5, length 64
07:58:09.001502 ARP, Request who-has 172.17.2.3 tell 172.17.2.2, length 28
07:58:09.001527 ARP, Request who-has 172.17.2.2 tell 172.17.2.3, length 28
07:58:09.001621 ARP, Reply 172.17.2.2 is-at 4e:fa:e8:b9:51:3a (oui Unknown), length 28
07:58:09.001616 ARP, Reply 172.17.2.3 is-at 0a:5f:67:a1:21:c0 (oui Unknown), length 28
07:58:16.169617 IP6 fe80::85f:67ff:fea1:21c0 > ff02::2: ICMP6, router solicitation, length 16
15 packets captured
15 packets received by filter
0 packets dropped by kernel
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger#
利用组播的方式,成功地在 node1 和 node2 网络命名空间之间建立了通信,并且可以通过 vxlan1 接口进行数据传输。
VTEP 通过 IGMP 加入同一个多播组 224.1.1.1。IGMP(Internet Group Management Protocol)是一种用于在 IP 网络中进行组播(multicast)组管理的协议。它允许主机和组播路由器之间进行通信,以确定组播组的成员关系,并使网络能够有效地转发组播流量
从上面的抓包报文中我们可以看到两个 ARP 请求
07:58:09.001502 ARP, Request who-has 172.17.2.3 tell 172.17.2.2, length 28
07:58:09.001527 ARP, Request who-has 172.17.2.2 tell 172.17.2.3, length 28
07:58:09.001621 ARP, Reply 172.17.2.2 is-at 4e:fa:e8:b9:51:3a (oui Unknown), length 28
07:58:09.001616 ARP, Reply 172.17.2.3 is-at 0a:5f:67:a1:21:c0 (oui Unknown), length 28
-
第一条日志:主机 1(172.17.2.2)发送一个 ARP 请求,询问 IP 地址 172.17.2.3 所对应的 MAC 地址,源 MAC 地址为主机 1 的 MAC 地址(4e:fa:e8:b9:51:3a)。 -
第二条日志:主机 2(172.17.2.3)发送一个 ARP 请求,询问 IP 地址 172.17.2.2 所对应的 MAC 地址,源 MAC 地址为主机 2 的 MAC 地址(0a:5f:67:a1:21:c0)。 -
第三条日志:主机 2 回复 ARP 请求,表示 172.17.2.2 对应的 MAC 地址是 4e:fa:e8:b9:51:3a。 -
第四条日志:主机 1 回复 ARP 请求,表示 172.17.2.3 对应的 MAC 地址是 0a:5f:67:a1:21:c0。
一个 VXLAN 网络的 ping 报文要经历ARP寻址+ICMP响应两个过程。当然,VTEP 设备学习到对方 ARP 地址后就可以免去 ARP 寻址的过程。
分析多播模式下 VXLAN 通信的全过程:
-
命名空间 node2 的 vxlan1 发送 ping 报文到 node1 的 172.17.2.2地址,内核发现源地址和目的 IP 地址在同一个局域网内。需要知道对方的MAC地址,而本地又没有缓存,故先发送一个ARP查询报文。 -
ARP 报文源 MAC地址为 node2 上 vxlan1 的 MAC 地址,目的 MAC 地址为255.255.255.255(广播地址),并根据配置添加VXLAN头部VNI=43(这个时候已经添加了vxlan头部)。 -
不知道对端 VTEP在哪台主机上但又配置了多播组,根据配置,VTEP会往多播地址224.1.1.1发送多播报文。 -
多播组中所有的主机都会收到这个报文,目标端内核发现是 VXLAN 报文,根据 VNI 发送给对应的 VTEP。 -
node1 的 VTEP 去掉 VXLAN 头部,取出真正的 ARP 请求报文。同时,VTEP 会记录源 MAC 地址和 IP 地址信息到 FDB表中,这便是一次学习过程。如果发现 ARP 不是发送给自己的,则直接丢弃;如果是发送给自己的,则生成 ARP 应答报文。 -
应答报文目的 MAC 地址是发送方 VTEP 的 MAC 地址,不需要多播。对端 VTEP 已经通过源报文学习到了 VTEP 所在主机的 MAC 地址,故会直接单播发送给目的 VTEP。 -
应答报文通过底层网络直接返回发送方主机,发送方主机根据 VNI 把报文转发给 VTEP,VTEP 解包取出 ARP 应答报文,添加到 VTEP 缓存中,并根据报文学习到目的 VTEP 所在的主机地址,添加到 FDB 表中。 -
VTEP双方(隧道网络双方)已经通过一次 ARP 报文知道了建立 ICMP 通信需要的所有信息,因此后续的 ICMP 报文都是在这条逻辑隧道中单播进行的。
VXLAN+桥接网络
上面的方法能够通过多播实现自动化的 overlay 网络构建,但是通信的双方只有一个 VTEP。在实际生产中,每台主机上都有几十台甚至上百台虚拟机或者容器需要通信,因此需要找到一种方法将这些通信实体组织起来,再经过隧道口 VTEP 转发出去
Linux 网桥可以连接多块虚拟网卡,因此可以使用网桥把多个虚拟机或者容器放到同一个 VXLAN 网络中,VXLAN+网桥的网络拓扑如图 1-25 所示。
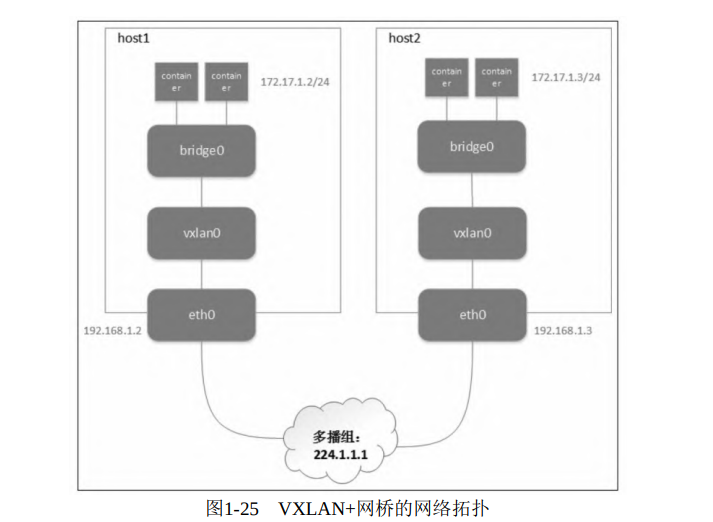 在这里插入图片描述
在这里插入图片描述
只有一个机器,在使用 Linux 网络命名空间嵌套的方式进行当前实验时,因为嵌套的 Linux network namespace 需要外层 namespace 存在驻留进程,内层的 namespace 才有效。所以实验失败了。
所以实验过程这里不在展示,感兴趣小伙伴可以下去尝试,至于嵌套的 namespace 如何解决,可以参考下面的 解决办法:
https://serverfault.com/questions/961504/cannot-create-nested-network-namespace
下面为在 两个 namespace 中的 Demo,命名可用作参考
liruilonger@cloudshell:~$ sudo ip netns exec node1 bash
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link add vxlan2 type vxlan id 45 dstport 4789 local 192.168.1.2 group 225.1.1.1 dev veth1
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link add bridge0 type bridge
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link set vxlan2 master bridge0
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link set vxlan2 up
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link set bridge0 up
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: veth1@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether ea:d1:4d:8c:c0:9a brd ff:ff:ff:ff:ff:ff link-netns node2
3: vxlan0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether c6:b1:87:67:d9:e4 brd ff:ff:ff:ff:ff:ff
4: vxlan1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether 4e:fa:e8:b9:51:3a brd ff:ff:ff:ff:ff:ff
5: vxlan2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master bridge0 state UNKNOWN mode DEFAULT group default qlen 1000
link/ether d2:71:34:09:f8:d7 brd ff:ff:ff:ff:ff:ff
6: bridge0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether d2:71:34:09:f8:d7 brd ff:ff:ff:ff:ff:ff
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip netns add pod1
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link add pod-veth0 netns pod1 type veth peer name pod-veth1
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link set dev pod-veth1 master bridge0
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip netns exec pod1 ip addr add 172.17.3.1/24 dev pod-veth0
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip netns exec pod1 ip link set lo up
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip netns exec pod1 ip link set pod-veth0 up
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger#
另一个命名空间配置
liruilonger@cloudshell:~$ sudo ip netns exec node2 bash
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link add vxlan2 type vxlan id 45 dstport 4789 local 192.168.1.3 group 225.1.1.1 dev veth2
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link add bridge0 type bridge
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link set vxlan2 master bridge0
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link set vxlan2 up
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link set bridge0 up
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: veth2@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
Error: Peer netns reference is invalid.
link/ether 46:26:8c:6d:21:bb brd ff:ff:ff:ff:ff:ff link-netns node1
3: vxlan0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether 5a:46:75:cd:ce:9e brd ff:ff:ff:ff:ff:ff
4: vxlan1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether 0a:5f:67:a1:21:c0 brd ff:ff:ff:ff:ff:ff
5: vxlan2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master bridge0 state UNKNOWN mode DEFAULT group default qlen 1000
link/ether 76:f8:f6:a1:51:3b brd ff:ff:ff:ff:ff:ff
6: bridge0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 76:f8:f6:a1:51:3b brd ff:ff:ff:ff:ff:ff
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip netns add pod2
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link add pod-veth0 netns pod2 type veth peer name pod-veth1
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip link set dev pod-veth1 master bridge0
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip netns exec pod2 ip addr add 172.17.3.2/24 dev pod-veth0
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip netns exec pod2 ip link set lo up
root@cs-1080702884152-ephemeral-ne4n:/home/liruilonger# ip netns exec pod2 ip link set pod-veth0 up
上面的命令执行完会报错,小伙伴可以把对应的 namespace 替换成 Linux 节点。
分布式控制中心
并不是所有的网络设备都支持多播,再加上多播方式带来的报文浪费,在实际生产中 VXLAN 的多播模式很少被采用。
为什么要引入多播?
隧道网络发送报文最关键的就是要知道对方虚拟机/容器的 MAC 地址及所在主机的 VTEP IP 地址。
对 overlay 网络来说,它的网段范围是分布在多个主机上的,因此传统 ARP报文的广播无法直接使用。要想做到overlay网络的广播,必须把报文发送到所有VTEP在的节点,这才使用了多播。
如果能够事先知道MAC地址和VTEP IP信息,直接告诉发送方 VTEP,就不需要多播了。
在分布式控制中心,一般情况下,这种架构在每个 VTEP 所在的节点都运行一个 agent,它会和控制中心通信,获取隧道通信需要的信息并以某种方式告诉 VTEP。
自维护 VTEP 组
如果有一种方法能够不通过多播,把 overlay 的广播报文发送给所有的 VTEP 主机,则也能完成相同的功能,即自己维护 VTEP网络组,即把上面的 Demo 中 ,FDB 表中多播相关的数据都替换成点对点的条目
如果不知道对方 VTEP 的地址,内核就会选择默认的 FDB表 项将网络包发送到 192.168.8.101 和 192.168.8.102,相当于手动维护了一个 VTEP的多播组。
ip link add vxlan0 type vxlan id 42 dstport 4789 dev eth0
bridge fdb append 00:00:00:00:00:00 dev vxlan0 dst 192.168.8.101
bridge fdb append 00:00:00:00:00:00 dev vxlan0 dst 192.168.8.102
在所有节点的 VTEP 上更新对应的FDB表项,就能实现overlay网络的连通。整个通信流程和多播模式相同,唯一的区别是,VTEP 第一次通信时会给所有组内成员发送单播报文,当然也只有一个 VTEP 会做出应答。
这个方案解决了在某些 underlay 网络中不能使用多播的问题,但并没有解决多播的另外一个问题:ARP每次查找MAC地址要发送大量的无用报文,如果VTEP组节点数量很大,那么每次查询都发送 N 个报文,其中只有一个报文真正有用。
手动维护 FDB 表
如果提前知道目的容器的MAC地址和它所在主机的 IP 地址,则可以通过更新 FDB 表项来减少ARP广播的报文数量。
在创建 VXLAN 设备时添加了 nolearning 参数,这个参数告诉 VTEP 不要通过收到的报文学习 FDB 表项的内容,因为我们自己会进行维护:
liruilonger@cloudshell:~$ sudo ip link add vxlan0 type vxlan id 42 dstport 4789 dev eth0 nolearning
liruilonger@cloudshell:~$ ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 6e:a2:d6:9d:e5:ab brd ff:ff:ff:ff:ff:ff link-netnsid 0
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1460 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 02:42:e2:0c:50:32 brd ff:ff:ff:ff:ff:ff
4: vxlan0: <BROADCAST,MULTICAST> mtu 1450 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 8a:14:bb:79:5c:19 brd ff:ff:ff:ff:ff:ff
添加 FDB 表项,告诉 VTEP 对应的 容器/虚拟机 MAC 地址与对应主机 IP 地址的映射关系:
liruilonger@cloudshell:~$ sudo bridge fdb append 6e:a2:d6:9d:e5:ab dev vxlan0 dst 192.168.8.101
liruilonger@cloudshell:~$ sudo bridge fdb append 00:00:00:00:00:00 dev vxlan0 dst 192.168.8.101
liruilonger@cloudshell:~$ bridge fdb show
01:00:5e:00:00:01 dev eth0 self permanent
33:33:00:00:00:01 dev docker0 self permanent
01:00:5e:00:00:6a dev docker0 self permanent
33:33:00:00:00:6a dev docker0 self permanent
01:00:5e:00:00:01 dev docker0 self permanent
02:42:e2:0c:50:32 dev docker0 vlan 1 master docker0 permanent
02:42:e2:0c:50:32 dev docker0 master docker0 permanent
00:00:00:00:00:00 dev vxlan0 dst 192.168.8.101 self permanent
6e:a2:d6:9d:e5:ab dev vxlan0 dst 192.168.8.101 self permanent
liruilonger@cloudshell:~$
知道了对方的 MAC 地址,则 VTEP 搜索 FDB 表项就知道应该发送到哪个对应的 VTEP 了。
需要注意的是,这个情况还是需要默认的表项(那些全零的表项),在不知道容器IP和MAC的对应关系时,通过默认方式发送ARP报文查询对方的MAC地址
还需要为 VTEP 添加 ARP 表项。所有要通信容器的 IP 地址和 MAC 地址的映射关系都要加进去
添加邻居表的相关数据
liruilonger@cloudshell:~$ sudo ip neigh add 10.20.1.4 lladdr 2e:c2:d6:9d:e5:ab dev vxlan0
liruilonger@cloudshell:~$
liruilonger@cloudshell:~$ ip neigh show
10.20.1.4 dev vxlan0 lladdr 2e:c2:d6:9d:e5:ab PERMANENT
10.20.1.3 dev vxlan0 lladdr 6e:a2:d6:9d:e5:ab PERMANENT
10.88.0.1 dev eth0 lladdr 76:78:7b:fc:e5:02 REACHABLE
liruilonger@cloudshell:~$
在要通信的所有节点配置完之后,容器就能互相 ping 通。当容器要访问彼此,并且第一次发送 ARP 请求时,这个请求并不会发给所有的 VTEP,而是由当前 VTEP 做出应答,大大减少了网络上的报文。
借助自动化的工具做到实时的表项(FDB 和 ARP)更新,这种方法能高效实现 overlay 网络的通信。
动态更新 FDB 和 ARP 表项
前一种方法通过动态更新 FDB 和 ARP 表项避免了多余的网络报文,但还有一个问题:为了让所有的容器能够正常通信,必须提前添加所有容器到 ARP 和 FDB 表项中。但是容器会频繁的变动,所以手动更新不现实
Linux 提供了另外一种方法,使内核能够动态地通知节点要和哪个容器通信,应用程序可以订阅这些事件。如果内核发现需要的 ARP 或者 FDB 表项不存在,则会发送事件给订阅的应用程序,这样应用程序可以从内核拿到这些信息更新表项,做到更精确的控制。
要收到L2(FDB)miss,必须满足几个条件:
-
目的 MAC地址未知,即没有对应的FDB表项; -
FDB中没有全零的表项,即默认规则; -
目的 MAC地址不是多播或者广播地址。
要实现这种功能,创建 VTEP 的时候需要加上额外的参数:
liruilonger@cloudshell:~$ ip link add vxlan0 type vxlan id 43 dstport 4789 dev eth0 nolearning proxy l2miss l3miss
这次多了两个参数 l2miss 和 l3miss:
-
nolearning表示禁用学习功能,即不会自动学习和更新 FDB 表项。这意味着 VXLAN 接口不会自动添加和更新关于 MAC 地址和对应 VTEP IP 的映射关系。 -
proxy表示启用代理模式,允许 VXLAN 接口代理其他主机的 ARP 请求和响应。这样可以实现更高效的 ARP 处理。 -
l2miss表示启用 L2 丢失事件处理,当接收到未知的 L2 报文时(如果设备找不到 MAC 地址需要的 VTEP 地址,就发送通知事件),将触发 L2 丢失事件。 -
l3miss表示启用 L3 丢失事件处理,当接收到未知的 L3 报文时(如果设备找不到需要 IP 对应的 MAC 地址,就发送通知事件),将触发 L3 丢失事件。
ip monitor 命令能监听某个网卡的事件:
ip monitor all dev vxlan0
[nsid current]miss 10.20.1.3 STALE
如果从本节点的容器 ping 另外一个节点的容器,就先发送 L3 miss,下面就是一个 L3 miss 的通知事件:
l3miss 说明了 VTEP 不知道它对应的 MAC 地址,因此要手动添加 ARP 记录,如下所示:
ip neigh replace 10.20.1.3 lladdr 2e:c2:d6:9d:e5:ab dev vxlan0 nud reachable
上面这条命令设置的 nud reachable 参数的意思是,这条记录有一个超时时间,系统发现它无效一段时间后会自动删除,无须用户手动删除。ARP 记录被删除后,当需要通信时,内核会再次发送 L3 miss 通知事件。nud 是 Neighbour Unreachability Detection 的缩写,根据需要这个参数也可以设置成其他值,比如 permanent,表示这个记录永远不会过时,系统不会检查它是否正确,也不会删除它。
这时还是不能正常通信,内核出现了 L2 miss 的通知事件:
ip monitor all dev vxlan0
[nsid current]miss lladdr 2e:c2:d6:9d:e5:ab STALE
类似地,这个事件的含义是不知道这个容器的 MAC 地址在哪个节点上,所以要手动添加 FDB 记录
bridge fdb add b2:ee:aa:42:8b:0b dst 192.168.8.101 dev vxlan0
在通信的另一台机器上执行响应的操作,就会发现两者能 ping 通
总结
VXLAN协议给虚拟网络带来了灵活性和扩展性,让云计算网络能够像计算、存储资源那样按需扩展,并灵活分布。与此同时,VXLAN 也带来了额外的复杂度和性能开销。性能开销主要包含两个方面:
-
每个 VXLAN报文都有额外的50字节开销,加上VXLAN字段,开销要到54字节。这对于小报文的传输是非常昂贵的操作。试想,如果某个报文应用数据才几个字节,那么原来的网络头部加上 VXLAN 报文头部就有 100 字节的控制信息; -
每个 VXLAN报文的封包和解包操作都是必需的,如果用软件来实现这些步骤,则额外的计算量是不可忽略的影响因素。
多播实现很简单,不需要中心化的控制。不是所有的网络都支持多播,需要事先规划多播组和 VNI 的对应关系,在 overlay 网络数量比较多时也会很麻烦,多播会导致大量的无用报文出现在网络中。
很多云计算的网络通过自动化的方式发现 VTEP 和 MAC 地址等信息,避免多播。
博文部分内容参考
© 文中涉及参考链接内容版权归原作者所有,如有侵权请告知 :)
《 Kubernetes 网络权威指南:基础、原理与实践》
https://cizixs.com/2017/09/28/linux-vxlan/
© 2018-2024 liruilonger@gmail.com, All rights reserved. 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)

- 点赞
- 收藏
- 关注作者
评论(0)