Base64与cv2读取的图片,格式互转

Base64编码
Base64编码是一种将二进制数据转换为可打印字符的方式,以便在文本格式中传输或存储。它通常用于将二进制数据编码为ASCII字符串,以便在电子邮件、网页或XML文件中传输。
Base64编码的原理是将3个8位字节的数据(即24位二进制数据)转换为4个6位二进制数据(即24位二进制数据),然后使用64个可打印字符来表示这4个6位二进制数据。这些可打印字符通常包括大小写字母和数字,以及"+“和”/"符号。
Base64编码的应用非常广泛,包括在HTTP环境下传递较长标识信息、加密电子邮件、将二进制数据编码为QR代码等。此外,Base64编码还被用于很多编程语言和库中,以方便在各种数据格式之间转换。
base64转cv2
import base64
import cv2
# cv2转base64
def cv2_to_base64(img):
img = cv2.imencode('.jpg', img)[1]
image_code = str(base64.b64encode(img))[2:-1]
return image_code
cv2 转base64
import base64
import numpy as np
import cv2
# base64转cv2
def base64_to_cv2(base64_code):
img_data = base64.b64decode(base64_code)
img_array = np.fromstring(img_data, np.uint8)
img = cv2.imdecode(img_array, cv2.COLOR_RGB2BGR)
return img
@[toc]
摘要
本专栏是讲解如何改进Yolov8的专栏。改进方法采用了最新的论文提到的方法。改进的方法包括:增加注意力机制、更换卷积、更换block、更换backbone、更换head、更换优化器等;每篇文章提供了一种到N种改进方法。
评测用的数据集是我自己标注的数据集,里面包含32种飞机。每种改进方法我都做了测评,并与官方的模型做对比。
代码和PDF版本的文章,我在验证无误后会上传到百度网盘中,方便大家下载使用。
这个专栏,求质不求量,争取尽心尽力打造精品专栏!!!
谢谢大家支持!!!

YoloV8改进策略:基于分层注意力的FasterViT,让YoloV8实现性能的飞跃
YoloV8改进策略:基于分层注意力的FasterViT,让YoloV8实现性能的飞跃
这篇文章向大家展示如何使用FasterViT改进YoloV8,我尝试了几种方法,选出了三种效果比较好的方法推荐给大家。
FasterViT结合了cnn的快速局部表示学习和ViT的全局建模特性的优点。新提出的分层注意力(HAT)方法将具有二次复杂度的全局自注意力分解为具有减少计算成本的多级注意力。我们受益于基于窗口的高效自我关注。每个窗口都可以访问参与局部和全局表示学习的专用载体Token。在高层次上,全局的自我关注使高效的跨窗口通信能够以较低的成本实现。FasterViT在精度与图像吞吐量方面达到了SOTA Pareto-front。
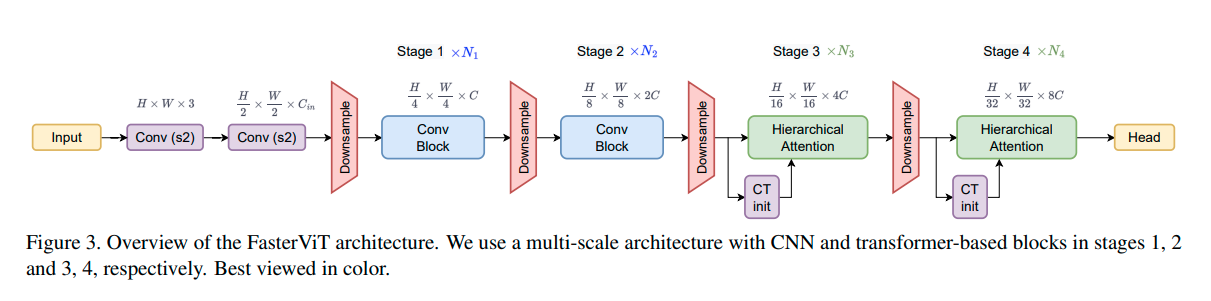
YoloV8改进策略:InceptionNext主干替换YoloV8和YoloV5的主干
YoloV8改进策略:InceptionNext主干替换YoloV8和YoloV5的主干
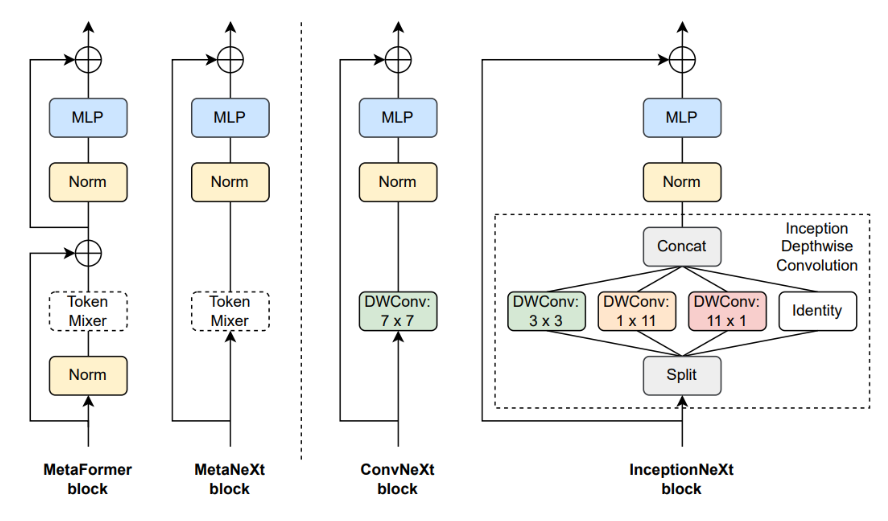
这篇文章主要讲解如何使用InceptionNext主干网络替换YoloV8和YoloV5的主干。更改了InceptionNext网络结构,和Yolov5、YoloV8的架构。
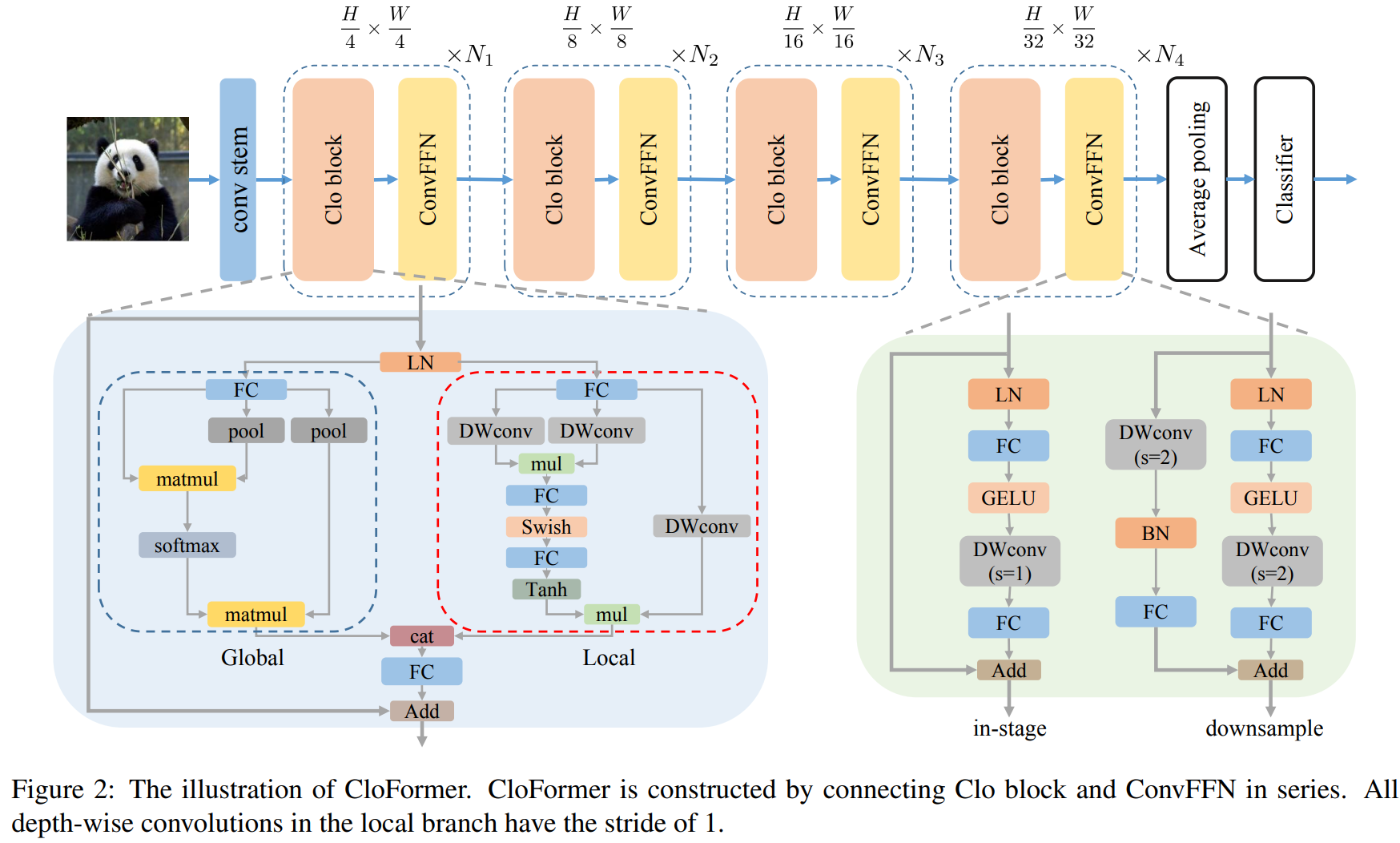
YoloV8改进策略:轻量级的CloFormer助力Yolov8在速度和精度上实现双双提升
YoloV8改进策略:轻量级的CloFormer助力Yolov8在速度和精度上实现双双提升
CloFormer是清华大学在今年发表的轻量级主干网络,引入了AttnConv,一种attention风格的卷积算子。所提出的AttnConv使用共享权重来聚合局部信息,并配置精心设计的上下文感知权重来增强局部特征。AttnConv和普通attention的结合使用池化来减少CloFormer中的FLOPs,使模型能够感知高频和低频信息。
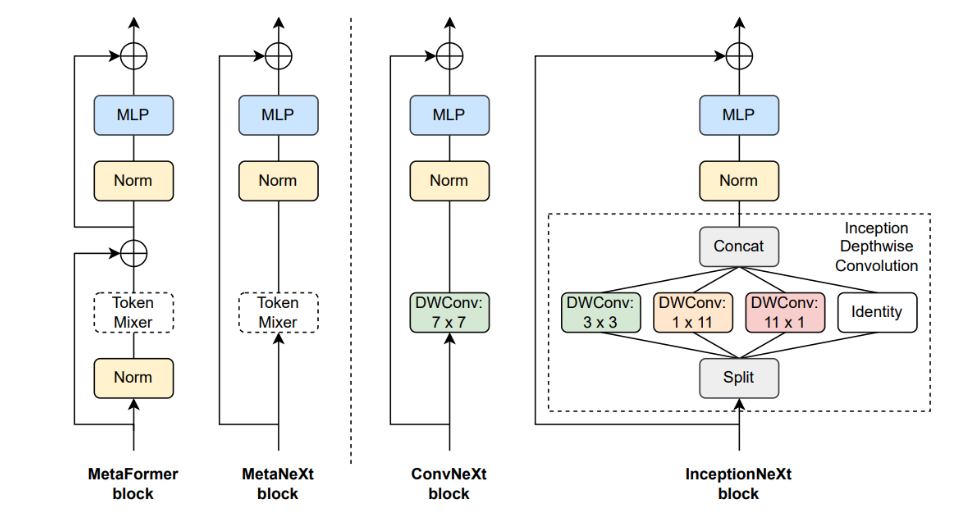
YoloV8改进策略:InceptionNeXt和YoloV8完美结合,让YoloV8大放异彩
YoloV8改进策略:InceptionNeXt和YoloV8完美结合,让YoloV8大放异彩
InceptionNeXt是今年颜水成团队发布的一篇论文,将ConvNext和Inception的思想融合,即IncepitonNeXt。InceptionNeXt-T实现了比convnext - t高1.6倍的训练吞吐量,并在ImageNet- 1K上实现了0.2%的top-1精度提高。
YoloV8改进策略:新出炉的EMA注意力机制助力YoloV8更加强大
YoloV8改进策略:新出炉的EMA注意力机制助力YoloV8更加强大
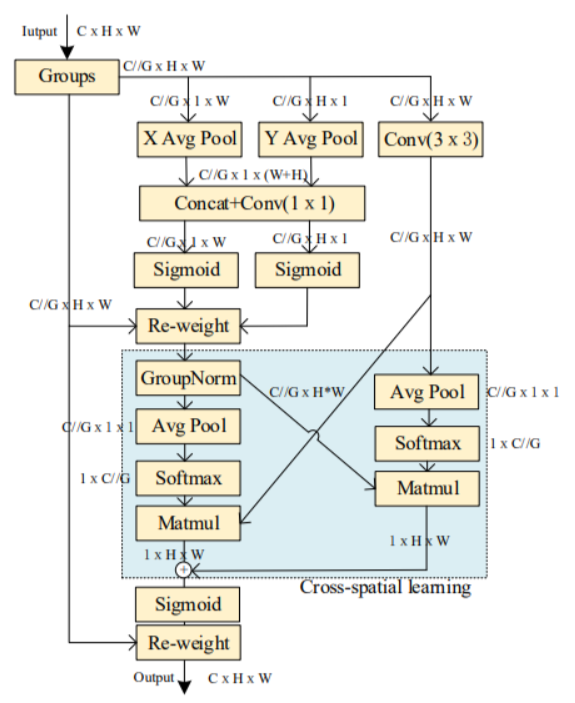
EMA注意力机制是今年新的高效的多尺度注意力模块。以保留每个通道上的信息和降低计算开销为目标,将部分通道重塑为批量维度,并将通道维度分组为多个子特征,使空间语义特征在每个特征组中均匀分布。具体来说,除了对全局信息进行编码以重新校准每个并行分支中的通道权重外,还通过跨维度交互进一步聚合两个并行分支的输出特征,以捕获像素级成对关系。
YoloV8改进策略:VanillaNet极简主义网络,大大降低YoloV8的参数
YoloV8改进策略:VanillaNet极简主义网络,大大降低YoloV8的参数
VanillaNet,一个包含优雅设计的神经网络架构。通过避免高深度,shotcut和复杂的操作,如自主意力,VanillaNet令人耳目一新的简洁,但非常强大。每一层都被精心制作得紧凑而直接,非线性激活函数在训练后被修剪以恢复原始结构。VanillaNet克服了固有复杂性的挑战,使其成为资源受限环境的理想选择。其易于理解和高度简化的架构为高效部署提供了新的可能性。大量的实验表明,VanillaNet提供的性能与著名的深度神经网络和视觉转换器相当,展示了极简主义在深度学习中的力量。VanillaNet的这一富有远见的旅程具有重新定义景观和挑战基础模型现状的巨大潜力,为优雅有效的模型设计开辟了一条新的道路。
YoloV8改进策略:RFAConv模块即插即用,实现YoloV8丝滑上分
YoloV8改进策略:RFAConv模块即插即用,实现YoloV8丝滑上分
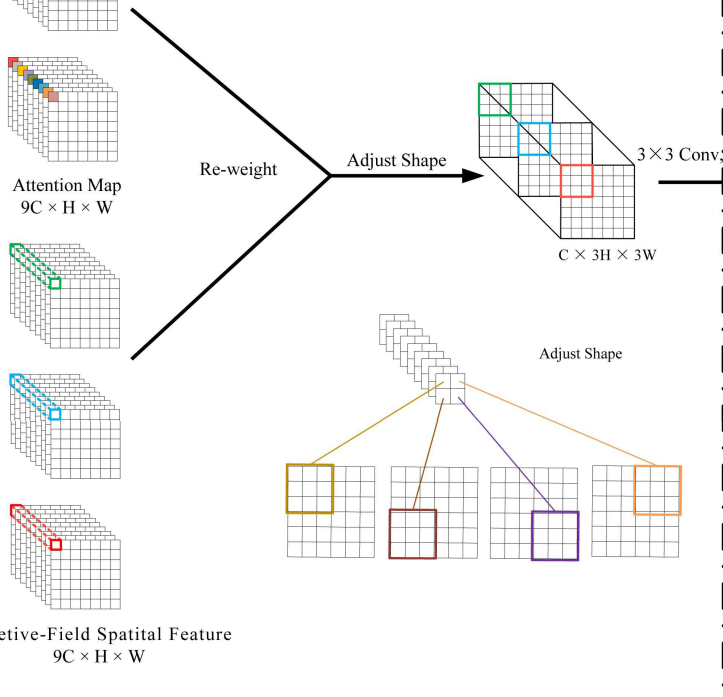
RFAConv是一种新的注意力机制,称为感受野注意力(RFA)。卷积块注意力模块(CBAM)和协调注意力模块(CA)只关注空间特征,不能完全解决卷积核参数共享的问题,但在RFA中,感受野空间特征不仅集中,而且为大尺寸卷积核提供了良好的注意力权重。RFA设计的感受野注意力卷积运算(RFAConv)可以被认为是取代标准卷积的一种新方法,它带来的计算成本和许多参数几乎可以忽略不计。由于作者没有开源我自己复现了一版,并尝试将其加入到YoloV8网络中。
YoloV8改进策略:让SeaFormer走进Yolov8的视野,轻量高效的注意力模块展现出无与伦比的魅力
YoloV8改进策略:让SeaFormer走进Yolov8的视野,轻量高效的注意力模块展现出无与伦比的魅力
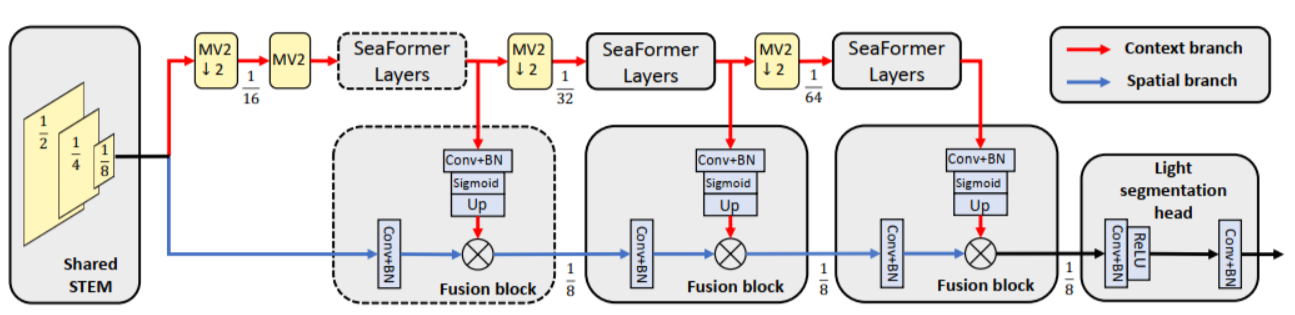
SeaFormer使用压缩轴和细节增强的方法设计了一个通用的注意力块。它可以进一步用于创建一系列具有卓越成本效益的骨干体系结构。再加上一个轻分割头,我们在基于arm的移动设备上在ADE20K和cityscape数据集上实现了分割精度和延迟之间的最佳权衡。关键的是,我们以更好的性能和更低的延迟击败了适合移动设备的竞争对手和基于transformer的对手,而且没有花哨的东西。
YoloV8改进策略:将DCN v1与v2运用到YoloV8中,化身成上分小黑子
YoloV8改进策略:将DCN v1与v2运用到YoloV8中,化身成上分小黑子
尝试用DCNv1与DCNv2代替普通的卷积!

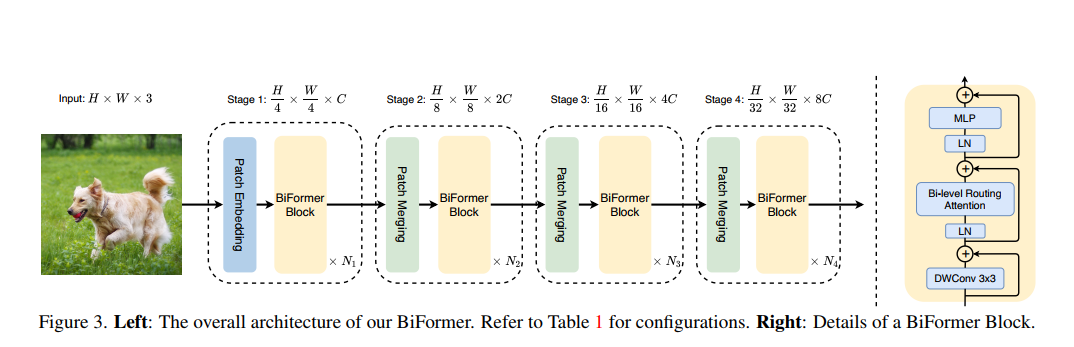
YoloV8改进策略:基于双层路由注意力的视觉Transformer提升YoloV8的检测能力
YoloV8改进策略:基于双层路由注意力的视觉Transformer提升YoloV8的检测能力
双层路由注意力实现具有内容感知的更灵活的计算分配。利用稀疏性来节省计算和内存,同时只涉及适用于GPU的密集矩阵乘法。用所提出的双层路由注意力建立了一个新的通用视觉transformer,称为BiFormer。
YoloV8改进策略:来自谷歌最新的优化器——Lion,在速度和精度上双双提升。Adam表示年轻人不讲武德
YoloV8改进策略:来自谷歌最新的优化器——Lion,在速度和精度上双双提升。Adam表示年轻人不讲武德
Lion将ViT在ImageNet上的准确率提高了2%,并在JFT上节省了高达5倍的预训练计算。在视觉-语言对比学习方面,在ImageNet上实现了88.3%的零样本和91.1%的微调精度,分别超过了之前的最佳结果2%和0.1%。在扩散模型上,Lion通过获得更好的FID分数并将训练计算量减少了2.3倍,超越了Adam。在自回归、掩码语言建模和微调方面,Lion表现出与Adam类似或更好的性能。对Lion的分析表明,其性能增益随着训练批大小的增加而增长。由于符号函数产生的更新范数更大,它还需要比Adam更小的学习率。
YoloV8改进策略:Conv2Former与YoloV8深度融合,极简网络,极高性能
YoloV8改进策略:Conv2Former与YoloV8深度融合,极简网络,极高性能
Conv2Former是在ConvNeXt基础上,做了进一步的优化,性能得到了提升。
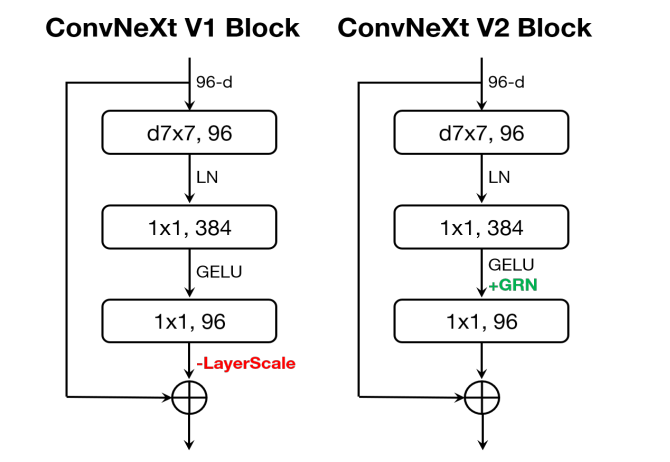
YoloV8改进策略:将ConvNextV2与YoloV8激情碰撞,能迸发出什么样的火花呢?
YoloV8改进策略:将ConvNextV2与YoloV8激情碰撞,能迸发出什么样的火花呢
ConvNextV2将一个全卷积掩码自编码器框架和一个新的全局响应归一化(GRN)层,可以添加到ConvNeXt架构中,以增强通道间的特征竞争,它显著提高了纯ConvNets在各种识别基准上的性能,包括ImageNet分类、COCO检测和ADE20K分割。
YoloV8改进策略:将CIoU替换成Wise-IoU,幸福涨点,值得拥有,还支持EIoU、GIoU、DIoU、SIoU无缝替换。
YoloV8改进策略:将CIoU替换成Wise-IoU,幸福涨点,值得拥有,还支持EIoU、GIoU、DIoU、SIoU无缝替换。
这篇文章讲述如何在yolov8中,使用Wise-IoU涨点。首先,翻译了论文,让大家了解什么是Wise IoU,以及Wise IoU的三个版本。接下来讲解如何在yolov8中添加Wise IoU。

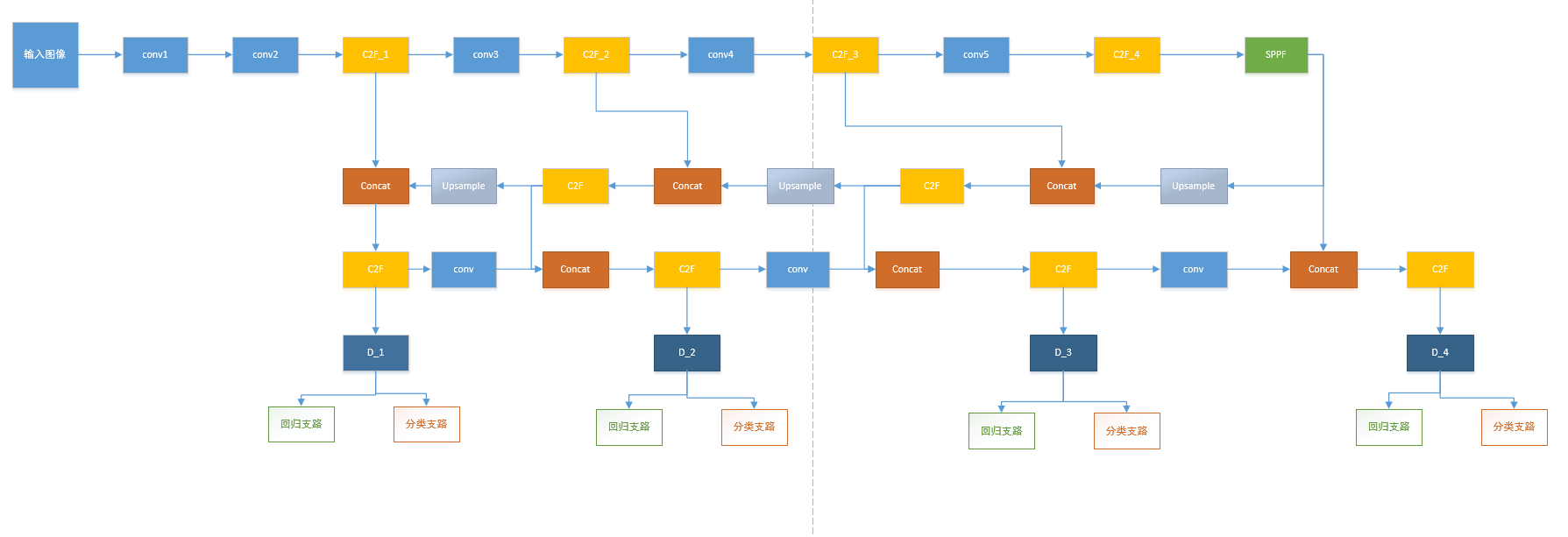
YoloV8改进策略:增加分支,减少漏检
通过增加一个分支,来提高小目标的检测
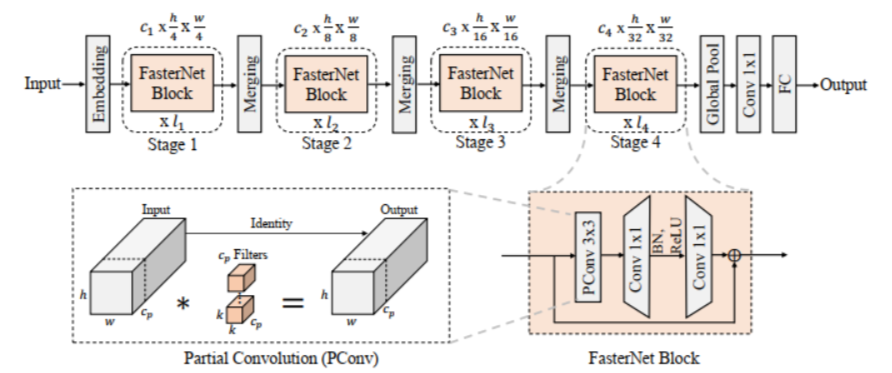
YoloV8改进策略:将FasterNet与YoloV8深度融合,打造更快更强的检测网络
YoloV8改进策略:将FasterNet与YoloV8深度融合,打造更快更强的检测网络
fastternet,这是一种新的神经网络家族,它在各种设备上获得了比其他网络更高的运行速度,而不影响各种视觉任务的准确性。
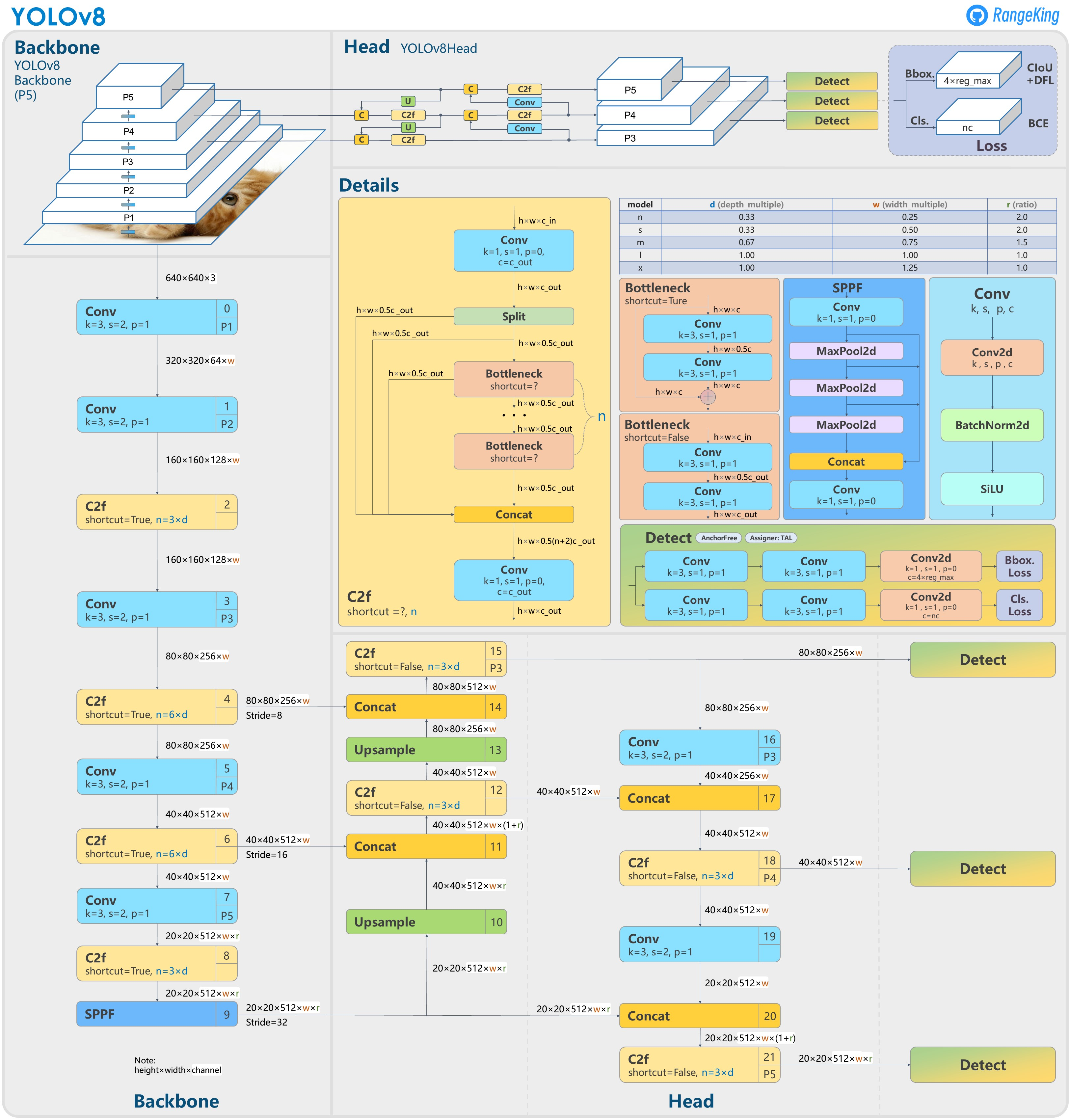
Yolov8网络详解与实战(附数据集)

- 点赞
- 收藏
- 关注作者
评论(0)