Linux 性能调优之存储设备调优

写在前面
-
考试整理相关笔记 -
博文内容涉及, IO调度器,以及IO负载工具fio介绍,磁盘整列,IO 分析工具简单介绍 -
理解不足小伙伴帮忙指正
对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃避方式,是对大众理想的懦弱回归,是随波逐流,是对内心的恐惧 ——赫尔曼·黑塞《德米安》
固态硬盘正逐步取代磁盘成为存储的标准解决方案,传统磁盘的转速、寻道时间、延迟、机械故障等特点,在新的固态硬盘中已经不复存在。固态硬盘的访问时间在真个设备中是统一的,因此碎片和磁道的优化也不再需要,固态硬盘大小更小、更轻、更节能。
但是固态硬盘也有局限性,比如成本较高。固态硬盘的写入次数有限。
很多传统硬盘的优化不再适用于固态硬盘,红帽不建议在固态硬盘设备使用日志,因为固态磨损增加,并且不必要的双重写入会导致速度缓慢。
选择合适的IO 调度器
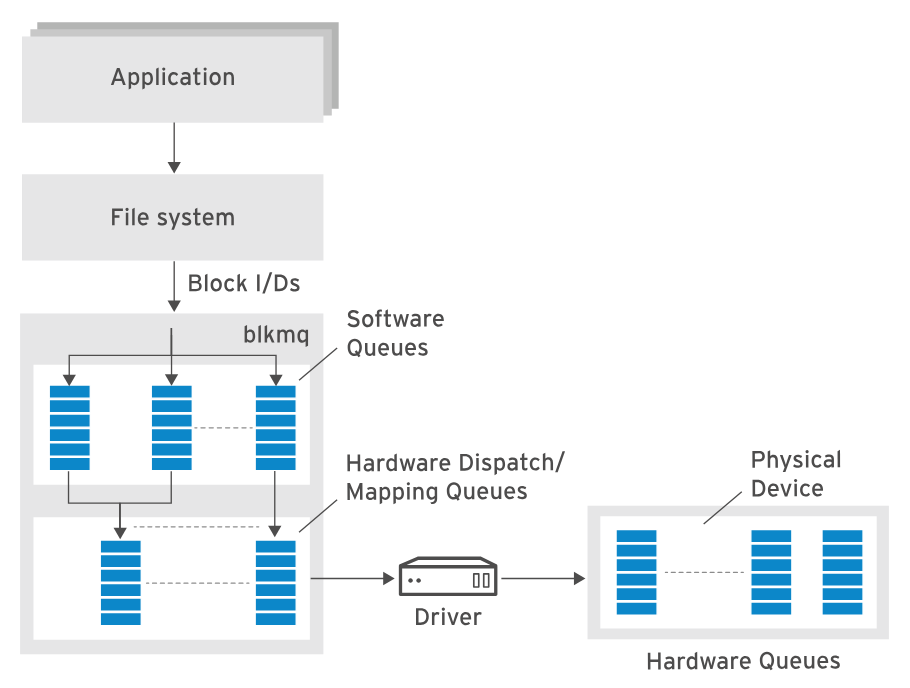 在这里插入图片描述
在这里插入图片描述
RHEL8开始使用新的多队列I/O调度器来替代之前的单队列调度器。
┌──[root@liruilongs.github.io]-[~]
└─$cat /sys/block/nvme0n1/queue/scheduler
[none] mq-deadline kyber bfq
┌──[root@liruilongs.github.io]-[~]
└─$cat /sys/block/sr0/queue/scheduler
none [mq-deadline] kyber bfq
┌──[root@liruilongs.github.io]-[~]
└─$
调度器分类:
Noop/none
Noop(none是多队列版本的Noop) 调度算法是 Linux 内核中最简单的 IO 调度算法之一。它也被称为电梯调度算法。Noop 调度算法将 IO 请求放入一个 FIFO(先进先出)队列中,并按顺序执行这些 IO 请求。对于一些在磁盘上连续的 IO 请求,Noop 算法会适当地进行一些合并操作。这个调度算法特别适用于那些不希望调度器重新组织 IO 请求顺序的应用程序。
Noop 调度算法的应用案例包括:
-
底层设备比内核调度器更优秀:当底层设备(如 RAID、SAN、NAS 设备)具有自己的高效调度算法时,使用 Noop 算法可以避免重复的调度开销。 -
上层应用比内核调度器更优秀:某些应用程序可能已经实现了自己的 IO 调度逻辑,使用 Noop 算法可以避免与内核调度器的冲突。 -
非旋转磁头的设备:对于不需要磁头寻道的设备(如 SSD),内核调度器的重新组织 IO 请求可能会浪费 CPU 时间,而 Noop 算法可以节省这些开销
Deadline/mq-deadline
Deadline 调度算法旨在确保每个 IO 请求在一定的时间内得到服务,以避免某个请求饥饿。每个请求都被赋予一个期限值,读请求的默认期限是 500 毫秒,写请求的默认期限是 5 秒。该算法适用于需要保证 IO 响应时间的应用场景。
Deadline应用:一些多线程和数据库的应用适合Deadline算法(业务压力重,功能单一的场景)
deadline是单队列,mq(multi-queue)是多队列,核心算法是一样的
CFQ(Completely Fair Queuing)
CFQ 是 Linux 内核默认的 IO 调度算法,它尝试为所有需要 IO 的进程分配请求队列和时间片。每个进程根据其 IO 优先级获得时间片,并在时间片内发送其读写请求给底层块设备。此算法旨在提供公平的 IO 资源分配,适用于多任务环境。
每个进程的时间片和每个进程的队列长度取决于进程的IO优先级,每个进程都会有一个IO优先级。通过ionice可以显示或修改进程的IO优先级!
┌──[root@liruilongs.github.io]-[~]
└─$man ionice
BFQ(Budget Fair Queueing)
BFQ 算法将以扇区数为单位的预算分配给每个进程,而不是固定的时间片。它旨在提供更精确的 IO 资源分配,避免某些任务占用过多的 IO 资源。BFQ 算法适用于对IO 响应时间要求较高的应用场景。
Kyber
Kyber 调度算法类似于 Noop,它是一种简单的调度算法,不进行显式的调度操作。它对于一些底层设备已经具有高效调度算法的情况下,可以发挥更好的性能。
❝注意:NVMe硬盘默认使用none I/O调度算法,你不能改变NVMe硬盘的调度算法。
使用fio工具模拟工作负载
测试存储系统需要模拟真实的工作负载。fio命令可以通过多进程和多线程模拟各种工作负载情况(实现别发读写数据),包括顺序读写,随机读写以及I/O类型。建议通过 /usr/share/doc/fio/HOWTO来学习fio如何使用。
┌──[root@liruilongs.github.io]-[~]
└─$dnf provides fio
Last metadata expiration check: 3:13:00 ago on Mon Feb 5 04:06:51 2024.
fio-3.35-1.el9.x86_64 : Multithreaded IO generation tool
Repo : appstream
Matched from:
Provide : fio = 3.35-1.el9
┌──[root@liruilongs.github.io]-[~]
└─$dnf -y install fio
┌──[root@liruilongs.github.io]-[~]
└─$rpm -ql fio | grep HOWTO
/usr/share/doc/fio/HOWTO.rst
┌──[root@liruilongs.github.io]-[~]
└─$cat $(!!) | grep -i -A 5 "Example output"
cat $(rpm -ql fio | grep HOWTO) | grep -i -A 5 "Example output"
Example output was based on the following:
TZ=UTC fio --iodepth=8 --ioengine=null --size=100M --time_based \
--rate=1256k --bs=14K --name=quick --runtime=1s --name=mixed \
--runtime=2m --rw=rw
Fio spits out a lot of output. While running, fio will display the status of the
--
Example output was based on the following:
TZ=UTC fio --iodepth=8 --ioengine=null --size=100M --runtime=58m \
--time_based --rate=2512k --bs=256K --numjobs=10 \
--name=readers --rw=read --name=writers --rw=write
Fio will condense the thread string as not to take up more space on the command
--
Example output was based on the following:
TZ=UTC fio --iodepth=16 --ioengine=posixaio --filename=/tmp/fiofile \
--direct=1 --size=100M --time_based --runtime=50s --rate_iops=89 \
--bs=7K --name=Client1 --rw=write
When fio is done (or interrupted by :kbd:`Ctrl-C`), it will show the data for
--
Example output was based on the following:
TZ=UTC fio --ioengine=null --iodepth=2 --size=100M --numjobs=2 \
--rate_process=poisson --io_limit=32M --name=read --bs=128k \
--rate=11M --name=write --rw=write --bs=2k --rate=700k
After each client has been listed, the group statistics are printed. They
┌──[root@liruilongs.github.io]-[~]
└─$
下面的命令执行随机写操作,将512M数据写入一个指定的文件中,写操作是不使用缓存,采用直接写入硬盘的方式,同时进行2个相同的操作(2个进程或线程)。
┌──[root@liruilongs.github.io]-[~]
└─$fio --name=randwrite --ioengine=libaio --iodepth=1 --rw=randwrite --bs=4K --direct=1 --size=512M --numjobs=2 --group_reporting --filename=/tmp/testfile
randwrite: (g=0): rw=randwrite, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=1
...
fio-3.35
Starting 2 processes
Jobs: 2 (f=2): [w(2)][95.7%][w=41.9MiB/s][w=10.7k IOPS][eta 00m:01s]
randwrite: (groupid=0, jobs=2): err= 0: pid=20196: Mon Feb 5 07:28:25 2024
write: IOPS=11.5k, BW=44.9MiB/s (47.1MB/s)(1024MiB/22803msec); 0 zone resets
slat (usec): min=12, max=3836, avg=23.81, stdev=27.13
clat (nsec): min=1709, max=6549.7k, avg=148047.50, stdev=154937.29
lat (usec): min=69, max=6587, avg=171.85, stdev=164.42
clat percentiles (usec):
| 1.00th=[ 80], 5.00th=[ 84], 10.00th=[ 86], 20.00th=[ 90],
| 30.00th=[ 94], 40.00th=[ 99], 50.00th=[ 106], 60.00th=[ 117],
| 70.00th=[ 131], 80.00th=[ 153], 90.00th=[ 221], 95.00th=[ 318],
| 99.00th=[ 898], 99.50th=[ 1123], 99.90th=[ 1696], 99.95th=[ 2008],
| 99.99th=[ 3097]
bw ( KiB/s): min=18528, max=64600, per=99.77%, avg=45878.96, stdev=6563.89, samples=90
iops : min= 4632, max=16150, avg=11469.69, stdev=1641.01, samples=90
lat (usec) : 2=0.01%, 4=0.06%, 10=0.02%, 20=0.01%, 50=0.02%
lat (usec) : 100=42.05%, 250=49.94%, 500=4.86%, 750=1.42%, 1000=0.92%
lat (msec) : 2=0.64%, 4=0.05%, 10=0.01%
cpu : usr=2.16%, sys=9.33%, ctx=270388, majf=0, minf=26
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,262144,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
WRITE: bw=44.9MiB/s (47.1MB/s), 44.9MiB/s-44.9MiB/s (47.1MB/s-47.1MB/s), io=1024MiB (1074MB), run=22803-22803msec
Disk stats (read/write):
dm-0: ios=0/259699, merge=0/0, ticks=0/38126, in_queue=38126, util=99.67%, aggrios=0/262144, aggrmerge=0/0, aggrticks=0/40150, aggrin_queue=40150, aggrutil=99.56%
nvme0n1: ios=0/262144, merge=0/0, ticks=0/40150, in_queue=40150, util=99.56%
┌──[root@liruilongs.github.io]-[~]
└─$
-
randwrite:测试名称。 -
rw=randwrite:读写模式为随机写入。 -
bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B:读取和写入的块大小都是 4096 字节。 -
ioengine=libaio:使用 libaio 作为 I/O 引擎。 -
iodepth=1:I/O 深度为 1。 -
write: IOPS=11.5k, BW=44.9MiB/s:写入操作的 IOPS(每秒输入/输出操作数)为 11,500,带宽为 44.9 MiB/s(兆字节/秒)。 -
slat:写入操作的起始时间统计。 -
clat:写入操作的完成时间统计。 -
lat:写入操作的总体响应时间统计。 -
bw:写入操作的带宽统计。 -
iops:写入操作的 IOPS 统计。 -
cpu:CPU 使用情况统计。 -
IO depths:不同 I/O 深度的统计。 -
Run status group 0 (all jobs):运行状态的总结信息。 -
WRITE: bw=44.9MiB/s (47.1MB/s), 44.9MiB/s-44.9MiB/s (47.1MB/s-47.1MB/s), io=1024MiB (1074MB), run=22803-22803msec:写入操作的带宽和持续时间统计。 -
Disk stats (read/write):磁盘的读写统计信息。
磁盘阵列
磁盘阵列是一种虚拟化存储技术,将多个磁盘组成一个大的磁盘,利用同步写入到这些磁盘的技术,不但可以加快读写速度,而且支持数据恢复(需要有冗余数据)。
RAID会将数据打散成很多小数据块,这些数据块会被写入阵列中的不同磁盘。这些数据需要满足一个或多个策略需求:数据条带化、数据镜像化、数据校验。
数据条带化将数据划分为条带,这些条带分布在RAID阵列内的多个磁盘中。
数据镜像提供了将条带复制到至少两个不同RAID磁盘得冗余性。数据奇偶校验通过将奇偶校验添加到条带来支持数据冗余,因此与相同数据量相关的其他条带可以使用工作数据及其相关的
RAID 0:数据条带化(Striping),没有冗余。通过将数据分割成条带并在多个磁盘之间分布存储,提高了吞吐量,但没有冗余备份。适用于需要高性能和较低成本的应用,但不提供故障容错能力。
 在这里插入图片描述
在这里插入图片描述
-
磁盘要求:至少需要两个磁盘。 -
容错能力:没有冗余,任何一个磁盘故障都会导致数据丢失。
RAID 1:数据镜像(Data Mirroring)。通过将数据复制到至少两个不同的 RAID 磁盘上,提供冗余备份。当一个磁盘故障时,仍然可以从镜像磁盘读取数据。数据冗余和读取冗余带来了更高的数据可靠性,但写入性能略有降低。
 在这里插入图片描述
在这里插入图片描述
-
磁盘要求:至少需要两个磁盘。 -
容错能力:可以容忍一个磁盘故障,因为数据被镜像到其他磁盘上。
RAID 4:基于块的条带化,带有专用奇偶校验磁盘。类似于 RAID 0,但额外使用了一个专用的奇偶校验磁盘来存储奇偶校验信息。该奇偶校验信息用于恢复任何一个数据块,从而提供了故障容错能力。
 在这里插入图片描述
在这里插入图片描述
-
磁盘要求:至少需要三个磁盘。 -
容错能力:可以容忍一个磁盘故障,因为有一个专用的奇偶校验磁盘。
RAID 5:基于块的条带化,带有分布式奇偶校验。类似于 RAID 4,但奇偶校验信息分布在所有磁盘上,而不是单独的奇偶校验磁盘上。这种分布式奇偶校验提供了更好的性能和容错能力。
 在这里插入图片描述
在这里插入图片描述
-
磁盘要求:至少需要三个磁盘。 -
容错能力:可以容忍一个磁盘故障,因为奇偶校验信息分布在所有磁盘上。
RAID 6:基于块的条带化,带有双重分布式奇偶校验。类似于 RAID 5,但提供了更高的冗余度。使用两个奇偶校验计算来提供更高级别的容错能力,即使在两个磁盘故障的情况下,也能够恢复数据。
 在这里插入图片描述
在这里插入图片描述
-
磁盘要求:至少需要四个磁盘。 -
容错能力:可以容忍两个磁盘故障,因为使用了双重分布式奇偶校验。
RAID 10:镜像的条带化。将数据分成条带并在多个磁盘上进行镜像。提供了数据冗余和高性能的组合。数据被同时写入多个磁盘,提供了冗余备份和更快的读取性能。
-
磁盘要求:至少需要四个磁盘。 -
容错能力:可以容忍多个磁盘故障,具体取决于故障发生在哪个镜像组上
创建软RAID
mdadm 是一个用于管理 Linux 软件 RAID 的工具。
//创建RAID,-l指定级别
[root@localhost ~]# mdadm -C /dev/md0 -l raid0 -n 2 /dev/vd[b-c]1
//停止使用RAID
[root@localhost ~]# mdadm --stop /dev/md0
//删除RAID
[root@localhost ~]# mdadm --remove /dev/md0
//将原来RAID硬盘中的数据清零
[root@localhost ~]# mdadm --zero-superblock /dev/vdb
[root@localhost ~]# mdadm --zero-superblock /dev/vdc
创建好RAID之后,最好在格式化文件系统的时候,让文件系统和RAID数据分块保持一致。我们需要先了解一下这些信息:
Chunk Size(块大小):Chunk 是 RAID 中的最小数据单元,决定了数据如何在磁盘上进行分割和存储。较小的块大小可以提供更好的性能,因为数据可以更细粒度地分布在多个磁盘上。然而,小块大小可能会增加磁盘开销和额外的存储空间。较大的块大小可以提供更高的数据传输效率,但在故障恢复时可能需要恢复更多的数据。
Number of Disks(磁盘数量):磁盘数量决定了 RAID 中可用于存储数据的物理磁盘数量。增加磁盘数量可以提高性能和存储容量。更多的磁盘可以提供更多的并行性,从而提高数据传输速度。但同时,也意味着更多的磁盘故障可能会导致数据丢失。
Number of Parity Disks(奇偶校验磁盘数量):奇偶校验磁盘用于存储冗余信息,以实现数据的容错能力。在 RAID 4、RAID 5 和 RAID 6 级别中,需要指定奇偶校验磁盘的数量。增加奇偶校验磁盘的数量可以提供更高的容错能力,因为更多的磁盘故障可以被容忍。然而,每个奇偶校验磁盘都会增加额外的存储开销。
对于XFS文件系统,格式化的时候可以使用su和sw选项指定RAID的chunk size和number of data disk,保持一致。
mkfs -t xfs -d su=64k,sw=4 /dev/san/lun1
对于ext4文件系统而言,我们需要掌握除了上面的信息还需要:
文件系统块大小(block size):文件系统块大小是文件系统使用的最小数据单元。它决定了文件在存储介质上的最小分配单位。较小的块大小可以提供更好的空间利用率,但在处理大文件时可能会增加磁盘开销。较大的块大小可以提高顺序读写的性能,但可能会导致对小文件的空间浪费。
使用这些信息可以计算stride和stride-width的值
stride是一个chunk中包含多少个文件系统block。比如对于64KiB的chunk磁盘阵列,如果文件系统block大小为4KiB,则stride=16。
strip-width是一个条带中包含多少文件系统block。
❝比如一个6块硬盘组成的RAID6,在RAID6中每个条带包含2个校验盘,所以就有
6-2=4块数据盘,一个条带有4个数据盘。这一个条带包含多少个文件系统block呢? 4(disk)* 16(stride) = 64 file system blocks per stripe。 4个硬盘代表4个chunk,每个chunk可以包含16个block,所以一个条带包含64个文件系统块。
# mkfs -t ext4 -E stride=16,stripe-width=64 /dev/san/lun1
通过逻辑卷配置RAID
RHEL8支持创建RAID级别的逻辑卷,目前支持RAID0,1,4,5,6, and 10
创建一个3G容量的RAID0级别逻辑卷,
-
--stripes 3: 这指定了要使用的条带数(即磁盘数量)为3。在RAID 0中,这意味着数据将被分割成3部分并分别存储在3个磁盘上。 -
--stripesize 4K: 这指定了每个条带的大小为4KB。这意味着每个磁盘上将存储4KB的数据块。
[root@localhost ~]# lvcreate --type raid0 -L 3G --stripes 3 --stripesize 4K -n raidlv radivg
选择IO分析工具
最简单的工具是使用top命令观察wa值
┌──[root@liruilongs.github.io]-[~]
└─$top
top - 10:52:58 up 10:41, 2 users, load average: 0.00, 0.00, 0.00
Tasks: 231 total, 1 running, 230 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.0 us, 25.0 sy, 0.0 ni, 75.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 15694.3 total, 14350.9 free, 910.1 used, 730.8 buff/cache
MiB Swap: 2048.0 total, 2048.0 free, 0.0 used. 14784.3 avail Mem
iostat
使用iostat命令输出了设备I/O统计信息
┌──[root@liruilongs.github.io]-[~]
└─$yum -y install sysstat
┌──[root@liruilongs.github.io]-[~]
└─$ iostat -Np
Linux 5.14.0-362.8.1.el9_3.x86_64 (liruilongs.github.io) 02/05/24 _x86_64_ (2 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.14 0.01 0.22 0.01 0.00 99.63
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
nvme0n1 14.28 13.25 67.45 0.00 511266 2602804 0
nvme0n1p1 0.02 1.51 0.06 0.00 58182 2130 0
nvme0n1p2 14.26 11.71 67.39 0.00 451888 2600674 0
sr0 0.00 0.08 0.00 0.00 2936 0 0
rl-root 14.36 11.17 67.39 0.00 431044 2600674 0
rl-swap 0.00 0.06 0.00 0.00 2220 0 0
┌──[root@liruilongs.github.io]-[~]
└─$
iotop
iotop 监控Linux系统中的磁盘I/O使用状况,实时显示系统中各个进程对I/O的使用情况。
┌──[root@liruilongs.github.io]-[~]
└─$yum -y install iotop
Total DISK READ : 0.00 B/s | Total DISK WRITE : 0.00 B/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE> COMMAND 1 be/4 root 0.00 B/s 0.00 B/s systemd --switched-root --system --deserialize 31
2 be/4 root 0.00 B/s 0.00 B/s [kthreadd]
3 be/0 root 0.00 B/s 0.00 B/s [rcu_gp]
4 be/0 root 0.00 B/s 0.00 B/s [rcu_par_gp]
5 be/0 root 0.00 B/s 0.00 B/s [slub_flushwq]
6 be/0 root 0.00 B/s 0.00 B/s [netns]
8 be/0 root 0.00 B/s 0.00 B/s [kworker/0:0H-events_highpri]
...................................
-
-o(--only)仅显示当前执行I/O操作的进程和线程信息 -
-P(--processes)显示进程信息 -
-a显示启动iotop命令开始的总的I/O数据信息
Blktrace
Blktrace是一个针对Linux内核中Block IO的跟踪工具,它能够记录I/O所经历的各个步骤,并从中分析是IO Scheduler慢还是硬件响应慢。这个工具可以在运行时捕获和记录块设备上的I/O操作,并提供详细的I/O请求队列信息,包括读写进程名、进程号、执行时间、读写物理块号、块大小等。
yum -y install blktrace
开始采集
┌──[root@liruilongs.github.io]-[~]
└─$ blktrace -d /dev/mapper/rl-root -o disk.log
User defined signal 1
结束
┌──[root@liruilongs.github.io]-[~]
└─$killall -SIGUSR1 blktrace
模拟测试
┌──[root@liruilongs.github.io]-[~]
└─$fio --name=randwrite --ioengine=libaio --iodepth=1 --rw=randwrite --bs=4K --direct=1 --size=512M --numjobs=5 --group_reporting --filename=/tmp/testfile
randwrite: (g=0): rw=randwrite, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=1
┌──[root@liruilongs.github.io]-[~]
└─$btt -i disk.log.blktrace.0
==================== All Devices ====================
ALL MIN AVG MAX N
--------------- ------------- ------------- ------------- -----------
Q2Qdm 0.000001070 0.000257360 17.654174647 655292
Q2Cdm 0.000054524 0.000268875 0.089907542 655281
==================== Device Overhead ====================
DEV | Q2G G2I Q2M I2D D2C
---------- | --------- --------- --------- --------- ---------
==================== Device Merge Information ====================
DEV | #Q #D Ratio | BLKmin BLKavg BLKmax Total
---------- | -------- -------- ------- | -------- -------- -------- --------
==================== Device Q2Q Seek Information ====================
DEV | NSEEKS MEAN MEDIAN | MODE
---------- | --------------- --------------- --------------- | ---------------
(253, 0) | 655293 362399.7 0 | 0(1798)
---------- | --------------- --------------- --------------- | ---------------
Overall | NSEEKS MEAN MEDIAN | MODE
Average | 655293 362399.7 0 | 0(1798)
......................................
pcp-system-tools
pcp-system-tools是一个用于监控系统性能的工具包,它提供了多种用于监控系统资源使用情况的工具。这个工具包与pcp(Performance Co-Pilot)框架一起使用,可以提供全面的系统性能监控解决方案。
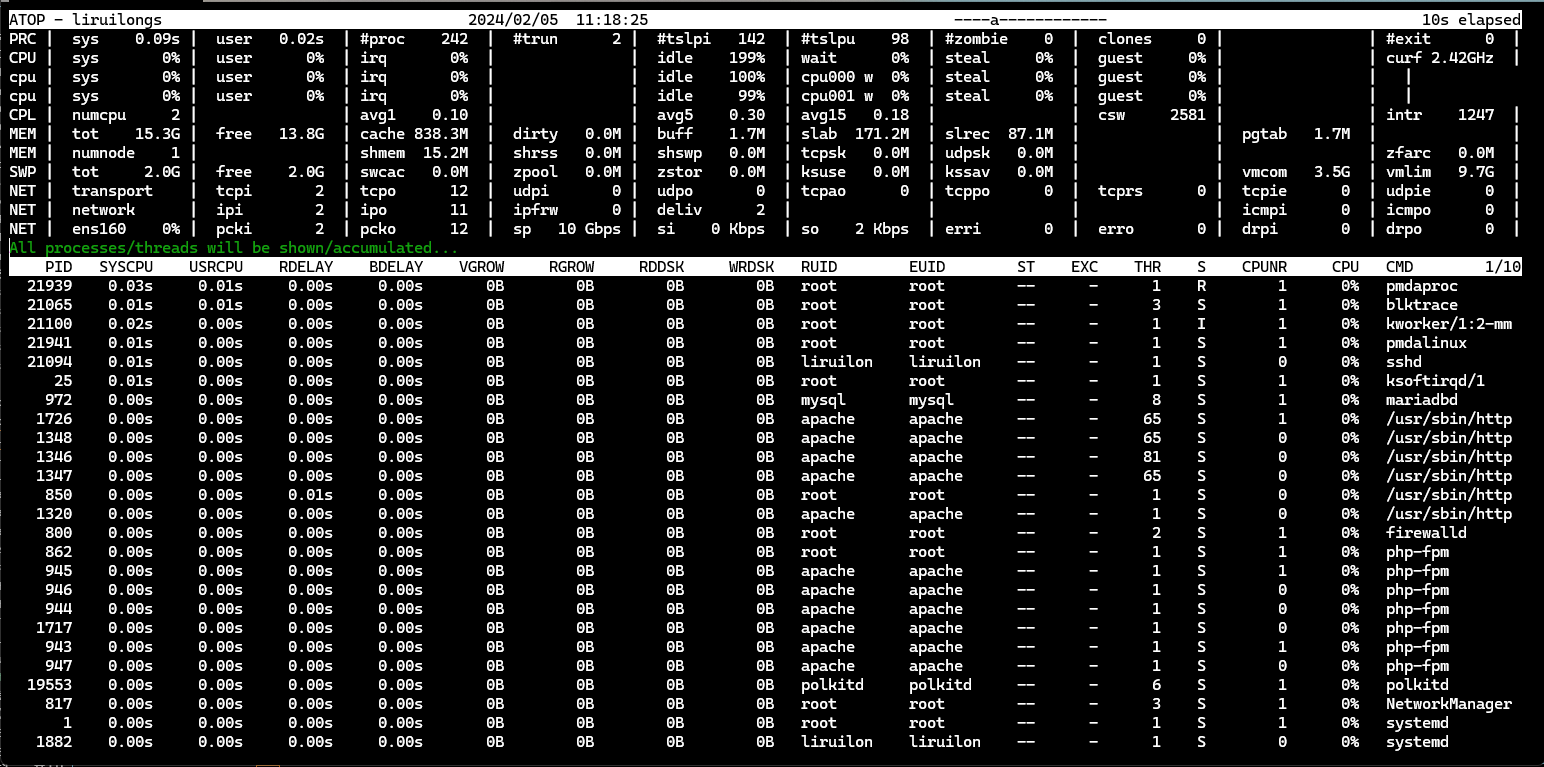 在这里插入图片描述
在这里插入图片描述
atop提供了对系统资源使用情况的全面视图,包括CPU、内存、磁盘I/O、网络等。它还提供了各种性能指标的实时和历史数据,以及对系统进程和资源的详细信息。
ATOP - liruilongs 2024/02/05 11:17:45 ----------------- 11h6m20s elapsedPRC | sys 0.04s | user 0.01s | #proc 243 | #trun 1 | #tslpi 142 | #tslpu 100 | #zombie 0 | clones 1 | | #exit 0 |CPU | sys 0% | user 0% | irq 0% | | idle 199% | wait 0% | steal 0% | guest 0% | | curf 2.42GHz |cpu | sys 0% | user 0% | irq 0% | | idle 99% | cpu001 w 0% | steal 0% | guest 0% | | |
cpu | sys 0% | user 0% | irq 0% | | idle 100% | cpu000 w 0% | steal 0% | guest 0% | | |
CPL | numcpu 2 | | avg1 0.19 | | avg5 0.35 | avg15 0.19 | | csw 2498 | | intr 1299 |MEM | tot 15.3G | free 13.8G | cache 838.3M | dirty 0.0M | buff 1.7M | slab 171.2M | slrec 87.1M | | pgtab 1.7M | |MEM | numnode 1 | | shmem 15.2M | shrss 0.0M | shswp 0.0M | tcpsk 0.0M | udpsk 0.0M | | | zfarc 0.0M |SWP | tot 2.0G | free 2.0G | swcac 0.0M | zpool 0.0M | zstor 0.0M | ksuse 0.0M | kssav 0.0M | | vmcom 3.5G | vmlim 9.7G |PAG | scan 0 | steal 0 | compact 0 | numamig 0 | migrate 0 | pgin 0 | pgout 64 | swin 0 | swout 0 | oomkill 0 |LVM | rl-root | busy 0% | read 0 | write 5 | discrd 0 | KiB/r 0 | KiB/w 12 | MBr/s 0.0 | MBw/s 0.0 | avio 0.0 ns |
DSK | nvme0n1 | busy 0% | read 0 | write 5 | discrd 0 | KiB/r 0 | KiB/w 12 | MBr/s 0.0 | MBw/s 0.0 | avio 0.80 ms |
NET | transport | tcpi 2 | tcpo 6 | udpi 0 | udpo 0 | tcpao 0 | tcppo 0 | tcprs 0 | tcpie 0 | udpie 0 |NET | network | ipi 2 | ipo 4 | ipfrw 0 | deliv 2 | | | | icmpi 0 | icmpo 0 |NET | ens160 0% | pcki 2 | pcko 6 | sp 10 Gbps | si 0 Kbps | so 0 Kbps | erri 0 | erro 0 | drpi 0 | drpo 0 |
PID SYSCPU USRCPU RDELAY BDELAY VGROW RGROW RDDSK WRDSK RUID EUID ST EXC THR S CPUNR CPU CMD 1/1 21939 0.02s 0.01s 0.00s 0.00s 416.0K 348.0K 0B 0B root root -- - 1 R 1 0% pmdaproc
21987 0.01s 0.00s 0.00s 0.00s 2.5M 2.4M 0B 0B root root -- - 1 S 1 0% pcp-atop 21100 0.01s 0.00s 0.00s 0.00s 0B 0B 0B 0B root root -- - 1 I 1 0% kworker/1:2-ev
850 0.00s 0.00s 0.00s 0.00s 0B 0B 0B 0B root root -- - 1 S 0 0% /usr/sbin/http
862 0.00s 0.00s 0.00s 0.00s 0B 0B 0B 0B root root -- - 1 S 1 0% php-fpm
21065 0.00s 0.00s 0.01s 0.00s 0B 0B 0B 0B root root -- - 3 S 0 0% blktrace
1 0.00s 0.00s 0.00s 0.00s 0B 0B 0B 0B root root -- - 1 S 1 0% systemd
21934 0.00s 0.00s 0.00s 0.00s 0B 0B 0B 0B pcp pcp -- - 1 S 0 0% pmcd
21941 0.00s 0.00s 0.00s 0.00s 0B 0B 0B 0B root root -- - 1 S 1 0% pmdalinux 21094 0.00s 0.00s 0.00s 0.00s 0B 712.0K 0B 0B liruilon liruilon -- - 1 S 0 0% sshd
801 0.00s 0.00s 0.00s 0.00s 0B 0B 0B 0B root root -- - 2 S 0 0% irqbalance 1929 0.00s 0.00s 0.00s 0.00s 0B 0B 0B 0B root root -- - 1 I 1 0% kworker/u256:0
16 0.00s 0.00s 0.00s 0.00s 0B 0B 0B 0B root root -- - 1 S 0 0% pr/tty0 17 0.00s 0.00s 0.00s 0.00s 0B 0B 0B 0B root root -- - 1 I 1 0% rcu_preempt 20419 0.00s 0.00s 0.00s 0.00s 0B 0B 0B 0B root root -- - 1 I 0 0% kworker/0:2-ev
500 0.00s 0.00s 0.00s 0.00s 0B 0B 0B 0B root root -- - 1 S 0 0% scsi_eh_21
25 0.00s 0.00s 0.00s 0.00s 0B 0B 0B 0B root root -- - 1 S 1 0% ksoftirqd/1
37 0.00s 0.00s 0.00s 0.00s 0B 0B 0B 0B root root -- - 1 S 1 0% kcompactd0
56 0.00s 0.00s 0.00s 0.00s 0B 0B 0B 0B root root -- - 1 I 0 0% kthrotld 98 0.00s 0.00s 0.00s 0.00s 0B 0B 0B 0B root root -- - 1 I 1 0% kworker/1:1H-k
649 0.00s 0.00s 0.01s 0.00s 0B 0B 0B 0B root root -- - 1 S 0 0% xfsaild/dm-0
21803 0.00s 0.00s 0.00s 0.00s 0B 0B 0B 0B root root -- - 1 I 0 0% kworker/u256:3
博文部分内容参考
© 文中涉及参考链接内容版权归原作者所有,如有侵权请告知,这是一个开源项目,如果你认可它,不要吝啬星星哦 :)
《 Red Hat Performance Tuning 442 》
© 2018-2023 liruilonger@gmail.com, All rights reserved. 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)

- 点赞
- 收藏
- 关注作者
评论(0)