Linux 可观测性 BPF&eBPF 以及 BCC&bpftrace 认知

写在前面
-
博文内容涉及: -
BPF和eBPF认知 -
BCC和bpftrace认知 -
BCC和bpftrace工具简单认知
-
-
理解不足小伙伴帮忙指正
对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃避方式,是对大众理想的懦弱回归,是随波逐流,是对内心的恐惧 ——赫尔曼·黑塞《德米安》
BPF和 eBPF 是什么
BPF 是 Berkeley Packet Filter(伯克利数据包过滤器)的缩写,诞生于1992年,其作用是提升网络包过滤工具的性能
2013年,Alexei Starovoitov 向Linux社区提交了重新实现BPF 的内核补丁, 和 Daniel Borkmann 共同完善后,在2014年正式并入 Linux 内核主线。
此举将BPF变成了一个更通用的执行引擎,可以创建先进的性能分析工具。
BPF提供了一种在各种内核事件和应用程序事件发生时运行一段小程序的机制。类似 JavaScript 中的事件处理机制,比如单机,双击鼠标触发的事件回调
BPF 则允许内核在系统和应用程序事件(如磁盘 I/O 事件)发生时运行一段小程序,这样就催生了新的系统编程技术。该技术将内核变得完全可编程,允许用户(包括非专业内核开发人员)定制和控制他们的系统,以解决现实问题。
BPF 是一项灵活而高效的技术,主要由下面几部分组成。由于它采用了虚拟指令集规范,因此也可将它视作一种虚拟机实现
-
指令集 -
存储对象 -
辅助函数
指令由 Linux 内核的 BPF 运行时模块执行,具体来说,该运行时模块提供两种执行机制:
-
解释器 -
即时 (JIT)编译器将 BPF 指令动态转换为本地化指令
在实际执行之前,BPF指令必须先通过验证器(verifer)的安全性检查,以确保 BPF 程序自身不会崩溃或者损坏内核
目前 BPF 的三个主要应用领域是 :
-
网络 -
可观测性 -
安全
eBPF : 扩展后的BPF通常缩写为eBPF,但官方的缩写仍然是BPF,不带e,事实上,在内核中只有一个执行引擎,即 BPF(扩展后的 BPF),它同时支持扩展后的 BPF和经典的 BPF 程序。
跟踪、嗅探、采样、剖析和可观测性分别是什么
跟踪(tracing)
是基于事件的记录一一这也是BPF 工具所使用的监测方式。
例如,Linux 下的strace(1),可以记录和打印系统调用(system call)事件的信息。有许多工具并不跟踪事件,而是使用固定的计数器统计监测事件的频次,然后打印出摘要信息,如Linux top()。
跟踪系统调用
┌──[root@vms100.liruilongs.github.io]-[~]
└─$strace ls -l
execve("/usr/bin/ls", ["ls", "-l"], 0x7ffeb7b94868 /* 41 vars */) = 0
brk(NULL) = 0x55b0705b1000
arch_prctl(0x3001 /* ARCH_??? */, 0x7fffbfa97d50) = -1 EINVAL (Invalid argument)
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=18335, ...}) = 0
mmap(NULL, 18335, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f9e45f5e000
close(3) = 0
.................................................................
fstat(3, {st_mode=S_IFREG|0755, st_size=33760, ...}) = 0
lseek(3, 26952, SEEK_SET) = 26952
......................................
跟踪工具的一个显著标志是,它具备 记录原始事件和事件元数据的能力。但是这类数据的数量不少,因此可能需要经过后续处理生成摘要信息。
strace(1) 的名字中有“trace”(跟踪)字样,但并非所有跟踪工具的名字中都带 “trace”,“tracing”一词也经常用于描述将 BPF 应用于可观测性方面的用途。
采样(sampling)
通过获取全部观测量的子集来描绘目标的大致图像;这也被称作生成性能剖析样本或profling。有一个BPF工具就叫profile(8),它基于计时器来对运行中的代码定时采样。采样工具的一个优点是,其性能开销比跟踪工具小,因为只对大量事件中的一部分进行测量。采样的缺点是,它只提供了一个大致的画像,会遗漏事件。
正在执行的线程的函数调用栈采样
┌──[root@vms100.liruilongs.github.io]-[~]
└─$profile
Sampling at 49 Hertz of all threads by user + kernel stack... Hit Ctrl-C to end.
^C
rcu_nocb_unlock_irqrestore
rcu_nocb_unlock_irqrestore
rcu_core
__softirqentry_text_start
irq_exit_rcu
irq_exit
smp_apic_timer_interrupt
__irqentry_text_start
pthread_mutex_unlock
[unknown]
- glance-api (3142)
...........................
可观测性(observability)
指通过全面观测来理解一个系统,可以实现这一目标的工具就可以归类为可观测性工具。这其中包括跟踪工具、采样工具和基于固定计数器的工具。但不包括基准测量 (benchmark) 工具,基准测量工具在系统上模拟业务负载会更改系统的状态。
当前涉及的 BPF 工具就属于可观测性工具,它们使用 BPF 技术进行可编程型跟踪分析。
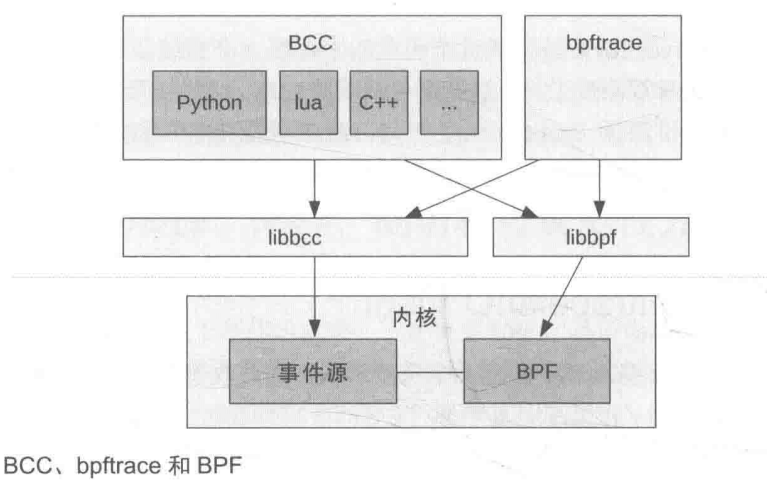
BCC、bpftrace和IO Visor
直接通过BPF 指令编写BPF程序是非常烦琐的,开发了可以提供高级语言编程支持的BPF前端;在跟踪用途方面,主要的前端是BCC和bpftrace。
BCC
BCC(BPF 编译器集合,BPF Compiler Collection)是最早用于开发 BPF 跟踪程序的高级框架。它提供了一个编写内核 BPF 程序的C语言环境,同时还提供了其他高级语言(如Python、Lua和C++)环境来实现用户端接口。它也是libbcc和 libbpf库'的前身,这两个库提供了使用BPF 程序对事件进行观测的库函数。
BCC源代码库中提供了 70多个BPF 工具,可以用来支持性能分析和排障工作。你可以在自己的系统上安装 BCC,无须自己动手编写任何 BCC代码.
bpftrace
bpftrace 是一个新近出现的前端,它提供了专门用于创建 BPF 工具的高级语言支持 ,bpftrace 工具的源代码非常简洁,因此本书中介绍相关工具时,可以直接带上源代码来展示具体的观测操作以及数据是如何被处理的。bpftrace 也是基于 libbcc 和 libbpf库进行构建的。
BCC和bpftrac 它们具有互补性:
 在这里插入图片描述
在这里插入图片描述
-
bpftrace在编写功能强大的单行程序短小的脚本方面甚为理想; -
BCC 则更适合开发复杂的脚本和作为后台进程使用,它还可以调用其他库的支持。比如,有不少用 Python 开发的 BCC程序,它们使用 Python 的 argparse库来提供复杂、精细的工具命令行参数支持。
ply
目前处在开发阶段的BPF 前端。它的设计目标是尽可能轻量化并且将依赖最小化,因此尤其适合在嵌入式Linux 环境下使用。如果ply 比 bpftrace更适合你的需求,
获取方式
BCC 和 bpftrace 不在内核代码仓库中,而是属于GitHub上的一个名为IOVisor https://github.com/iovisor 的Linux基金会项目。
 在这里插入图片描述
在这里插入图片描述
初识BCC:快速上手
bcc 是一个用于创建有效的内核跟踪和操作程序的工具包,它包括多个有用的工具和示例。使用扩展的BPF(伯克利分组过滤器),正式名称为eBPF,Linux3.15 中首次添加的一项新功能。BCC使用的大部分内容都需要Linux4.1或更高版本。
安装教程以及必备条件参考:https://github.com/iovisor/bcc/blob/master/INSTALL.md
当前实验环境
┌──[liruilong@liruilongs.github.io]-[~]
└─$hostnamectl
Static hostname: liruilongs.github.io
Icon name: computer-vm
Chassis: vm 🖴
Machine ID: 7deac2815b304f9795f9e0a8b0ae7765
Boot ID: 9ef333d031af42ed934eab41c98782e3
Virtualization: vmware
Operating System: Rocky Linux 9.3 (Blue Onyx)
CPE OS Name: cpe:/o:rocky:rocky:9::baseos
Kernel: Linux 5.14.0-362.8.1.el9_3.x86_64
Architecture: x86-64
Hardware Vendor: VMware, Inc.
Hardware Model: VMware Virtual Platform
Firmware Version: 6.00
安装工具集
┌──[liruilong@liruilongs.github.io]-[~]
└─$sudo dnf install bcc-tools
默认会安装到: /usr/share/bcc/tools/
┌──[liruilong@liruilongs.github.io]-[~]
└─$cd /usr/share/bcc/tools/
┌──[liruilong@liruilongs.github.io]-[/usr/share/bcc/tools]
└─$ls
argdist dbstat funclatency mysqld_qslower ppchcalls sofdsnoop tcplife
bashreadline dcsnoop funcslower netqtop profile softirqs tcpretrans
.....................................
funccount memleak phpstat shmsnoop tcpconnlat xfsdist
dbslower funcinterval mountsnoop pidpersec slabratetop tcpdrop xfsslower
环境变量配置
┌──[liruilong@liruilongs.github.io]-[/usr/share/bcc/tools]
└─$vim ~/.bash_profile
┌──[liruilong@liruilongs.github.io]-[/usr/share/bcc/tools]
└─$ 9L, 173B written
┌──[liruilong@liruilongs.github.io]-[/usr/share/bcc/tools]
└─$source ~/.bash_profile
┌──[liruilong@liruilongs.github.io]-[/usr/share/bcc/tools]
└─$cat ~/.bash_profile
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
PATH=$PATH:/usr/share/bcc/tools
# User specific environment and startup programs
┌──[liruilong@liruilongs.github.io]-[/usr/share/bcc/tools]
└─$
普通用户报错没有权限,需要 root 才行
┌──[liruilong@liruilongs.github.io]-[/usr/share/bcc/tools]
└─$execsnoop
modprobe: ERROR: could not insert 'kheaders': Operation not permitted
Unable to find kernel headers. Try rebuilding kernel with CONFIG_IKHEADERS=m (module) or installing the kernel development package for your running kernel version.
chdir(/lib/modules/5.14.0-362.8.1.el9_3.x86_64/build): No such file or directory
Traceback (most recent call last):
File "/usr/share/bcc/tools/execsnoop", line 243, in <module>
b = BPF(text=bpf_text)
File "/usr/lib/python3.9/site-packages/bcc/__init__.py", line 479, in __init__
raise Exception("Failed to compile BPF module %s" % (src_file or "<text>"))
Exception: Failed to compile BPF module <text>
提权提示找不到命令
┌──[liruilong@liruilongs.github.io]-[/usr/share/bcc/tools]
└─$sudo execsnoop
[sudo] password for liruilong:
sudo: execsnoop: command not found
切 root 然后配置一下
┌──[liruilong@liruilongs.github.io]-[/usr/share/bcc/tools]
└─$sudo -i
[root@liruilongs ~]# vim ~/.bashrc
[root@liruilongs ~]# vim ~/.bash_profile
[root@liruilongs ~]# source ~/.bash_profile
┌──[root@liruilongs.github.io]-[~]
└─$
execsnoop(8): 跟踪每个新创建的进程,并且为每次进程创建打印一行信息。它通过跟踪execve(2)系统调用来工作。execve(2)是exec(2)系统调用的一个变体(也因而得名)
┌──[root@liruilongs.github.io]-[~]
└─$execsnoop
PCOMM PID PPID RET ARGS
top 22098 22067 0 /usr/bin/top
ps 22099 22067 0 /usr/bin/ps
execsnoop(8)带上命令行参数-t后,会增加一列时间戳输出:
┌──[root@vms100.liruilongs.github.io]-[~]
└─$execsnoop -t
TIME(s) PCOMM PID PPID RET ARGS
0.437 runc 84719 2258 0 /usr/bin/runc --root /var/run/docker/runtime-runc/moby --log /run/containerd/io.containerd.runtime.v2.task/moby/5c09e1cd52c9e46b37bd395293f3d5553608a1487170b3b7e3b8e6616ad66861/log.json --log-format json exec --process /tmp/runc-process1711123088 --detach --pid-file /run/containerd/io.containerd.runtime.v2.task/moby/5c09e1cd52c9e46b37bd395293f3d5553608a1487170b3b7e3b8e6616ad66861/e030b7417387 5c09e1cd52c9e46b37bd395293f3d5553608a1487170b3b7e3b8e6616ad66861
0.462 exe 84727 84719 0 /proc/self/exe init
0.514 sh 84729 84719 0 /bin/sh -c healthcheck_curl http://192.168.26.100:80
0.517 healthcheck_cur 84729 84719 0 /usr/local/bin/healthcheck_curl http://192.168.26.100:80
0.522 curl 84734 84729 0 /usr/bin/curl -q -g -k -s -S --fail -o /dev/null --max-time 10 --user-agent curl-healthcheck --write-out \n%{http_code} %{remote_ip}:%{remote_port} %{time_total} seconds\n http://192.168.26.100:80
...........................................................m
1.281 curl 84781 84775 0 /usr/bin/curl -q -g -k -s -S --fail -o /dev/null --max-time 10 --user-agent curl-healthcheck --write-out \n%{http_code} %{remote_ip}:%{remote_port} %{time_total} seconds\n http://192.168.26.100:9292
^C┌──[root@vms100.liruilongs.github.io]-[~]
└─$
┌──[root@vms100.liruilongs.github.io]-[~]
└─$execsnoop -T
TIME PCOMM PID PPID RET ARGS
01:49:59 clustercheck 86328 2039 0 /usr/bin/clustercheck
01:49:59 mysql 86330 86329 0 /usr/bin/mysql -nNE --connect-timeout=10 --user=haproxy --password= --host=192.168.26.100 --port=3306 -e SHOW STATUS LIKE 'wsrep_local_state';
01:49:59 tail 86331 86329 0 /usr/bin/tail -1
01:49:59 sleep 86332 86328 0 /usr/bin/sleep 0.1
01:49:59 runc 86333 1863 0 /usr/bin/runc --root /var/run/docker/runtime-runc/moby --log /run/containerd/io.containerd.runtime.v2.task/moby/bf92d0426c354f8c378d27e51716d3df978143c0a63fb9d614841bec210080e4/log.json --log-format json exec --process /tmp/runc-process3051711556 --detach --pid-file /run/containerd/io.containerd.runtime.v2.task/moby/bf92d0426c354f8c378d27e51716d3df978143c0a63fb9d614841bec210080e4/34ea8b434d4e bf92d0426c354f8c378d27e51716d3df978143c0a63fb9d614841bec210080e4
01:49:59 clustercheck 86336 2039 0 /usr/bin/clustercheck
01:49:59 tail 86339 86337 0 /usr/bin/tail -1
01:49:59 mysql 86338 86337 0 /usr/bin/mysql -nNE --connect-timeout=10 --user=haproxy --password= --host=192.168.26.100 --port=3306 -e SHOW STATUS LIKE 'wsrep_local_state';
01:49:59 check_alive.sh 86342 3186 0 /check_alive.sh
01:49:59 socat 86344 86342 0 /usr/bin/socat unix-connect:/var/lib/kolla/haproxy/haproxy.sock stdio
............................................................................
01:50:00 id 86369 86367 0 /usr/bin/id -un
01:50:00 id 86370 86367 0 /usr/bin/id -un
execsnoop(8) 的输出可以用来辅助支撑一个性能分析方法论:业务负载画像(workload characterization)
业务负载画像方法论其实很简单,就是给当前业务负载定性。理解了业务负载,很多时候就足够解决问题了,这避免了深入分析延迟问题,也不需要进行下钻分析 (drill-down analysis)。
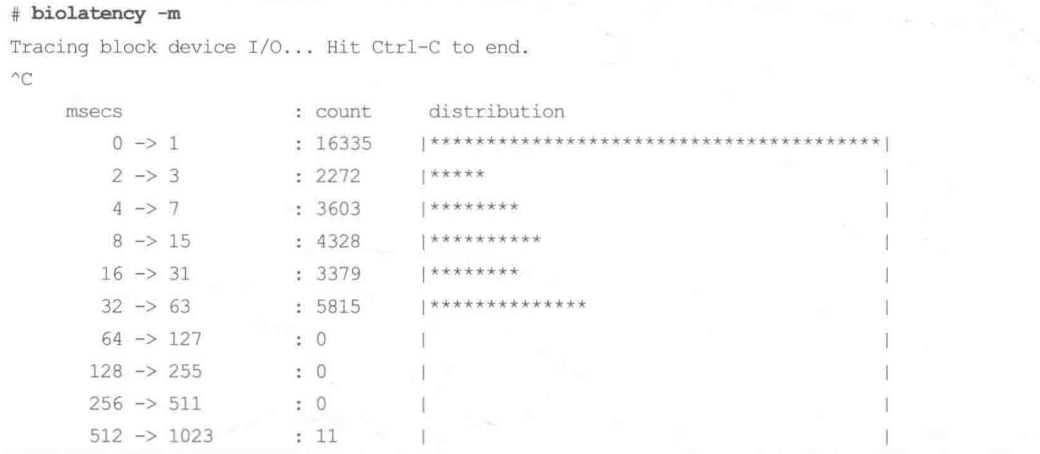
execsnoop(8) 会在每个进程创建时打印信息,而其他一些 BPF 工具则可以高效地计算摘要统计信息。另一个可以快速上手的工具是 biolatency(8),它可以绘制块设备I/O(diskI/0)的延迟直方图。
下面是在一台生产环境中的数据库服务器上运行biolatency(8)的输出,该数据库对延迟非常敏感,因为该服务的服务质量目标(service levelagreement)只有几毫秒。
 在这里插入图片描述
在这里插入图片描述
当biolatency(8)工具运行时会监测块I/O事件,它们的延迟信息通过BPF程序进行计算和统计。当工具停止执行后(用户按下 Ctrl+C 组合键),摘要信息就被打印出来了笔者使用了命令行参数-m来使得统计值以毫秒为单位输出。
┌──[root@liruilongs.github.io]-[~]
└─$biolatency
Tracing block device I/O... Hit Ctrl-C to end.
^C
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 0 | |
16 -> 31 : 0 | |
32 -> 63 : 0 | |
64 -> 127 : 2 |** |
128 -> 255 : 11 |*********** |
256 -> 511 : 14 |************** |
512 -> 1023 : 39 |****************************************|
┌──[liruilong@liruilongs.github.io]-[~]
└─$dd if=/dev/zero of=output.txt bs=1000M count=10
10+0 records in
10+0 records out
10485760000 bytes (10 GB, 9.8 GiB) copied, 8.31509 s, 1.3 GB/s
┌──[root@liruilongs.github.io]-[~]
└─$biolatency -m
Tracing block device I/O... Hit Ctrl-C to end.
^C
msecs : count distribution
0 -> 1 : 12623 |****************************************|
2 -> 3 : 302 | |
4 -> 7 : 12 | |
┌──[root@liruilongs.github.io]-[~]
└─$
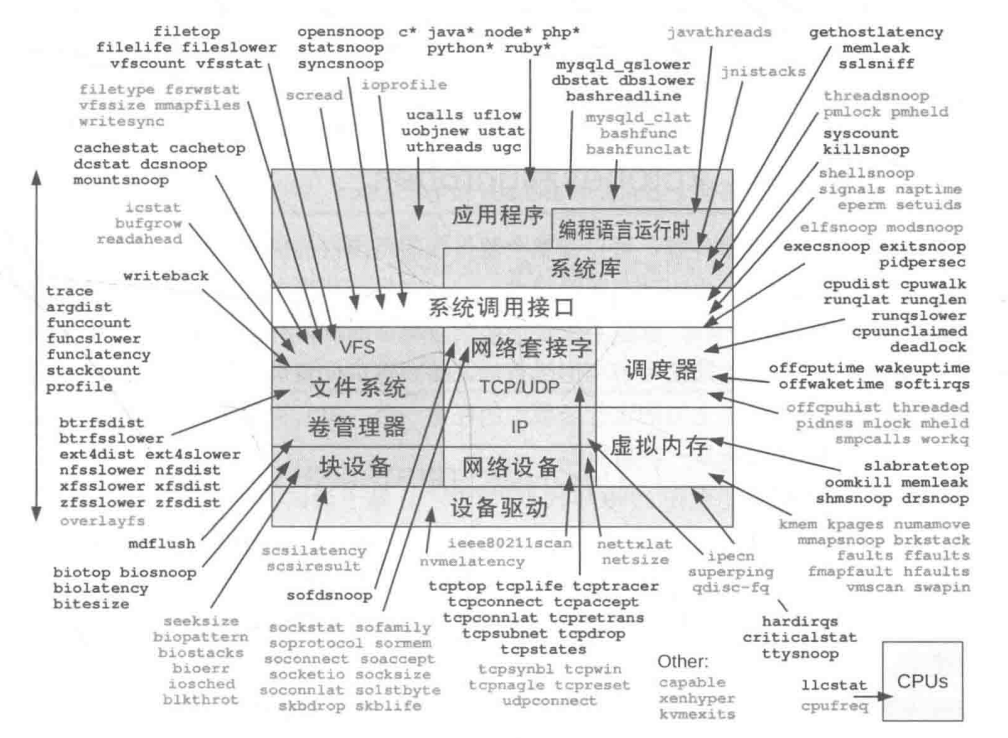
BPF跟踪的能见度
BPF跟踪可以在整个软件栈范围内提供能见度,允许我们随时根据需要开发新的工具和监测功能。在生产环境中可以立刻部署BPF跟踪程序,不需要重启系统,也不需要以特殊方式重启应用软件
 在这里插入图片描述
在这里插入图片描述
动态跟踪:kprobes和 uprobes
也叫动态插桩技术,在生产环境中对正在运行的软件插入观测点的能力。在未启用时,软件不受任何影响,动态插桩的开销为零。
Linux系统中的第一个动态插桩技术实现,是一个IBM团队在2000年开发的 DProbes 技术,源自 DProbes 的对内核函数的动态插桩(kprobes),最终于2004年正式进入内核,
2012年,Linux以uprobes形式增加了对用户态函数的动态插桩支持。BPF跟踪工具既支持kprobes又支持uprobes,因而也就支持对整个软件栈进行动态插桩。
静态跟踪:tracepoint(内核跟踪点)和USDT
动态插桩技术有一点不好:随着软件版本的变更,被插桩的函数有可能被重新命名,或者被移除。这属于接口稳定性问题。当对内核或者应用软件升级之后,可能会出现BPF工具无法正常工作的情况。
对于稳定性问题和内联问题,有一个统一的解决办法,那就是改用静态插桩技术, 静态插桩会将稳定的事件名字编码到软件代码中,由开发者进行维护。
BPF跟踪工具支持内核的静态跟踪点插桩技术,也支持用户态的静态定义跟踪插桩技术USDT(userlevelstatically defined tracing)。
静态插桩技术也有美中不足:插点会增加开发者的维护成本,因此即使软件中存在静态插桩点,通常数量也十分有限。
上面提到的这些细节,除非需要开发自己的 BPF 工具,一般不需要关注。如果确实需要开发,一个推荐的策略是,首先尝试使用静态跟踪技术(跟踪点或者USDT),如果不够的话再转而使用动态跟踪技术(kprobes或uprobes)。
初识bpftrace:跟踪open()
┌──[root@liruilongs.github.io]-[~]
└─$bpftrace -e 'tracepoint:syscalls:sys_enter_open printf("%s %s n", comm,str(args->filename));}'
-bash: bpftrace: command not found
bpftrace 也需要安装一下,安装包默认就是命令的名字
┌──[root@liruilongs.github.io]-[~]
└─$yum provides bpftrace
Last metadata expiration check: 0:32:51 ago on Sat Jan 13 19:19:05 2024.
bpftrace-0.17.0-2.el9.x86_64 : High-level tracing language for Linux eBPF
Repo : appstream
Matched from:
Provide : bpftrace = 0.17.0-2.el9
┌──[root@liruilongs.github.io]-[~]
└─$dnf -y install bpftrace
....
┌──[root@liruilongs.github.io]-[~]
└─$which bpftrace
/bin/bpftrace
通过为 bpftrace`` 的命令行加参数-l和通配符的方式,列出所有的与open`系统调用相关的跟踪点,或者叫追踪点
open是一个系统调用(System Call),用于在操作系统中打开文件或创建新文件。
┌──[root@liruilongs.github.io]-[~]
└─$bpftrace -l "tracepoint:syscalls:sys_enter_open*"
tracepoint:syscalls:sys_enter_open
tracepoint:syscalls:sys_enter_open_by_handle_at
tracepoint:syscalls:sys_enter_open_tree
tracepoint:syscalls:sys_enter_openat
tracepoint:syscalls:sys_enter_openat2
┌──[root@liruilongs.github.io]-[~]
└─$
当前看的的这些就为静态的跟踪点,或者叫静态插桩点。
通过下面的 bpftrace 编码我们可以捕获 sys_enter_open 系统调用事件。类似 JavaScript`` 中使用onclick` 来捕获点击事件。
┌──[root@liruilongs.github.io]-[~]
└─$bpftrace -e 'tracepoint:syscalls:sys_enter_open printf("%s %s n", comm,str(args->filename));}'
stdin:1:36-43: ERROR: syntax error, unexpected (, expecting {
tracepoint:syscalls:sys_enter_open printf("%s %s n", comm,str(args->filename));}
~~~~~~~
┌──[root@liruilongs.github.io]-[~]
└─$bpftrace -e 'tracepoint:syscalls:sys_enter_open { printf("%s %s n", comm,str(args->filename));}'
Attaching 1 probe...
BPF程序被定义在单引号所包围的代码内,当敲击 Enter 键运行 bpftrace 命令时它会立即被编译并且运行。
而当按下Ctrl+C`` 组合键结束命令执行时,open(2)的跟踪点就被禁用了,相应地,BPF 小程序也会被移除。这就是 BPF 跟踪工具提供的按需插桩的工作方式:它们只在相关命令的存活期间被激活`,观测时间可以短至几秒。
上面的命令中并没有捕获到事件,sys_enter_open 在这段时间并没有发生调用。换一种方式
┌──[root@liruilongs.github.io]-[~]
└─$bpftrace -e 'tracepoint:syscalls:sys_enter_open* { @[probe] = count(); }'
Attaching 5 probes...
^C
@[tracepoint:syscalls:sys_enter_openat]: 2321
┌──[root@liruilongs.github.io]-[~]
└─$
命令中的BPFtrace脚本使用tracepoint:syscalls:sys_enter_open*追踪点来捕获open系统调用及其变体的进入事件。@[probe]表示要创建一个BPF Map,用于存储每个追踪点事件的计数。count()函数用于递增计数器。
通过输出可以看到 sys_enter_openat 被调用了2321 次
实际上 bpftrace 自带了opensnoop.bt,这个工具可以同时对每个系统调用的开始和结束位置进行跟踪,然后将结果分列输出:
查看脚本位置
┌──[root@liruilongs.github.io]-[~]
└─$rpm -ql bpftrace | grep opensnoop
/usr/share/bpftrace/tools/doc/opensnoop_example.txt
/usr/share/bpftrace/tools/opensnoop.bt
/usr/share/man/man8/opensnoop.bt.8.gz
帮助文档查看
┌──[root@liruilongs.github.io]-[~]
└─$cat /usr/share/bpftrace/tools/doc/opensnoop_example.txt
...........
Example output:
# ./opensnoop.bt
Attaching 3 probes...
Tracing open syscalls... Hit Ctrl-C to end.
PID COMM FD ERR PATH
2440 snmp-pass 4 0 /proc/cpuinfo
2440 snmp-pass 4 0 /proc/stat
............
简单使用
┌──[root@vms100.liruilongs.github.io]-[~]
└─$/usr/share/bpftrace/tools/opensnoop.bt
Attaching 6 probes...
Tracing open syscalls... Hit Ctrl-C to end.
PID COMM FD ERR PATH
970 tuned 16 0 /proc/9218/cmdline
9218 curl 4 0 /dev/null
961 updatedb 19 0 .
970 tuned 16 0 /proc/9218/stat
6826 event_loop 88 0 /etc/hosts
961 updatedb 20 0 .
961 updatedb 21 0 .
961 updatedb 22 0 .
1072 dockerd 173 0 /var/lib/docker/containers/bf92d0426c354f8c378d27e51716d3df9781
..........................................................
3403 9_dirty_io_sche -1 2 /usr/lib/rabbitmq/lib/rabbitmq_server-3.9.29/plugins/rabbitmq_p
3403 9_dirty_io_sche -1 2 /usr/lib/rabbitmq/lib/rabbitmq_server-3.9.29/plugins/rabbitmq_p
9219 sshd 9 0 /proc/self/oom_score_adj
脚本内容查看
┌──[root@liruilongs.github.io]-[~]
└─$cat /usr/share/bpftrace/tools/opensnoop.bt
#!/usr/bin/bpftrace
/*
* opensnoop Trace open() syscalls.
* For Linux, uses bpftrace and eBPF.
*
* Also a basic example of bpftrace.
*
* USAGE: opensnoop.bt
*
* This is a bpftrace version of the bcc tool of the same name.
*
* Copyright 2018 Netflix, Inc.
* Licensed under the Apache License, Version 2.0 (the "License")
*
* 08-Sep-2018 Brendan Gregg Created this.
*/
BEGIN
{
printf("Tracing open syscalls... Hit Ctrl-C to end.\n");
printf("%-6s %-16s %4s %3s %s\n", "PID", "COMM", "FD", "ERR", "PATH");
}
tracepoint:syscalls:sys_enter_open,
tracepoint:syscalls:sys_enter_openat
{
@filename[tid] = args->filename;
}
tracepoint:syscalls:sys_exit_open,
tracepoint:syscalls:sys_exit_openat
/@filename[tid]/
{
$ret = args->ret;
$fd = $ret >= 0 ? $ret : -1;
$errno = $ret >= 0 ? 0 : - $ret;
printf("%-6d %-16s %4d %3d %s\n", pid, comm, $fd, $errno,
str(@filename[tid]));
delete(@filename[tid]);
}
END
{
clear(@filename);
}
┌──[root@liruilongs.github.io]-[~]
└─$
opensnoop.bt 的bpftrace脚本,用于跟踪open()系统调用。它以脚本的形式使用bpftrace和eBPF来实现。
脚本简单说明:
该脚本的功能是跟踪进程执行的open()系统调用,并打印相关信息,包括进程ID(PID)、进程命令(COMM)、文件描述符(FD)、错误码(ERR)和文件路径(PATH)。可以通过运行该脚本来监视系统中发生的open()和openat()系统调用,并了解进程打开文件的情况
脚本的执行逻辑如下:
BEGIN块在脚本开始时执行,打印跟踪提示信息。
-
tracepoint:syscalls:sys_enter_open和tracepoint:syscalls:sys_enter_openat是用于跟踪open()和openat()系统调用的进入跟踪点。 -
当进入这些系统调用时,将保存相应 线程的文件名(args->filename)到@filename[tid]中,其中tid表示线程ID。 -
tracepoint:syscalls:sys_exit_open和tracepoint:syscalls:sys_exit_openat是用于跟踪open()和openat()系统调用的退出跟踪点。 -
当退出这些系统调用时,从 @filename[tid]中获取文件名,并打印相关信息,包括进程ID、进程命令、文件描述符、错误码和文件路径。 -
打印完信息后,从@filename[tid]中删除相应的文件名。 -
END块在脚本结束时执行,清除@filename变量。
bpftrace 自带的一些其他的脚本
┌──[root@liruilongs.github.io]-[~]
└─$rpm -ql bpftrace | egrep "*.bt$"
/usr/share/bpftrace/tools/bashreadline.bt
/usr/share/bpftrace/tools/biolatency.bt
/usr/share/bpftrace/tools/biosnoop.bt
/usr/share/bpftrace/tools/biostacks.bt
/usr/share/bpftrace/tools/bitesize.bt
/usr/share/bpftrace/tools/capable.bt
/usr/share/bpftrace/tools/cpuwalk.bt
.......................
/usr/share/bpftrace/tools/undump.bt
/usr/share/bpftrace/tools/vfscount.bt
/usr/share/bpftrace/tools/vfsstat.bt
/usr/share/bpftrace/tools/writeback.bt
/usr/share/bpftrace/tools/xfsdist.bt
┌──[root@liruilongs.github.io]-[~]
└─$
1.9 再回到BCC:跟踪open()
BCC 工具集也有相同的跟踪文件打开操作的工具
┌──[root@liruilongs.github.io]-[~]
└─$which opensnoop
/usr/share/bcc/tools/opensnoop
直接运行即可
┌──[root@liruilongs.github.io]-[~]
└─$opensnoop
PID COMM FD ERR PATH
782 NetworkManager 22 0 /var/lib/NetworkManager/internal-46d62731-5d04-3015-89e4-91b63f881d9a-ens160.lease.YBUMH2
782 NetworkManager 22 0 /var/lib/NetworkManager
693 systemd-journal 21 0 /proc/782/comm
693 systemd-journal 21 0 /proc/782/cmdline
693 systemd-journal 21 0 /proc/782/status
693 systemd-journal 21 0 /proc/782/sessionid
693 systemd-journal 21 0 /proc/782/loginuid
693 systemd-journal 21 0 /proc/782/cgroup
693 systemd-journal -1 2 /run/systemd/units/log-extra-fields:NetworkManager.service
693 systemd-journal 21 0 /run/log/journal/7deac2815b304f9795f9e0a8b0ae7765
1 systemd 19 0 /proc/693/cgroup
两个工具的区别:
-
bpftrace工具通常比较简单,功能单一,只做一件事情 -
BCC工具则一般比较复杂支持的运行模式也比较多.
你可以通过修改bpftrace版本的opensnoop 工具只显示失败的 open 系统调用,而 BCC 版本则通过命令行参数(-x)直接支持了这一功能:
帮助文档查看 ./opensnoop -x # only show failed opens
┌──[root@liruilongs.github.io]-[~]
└─$opensnoop -h
usage: opensnoop [-h] [-T] [-U] [-x] [-p PID] [-t TID] [--cgroupmap CGROUPMAP] [--mntnsmap MNTNSMAP]
[-u UID] [-d DURATION] [-n NAME] [-e] [-f FLAG_FILTER] [-F] [-b BUFFER_PAGES]
Trace open() syscalls
optional arguments:
-h, --help show this help message and exit
-T, --timestamp include timestamp on output
-U, --print-uid print UID column
-x, --failed only show failed opens
-p PID, --pid PID trace this PID only
-t TID, --tid TID trace this TID only
--cgroupmap CGROUPMAP
trace cgroups in this BPF map only
--mntnsmap MNTNSMAP trace mount namespaces in this BPF map only
-u UID, --uid UID trace this UID only
-d DURATION, --duration DURATION
total duration of trace in seconds
-n NAME, --name NAME only print process names containing this name
-e, --extended_fields
show extended fields
-f FLAG_FILTER, --flag_filter FLAG_FILTER
filter on flags argument (e.g., O_WRONLY)
-F, --full-path show full path for an open file with relative path
-b BUFFER_PAGES, --buffer-pages BUFFER_PAGES
size of the perf ring buffer (must be a power of two number of pages and
defaults to 64)
examples:
./opensnoop # trace all open() syscalls
./opensnoop -T # include timestamps
./opensnoop -U # include UID
./opensnoop -x # only show failed opens
./opensnoop -p 181 # only trace PID 181
./opensnoop -t 123 # only trace TID 123
./opensnoop -u 1000 # only trace UID 1000
./opensnoop -d 10 # trace for 10 seconds only
./opensnoop -n main # only print process names containing "main"
./opensnoop -e # show extended fields
./opensnoop -f O_WRONLY -f O_RDWR # only print calls for writing
./opensnoop -F # show full path for an open file with relative path
./opensnoop --cgroupmap mappath # only trace cgroups in this BPF map
./opensnoop --mntnsmap mappath # only trace mount namespaces in the map
跟踪进程打开的文件失败的情况,并显示文件的路径,包括符号链接的解析结果,
┌──[root@vms100.liruilongs.github.io]-[~]
└─$opensnoop -x
PID COMM FD ERR PATH
970 tuned -1 2 /proc/32357/cmdline
970 tuned -1 2 /proc/32357/stat
970 tuned -1 2 /proc/32357/stat
970 tuned -1 2 /proc/32357/cmdline
970 tuned -1 2 /proc/32357/stat
970 tuned -1 2 /proc/32357/stat
32349 erl -1 6 /dev/tty
32349 erl -1 2 /lib64/glibc-hwcaps/x86-64-v3/libnss_sss.so.2
..........................................................................
32349 erl -1 2 /usr/lib64/haswell/libnss_sss.so.2
32349 erl -1 2 /usr/lib64/x86_64/libnss_sss.so.2
32349 erl -1 2 /usr/lib64/libnss_sss.so.2
970 tuned -1 2 /proc/32359/cmdline
970 tuned -1 2 /proc/32359/stat
970 tuned -1 2 /proc/32359/stat
32349 10_dirty_io_sch -1 2 ./start_clean.boot
总结
BPF 工具可以用来辅助性能分析和故障定位工作,有两个主要项目提供了这些工具:BCC和bpftrace。它们运行需的动态和静态插桩(跟踪)技术。
博文部分内容参考
© 文中涉及参考链接内容版权归原作者所有,如有侵权请告知,这是一个开源项目,如果你认可它,不要吝啬星星哦 :)
《BPF Performance Tools》
iovisor: https://github.com/iovisor/
© 2018-2023 liruilonger@gmail.com, All rights reserved. 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)

- 点赞
- 收藏
- 关注作者
评论(0)