如何获取局域网内海康摄像头的IP地址

@[toc]
问题
在房间里部署了很多海康摄像头,但是却不知道IP地址,如何才能获取到这些摄像头的IP地址呢?
解决方法
海康提供了一个工具,将其下载后安装即可,下载地址:
https://www.hikvision.com/cn/support/tools/hitools/clea8b3e4ea7da90a9/
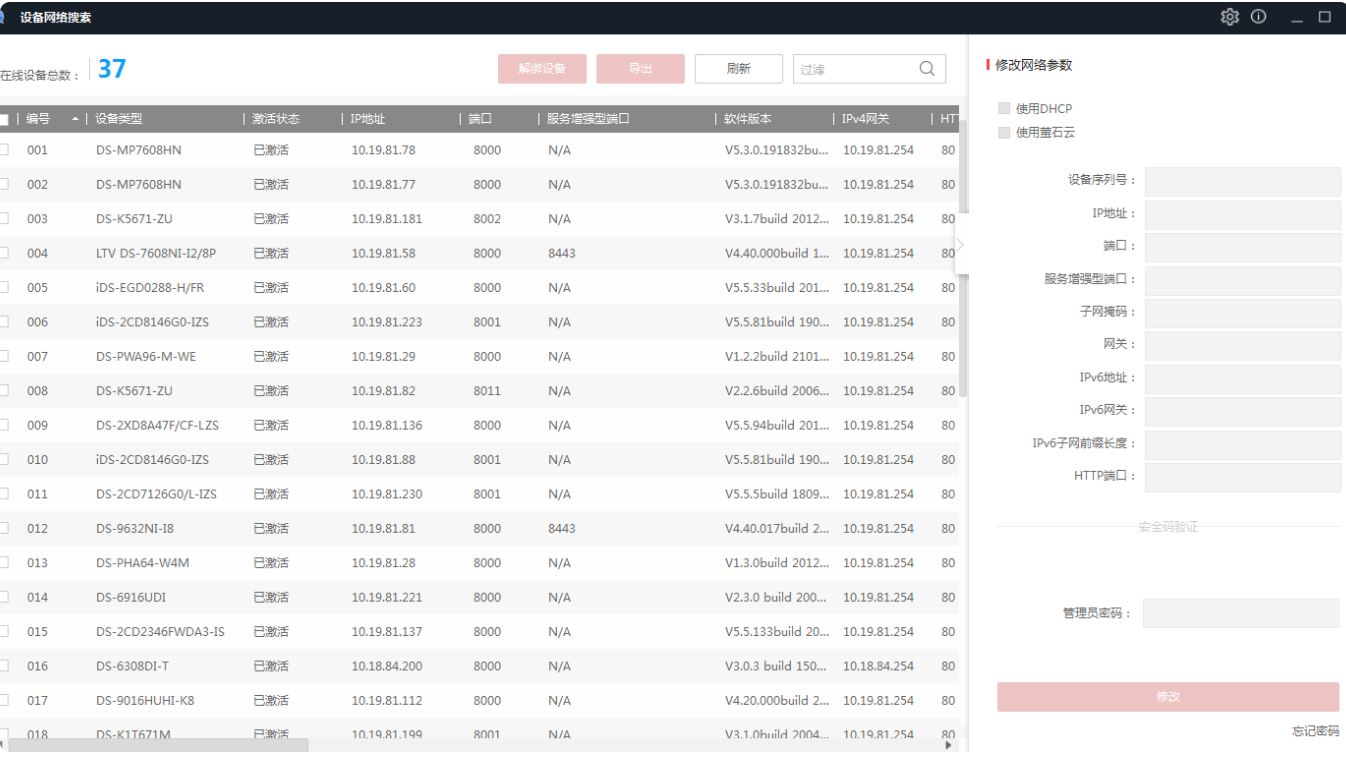
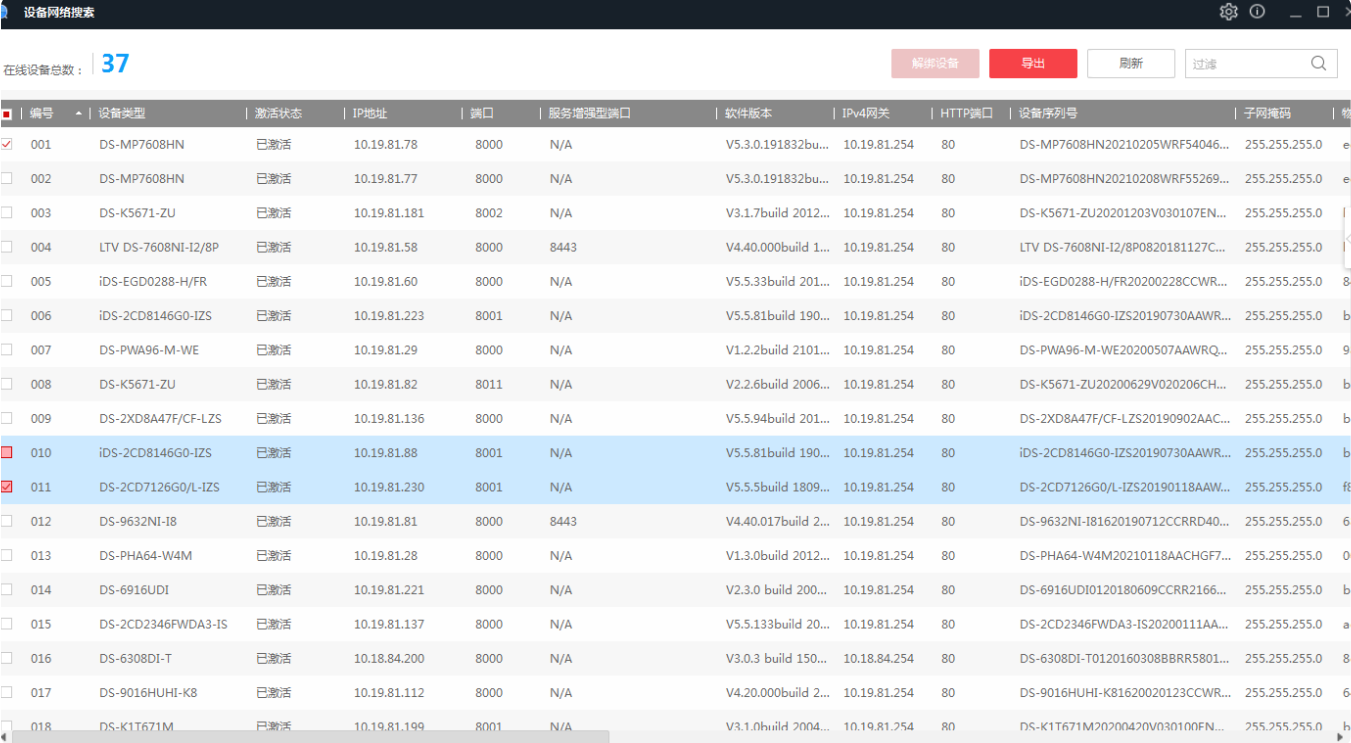
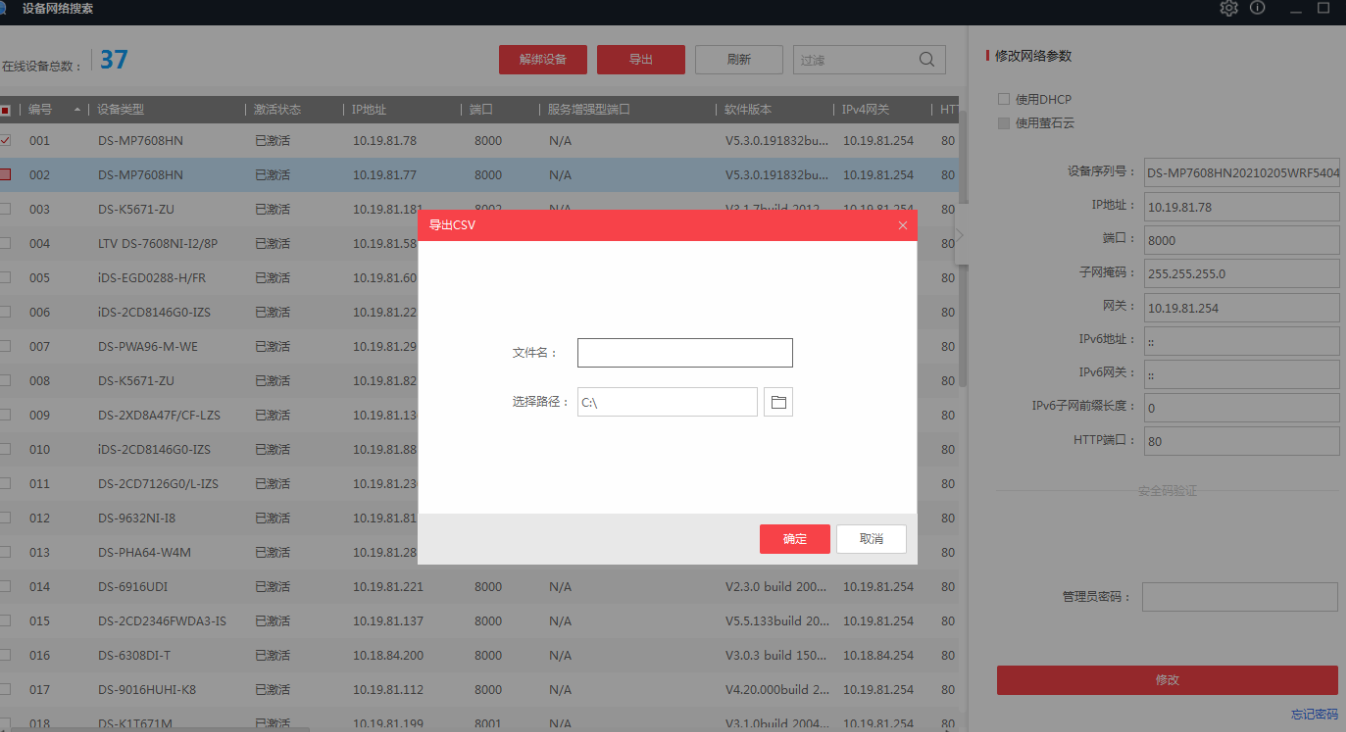
通过SADP软件搜索局域网内所在网段的在线设备。同时支持查看设备信息、激活设备、修改设备的网络参数、重置设备密码等功能
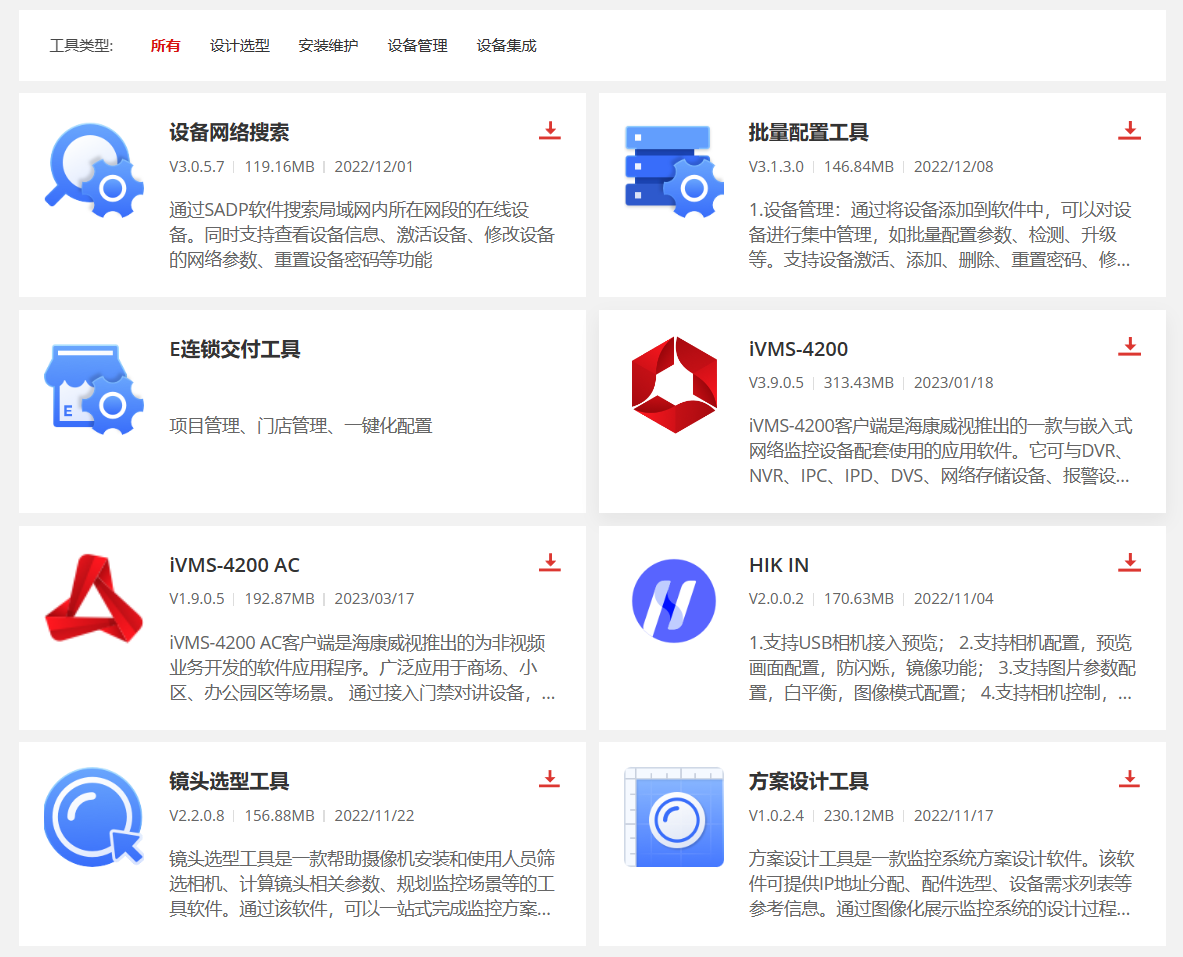
还有更多的工具,链接:
https://www.hikvision.com/cn/support/tools/hitools/
@[toc]
图像分类网络

AlexNet
VGGNet
GooLeNet系列
ResNet
DenseNet
Swin Transformer
【第49篇】Swin Transformer V2:扩展容量和分辨率
MAE
CoAtNet
【第22篇】CoAtNet:将卷积和注意力结合到所有数据大小上
ConvNeXtV1、V2
【第25篇】力压Tramsformer,ConvNeXt成了CNN的希望
【第64篇】ConvNeXt V2论文翻译:ConvNeXt V2与MAE激情碰撞
MobileNet系列
【第26篇】MobileNets:用于移动视觉应用的高效卷积神经网络
MPViT
VIT
SWA
EfficientNet系列
【第34篇】 EfficientNetV2:更快、更小、更强——论文翻译
MOBILEVIT
【第35篇】MOBILEVIT:轻量、通用和适用移动设备的Vision Transformer
EdgeViTs
【第37篇】EdgeViTs: 在移动设备上使用Vision Transformers 的轻量级 CNN
MixConv
RepLKNet
【第39篇】RepLKNet将内核扩展到 31x31:重新审视 CNN 中的大型内核设计
TransFG
【第40篇】TransFG:用于细粒度识别的 Transformer 架构
ConvMAE
【第41篇】ConvMAE:Masked Convolution 遇到 Masked Autoencoders
MicroNet
【第42篇】MicroNet:以极低的 FLOP 实现图像识别
RepVGG
MaxViT
MAFormer
【第53篇】MAFormer: 基于多尺度注意融合的变压器网络视觉识别
GhostNet系列
【第57篇】RepGhost:一个通过重新参数化实现硬件高效的Ghost模块
DEiT系列
【第58篇】DEiT:通过注意力训练数据高效的图像transformer &蒸馏
MetaFormer
RegNet
InternImage
【第73篇】InternImage:探索具有可变形卷积的大规模视觉基础模型
FasterNet
【第74篇】 FasterNet:CVPR2023年最新的网络,基于部分卷积PConv,性能远超MobileNet,MobileVit
注意力机制
物体检测
【第11篇】微软发布的Dynamic Head,创造COCO新记录:60.6AP
【第12篇】Sparse R-CNN: End-to-End Object Detection with Learnable Proposals
【第13篇】CenterNet2论文解析,COCO成绩最高56.4mAP
【第31篇】探索普通视觉Transformer Backbones用于物体检测
【第45篇】YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
行人属性识别
行人跟踪
【第65篇】SMILEtrack:基于相似度学习的多目标跟踪
OCR
【第20篇】像人类一样阅读:自主、双向和迭代语言 场景文本识别建模
超分辨采样
弱光增强
RetinexNet
【第52篇】RetinexNet: Deep Retinex Decomposition for Low-Light Enhancement
NLP
多模态
知识蒸馏
【第54篇】知识蒸馏:Distilling the Knowledge in a Neural Network
剪枝
智慧城市

- 点赞
- 收藏
- 关注作者
评论(0)